Не в совокупности ищи единства, но более – в единообразии разделения.
Козьма Прутков
Нельзя не заметить, что аспектно-ориентированное программирование с каждым годом берет новые рубежи популярности. На хабре было уже несколько статей посвященных этому вопросу, от Java до PHP. Пришло время обратить свой взор на С/C++. Теперь я в первом же абзаце признаюсь, что речь пойдет не об «настоящих аспектах», но о чем-то, близко с ними связанном. Также рассуждение будет вестись в контексте embedded-проектов, хотя описываемые методы могут применяться где угодно, но именно embedded, это та область, где эффект будет максимально ощутимым. Еще я буду использовать слова «хидер» и «дефайн» для обозначения, соответственно, «заголовочного файла» и «макроопределения». Сухой и академичный язык это хорошо, но в данном случае, мне кажется, все будет проще понять, если пользоваться устоявшимися англицизмами.
Одной из причин существования понятия «программная архитектура», является необходимость управления сложностью. На этом поприще пока ничего лучше компонентной модели не придумали. Даже стандарты описания архитектуры ПО от IEEE основаны на принципе разбиения проекта на компоненты. Компоненты – это хорошо, это слабая связность, возможность повторного использования и, в конечном итоге, хорошая архитектура.
В свою очередь, программирование (в широком смысле), это во многом попытка структурировать и описать виртуальный мир в виде текстового описания. И все бы хорошо, но мир (даже виртуальный) устроен несколько сложнее, чем набор взаимодействующих объектов/компонентов. Существует функциональность, называемая «сквозной», которая не содержится в каком-то одном месте, а «размазана» по другим модулям. В качестве примеров можно привести как хрестоматийные: логирование, трассировка, обработка ошибок, так и «нетривиальные», вроде безопасности, поддержки виртуальной памяти или многопроцессорности. Во всех этих случаях, помимо основного модуля (в случае логирования, это может быть сама функция, выводящая лог) существует еще какое-то «нечто», которое должно быть добавлено в другие модули. Причем эти модули не знают об этом. Это нечто называется аспектами. Решением вопроса внедрения аспектов в модули, ничего об этих аспектах не знающих, собственно, и занимается аспектно-ориентированное программирование (АОП).
Близким к АОП понятием является внедрение зависимостей (ВЗ). Хотя их часто противопоставляют друг другу, на самом деле между ними больше общего, чем различий. Главное различие заключается в том, что АОП предполагает, что целевой модуль вообще ничего не знает о том, что и как может в него внедряться. У этого метода есть недостатки, которые я не буду здесь перечислять, дабы не углубляться в философию программирования в целом. Замечу только, что АОП не может решить проблему с «нетривиальными аспектами», когда код нужно внедрить в некоторые специальные точки, зависящие от алгоритма (привязка аспектов происходит к синтаксическим конструкциям вроде вызова функций, возвратов из функций и т.д.). Здесь выходит на сцену внедрение зависимостей. Чем хорошо ВЗ? Прежде всего тем, что интерфейс внедряемого аспекта и модуля становится определенным и не привязанным к синтаксису и именам функций в целевом модуле. Это открывает дорогу для создания «модулей уровня исходных текстов», о которых я и буду говорить в данной статье (модульность сама по себе это тема отдельного большого разговора). Что общего между ВЗ и АОП? Хотя бы то, что ВЗ так же, как и АОП, позволяет внедрять некоторый сторонний код (аспекты), о всех возможных вариантах которого целевой код не знает. Принципиальная разница только в том, что в классическом АОП точки внедрения описываются в коде самого аспекта, а в случае ВЗ, код внедряется в уже находящиеся в целевом коде вызовы интерфейсных методов.
Адепты Java/C# обоснованно возразят, что ВЗ это просто паттерн проектирования, который реализуется в любом языке, просто вместо создания объекта и вызовов его методов, надо вызвать фабричный метод, который проанализирует некоторую внешнюю конфигурацию и создаст то, что надо. Но опять же, поскольку мы находимся в контексте embedded, никакой необоснованной косвенности и динамического конфигурирования быть не должно, т.к. это оказывает самое прямое влияние на производительность. Все должно, по-возможности, происходить статически.
Таким образом, это пост о том, как (и зачем) можно сделать статическое внедрение зависимостей для проектов на С/C++, какие проблемы оно может решить, и как можно с его помощью облегчить себе жизнь.
Проекты для embedded имеют такую специфику, что волей-неволей им приходится работать в большом числе разных окружений и конфигураций (я, в свое время, работал с кодовой базой, которая компилировалась тремя компиляторами под 6 разных ОС, причем различные вариации GCC, которых было где-то 3-4, я считаю за один компилятор). Для разных плат была разная логика, разные драйверы и т.д. Естественным способом навести в этом какой-то порядок является введение конфигурационного хидера, содержащего набор дефайнов (#define), который включал-отключал бы какую-то функциональность. Для каждой возможной конфигурации вводился бы такой файл, и после компиляции всех файлов проекта, собиралось бы то, что нужно.
Не нужно объяснять, что по мере разрастания проекта и увеличения количества модулей в нем, растет размер этого конфигурационного файла, а также количество неявных связей между компонентами. Я имею ввиду то, что структуру проекта автор должен держать в голове, а исходники, которые по смыслу содержат некоторую информацию о зависимостях, никак ему в этом не помогают. Кроме того, поскольку для каждой конфигурации компилируется только какое-то подмножество файлов, достаточно утомительно компилировать все файлы, исключая содержимое ненужных с помощью тех же дефайнов. В качестве альтернативы, можно настроить систему сборки так, чтобы собирались только нужные файлы, но в этом случае надо вручную поддерживать согласованность конфигурационных файлов системы сборки и исходников.
Еще один случай из личного опыта, как-то потребовалось часть проекта отдать заказчику в виде библиотеки. Но с библиотекой надо было поставить и хидеры, причем со всей их внутренней структурой папок. Мало того, что на собственно выявление всех нужных хидеров ушло приличное время, заказчику потребовалось копировать нашу структуру папок хидеров и как-то встраивать в свой проект, на что также ушло время.
Разговоры о модульности в С/C++ ведутся столько, сколько существуют сами эти языки. Довольно часто в списках вакансий мелькает что-то вроде software configuration management engineer, и хотя, на первый взгляд, кажется что это что-то вроде «директора шлагбаума», на самом деле проблема более чем актуальна. Хотя проблема существует не только в С/C++, но именно там это особенно важно из-за активного применения этих языков в проектах, критичных к производительности, и из-за чего применение динамических методов конфигурирования зачастую неприемлемо. Изначально предполагалось, что модульность в С/C++ должна существовать только на уровне библиотек. Чтобы убедиться в этом, достаточно посмотреть на структуру исходников подавляющего большинства проектов на С/C++ (особенно это касается С). Среди подпапок «модулей» содержится папка include, которая содержит хидеры всего проекта, доступная всем модулям. Это «референсный путь». Весь проект, таким образом, представляет собой монолит, конфигурируемый с помощью макропроцессора и системы сборки. Добавление нового модуля влечет добавление его хидеров в общую папку, прописывание новых директив #include, изменения конфигурации системы сборки и многих других мелочей, после чего модуль перестает быть модулем, а становится неотъемлемой частью проекта. Модуль нельзя скомпилировать отдельно от проекта, а проект нельзя собрать без модуля. Ориентация на глобальную папку с хидерами затрудняет также повторное использование модулей в других проектах, просто копированием файлов можно получить в лучшем случае ошибки компиляции (в худшем файлы вообще будут просто лежать в дереве проекта и не будут компилироваться). Дополнительной проблемой является необходимость вручную поддерживать согласованность зависимостей файлов друг от друга, а также определение правильного списка «include directories». Вместе с тем очевидно, что если в проект включается некоторый заголовочный файл, содержащий прототипы функций, то сами функции (реализации) также должны быть включены в сборку.
Возможностей конфигурирования не так много, в основном используются три метода, так сказать «проверенные временем». Первый — #ifdef-#elif-#endif. Каждая точка в коде, поведение которой может меняться в зависимости от конфигурации, обрамляется #ifdef-ом и начинает зависеть от определений из общего «конфигурационного» хидера. Проблемы начинаются, когда надо добавить еще один вариант #elif. Если такие #ifdef равномерно распределены по сотням файлов, сама идея что-то добавить во все эти файлы выглядит бредово. Я называю это «закрытой» системой конфигурирования, вариантов ifdef-а столько, сколько разработчик сиситемы предусмотрел изначально, добавить что-то еще, не меняя исходников, нельзя.
Второй способ полагается на систему сборки, некоторые функции содержат несколько возможных реализаций, нужная реализация определяется конфигурацией системы сборки. Например, если лог проекта выводится через функцию print_log, то может быть несколько реализаций этой функции. Главный недостаток этого метода – накладные расходы времени выполнения. Если нам нужно отключить вызовы каких-то функций, можно написать модуль-заглушку, но какая-то функция все-равно должна быть вызвана.
Наконец, третий способ — виртуальные заголовочные файлы. С помощью средств файловой системы абстрактные имена хидеров вроде cpu.h отображаются на конкретные вроде arm.h или x86.h. Подобная виртуальность хидеров помогает отключать ненужную функциональность путем подмены хидера и замены функций на «пустые» макросы, обладает «открытостью»: хидер можно подставить любой без изменения исходников. Но, к сожалению, отсутствует связь между хидерами и сишными функциями содержащими реализацию нужных функций. Эту согласованность между настройками, абстрактными именами хидеров, конкретными именами и системой сборки надо опять-таки поддерживать вручную. Помимо этого, не всегда очевидно, на какие именно имена и что можно настраивать. В итоге плохо документированный проект опять становится неподдерживаемым.
Разумеется, фантазия разработчиков этими тремя методами не ограничивается, и в разных проектах можно встретить самые разные методы конфигурирования. Где-то используются shell-скрипты, генерирующие glue-исходники (главным образом для того, чтобы организовать распространение дефайнов как в хидеры исходников, так и в файлы системы сборки), где-то CMake/SCons и т.д. Обилие этих методов опять же говорит о том, что согласия и каких-то общих методов решения проблемы конфигурирования не существует на данный момент.
Центральная идея, как можно решить эти проблемы, заключается в том, что информация о зависимостях должна содержаться в самих исходниках. Связь между заголовочными файлами и реализацией должна быть явной, а не находиться только в голове у разработчка. Нечто похожее было несколько десятков лет назад в Pascal (в зале слышны обвинения докладчика в ереси). Старожилы помнят, что паскалевские модули содержали две секции interface и implementation, а в качестве инклудов использовался uses <имя модуля>. В этом варианте сами исходники содержали всю информацию о зависимостях и можно было по одним только исходникам построить полный граф зависимостей и понять, что надо скомпилировать, для того чтобы собрать какой-то модуль.
Хотелось бы добавить в сишные исходники некоторую информацию, которая помогла бы внешней системе анализа исходников отследить зависимости между ними.
Когда искались варианты решения этой проблемы, всем было понятно, что время, когда можно было вносить синтаксические изменения такого масштаба в язык, давно прошло. Даже гигантам софтверной индустрии требуется немало ресурсов для того чтобы вывести в жизнь новый язык, не говоря уже о том, чтоб внести какие-то изменения в святая святых – С/С++, кода на которых уже написано более чем много. Поэтому пришлось довольствоваться только тем, что предлагает стандарт. Написать какие-то метки в файле можно многими способами, основной вопрос был в том, как сделать «контролируемый импорт» (Include), а также отследить зависимости. Для инклудов выбор невелик, согласно стандарту, туда можно писать только имена файлов (в кавычках либо угловых скобках) и макросы. Именно последние и дали ключ к решению проблемы. Но обо всем по порядку.
Не мудрствуя лукаво, решено было добавить аналогичные паскалевским метки в хидеры и исходники. Что-то вроде метки INTERFACE:IMPLEMENTATION. Было много дискуссий, чем именно их нужно делать, но остановились в итоге на #pragma. До сих пор есть сомнения, стоило ли делать метки в таком виде (и получать пачки warning-ов вроде unknown pragma). Теоретически, #pragma позволяет добавить информацию об импортах/экспортах еще и в бинарники, тогда в процессе конфигурирования смогут участвовать как исходники, так и библиотеки. Разрабатывались (и разрабатываются) версии с использованием макросов (подстановка значений в которые происходит на этапе анализа исходников, а рабочий файл содержит пустой макрос-заглушку). Этот вопрос остается дискуссионным.
Как уже говорилось выше, каждый хидер должен иметь внутри себя метку вида
где <interface_name> — имя интерфейса, а <impl_version> это идентификатор конкретной реализации (версия, вариант, и т.д.). То есть каждый компонент, должен иметь уникальную метку. У тех компонентов, у которых интерфейс совпадает, должна также совпадать и часть interface_name. Версия или реализация нужна, чтобы различать реализации между собой. Аналогичную метку должен иметь файл реализации, только вместо fx interface — fx implementation. Различные прагмы interface/implementation нужны, чтоб различать метки, находящиеся в хидерах и в исходниках (о том, почему нельзя это понять из расширения файлов, будет говориться ниже).
Таким образом, компонент, состоящий, к примеру, из хидера и сишных файлов должен содержать во всех своих файлах одинаковую метку interface_name и version, только в хидере будет #pragma fx interface, а в исходниках pragma fx implementation. Другая реализация того же компонента (с таким же интерфейсом) должна также во всех своих файлах содержать одинаковую метку, но version должен отличаться от того, который написан в первом компоненте и т.д. Включение же чего-либо с помощью #include должно использовать имя интерфейса, а не имя файла, как обычно. В текущей реализации для этого используется макрос
Откуда возьмутся эти макросы? Некоторый внешний инструмент, получив пути к исходникам, должен их проанализировать, найти в них эти метки, построить все графы, после чего сгенерировать общий заголовочный файл, содержащий отображения имен файлов на имена интерфейсов и определить макрос FX_INTERFACE. Данный файл должен быть принудительно включен во все компилируемые файлы директивой компилятора ВМЕСТО путей к Include-директориям, т.к. этот файл уже содержит пути ко всем нужным файлам (впрочем, никто не запрещает смешивать это в любых пропорциях со стандартным подходом с обычными #include со скобками).
Рассмотрим некоторый модуль А, находящийся в файле module_a.c и модуль Б, в файле module_b.c, а также соответствующие им хидеры. module_b.h включает интерфейс, определенный в module_a.h. В первом приближении все выглядит так:
Реализация определена в файле module_a.c:
Создаём модуль B, который использует (ссылается) на модуль A:
Реализация модуля B в файле “module_b.c”:
Из этого уже понятно, как можно получить зависимости исходников от заголовочного файла. Если кто-то использует хидер, содержащий определенный интерфейс, то скомпилировать нужно также все файлы-реализации (с расширением с или срр), содержащие такие же метки implementation.
Как теперь отследить зависимости и понять, что если нам надо скомпилировать module_b.с, то это влечет за собой необходимость компиляции и module_a.с? Если каждый файл включает все модули, от которых он зависит, в виде include-ов, а каждый заголовочный файл содержит в себе #pragma fx interface, тогда, обработав файл препроцессором, и найдя в выводе все #pragma, можно понять, какие у данного модуля зависимости (все найденные implementation, зависят от всех найденных interface). В частности, пропустив через препроцессор файл module_b.с получим что-то вроде:
Из этого примера понятно, почему нужны разные прагмы для хидеров и исходников: после работы препроцессора информация о расширениях теряется, поэтому, чтобы отследить зависимости исходников от хидеров, метки должны различаться.
Теперь рассмотрим главный штрих, который на самом деле являлся первопричиной всех наших изысканий. Если посмотреть на классический пример АОП или ВЗ – логирование, то обычно оно определяется как набор макросов, отключив которые в одном модуле, они отключаются по всему проекту. Такой же трюк проделывается с трассировкой и некоторыми другими вещами. Логично задать вопрос, почему бы не сделать то же самое вообще с любым модулем (интерфейсом)? Поскольку включение хидера это обычно включение некоторого абстрактного интерфейса, почему бы его таковым и не сделать. Написав вот так:
получаем модуль, импортирующий некоторый абстрактный интерфейс, причем на уровне исходников нету никакой информации о том, какая именно реализация будет использоваться. Проект становится истинно модульным, в исходниках больше нету никакой неявной информации о связях между компонентами.
Понятно, что в случае использования абстрактных интерфейсов нужна внешняя информация о связях, в которой будет содержаться информация вроде A:DEFAULT = A:VER1. Она может содержаться в каком-то внешнем файле отображений. Теперь, изменяя этот файл отображений, мы можем сделать полноценное ВЗ работающее во время компиляции, причем с автоматическим отслеживанием зависимостей и автоматическим же выяснением, какие файлы должны войти в сборку.
Чем файл отображений отличается от упомянутого глобального config.h? Отличий немного, но они важные, config.h предполагает, что он будет включен во все файлы и что все файлы надо компилировать (возможно, содержимое некоторых из них будет полностью исключено препроцессором), а предлагаемый подход влияет на построение графа модулей и построение списков файлов для сборки, то есть то, что не должно компилироваться – не будет компилироваться вообще, причем зависимости извлекаются из самих исходников и, к примеру, закомментировав какой-то include автоматически получаем исключение файлов-реализаций из сборки без небходимости делать это вручную.
Получаемые таким образом компоненты гораздо более лояльны к повторному использованию себя, нежели обычные исходники, в частности, такие модули достаточно просто скопировать в дерево проекта, чтобы их можно было использовать. В качестве бонуса идет абсолютная свобода в структуре исходников, их можно перекладывать по папкам и переименовывать файлы хоть 20 раз на дню. Можно забыть о настройке include-директорий, проблемах с переименованием файлов, прописыванием новопоявившихся файлов в makefiles и т.д. Кроме того, если интерфейсы делать на должном уровне абстракции, можно отказаться также и от #ifdef-ов. Система получается «открытой», в качестве виртуального хидера можо указать любую реализацию, а не только те, которые были изначально предусмотрены, как это было бы в случае с #ifdef. Про кроссплатформенность и совместимость со всеми компиляторами говорить не буду: тут и так все понятно.
У системы, основанной на внедрении зависимостей очень простая архитектура, до того, как это внедрение произведено. Вся система представляет собой плоский набор компонентов, никак не связанных друг с другом. Архитектура, как иерархия между ними, и как граф взаимодействий, целиком определяется информацией о зависимостях. Компоненты, конечно, нельзя соединять произвольным образом, они накладывают ограничения на возможные конфигурации, но всю эту информацию можно извлечь из исходников. Конфигурирование можно осуществлять на уровне замены подграфов.
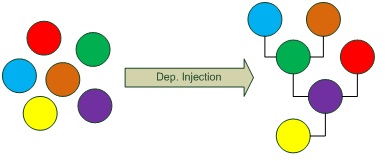
Это что касается разноцветных кружочков.
Конечно, кроме достоинств, есть и много проблем, я перечислю лишь некоторые из них: интерфейсы глобальны, то есть в собранной системе может быть только 1 экземпляр каждого модуля. Кроме того, соответствие имени интерфейса и содержимого хидера на совести автора. Тот факт, что интерфейс подходит синтаксически для данной конфигурации, еще не говорит о том, что реализация будет работать так, как ожидается (и что будет работать во всех возможных случаях). Поэтому, если модуль подходит по интерфейсу, это еще не значит, что он подойдет во всех случаях. Последствия применения «неправильного» модуля могут быть печальны, даже если все компилируется.

Другим вопросом являются циклические зависимости. Собственно, эта проблема есть и в «обычном» С, когда несколько хидеров инклудят друг друга. Здесь работают те же правила, что и «в общем», поскольку не используется ничего, выходящего за пределы препроцессора, и все #include FX_INTERFACE в конечном итоге отображаются на имена файлов, эти файлы следует защищать от повторного включения с помощью обычных методов: #ifndef/#define или #pragma once. Ситуация, когда два модуля зависят друг от друга, допустима, поскольку файлы обрабатываются препроцессором отдельно, никакой рекурсии не произойдет, а возможные дубликаты файлов удаляются из списка исходников для компиляции (это не хак, это фича: один и тот же модуль могут инклудить несколько раз, но это не значит, что его исходники надо несколько раз написать в makefile).
В общем, проблемы еще есть, но, как говорится, «мы работаем над этим».
Можно было бы, по традиции, рассмотреть вынесение в модуль логирования или чего-то подобного, но полиморфизм на уровне функций это не очень интересно. В С довольно часто используется run-time контроль типа, то есть методы объекта могут захотеть проконтролировать, что им в качестве аргумента дали именно тот тип, который они ожидают, несмотря на возможные приведения типа пользователем. Для этих целей внутри структуры выделяется специальное поле, содержащее некоторое нетривиальное значение, которое устанавливается на этапе инициализации объекта конструктором, а затем проверяется всеми функциями, работающими с объектом. Если там отличное от ожидаемого значение – значит нам дали объект неправильного типа либо где-то произошло затирание чужой памяти. Также понятно, что после того, как программа отлажена, весь этот функционал нужно удалить. Динамическими методами конфигурирования задача не решается, т.к. после определения sizeof-ов всех структур, что-то из них удалить и уменьшить размеры уже невозможно.
Возможны различные реализации этого механизма. Например, во время инициализации, вместо того, чтобы просто устанавливать какое-то magic-значение, можно, пользуясь адресом этого поля, которое находится в объекте, добавлять объект в какой-нибудь «пул существующих в системе валидных объектов». Если пришел какой-то адрес, а его в «пуле» нет, значит объект невалиден.
«Классические» методы решения этой задачи имеют недостатки. В частности, включение/отключение может быть реализовано с помощью #ifdef, но использование разных реализаций уже требует взаимодействия с системой сборки. Если соответствующие дефайны действуют также и на систему сборки, все равно добавить какой-то новый вариант не так просто, т.к. систему конфигурирования надо «научить» этому новому варианту (прописать имена файлов для компиляции в конфиги + зависимости). Рассмотрим, как можно сделать «открытую» для конфигурирования систему.
Начнем с интерфейса модуля, реализующего нужные нам функции. Интерфейс модуля, то есть то, что дожно содержаться в его хидере, включает некоторый тип данных, который должен расширять защищаемые объекты, а также набор функций для инициализации этого типа данных и для проверки.
Его реализация не важна, важно то, что если кто-то использует такой хидер, то реализация попадет в билд автоматически. Понятие «интерфейс» здесь используется в широком смысле, в отличие от определения в стиле ООП: под «интерфейсом» имеется ввиду некоторое соглашение, а не только набор и сигнатуры функций. В частности, тип данных «runtime_protection» является частью интерфейса RUNTIME_PROTECTION, то есть все хидеры, имеющие такую прагму, обязаны как-то определять такой тип данных (не обязательно как структуру).
Модули, использующие такую защиту, должны, перед тем как использовать упомянутые типы данных и функции, сделать импорт интерфейса:
Реализация объекта просто использует функции, не задумываясь о том, чем они являются и откуда берутся:
В случае, если мы хотим отключить проверки типов, надо написать интерфейс-заглушку вроде:
Хотя это и не по стандарту, но некоторые компиляторы для С делают sizeof пустых структур равным нулю (по стандарту, sizeof не может быть равным нулю, но, по тому же стандарту, пустая структура в С — это ошибка). Если требуется строгое следование букве стандарта, тогда можно либо обернуть объявление структуры макросом, либо смириться с некоторыми накладными расходами и написать там int dummy.
Если в качестве интерфейса по умолчанию используется заглушка, это становится синтаксически экивалентно отсутствию каких-либо проверок, если обработка ошибок не обернута, это приведет к условиям вроде if(true), которые должны быть оптимизированы компилятором. Теперь можно писать различные варианты такого модуля, причем исходники, которые используют этот интерфейс не потребуют вообще никаких изменений. Изменяя только файл отображения, автоматически будут меняться как хидеры, так и списки файлов для компиляции и сборки.
Финалом наших изысканий (который, в данный момент, можно показать публике) стал инструмент FX-DJ, FX – потому что изначально он предназначался исключительно для конфигурирования FX-RTOS — другого нашего проекта, и все инструменты были с префиксом FX (почему сама ОС так называется, это тема другого разговора). Ну а DJ, как вы могли догадаться, означает Dependency inJector, а вовсе не DJ, хотя определенные параллели с диджеями по части выполняемых задач все-таки есть.
Он представляет собой дополнительную фазу сборки, выполняющуюся до компиляции – configuration-фазу, когда из некоего абстрактного пула исходников-компонентов по неким правилам формируется иерархическая система, основанная на зависимостях, в результате которой определяются списки файлов, которые надо собрать, после чего происходят, как обычно, фазы компиляции и компоновки. Поддерживается вывод списка файлов для компиляции как в виде плоского списка для использования каким-то внешним инструментом, так и в формате make.
Весь процесс можно изобразить примерно так:
Alias files – это те самые файлы, отображающие default-интерфейсы на конкретные. Каждый из них соответствует определенной конфигурации. Target – целевой интерфейс, тот, который в корне дерева зависимостей.
Пока это все сделано в виде компактного скрипта на Python 2.7 (в комплект входит также скомпилированный с помощью py2exe исполняемый файл, не требующий установленного Python). Инструмент распространяется под модифицированной BSD-лицензией, поэтому делать с ним можно практически все что угодно и бесплатно. Хотя всё уже опубликовано, в целом все пока находится в состоянии alpha-version, «блог компании» находится в процессе покупки, поэтому пока поговорим только о концепциях, а ссылки на скачивание будут позже.
Если тема окажется интересной, расскажу в следующей статье об FX-RTOS: зачем нужна «еще одна» операционная система, идеях, лежащих в ее основе, «почему это нельзя было сделать на основе линукса» и т.д.
Последнее время тема модулей в С/C++ поднимается регулярно, начиная от обсуждения их в комитете по стандартизации С++ и заканчивая предложениями Apple по их поддержке в LLVM. В посте описан еще один взгляд на данную проблему и способы ее решения. Получившийся вариант обладает, безусловно, определенными недостатками, однако не требует никаких синтаксических изменений в языке, может применяться в любых проектах уже сейчас и решает те задачи, для решения которых создавался: создание программных модулей уровня исходных текстов, независимость от структуры папок конкретного проекта, включение/отключение/замена модулей без изменений в исходниках, автоматическое управление сборкой без необходимости описания зависимостей вручную, кроссплатформенность, 100% совместимость со стандартом и т.д.
На этом пока все. Всем спасибо за внимание.
Козьма Прутков
Немного воды вначале
Нельзя не заметить, что аспектно-ориентированное программирование с каждым годом берет новые рубежи популярности. На хабре было уже несколько статей посвященных этому вопросу, от Java до PHP. Пришло время обратить свой взор на С/C++. Теперь я в первом же абзаце признаюсь, что речь пойдет не об «настоящих аспектах», но о чем-то, близко с ними связанном. Также рассуждение будет вестись в контексте embedded-проектов, хотя описываемые методы могут применяться где угодно, но именно embedded, это та область, где эффект будет максимально ощутимым. Еще я буду использовать слова «хидер» и «дефайн» для обозначения, соответственно, «заголовочного файла» и «макроопределения». Сухой и академичный язык это хорошо, но в данном случае, мне кажется, все будет проще понять, если пользоваться устоявшимися англицизмами.
Одной из причин существования понятия «программная архитектура», является необходимость управления сложностью. На этом поприще пока ничего лучше компонентной модели не придумали. Даже стандарты описания архитектуры ПО от IEEE основаны на принципе разбиения проекта на компоненты. Компоненты – это хорошо, это слабая связность, возможность повторного использования и, в конечном итоге, хорошая архитектура.
В свою очередь, программирование (в широком смысле), это во многом попытка структурировать и описать виртуальный мир в виде текстового описания. И все бы хорошо, но мир (даже виртуальный) устроен несколько сложнее, чем набор взаимодействующих объектов/компонентов. Существует функциональность, называемая «сквозной», которая не содержится в каком-то одном месте, а «размазана» по другим модулям. В качестве примеров можно привести как хрестоматийные: логирование, трассировка, обработка ошибок, так и «нетривиальные», вроде безопасности, поддержки виртуальной памяти или многопроцессорности. Во всех этих случаях, помимо основного модуля (в случае логирования, это может быть сама функция, выводящая лог) существует еще какое-то «нечто», которое должно быть добавлено в другие модули. Причем эти модули не знают об этом. Это нечто называется аспектами. Решением вопроса внедрения аспектов в модули, ничего об этих аспектах не знающих, собственно, и занимается аспектно-ориентированное программирование (АОП).
Близким к АОП понятием является внедрение зависимостей (ВЗ). Хотя их часто противопоставляют друг другу, на самом деле между ними больше общего, чем различий. Главное различие заключается в том, что АОП предполагает, что целевой модуль вообще ничего не знает о том, что и как может в него внедряться. У этого метода есть недостатки, которые я не буду здесь перечислять, дабы не углубляться в философию программирования в целом. Замечу только, что АОП не может решить проблему с «нетривиальными аспектами», когда код нужно внедрить в некоторые специальные точки, зависящие от алгоритма (привязка аспектов происходит к синтаксическим конструкциям вроде вызова функций, возвратов из функций и т.д.). Здесь выходит на сцену внедрение зависимостей. Чем хорошо ВЗ? Прежде всего тем, что интерфейс внедряемого аспекта и модуля становится определенным и не привязанным к синтаксису и именам функций в целевом модуле. Это открывает дорогу для создания «модулей уровня исходных текстов», о которых я и буду говорить в данной статье (модульность сама по себе это тема отдельного большого разговора). Что общего между ВЗ и АОП? Хотя бы то, что ВЗ так же, как и АОП, позволяет внедрять некоторый сторонний код (аспекты), о всех возможных вариантах которого целевой код не знает. Принципиальная разница только в том, что в классическом АОП точки внедрения описываются в коде самого аспекта, а в случае ВЗ, код внедряется в уже находящиеся в целевом коде вызовы интерфейсных методов.
Адепты Java/C# обоснованно возразят, что ВЗ это просто паттерн проектирования, который реализуется в любом языке, просто вместо создания объекта и вызовов его методов, надо вызвать фабричный метод, который проанализирует некоторую внешнюю конфигурацию и создаст то, что надо. Но опять же, поскольку мы находимся в контексте embedded, никакой необоснованной косвенности и динамического конфигурирования быть не должно, т.к. это оказывает самое прямое влияние на производительность. Все должно, по-возможности, происходить статически.
Таким образом, это пост о том, как (и зачем) можно сделать статическое внедрение зависимостей для проектов на С/C++, какие проблемы оно может решить, и как можно с его помощью облегчить себе жизнь.
Специфика больших embedded-проектов
Проекты для embedded имеют такую специфику, что волей-неволей им приходится работать в большом числе разных окружений и конфигураций (я, в свое время, работал с кодовой базой, которая компилировалась тремя компиляторами под 6 разных ОС, причем различные вариации GCC, которых было где-то 3-4, я считаю за один компилятор). Для разных плат была разная логика, разные драйверы и т.д. Естественным способом навести в этом какой-то порядок является введение конфигурационного хидера, содержащего набор дефайнов (#define), который включал-отключал бы какую-то функциональность. Для каждой возможной конфигурации вводился бы такой файл, и после компиляции всех файлов проекта, собиралось бы то, что нужно.
Не нужно объяснять, что по мере разрастания проекта и увеличения количества модулей в нем, растет размер этого конфигурационного файла, а также количество неявных связей между компонентами. Я имею ввиду то, что структуру проекта автор должен держать в голове, а исходники, которые по смыслу содержат некоторую информацию о зависимостях, никак ему в этом не помогают. Кроме того, поскольку для каждой конфигурации компилируется только какое-то подмножество файлов, достаточно утомительно компилировать все файлы, исключая содержимое ненужных с помощью тех же дефайнов. В качестве альтернативы, можно настроить систему сборки так, чтобы собирались только нужные файлы, но в этом случае надо вручную поддерживать согласованность конфигурационных файлов системы сборки и исходников.
Еще один случай из личного опыта, как-то потребовалось часть проекта отдать заказчику в виде библиотеки. Но с библиотекой надо было поставить и хидеры, причем со всей их внутренней структурой папок. Мало того, что на собственно выявление всех нужных хидеров ушло приличное время, заказчику потребовалось копировать нашу структуру папок хидеров и как-то встраивать в свой проект, на что также ушло время.
Почему C/C++ проекты сложно конфигурировать
Разговоры о модульности в С/C++ ведутся столько, сколько существуют сами эти языки. Довольно часто в списках вакансий мелькает что-то вроде software configuration management engineer, и хотя, на первый взгляд, кажется что это что-то вроде «директора шлагбаума», на самом деле проблема более чем актуальна. Хотя проблема существует не только в С/C++, но именно там это особенно важно из-за активного применения этих языков в проектах, критичных к производительности, и из-за чего применение динамических методов конфигурирования зачастую неприемлемо. Изначально предполагалось, что модульность в С/C++ должна существовать только на уровне библиотек. Чтобы убедиться в этом, достаточно посмотреть на структуру исходников подавляющего большинства проектов на С/C++ (особенно это касается С). Среди подпапок «модулей» содержится папка include, которая содержит хидеры всего проекта, доступная всем модулям. Это «референсный путь». Весь проект, таким образом, представляет собой монолит, конфигурируемый с помощью макропроцессора и системы сборки. Добавление нового модуля влечет добавление его хидеров в общую папку, прописывание новых директив #include, изменения конфигурации системы сборки и многих других мелочей, после чего модуль перестает быть модулем, а становится неотъемлемой частью проекта. Модуль нельзя скомпилировать отдельно от проекта, а проект нельзя собрать без модуля. Ориентация на глобальную папку с хидерами затрудняет также повторное использование модулей в других проектах, просто копированием файлов можно получить в лучшем случае ошибки компиляции (в худшем файлы вообще будут просто лежать в дереве проекта и не будут компилироваться). Дополнительной проблемой является необходимость вручную поддерживать согласованность зависимостей файлов друг от друга, а также определение правильного списка «include directories». Вместе с тем очевидно, что если в проект включается некоторый заголовочный файл, содержащий прототипы функций, то сами функции (реализации) также должны быть включены в сборку.
Возможностей конфигурирования не так много, в основном используются три метода, так сказать «проверенные временем». Первый — #ifdef-#elif-#endif. Каждая точка в коде, поведение которой может меняться в зависимости от конфигурации, обрамляется #ifdef-ом и начинает зависеть от определений из общего «конфигурационного» хидера. Проблемы начинаются, когда надо добавить еще один вариант #elif. Если такие #ifdef равномерно распределены по сотням файлов, сама идея что-то добавить во все эти файлы выглядит бредово. Я называю это «закрытой» системой конфигурирования, вариантов ifdef-а столько, сколько разработчик сиситемы предусмотрел изначально, добавить что-то еще, не меняя исходников, нельзя.
Второй способ полагается на систему сборки, некоторые функции содержат несколько возможных реализаций, нужная реализация определяется конфигурацией системы сборки. Например, если лог проекта выводится через функцию print_log, то может быть несколько реализаций этой функции. Главный недостаток этого метода – накладные расходы времени выполнения. Если нам нужно отключить вызовы каких-то функций, можно написать модуль-заглушку, но какая-то функция все-равно должна быть вызвана.
Наконец, третий способ — виртуальные заголовочные файлы. С помощью средств файловой системы абстрактные имена хидеров вроде cpu.h отображаются на конкретные вроде arm.h или x86.h. Подобная виртуальность хидеров помогает отключать ненужную функциональность путем подмены хидера и замены функций на «пустые» макросы, обладает «открытостью»: хидер можно подставить любой без изменения исходников. Но, к сожалению, отсутствует связь между хидерами и сишными функциями содержащими реализацию нужных функций. Эту согласованность между настройками, абстрактными именами хидеров, конкретными именами и системой сборки надо опять-таки поддерживать вручную. Помимо этого, не всегда очевидно, на какие именно имена и что можно настраивать. В итоге плохо документированный проект опять становится неподдерживаемым.
Разумеется, фантазия разработчиков этими тремя методами не ограничивается, и в разных проектах можно встретить самые разные методы конфигурирования. Где-то используются shell-скрипты, генерирующие glue-исходники (главным образом для того, чтобы организовать распространение дефайнов как в хидеры исходников, так и в файлы системы сборки), где-то CMake/SCons и т.д. Обилие этих методов опять же говорит о том, что согласия и каких-то общих методов решения проблемы конфигурирования не существует на данный момент.
Серебряная пуля
Центральная идея, как можно решить эти проблемы, заключается в том, что информация о зависимостях должна содержаться в самих исходниках. Связь между заголовочными файлами и реализацией должна быть явной, а не находиться только в голове у разработчка. Нечто похожее было несколько десятков лет назад в Pascal (в зале слышны обвинения докладчика в ереси). Старожилы помнят, что паскалевские модули содержали две секции interface и implementation, а в качестве инклудов использовался uses <имя модуля>. В этом варианте сами исходники содержали всю информацию о зависимостях и можно было по одним только исходникам построить полный граф зависимостей и понять, что надо скомпилировать, для того чтобы собрать какой-то модуль.
Хотелось бы добавить в сишные исходники некоторую информацию, которая помогла бы внешней системе анализа исходников отследить зависимости между ними.
Когда искались варианты решения этой проблемы, всем было понятно, что время, когда можно было вносить синтаксические изменения такого масштаба в язык, давно прошло. Даже гигантам софтверной индустрии требуется немало ресурсов для того чтобы вывести в жизнь новый язык, не говоря уже о том, чтоб внести какие-то изменения в святая святых – С/С++, кода на которых уже написано более чем много. Поэтому пришлось довольствоваться только тем, что предлагает стандарт. Написать какие-то метки в файле можно многими способами, основной вопрос был в том, как сделать «контролируемый импорт» (Include), а также отследить зависимости. Для инклудов выбор невелик, согласно стандарту, туда можно писать только имена файлов (в кавычках либо угловых скобках) и макросы. Именно последние и дали ключ к решению проблемы. Но обо всем по порядку.
Не мудрствуя лукаво, решено было добавить аналогичные паскалевским метки в хидеры и исходники. Что-то вроде метки INTERFACE:IMPLEMENTATION. Было много дискуссий, чем именно их нужно делать, но остановились в итоге на #pragma. До сих пор есть сомнения, стоило ли делать метки в таком виде (и получать пачки warning-ов вроде unknown pragma). Теоретически, #pragma позволяет добавить информацию об импортах/экспортах еще и в бинарники, тогда в процессе конфигурирования смогут участвовать как исходники, так и библиотеки. Разрабатывались (и разрабатываются) версии с использованием макросов (подстановка значений в которые происходит на этапе анализа исходников, а рабочий файл содержит пустой макрос-заглушку). Этот вопрос остается дискуссионным.
Как уже говорилось выше, каждый хидер должен иметь внутри себя метку вида
#pragma fx interface <interface_name>:<impl_version>
где <interface_name> — имя интерфейса, а <impl_version> это идентификатор конкретной реализации (версия, вариант, и т.д.). То есть каждый компонент, должен иметь уникальную метку. У тех компонентов, у которых интерфейс совпадает, должна также совпадать и часть interface_name. Версия или реализация нужна, чтобы различать реализации между собой. Аналогичную метку должен иметь файл реализации, только вместо fx interface — fx implementation. Различные прагмы interface/implementation нужны, чтоб различать метки, находящиеся в хидерах и в исходниках (о том, почему нельзя это понять из расширения файлов, будет говориться ниже).
Таким образом, компонент, состоящий, к примеру, из хидера и сишных файлов должен содержать во всех своих файлах одинаковую метку interface_name и version, только в хидере будет #pragma fx interface, а в исходниках pragma fx implementation. Другая реализация того же компонента (с таким же интерфейсом) должна также во всех своих файлах содержать одинаковую метку, но version должен отличаться от того, который написан в первом компоненте и т.д. Включение же чего-либо с помощью #include должно использовать имя интерфейса, а не имя файла, как обычно. В текущей реализации для этого используется макрос
FX_INTERFACE(<interface>,<impl_version>)
Откуда возьмутся эти макросы? Некоторый внешний инструмент, получив пути к исходникам, должен их проанализировать, найти в них эти метки, построить все графы, после чего сгенерировать общий заголовочный файл, содержащий отображения имен файлов на имена интерфейсов и определить макрос FX_INTERFACE. Данный файл должен быть принудительно включен во все компилируемые файлы директивой компилятора ВМЕСТО путей к Include-директориям, т.к. этот файл уже содержит пути ко всем нужным файлам (впрочем, никто не запрещает смешивать это в любых пропорциях со стандартным подходом с обычными #include со скобками).
Рассмотрим некоторый модуль А, находящийся в файле module_a.c и модуль Б, в файле module_b.c, а также соответствующие им хидеры. module_b.h включает интерфейс, определенный в module_a.h. В первом приближении все выглядит так:
/* Содержимое файла module_a.h. Интерфейс модуля А версии VER1 */
…
#pragma fx interface A:VER1
Реализация определена в файле module_a.c:
/* Реализация модуля A версии VER1 */
#pragma fx implementation A:VER1
Создаём модуль B, который использует (ссылается) на модуль A:
/* Module_B.h. Включение интерфейса A */
#include FX_INTERFACE(A, VER1)
…
/* Интерфейс модуля B версии VER1 */
#pragma fx interface B:VER1
Реализация модуля B в файле “module_b.c”:
/* Включение своего хидера */
#include FX_INTERFACE(B, VER1)
…
/* Реализация модуля B версии VER1 */
#pragma fx implementation B:VER1
Из этого уже понятно, как можно получить зависимости исходников от заголовочного файла. Если кто-то использует хидер, содержащий определенный интерфейс, то скомпилировать нужно также все файлы-реализации (с расширением с или срр), содержащие такие же метки implementation.
Как теперь отследить зависимости и понять, что если нам надо скомпилировать module_b.с, то это влечет за собой необходимость компиляции и module_a.с? Если каждый файл включает все модули, от которых он зависит, в виде include-ов, а каждый заголовочный файл содержит в себе #pragma fx interface, тогда, обработав файл препроцессором, и найдя в выводе все #pragma, можно понять, какие у данного модуля зависимости (все найденные implementation, зависят от всех найденных interface). В частности, пропустив через препроцессор файл module_b.с получим что-то вроде:
/* Хидер модуля А включенный модулем Б */
#pragma fx interface A:VER1
…
/* Собственная метка из хидера модуля Б */
#pragma fx interface B:VER1
…
/* Метка файла module_b.c */
#pragma fx implementation B:VER1
Из этого примера понятно, почему нужны разные прагмы для хидеров и исходников: после работы препроцессора информация о расширениях теряется, поэтому, чтобы отследить зависимости исходников от хидеров, метки должны различаться.
Теперь рассмотрим главный штрих, который на самом деле являлся первопричиной всех наших изысканий. Если посмотреть на классический пример АОП или ВЗ – логирование, то обычно оно определяется как набор макросов, отключив которые в одном модуле, они отключаются по всему проекту. Такой же трюк проделывается с трассировкой и некоторыми другими вещами. Логично задать вопрос, почему бы не сделать то же самое вообще с любым модулем (интерфейсом)? Поскольку включение хидера это обычно включение некоторого абстрактного интерфейса, почему бы его таковым и не сделать. Написав вот так:
#include FX_INTERFACE(A, DEFAULT)
получаем модуль, импортирующий некоторый абстрактный интерфейс, причем на уровне исходников нету никакой информации о том, какая именно реализация будет использоваться. Проект становится истинно модульным, в исходниках больше нету никакой неявной информации о связях между компонентами.
Понятно, что в случае использования абстрактных интерфейсов нужна внешняя информация о связях, в которой будет содержаться информация вроде A:DEFAULT = A:VER1. Она может содержаться в каком-то внешнем файле отображений. Теперь, изменяя этот файл отображений, мы можем сделать полноценное ВЗ работающее во время компиляции, причем с автоматическим отслеживанием зависимостей и автоматическим же выяснением, какие файлы должны войти в сборку.
Чем файл отображений отличается от упомянутого глобального config.h? Отличий немного, но они важные, config.h предполагает, что он будет включен во все файлы и что все файлы надо компилировать (возможно, содержимое некоторых из них будет полностью исключено препроцессором), а предлагаемый подход влияет на построение графа модулей и построение списков файлов для сборки, то есть то, что не должно компилироваться – не будет компилироваться вообще, причем зависимости извлекаются из самих исходников и, к примеру, закомментировав какой-то include автоматически получаем исключение файлов-реализаций из сборки без небходимости делать это вручную.
Получаемые таким образом компоненты гораздо более лояльны к повторному использованию себя, нежели обычные исходники, в частности, такие модули достаточно просто скопировать в дерево проекта, чтобы их можно было использовать. В качестве бонуса идет абсолютная свобода в структуре исходников, их можно перекладывать по папкам и переименовывать файлы хоть 20 раз на дню. Можно забыть о настройке include-директорий, проблемах с переименованием файлов, прописыванием новопоявившихся файлов в makefiles и т.д. Кроме того, если интерфейсы делать на должном уровне абстракции, можно отказаться также и от #ifdef-ов. Система получается «открытой», в качестве виртуального хидера можо указать любую реализацию, а не только те, которые были изначально предусмотрены, как это было бы в случае с #ifdef. Про кроссплатформенность и совместимость со всеми компиляторами говорить не буду: тут и так все понятно.
У системы, основанной на внедрении зависимостей очень простая архитектура, до того, как это внедрение произведено. Вся система представляет собой плоский набор компонентов, никак не связанных друг с другом. Архитектура, как иерархия между ними, и как граф взаимодействий, целиком определяется информацией о зависимостях. Компоненты, конечно, нельзя соединять произвольным образом, они накладывают ограничения на возможные конфигурации, но всю эту информацию можно извлечь из исходников. Конфигурирование можно осуществлять на уровне замены подграфов.

Это что касается разноцветных кружочков.
Конечно, кроме достоинств, есть и много проблем, я перечислю лишь некоторые из них: интерфейсы глобальны, то есть в собранной системе может быть только 1 экземпляр каждого модуля. Кроме того, соответствие имени интерфейса и содержимого хидера на совести автора. Тот факт, что интерфейс подходит синтаксически для данной конфигурации, еще не говорит о том, что реализация будет работать так, как ожидается (и что будет работать во всех возможных случаях). Поэтому, если модуль подходит по интерфейсу, это еще не значит, что он подойдет во всех случаях. Последствия применения «неправильного» модуля могут быть печальны, даже если все компилируется.

Другим вопросом являются циклические зависимости. Собственно, эта проблема есть и в «обычном» С, когда несколько хидеров инклудят друг друга. Здесь работают те же правила, что и «в общем», поскольку не используется ничего, выходящего за пределы препроцессора, и все #include FX_INTERFACE в конечном итоге отображаются на имена файлов, эти файлы следует защищать от повторного включения с помощью обычных методов: #ifndef/#define или #pragma once. Ситуация, когда два модуля зависят друг от друга, допустима, поскольку файлы обрабатываются препроцессором отдельно, никакой рекурсии не произойдет, а возможные дубликаты файлов удаляются из списка исходников для компиляции (это не хак, это фича: один и тот же модуль могут инклудить несколько раз, но это не значит, что его исходники надо несколько раз написать в makefile).
В общем, проблемы еще есть, но, как говорится, «мы работаем над этим».
Пример
Можно было бы, по традиции, рассмотреть вынесение в модуль логирования или чего-то подобного, но полиморфизм на уровне функций это не очень интересно. В С довольно часто используется run-time контроль типа, то есть методы объекта могут захотеть проконтролировать, что им в качестве аргумента дали именно тот тип, который они ожидают, несмотря на возможные приведения типа пользователем. Для этих целей внутри структуры выделяется специальное поле, содержащее некоторое нетривиальное значение, которое устанавливается на этапе инициализации объекта конструктором, а затем проверяется всеми функциями, работающими с объектом. Если там отличное от ожидаемого значение – значит нам дали объект неправильного типа либо где-то произошло затирание чужой памяти. Также понятно, что после того, как программа отлажена, весь этот функционал нужно удалить. Динамическими методами конфигурирования задача не решается, т.к. после определения sizeof-ов всех структур, что-то из них удалить и уменьшить размеры уже невозможно.
Возможны различные реализации этого механизма. Например, во время инициализации, вместо того, чтобы просто устанавливать какое-то magic-значение, можно, пользуясь адресом этого поля, которое находится в объекте, добавлять объект в какой-нибудь «пул существующих в системе валидных объектов». Если пришел какой-то адрес, а его в «пуле» нет, значит объект невалиден.
«Классические» методы решения этой задачи имеют недостатки. В частности, включение/отключение может быть реализовано с помощью #ifdef, но использование разных реализаций уже требует взаимодействия с системой сборки. Если соответствующие дефайны действуют также и на систему сборки, все равно добавить какой-то новый вариант не так просто, т.к. систему конфигурирования надо «научить» этому новому варианту (прописать имена файлов для компиляции в конфиги + зависимости). Рассмотрим, как можно сделать «открытую» для конфигурирования систему.
Начнем с интерфейса модуля, реализующего нужные нам функции. Интерфейс модуля, то есть то, что дожно содержаться в его хидере, включает некоторый тип данных, который должен расширять защищаемые объекты, а также набор функций для инициализации этого типа данных и для проверки.
/*Встраиваемый в защищаемые классы объект.*/
typedef struct _runtime_protection
{
int magic_cookie;
} runtime_protection, *pruntime_protection;
/*Интерфейсные функции.*/
void runtime_protection_init(pruntime_protection object, int cookie);
int runtime_protection_check(pruntime_protection object, int cookie);
/*Метка интерфейса.*/
#pragma fx interface RUNTIME_PROTECTION:VER1
Его реализация не важна, важно то, что если кто-то использует такой хидер, то реализация попадет в билд автоматически. Понятие «интерфейс» здесь используется в широком смысле, в отличие от определения в стиле ООП: под «интерфейсом» имеется ввиду некоторое соглашение, а не только набор и сигнатуры функций. В частности, тип данных «runtime_protection» является частью интерфейса RUNTIME_PROTECTION, то есть все хидеры, имеющие такую прагму, обязаны как-то определять такой тип данных (не обязательно как структуру).
Модули, использующие такую защиту, должны, перед тем как использовать упомянутые типы данных и функции, сделать импорт интерфейса:
/*Включение интерфейса по абстрактному имени.*/
#include FX_INTERFACE(RUNTIME_PROTECTION, DEFAULT)
/*«Магическое» значение для защиты объекта.*/
enum { MAGIC_VALUE_SOME_OBJECT = 0x11223344 };
/*Защищаемый объект включает в себя компонент для защиты.*/
typedef struct some_object
{
int dummy;
runtime_protection rtp;
}
some_object, *psome_object;
/*Приведение типа к включенному подклассу.*/
#define some_object_as_rtp(so) (&((so)->rtp))
/*Метка интерфейса для some_object.*/
#pragma fx interface SOME_OBJECT:VER1
Реализация объекта просто использует функции, не задумываясь о том, чем они являются и откуда берутся:
/*Включение своего хидера.*/
#include FX_INTERFACE(SOME_OBJECT, VER1)
/*Метка реализации для some_object.*/
#pragma fx implementation SOME_OBJECT:VER1
void some_object_init(psome_object object)
{
/*Инициализация «магического» значения внутри структуры.*/
runtime_protection_init(
some_object_as_rtp(object),
MAGIC_VALUE_SOME_OBJECT);
…
}
void some_object_method(psome_object object)
{
/*Динамическая проверка типа.*/
If(!runtime_protection_check(
some_object_as_rtp(object),
MAGIC_VALUE_SOME_OBJECT))
{
//Error! Invalid object.
}
}
В случае, если мы хотим отключить проверки типов, надо написать интерфейс-заглушку вроде:
typedef struct _runtime_protection
{}
runtime_protection, *pruntime_protection;
#define runtime_protection_init(obj, magic)
/*Проверка всегда удачна, если защита отключена.*/
#define runtime_protection_check (1)
/*Экспорт другой реализации интерфейса RUNTIME_PROTECTION.*/
#pragma fx interface RUNTIME_PROTECTION:STUB
Хотя это и не по стандарту, но некоторые компиляторы для С делают sizeof пустых структур равным нулю (по стандарту, sizeof не может быть равным нулю, но, по тому же стандарту, пустая структура в С — это ошибка). Если требуется строгое следование букве стандарта, тогда можно либо обернуть объявление структуры макросом, либо смириться с некоторыми накладными расходами и написать там int dummy.
Если в качестве интерфейса по умолчанию используется заглушка, это становится синтаксически экивалентно отсутствию каких-либо проверок, если обработка ошибок не обернута, это приведет к условиям вроде if(true), которые должны быть оптимизированы компилятором. Теперь можно писать различные варианты такого модуля, причем исходники, которые используют этот интерфейс не потребуют вообще никаких изменений. Изменяя только файл отображения, автоматически будут меняться как хидеры, так и списки файлов для компиляции и сборки.
FX-DJ
Финалом наших изысканий (который, в данный момент, можно показать публике) стал инструмент FX-DJ, FX – потому что изначально он предназначался исключительно для конфигурирования FX-RTOS — другого нашего проекта, и все инструменты были с префиксом FX (почему сама ОС так называется, это тема другого разговора). Ну а DJ, как вы могли догадаться, означает Dependency inJector, а вовсе не DJ, хотя определенные параллели с диджеями по части выполняемых задач все-таки есть.
Он представляет собой дополнительную фазу сборки, выполняющуюся до компиляции – configuration-фазу, когда из некоего абстрактного пула исходников-компонентов по неким правилам формируется иерархическая система, основанная на зависимостях, в результате которой определяются списки файлов, которые надо собрать, после чего происходят, как обычно, фазы компиляции и компоновки. Поддерживается вывод списка файлов для компиляции как в виде плоского списка для использования каким-то внешним инструментом, так и в формате make.
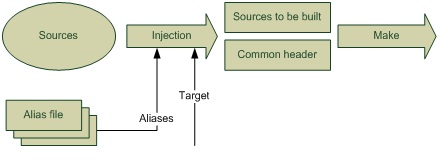
Весь процесс можно изобразить примерно так:

Alias files – это те самые файлы, отображающие default-интерфейсы на конкретные. Каждый из них соответствует определенной конфигурации. Target – целевой интерфейс, тот, который в корне дерева зависимостей.
Пока это все сделано в виде компактного скрипта на Python 2.7 (в комплект входит также скомпилированный с помощью py2exe исполняемый файл, не требующий установленного Python). Инструмент распространяется под модифицированной BSD-лицензией, поэтому делать с ним можно практически все что угодно и бесплатно. Хотя всё уже опубликовано, в целом все пока находится в состоянии alpha-version, «блог компании» находится в процессе покупки, поэтому пока поговорим только о концепциях, а ссылки на скачивание будут позже.
Если тема окажется интересной, расскажу в следующей статье об FX-RTOS: зачем нужна «еще одна» операционная система, идеях, лежащих в ее основе, «почему это нельзя было сделать на основе линукса» и т.д.
Заключение
Последнее время тема модулей в С/C++ поднимается регулярно, начиная от обсуждения их в комитете по стандартизации С++ и заканчивая предложениями Apple по их поддержке в LLVM. В посте описан еще один взгляд на данную проблему и способы ее решения. Получившийся вариант обладает, безусловно, определенными недостатками, однако не требует никаких синтаксических изменений в языке, может применяться в любых проектах уже сейчас и решает те задачи, для решения которых создавался: создание программных модулей уровня исходных текстов, независимость от структуры папок конкретного проекта, включение/отключение/замена модулей без изменений в исходниках, автоматическое управление сборкой без необходимости описания зависимостей вручную, кроссплатформенность, 100% совместимость со стандартом и т.д.
На этом пока все. Всем спасибо за внимание.
