
Уже 2 месяца использую на своих компьютерах модуль zRam и хочу поделиться результатами. На практике он позволил мне не используя раздел подкачки, и не получая видимого замедления работы компьютера увеличить размер оперативной памяти в 2.5-3 раза. На сервере виртуалок тот же подход позволил очень ощутимо увеличить отзывчивость при нехватке памяти.
Заинтересовавшихся прошу под кат.
Как говорит Википедия
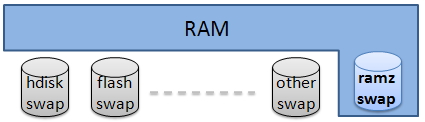
zRam это экспериментальный модуль ядра Linux (ранее известный как «compcache»). Он увеличивает производительность путем предотвращения подкачки страниц на диск, используя сжатое блочное устройство в оперативной памяти, пока не появится необходимость использовать файл подкачки на жестком диске. Скорость обмена с оперативной памятью быстрее, чем с жестким диском, следовательно zRam позволяет Linux производить большее число операций подкачки, особенно на старых компьютерах с малым объемом оперативной памяти.
Для пользователя все выглядит так: для начала нужно загрузить модуль (предварительно скомпилировав если он отсутствует)
modprobe zram num_devices=4
В num_devices задается количество сжатых блочных устройств, которое будет создано.
Для наиболее оптимального использования CPU стоит учесть: сжатие каждого устройства zram однопоточное. Потому я создаю их по количеству ядер.
При настройке модуля задается фиксированный размер НЕ сжатых данных в байтах
SIZE=1536
echo $(($SIZE*1024*1024)) > /sys/block/zram0/disksize
echo $(($SIZE*1024*1024)) > /sys/block/zram1/disksize
echo $(($SIZE*1024*1024)) > /sys/block/zram2/disksize
echo $(($SIZE*1024*1024)) > /sys/block/zram3/disksize
В итоге будет создано устройство /dev/zram0 заданного размера
Disk /dev/zram0: 1610 MB, 1610612736 bytes, 393216 sectors
Units = sectors of 1 * 4096 = 4096 bytes
Sector size (logical/physical): 4096 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytesДанные записанные на него будут прозрачно сжаты в памяти. Что делать с ним далее — уже ваш выбор, я на этих устройствах создаю разделы подкачки.
mkswap /dev/zram0
mkswap /dev/zram1
mkswap /dev/zram2
mkswap /dev/zram3
swapon /dev/zram0 -p 10
swapon /dev/zram1 -p 10
swapon /dev/zram2 -p 10
swapon /dev/zram3 -p 10
Далее уже ядро думает само какие данные туда складывать в зависимости от того как часто вы к ним обращаетесь и как много памяти свободно.
Мой опыт показывает, что степень сжатия обычно 1 к 3.
На практике это позволило на ноутбуке в 8Gb памяти вынести компиляцию libreoffice в tmpfs. (она требует 7 Гбайт временных файлов и примерно 1 Гбайт памяти потребляет каждый поток gcc при сборке).
Область применения такой идеи крайне широка:
- нетбуки: у девушки ноутбук в двух-ядерным Atom-мом. И всего лишь 2 гигабайта оперативной памяти (больше не вставить). В итоге одна «наглая рыжая морда» все время съедала всю память и посылала машину в swap. Подключил zRam и девушка довольна
- Сервера виртуализации: прозрачное сжатие памяти виртуальных машин может позволить выполнять большее число виртуальных машин одновременно: у нас есть сервер используемый для тестирования веб-приложения под различными конфигурациями клиентов (операционки, браузеры, версии плагинов к браузерам, настройки локалей и кодировок). Прохождение тестов на нем всегда было «задумчивым» процессом. Использование zRam позволило уменьшить время прохождение тестов с 30 минут до 18
Дополнение:
Изначально разработка велась под названием compcache, и первые рабочие версии были сделаны для ядра 2.6.26(Июль 2008)
Начиная с декабря 2009 года и ядра 2.6.33 оно доступно в ядре, в разделе Staging. Для более старый ядер патчи все еще доступны на вышеуказанном сайте.
В ядре 3.8 должно было быть вынесено из Staging, но это не произошло.
