Предпринимая попытки постичь DDD вы наверняка натолкнетесь на этот паттерн, который часто тесно используется вместе с другим, не менее интересным, паттерном «Репозиторий». Этот паттерн предоставляет возможность описывать требования к бизнес-объектам, и затем использовать их (и их композиции) для фильтрации не дублируя запросы.
Давайте для примера спроектируем домен для простого группового чата: у нас будут три сущности: Группа и Пользователь, между которыми связь многие-ко-многим (один пользователь может находиться в разных группах, в группе может быть несколько пользователей) и Message представляющий собой сообщение, которое пользователь может написать в какой-либо группе:
Теперь представьте, что вы пишите два метода в Application Service:
Вы можете позволить сервисам самим строить запросы поверх репозитария:
Минусы:
Открытие объекта запроса наружу для репозитория сравнимо с открытием магазина торгующего оружием без требования лицензии у покупателей — вы просто не уследите за всеми и кто-нибудь обязательно кого-нибудь пристрелит. Расшифрую аналогию: у вас почти наверняка будет очень много схожих запросов поверх Query в разных частях сервиса(ов) и если вы решите добавить новое поле (к примеру, дополнительно фильтровать группы по признаку IsDeleted, а пользователей по признаку IsBanned) и учитывать его при многих выборках — вы рискуете пропустить какой-нибудь метод.
Можно просто описать в контракте репозитария все методы, которые нужны для сервисов спрятав в них фильтрацию, реализация будет выглядить так:
Минусы:
Это реализация лишена недостатка первой, но имеет свой — постепенно ваш репозитарий будет разрастаться и распухать и, в конце концов, превратится во что-то слабо поддерживаемое.
Тут на помощь к нам и приходит паттерн Спецификация, благодаря которому наш код будет выглядеть так:
Получаем двойной профит: репозитарий чист аки слеза младенца и не распухает, а в сервисах нет дублирования запросов и риска пропустить где-нибудь условие, к примеру если вы решите фильтровать группы везде по признаку IsDeleted – вам будет достаточно добавить это условие один раз в спецификации MemberSpecs .FromGroup
Мартин Фаулер (и Эрик Эванс) предложил следующий интерфейс спецификации:
Ребята из linqspecs.codeplex.com cделали его более дружественным к репозитарию (его конкретным реализациям на основе EF, nHibernate и т.п.) и даже серилизуемыми:
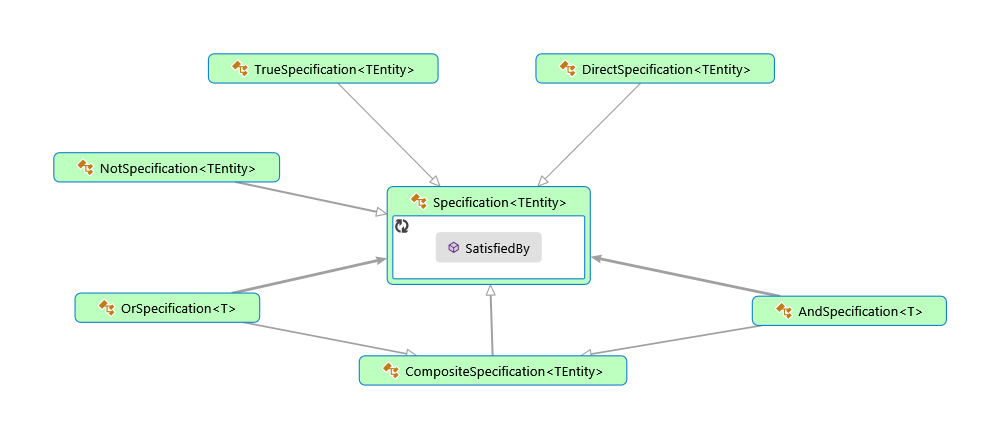
Благодаря ExpressionTree репозиторий сможет распарсить выражение и транслировать его в SQL или во что-либо ещё. Базовая реализация c основными логическими элементами выглядит так:
Теперь нам осталось лишь для каждой сущности (агрегата) написать статический класс, содержащий спецификации. Для нашего примера он будет выглядеть следующим образом:
Вот таким образом мы избавились от дублирования условий даже в нашем небольшом примере, но по настоящему оценить это можно на больших проектах со сложной логикой. В этом и беда DDD, что его объясняют всегда на небольших примерах и трудно отделаться от мысли, что всё это оверинженеринг.
Отличный пример, откуда были взяты реализации спецификаций находится здесь. Так же обращаю внимание на эту статью на хабре со списком литературы по DDD.
Пример
Давайте для примера спроектируем домен для простого группового чата: у нас будут три сущности: Группа и Пользователь, между которыми связь многие-ко-многим (один пользователь может находиться в разных группах, в группе может быть несколько пользователей) и Message представляющий собой сообщение, которое пользователь может написать в какой-либо группе:
public class Member
{
public string Nick { get; set; }
public string Country { get; set; }
public int Age { get; set; }
public ICollection<Group> Groups { get; set; }
public ICollection<Message> Messages { get; set; }
}
public class Message
{
public string Body { get; set; }
public DateTime Timestamp { get; set; }
public Member Author { get; set; }
}
public class Group
{
public string Name { get; set; }
public string Subject { get; set; }
public Member Owner { get; set; }
public ICollection<Message> Messages { get; set; }
public ICollection<Member> Members { get; set; }
}
Теперь представьте, что вы пишите два метода в Application Service:
/// <summary>
/// Все участники из заданой группы, указавшие заданую страну в профиле
/// </summary>
public ICollection<Member> GetMembersInGroupFromCountry(string groupName, string country)
{
}
/// <summary>
/// Все участники из заданой группы, которые не написал ни одного сообщения в указаный период времени
/// </summary>
public ICollection<Member> GetInactiveMembersInGroupOnDateRange(string groupName, DateTime start, DateTime end)
{
}Реализация 1 (плохая):
Вы можете позволить сервисам самим строить запросы поверх репозитария:
public ICollection<Member> GetMembersInGroupFromCountry(string groupName, string country)
{
return _membersRepository.Query.Where(m => m.Groups.Any(g => g.Name == groupName) && m.Country == country);
}
public ICollection<Member> GetInactiveMembersInGroupOnDateRange(string groupName, DateTime start, DateTime end)
{
return _membersRepository.Query.Where(m => m.Groups.Any(g => g.Name == groupName) &&
!m.Messages.Any(msg => msg.Timestamp > start && msg.Timestamp < end));
}
Минусы:
Открытие объекта запроса наружу для репозитория сравнимо с открытием магазина торгующего оружием без требования лицензии у покупателей — вы просто не уследите за всеми и кто-нибудь обязательно кого-нибудь пристрелит. Расшифрую аналогию: у вас почти наверняка будет очень много схожих запросов поверх Query в разных частях сервиса(ов) и если вы решите добавить новое поле (к примеру, дополнительно фильтровать группы по признаку IsDeleted, а пользователей по признаку IsBanned) и учитывать его при многих выборках — вы рискуете пропустить какой-нибудь метод.
Реализация 2 (неплохая):
Можно просто описать в контракте репозитария все методы, которые нужны для сервисов спрятав в них фильтрацию, реализация будет выглядить так:
public ICollection<Member> GetMembersInGroupFromCountry(string groupName, string country)
{
return _membersRepository. GetMembersInGroupFromCountry(groupName, country);
}
public ICollection<Member> GetInactiveMembersInGroupOnDateRange(string groupName, DateTime start, DateTime end)
{
return _membersRepository. GetInactiveMembersInGroupOnDateRange(groupName, start, end);
}
Минусы:
Это реализация лишена недостатка первой, но имеет свой — постепенно ваш репозитарий будет разрастаться и распухать и, в конце концов, превратится во что-то слабо поддерживаемое.
Реализация 3 (отличная):
Тут на помощь к нам и приходит паттерн Спецификация, благодаря которому наш код будет выглядеть так:
public ICollection<Member> GetMembersInGroupFromCountry(string groupName, string country)
{
return _membersRepository.AllMatching(MemberSpecifications.Group(groupName) &&
MemberSpecs.FromCountry(country));
}
public ICollection<Member> GetInactiveMembersInGroupOnDateRange(string groupName, DateTime start, DateTime end)
{
return _membersRepository.AllMatching(MemberSpecifications.Group(groupName) &&
MemberSpecs.InactiveInDateRange(start, end));
}
Получаем двойной профит: репозитарий чист аки слеза младенца и не распухает, а в сервисах нет дублирования запросов и риска пропустить где-нибудь условие, к примеру если вы решите фильтровать группы везде по признаку IsDeleted – вам будет достаточно добавить это условие один раз в спецификации MemberSpecs .FromGroup
Реализация паттерна
Мартин Фаулер (и Эрик Эванс) предложил следующий интерфейс спецификации:
public abstract class Specification<T>
{
public abstract bool IsSatisfiedBy(T entity);
}
Ребята из linqspecs.codeplex.com cделали его более дружественным к репозитарию (его конкретным реализациям на основе EF, nHibernate и т.п.) и даже серилизуемыми:
public abstract class Specification<T>
{
public abstract Expression<Func<T, bool>> IsSatisfiedBy();
}
Благодаря ExpressionTree репозиторий сможет распарсить выражение и транслировать его в SQL или во что-либо ещё. Базовая реализация c основными логическими элементами выглядит так:

Теперь нам осталось лишь для каждой сущности (агрегата) написать статический класс, содержащий спецификации. Для нашего примера он будет выглядеть следующим образом:
public static class MemberSpecifications
{
public static Specification<Member> Group(string groupName)
{
return new DirectSpecification<User>(member =>
member.Groups.Any(g => g.Name == groupName));
}
public static Specification<Member> Country(string country)
{
return new DirectSpecification<User>(member =>
member.Country == country);
}
public static Specification<Member> InactiveSinceTo(DateTime start, DateTime end)
{
return new DirectSpecification<User>(member =>
member.Messages.Any(msg => msg.Timestamp > start && msg.Timestamp < end));
}
}
Заключение
Вот таким образом мы избавились от дублирования условий даже в нашем небольшом примере, но по настоящему оценить это можно на больших проектах со сложной логикой. В этом и беда DDD, что его объясняют всегда на небольших примерах и трудно отделаться от мысли, что всё это оверинженеринг.
Ссылки
Отличный пример, откуда были взяты реализации спецификаций находится здесь. Так же обращаю внимание на эту статью на хабре со списком литературы по DDD.
