Redis это размещаемое в памяти хранилище ключ-значение, обычно используемое для кэшей и подобных механизмов ускорения сетевых приложений. Мы, тем не менее, храним все наши данные в Redis — в нашей главной базе данных.
Сеть полна предупреждений и предостерегающих повествований об использовании подобного подхода. Есть ужасающие истории о потере данных, исчерпании памяти или людях неспособных эффективно управлять данными в Redis, вы, возможно, интересуетесь «О чём вы вообще думаете?». Так вот, наш рассказ, почему мы всё же решили использовать Redis и как мы преодолели все эти проблемы.
Прежде всего, я хотел бы подчеркнуть что большинство приложений вовсе не должны обращать внимания на костыли использованные, что бы пойти таким путём. Это было важно для нашего сценария использования, но мы можем быть граничным случаем.
Redis быстр. Когда я говорю быстр, я имею в виду Быстр с заглавной буквы Б. Это по существу memcached с более продуманными типами данных, нежели просто строковые значения. Даже некоторые продвинутые операции такие, как пересечение множеств, выборка диапазонов zset, ослепительно быстры. Есть все поводы использовать Redis для быстроменяющихся активно запрашиваемых данных. Он довольно часто используется в качестве кэша, который может быть перестроен по данным из резервной базы данных. Это мощная замена memcached предоставляющая более продвинутое кэширование для различных видов хранимых вами данных.
Как и в memcached, всё находится в памяти. Redis сохраняется на диск, но он не сохраняет данные синхронно с тем как вы записываете их. Есть две причины из-за которых Redis в качестве главного хранилища — отстой:
— Вы вынуждены умещать все свои данные в памяти, и…
— Если сервер откажет между двумя синхронизациями с диском — вы потеряете всё что сидело в памяти.
Из-за этих двух проблем Redis обосновался в компактной нише в качестве временного кэша для данных которыми вы можете пожертвовать, но не главного хранилища данных. Предоставляя быстрый доступ к часто необходимым данным с возможностью перестроения при необходимости.
Недостаток использования более традиционных хранилищ за Redis заключается в затыке с производительностью этих хранилищ. Вам приходится жертвовать производительностью чтобы убедиться, что данные сохранены на диск. Совершенно нормальная сделка для почти каждого приложения. Вы можете получить великолепную производительность по чтению и «хорошую» производительность по записи. Я должен пояснить, что «хорошая» для меня вполне вероятно может быть безумно быстрая для большинства людей. Достаточно сказать, что «хорошая» производительность по записи должна удволетворить большинство, кроме самых высоко нагруженных приложений.
Я полагаю, что вы можете выполнить запрос на запись в Redis а потом сохраниться при помощи реляционного хранилища, но тогда остаются те же риски падения Redis и потери данных очереди записи.
Moot предлагается как полностью бесплатный продукт. Нам, таким образом, необходимо иметь возможность обрабатывать крупные нагрузки на очень небольшом количестве железа. Если нам нужна куча больших баз данных для форума обслуживающего несколько миллионов пользователей в месяц, то нет никаких способов остаться бесплатным сервисом. Поскольку мы хотим, что бы Moot был и бесплатным и неограниченным, мы вынуждены были оптимизировать до предела.
Мы могли бы просто избежать этого установив какие-нибудь ограничения на бесплатные сервисы и брать деньги за просмотр страниц или постов. Не знаю как вы, но я, в общем, не люблю продукты, которые бесплатны «пока вы не раскрутитесь». Скажем, вы настроили форум, а потом что-то на вашем сайте станет вирусным. Внезапно, вас ошарашат счётом за превышение бесплатного уровня. И вот то, что начиналось как развлечение, из-за внезапной популярности вашего блога о теории заговоров, превращается в ужас грядущего счёта. Вас наказывают за ваш успех. Это то, чего мы хотели бы избежать.
Мы так же могли бы решить монетизироваться размещая рекламу, и позволив себе более высокие эксплуатационные расходы. Это, тем не менее, полностью расходится с нашим базовыми ценностями как бизнеса. По нашему мнению, если кто-то собирается размещать рекламу на вашем сайте, это должны быть вы а не мы. Moot должен предлагаться без условий, ограничений и приписок.
Принимая во внимание всё вышесказанное, необходимо достичь непревзойдённой производительности для постинга и чтения не взирая на инженерные сложности. Это базис для нашей возможности работать. У нас была изначальная цель, чтобы все вызовы API обрабатывались менее чем за 10мс даже под высокой нагрузкой, и даже тогда, когда обрабатываются большие сложные списки или поиски. Redis, очевидно, может обеспечить нам такую производительность, но две большие проблемы никуда не делись: Как, блин, мы сможем использовать Redis, если у нас могут быть сотни гигабайт данных, и что делать с падением сервера?
Так началось наше исследование способов проектирования с учётом этих ограничений. У нас с самого начала было точное понимание какими будут задачи у Moot, и наших ценностей как компании, поэтому нам повезло иметь возможность обдумать эти особенности до написания первых строчек кода. Я полагаю что эти проблемы были бы чрезмерно сложны, если бы мы решили пойти этим путём, имея множество готового кода.
Это самая сложна из двух проблем. Количество памяти, которое может быть на одном компьютере, конечно. Наибольшее количество на EC2 это 244-гигабайтный сервер. Хотя это по прежнему конечный объём, это довольно хороший лимит для начала. К сожалению, при этом ваш 16-ядерный сервер будет использовать только одно ядро для Redis. Что ж, как на счёт добавления по подчинённому процессу Redis на каждое ядро? Тогда у вас осталось по 15 ГБ памяти на каждый экземпляр. Опять фигня! Это плохое ограничение, если вы хотите иметь возможность выжать из сервера мощность. Это не достаточно данных для сервиса хостинга.
Мы решили спроектировать наше Redis-хранилище с самого начала разделённым среди множества Redis кластеров. Мы хэшируем и разделяем данные в блоки содержащие все структуры, относящиеся к данному сегменту данных. Данные сильно разделены с самого начала и мы можем по необходимости создавать новые блоки быстро и просто.
Для разбивки данных мы храним таблици хэшей и адресов примерно так:
Когда поступают данные, мы вычисляем хэш на основе наших требований к связности данных, потом мы проверяем в shards.map был ли он назначен какому-нибудь блоку, и если да — мы можем направить вызовы на тот блок.
Если хэш ещё не приписан к какому либо блоку, мы создаём список доступных блоков множа их в соответствии с весом. Если например выполнить:
Список будет выглядеть как-то так:
После этого мы назначаем случайный блок из списка, сохраняем в карту распределения и идём далее.
Применяя такую схему мы можем легко контролировать сколько данных поступает в блоки, добавлять новые блоки или даже исключать блоки из рассмотрения, если видим, что они заполнены.
Реально мы начали с сотен блоков так что нечего беспокоиться о нагрузке на сервера и ограничениях памяти.
Отдельные блоки остаются очень малыми. Один сервер содержит много блоков в базах данных Redis и, если эти блоки увеличиваются в размерах, мы легко можем разделить базы Redis на независимые экземпляры. Скажем у нас экземпляр Redis с 100 блоками, мы видим, что некоторые блоки увеличиваются в размере и мы разделяем Redis на два экземпляра по 50 блоков каждый. Мы можем точно настроить веса чтобы поддерживать распределение между блоками в реальном времени.
Самая сложная часть, это точно определить то, как вы сегментируете ваши данные. Это очень специфично и наш вариант сегментации, возможно, тема для отдельного поста.
Такая стратегия хранения должна разрабатываться в приложении с самого начала. Часто люди пытаются разделять данные, которые так не спроектированы, в этом то и загвоздка для их использования Redis. Поскольку мы чётко знали, что ограничение памяти будет проблемой, мы смогли спроектировать решение в самом ядре нашей системы управления данными, ещё до того как мы написали хоть одну строчку кода.
Разобраться с отказами оказалось, смешно сказать, легче. У нас для кластера Redis было 3 разные роли:
— Мастер, где происходили почти все операции на запись,
— Подчинённый, гда происходили почти все чтения,
— Хранитель, выделенный для сохранения данных.
Мастер и подчинённый работают в общем как и любые другие в кластере Redis. В этом нет ничего интересного. Что мы сделали нового, это то что в каждом кластере есть по 2 сервера, используемых в качестве хранителей. Эти сервера:
— Не принимают никаких входящих соединений и не несут никакой нагрузки Redis запросов, кроме простой репликации
— Хранение AOF в ежесекундном режиме
— Ежечасный снимок RDB
— Синхронизируют AOF и RDB в S3
В виду того, что параметры производительности для хранения могут несколько различаться, один сервер хранитель может обработать различное количество блоков. Мы просто запускаем по одному экземпляру на каждый блок, который должен храниться. Другими словами, нет необходимости в отношении 1 к 1 между блоками и серверами с ролью хранителя.
У нас два этих сервера расположены в различных зонах доступности, так что даже если одна из зон выходит из строя, у нас есть работающий актуальный сервер-хранитель.
Таким образом, чтобы нам потерять данные необходим довольно большой отказ в EC2 и даже тогда, мы потеряем только около секунды данных.
Если вы рассматриваете сценарий нарушения связности сети, когда мастер может быть изолирован от подчинённых, его можно нивелировать проверкой репликации подчинённых(установить произвольный ключ в произвольное значение и проверить, обновились ли данные у подчинённого) Если мастер изолирован, мы останавливаем запись: Согласованность и Устойчивость к потере связности за счёт Доступности. Redis Sentinel тоже мог бы помочь нам с этим, но Sentinel был выпущен позже того, как мы реализовали большую часть системы. Мы не исследовали, как Sentinel мог бы вписаться бы в наше уравнение.
В конце концов, мы смогли построить систему, которая под нагрузкой выполняет вызовы API за приблизительно 2 мс.
Значение 2 мс — при обслуживании нашего самого тяжёлого API-вызова, инициализационного API-вызова.
Многие наши запросы обслуживаются гораздо быстрее ( лайки например часто за 0.6-0.7 мс). Мы можем исполнять 1000 API запросов в секунду на одном API сервере. И для построения страницы требуется один API вызов. В замер включены все наши проверки данных, управление блоками, аутентификация, управление сессиями, соединениями, сериализация JSON и так далее.
Серверы API, которые позволяют работать с такой нагрузкой, стоят всего $90 в месяц, так что мы можем поддерживать и горизонтально масштабировать довольно большие нагрузки по очень маленькой цене. Другая побочная польза от сильно разделённых на блоки данных, это то что горизонтальное масштабирование выполняется тривиально.
Многое из этого заслуга не только ЭТИХ решений для Redis. Есть ещё несколько трюков для того, чтобы система производительно работала под высокой параллельной нагрузкой. Один из этик трюков в том, что почти половина нашего кода написана на Lua и работает прямо в Redis. Это другая вещь, которую в общем говорят не делать. Что касается того, как и почему у нас тысячи строк кода на Lua — подождите следующего поста о нашем применении Redis.
Взгляните на нашу реальную производительность, мы запустились пару дней назад, и получили неплохой начальный всплеск. Мы обслуживали 50 API вызовов в секунду и процессор нашего главного API сервера (мы до сих пор посылаем весь трафик на один) был полностью в простое. Вот графики, начиная с нашего запуска до момента написания поста.
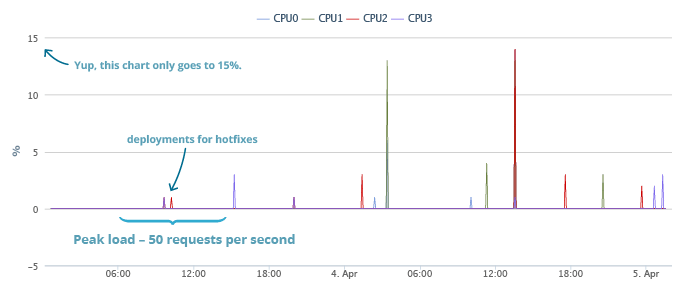
Пояснение: я ссылаюсь на API сервер как на замеряемый, так как наш сервер приложений и Redis сервер это одно и тоже. API сервер несёт на себе как несколько блоков, так и приложение. Идея была в том, чтобы маршрутизировать трафик на сервер где в основном расположен этот блок, чтобы воспользоваться unix-сокетами для подключения к Redis. Это позволят избегать излишнего сетевого трафика поэтому нет особого различия между Сервером приложений, Redis мастером и Redis подчинённым. Любой API сервер может обработать любой запрос, просто мы даём гораздо больший приоритет мастер серверу задействованного сегмента данных. Все серверы — серверы приложений, и все серверы — мастера для каких-то блоков и подчинённые для других.
tl;dr
Есть множество причин не использовать Redis как главное хранилище на жёстком диске, но если, по каким-то причинам, ваш вариант использования требует этого, вам необходимо начинать с самого начала. Вам стоит проектировать ваши данные разделёнными и помнить о дополнительной стоимости выделенных серверов хранения.
ПОПРАВКА
Я только что понял, что я посчитал стоимость отдельного сервера и забыл добавить амортизированную единовременную стоимость зарезервированных экземпляров. Должно быть $213.
Сеть полна предупреждений и предостерегающих повествований об использовании подобного подхода. Есть ужасающие истории о потере данных, исчерпании памяти или людях неспособных эффективно управлять данными в Redis, вы, возможно, интересуетесь «О чём вы вообще думаете?». Так вот, наш рассказ, почему мы всё же решили использовать Redis и как мы преодолели все эти проблемы.
Прежде всего, я хотел бы подчеркнуть что большинство приложений вовсе не должны обращать внимания на костыли использованные, что бы пойти таким путём. Это было важно для нашего сценария использования, но мы можем быть граничным случаем.
Redis как хранилище данных
Redis быстр. Когда я говорю быстр, я имею в виду Быстр с заглавной буквы Б. Это по существу memcached с более продуманными типами данных, нежели просто строковые значения. Даже некоторые продвинутые операции такие, как пересечение множеств, выборка диапазонов zset, ослепительно быстры. Есть все поводы использовать Redis для быстроменяющихся активно запрашиваемых данных. Он довольно часто используется в качестве кэша, который может быть перестроен по данным из резервной базы данных. Это мощная замена memcached предоставляющая более продвинутое кэширование для различных видов хранимых вами данных.
Как и в memcached, всё находится в памяти. Redis сохраняется на диск, но он не сохраняет данные синхронно с тем как вы записываете их. Есть две причины из-за которых Redis в качестве главного хранилища — отстой:
— Вы вынуждены умещать все свои данные в памяти, и…
— Если сервер откажет между двумя синхронизациями с диском — вы потеряете всё что сидело в памяти.
Из-за этих двух проблем Redis обосновался в компактной нише в качестве временного кэша для данных которыми вы можете пожертвовать, но не главного хранилища данных. Предоставляя быстрый доступ к часто необходимым данным с возможностью перестроения при необходимости.
Недостаток использования более традиционных хранилищ за Redis заключается в затыке с производительностью этих хранилищ. Вам приходится жертвовать производительностью чтобы убедиться, что данные сохранены на диск. Совершенно нормальная сделка для почти каждого приложения. Вы можете получить великолепную производительность по чтению и «хорошую» производительность по записи. Я должен пояснить, что «хорошая» для меня вполне вероятно может быть безумно быстрая для большинства людей. Достаточно сказать, что «хорошая» производительность по записи должна удволетворить большинство, кроме самых высоко нагруженных приложений.
Я полагаю, что вы можете выполнить запрос на запись в Redis а потом сохраниться при помощи реляционного хранилища, но тогда остаются те же риски падения Redis и потери данных очереди записи.
Что нам нужно?
Moot предлагается как полностью бесплатный продукт. Нам, таким образом, необходимо иметь возможность обрабатывать крупные нагрузки на очень небольшом количестве железа. Если нам нужна куча больших баз данных для форума обслуживающего несколько миллионов пользователей в месяц, то нет никаких способов остаться бесплатным сервисом. Поскольку мы хотим, что бы Moot был и бесплатным и неограниченным, мы вынуждены были оптимизировать до предела.
Мы могли бы просто избежать этого установив какие-нибудь ограничения на бесплатные сервисы и брать деньги за просмотр страниц или постов. Не знаю как вы, но я, в общем, не люблю продукты, которые бесплатны «пока вы не раскрутитесь». Скажем, вы настроили форум, а потом что-то на вашем сайте станет вирусным. Внезапно, вас ошарашат счётом за превышение бесплатного уровня. И вот то, что начиналось как развлечение, из-за внезапной популярности вашего блога о теории заговоров, превращается в ужас грядущего счёта. Вас наказывают за ваш успех. Это то, чего мы хотели бы избежать.
Мы так же могли бы решить монетизироваться размещая рекламу, и позволив себе более высокие эксплуатационные расходы. Это, тем не менее, полностью расходится с нашим базовыми ценностями как бизнеса. По нашему мнению, если кто-то собирается размещать рекламу на вашем сайте, это должны быть вы а не мы. Moot должен предлагаться без условий, ограничений и приписок.
Принимая во внимание всё вышесказанное, необходимо достичь непревзойдённой производительности для постинга и чтения не взирая на инженерные сложности. Это базис для нашей возможности работать. У нас была изначальная цель, чтобы все вызовы API обрабатывались менее чем за 10мс даже под высокой нагрузкой, и даже тогда, когда обрабатываются большие сложные списки или поиски. Redis, очевидно, может обеспечить нам такую производительность, но две большие проблемы никуда не делись: Как, блин, мы сможем использовать Redis, если у нас могут быть сотни гигабайт данных, и что делать с падением сервера?
Что же теперь делать?
Так началось наше исследование способов проектирования с учётом этих ограничений. У нас с самого начала было точное понимание какими будут задачи у Moot, и наших ценностей как компании, поэтому нам повезло иметь возможность обдумать эти особенности до написания первых строчек кода. Я полагаю что эти проблемы были бы чрезмерно сложны, если бы мы решили пойти этим путём, имея множество готового кода.
Все данные в памяти. Блин.
Это самая сложна из двух проблем. Количество памяти, которое может быть на одном компьютере, конечно. Наибольшее количество на EC2 это 244-гигабайтный сервер. Хотя это по прежнему конечный объём, это довольно хороший лимит для начала. К сожалению, при этом ваш 16-ядерный сервер будет использовать только одно ядро для Redis. Что ж, как на счёт добавления по подчинённому процессу Redis на каждое ядро? Тогда у вас осталось по 15 ГБ памяти на каждый экземпляр. Опять фигня! Это плохое ограничение, если вы хотите иметь возможность выжать из сервера мощность. Это не достаточно данных для сервиса хостинга.
Мы решили спроектировать наше Redis-хранилище с самого начала разделённым среди множества Redis кластеров. Мы хэшируем и разделяем данные в блоки содержащие все структуры, относящиеся к данному сегменту данных. Данные сильно разделены с самого начала и мы можем по необходимости создавать новые блоки быстро и просто.
Для разбивки данных мы храним таблици хэшей и адресов примерно так:
shards.map = hash:{
'shard hash' : [shard id]
}
shards.[shard id] = hash:{
master : [master ip/port],
slave0 : [slave 0 ip/port],
slave1 : [slave 0 ip/port],
...
}
shards.list = zset:{
shard1:[weight],
shard2:[weight],
...
}
Когда поступают данные, мы вычисляем хэш на основе наших требований к связности данных, потом мы проверяем в shards.map был ли он назначен какому-нибудь блоку, и если да — мы можем направить вызовы на тот блок.
Если хэш ещё не приписан к какому либо блоку, мы создаём список доступных блоков множа их в соответствии с весом. Если например выполнить:
redis.call('zadd', 'shards.list', 1, 'shard1')
redis.call('zadd', 'shards.list', 2, 'shard2')
redis.call('zadd', 'shards.list', 1, 'shard3')
Список будет выглядеть как-то так:
[shard1, shard2, shard2, shard3]
После этого мы назначаем случайный блок из списка, сохраняем в карту распределения и идём далее.
Применяя такую схему мы можем легко контролировать сколько данных поступает в блоки, добавлять новые блоки или даже исключать блоки из рассмотрения, если видим, что они заполнены.
Реально мы начали с сотен блоков так что нечего беспокоиться о нагрузке на сервера и ограничениях памяти.
Отдельные блоки остаются очень малыми. Один сервер содержит много блоков в базах данных Redis и, если эти блоки увеличиваются в размерах, мы легко можем разделить базы Redis на независимые экземпляры. Скажем у нас экземпляр Redis с 100 блоками, мы видим, что некоторые блоки увеличиваются в размере и мы разделяем Redis на два экземпляра по 50 блоков каждый. Мы можем точно настроить веса чтобы поддерживать распределение между блоками в реальном времени.
Самая сложная часть, это точно определить то, как вы сегментируете ваши данные. Это очень специфично и наш вариант сегментации, возможно, тема для отдельного поста.
Такая стратегия хранения должна разрабатываться в приложении с самого начала. Часто люди пытаются разделять данные, которые так не спроектированы, в этом то и загвоздка для их использования Redis. Поскольку мы чётко знали, что ограничение памяти будет проблемой, мы смогли спроектировать решение в самом ядре нашей системы управления данными, ещё до того как мы написали хоть одну строчку кода.
Падения сервера
Разобраться с отказами оказалось, смешно сказать, легче. У нас для кластера Redis было 3 разные роли:
— Мастер, где происходили почти все операции на запись,
— Подчинённый, гда происходили почти все чтения,
— Хранитель, выделенный для сохранения данных.
Мастер и подчинённый работают в общем как и любые другие в кластере Redis. В этом нет ничего интересного. Что мы сделали нового, это то что в каждом кластере есть по 2 сервера, используемых в качестве хранителей. Эти сервера:
— Не принимают никаких входящих соединений и не несут никакой нагрузки Redis запросов, кроме простой репликации
— Хранение AOF в ежесекундном режиме
— Ежечасный снимок RDB
— Синхронизируют AOF и RDB в S3
В виду того, что параметры производительности для хранения могут несколько различаться, один сервер хранитель может обработать различное количество блоков. Мы просто запускаем по одному экземпляру на каждый блок, который должен храниться. Другими словами, нет необходимости в отношении 1 к 1 между блоками и серверами с ролью хранителя.
У нас два этих сервера расположены в различных зонах доступности, так что даже если одна из зон выходит из строя, у нас есть работающий актуальный сервер-хранитель.
Таким образом, чтобы нам потерять данные необходим довольно большой отказ в EC2 и даже тогда, мы потеряем только около секунды данных.
Если вы рассматриваете сценарий нарушения связности сети, когда мастер может быть изолирован от подчинённых, его можно нивелировать проверкой репликации подчинённых(установить произвольный ключ в произвольное значение и проверить, обновились ли данные у подчинённого) Если мастер изолирован, мы останавливаем запись: Согласованность и Устойчивость к потере связности за счёт Доступности. Redis Sentinel тоже мог бы помочь нам с этим, но Sentinel был выпущен позже того, как мы реализовали большую часть системы. Мы не исследовали, как Sentinel мог бы вписаться бы в наше уравнение.
Конечный результат
В конце концов, мы смогли построить систему, которая под нагрузкой выполняет вызовы API за приблизительно 2 мс.
Значение 2 мс — при обслуживании нашего самого тяжёлого API-вызова, инициализационного API-вызова.
Многие наши запросы обслуживаются гораздо быстрее ( лайки например часто за 0.6-0.7 мс). Мы можем исполнять 1000 API запросов в секунду на одном API сервере. И для построения страницы требуется один API вызов. В замер включены все наши проверки данных, управление блоками, аутентификация, управление сессиями, соединениями, сериализация JSON и так далее.
Серверы API, которые позволяют работать с такой нагрузкой, стоят всего $90 в месяц, так что мы можем поддерживать и горизонтально масштабировать довольно большие нагрузки по очень маленькой цене. Другая побочная польза от сильно разделённых на блоки данных, это то что горизонтальное масштабирование выполняется тривиально.
Многое из этого заслуга не только ЭТИХ решений для Redis. Есть ещё несколько трюков для того, чтобы система производительно работала под высокой параллельной нагрузкой. Один из этик трюков в том, что почти половина нашего кода написана на Lua и работает прямо в Redis. Это другая вещь, которую в общем говорят не делать. Что касается того, как и почему у нас тысячи строк кода на Lua — подождите следующего поста о нашем применении Redis.
Взгляните на нашу реальную производительность, мы запустились пару дней назад, и получили неплохой начальный всплеск. Мы обслуживали 50 API вызовов в секунду и процессор нашего главного API сервера (мы до сих пор посылаем весь трафик на один) был полностью в простое. Вот графики, начиная с нашего запуска до момента написания поста.
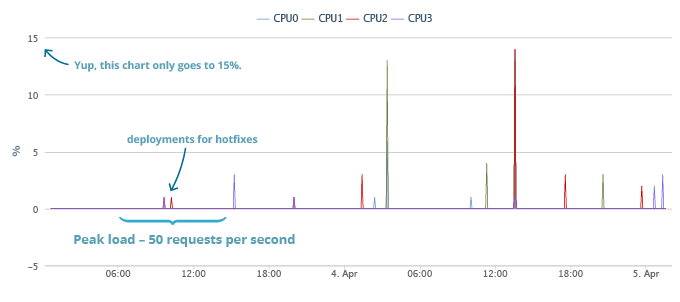
Во время наших пиковых нагрузок всё тихо. Вы можете заметить пару всплесков, когда мы накатывали хотфиксы, но в остальном ни шороха. Более поздние всплески соответствуют обновлениям системы, исправлениям и другим проводимым системным работам. Общая нагрузка так же включает увеличенные накладные расходы на логгирование которое мы вели в период начального бета теста.
Пояснение: я ссылаюсь на API сервер как на замеряемый, так как наш сервер приложений и Redis сервер это одно и тоже. API сервер несёт на себе как несколько блоков, так и приложение. Идея была в том, чтобы маршрутизировать трафик на сервер где в основном расположен этот блок, чтобы воспользоваться unix-сокетами для подключения к Redis. Это позволят избегать излишнего сетевого трафика поэтому нет особого различия между Сервером приложений, Redis мастером и Redis подчинённым. Любой API сервер может обработать любой запрос, просто мы даём гораздо больший приоритет мастер серверу задействованного сегмента данных. Все серверы — серверы приложений, и все серверы — мастера для каких-то блоков и подчинённые для других.
tl;dr
Есть множество причин не использовать Redis как главное хранилище на жёстком диске, но если, по каким-то причинам, ваш вариант использования требует этого, вам необходимо начинать с самого начала. Вам стоит проектировать ваши данные разделёнными и помнить о дополнительной стоимости выделенных серверов хранения.
ПОПРАВКА
Я только что понял, что я посчитал стоимость отдельного сервера и забыл добавить амортизированную единовременную стоимость зарезервированных экземпляров. Должно быть $213.
