У нас неплохо получается хранить фотографии, поэтому мы решили упростить жизнь и вам, если вы хотите соорудить свой tumblr, facebook или imgur. Дело на самом деле нехитрое, но есть тонкости, о которых лучше знать заранее. К тому же мы сделали всё на node.js, что не слишком характерно для хранилища с более чем 100 000 000 фотографий.

В open-source мы решили отдать ту часть инфраструктуры, которая непосредственно взаимодействует с дисками. Остальным у нас заведует nginx, и его улучшения уже либо в основной ветке nginx (прогрессивный jpeg в модуле image_filter и поддержка переменных в нём же), либо ждут своего часа в рассылке nginx-devel (возможность «прилипания» к определённому краю изображения при crop).
Хранилище подходит не только для фотографий, но и для любых данных, которые склонны к бесконечному сроку жизни и имеют конечный, достаточно малый размер. Хранить большие объёмы данных типа видео проще и выгоднее, просто укладывая его на файловую систему. Данные должны быть неизменяемыми. Если вы наложили фильтр на фотографию — сохраните под новым именем.
Во всей инфраструктуре нет единой точки отказа, так что попадание метеоритов в пару серверов для нас не является проблемой. Диски разваливаются куда чаще, чем хотелось бы, так что такая фича была заложена с самого начала.
Попробую рассказать вкратце о составных частях.
Ссылка на GitHub. Тут же можно узнать, как развернуть систему в целом.
Координаторы — уровень, с которым общается приложение для сохранения данных в сторадж. Умеет команды:
Инстансы координаторов равноправны и взаимозаменяемы, они заведуют шардингом данных, общаясь через zookeeper. Они знают, куда нужно положить следующую фотографию. Количество инстансов в шарде определяет количество копий данных, количество шардов и их размер — общий размер хранилища.
Шард — несколько инстансов backpack, имеющих одинаковый набор данных.
При загрузке фотографии в хранилище, она сохраняется на одном инстансе шарда, после чего создаются задачи на репликацию на остальные инстансы того же шарда. У нас на каждый шард по 3 инстанса backpack на разных физических машинах, чтобы в случае падения метеорита в один сервер, шард продолжал функционировать.
Стоит отметить, что мы всеми силами стараемся не делать лишних движений, поэтому при добавлении нового шарда в хранилище, не происходит перебалансировки. Просто мы более активно пишем в новый шард. Это не потому, что перебалансировка — это сложно (на самом деле да) или потому что мы не осилили (на самом деле осилили, потом передумали), а потому что это на самом деле не нужно.
Ссылка на GitHub.
Уровень репликации, который только и делает, что расладывает картинки по инстансам backpack. Недоступные инстансы получают свои данные после того, как очнутся. Использует модуль zk-redis-queue, чтобы гарантировать обработку сообщений хотя бы однажды.
Инстансы репликаторов также взаимозаменяемы и равноправны, что позволяет запускать их столько, сколько требует ваша нагрузка.
Ссылка на GitHub.
Уровень хранения данных, самая соль хранилища. Умеет команды webdav (GET, PUT):
При желании может быть заменён nginx с модулем webdav или чем-нибудь, что умеет webdav. Нам nginx не хватило, поэтому пришлось делать сам backpack. Вдохновлялись haystack от facebook, где они хранят свои фотографии. Haystack оказался закрытой разработкой, но к нему есть whitepaper, из которого и были почерпнуты драгоценные знания.
Суть backpack в хранении индекса полностью в памяти (redis) и записи многих мелких файлов в большие. Таким образом нам для чтения файла нужно только получить его данные (offset и length) из индекса и сделать один pread. Не нужно поднимать информацию по метаданным фотографий (права файла и подобные), любые данные на расстоянии одного disk seek. Помимо прочего мы используем O_DIRECT, чтобы выравнивать чтения по диску, это даёт несколько бонусных процентов к производительности.
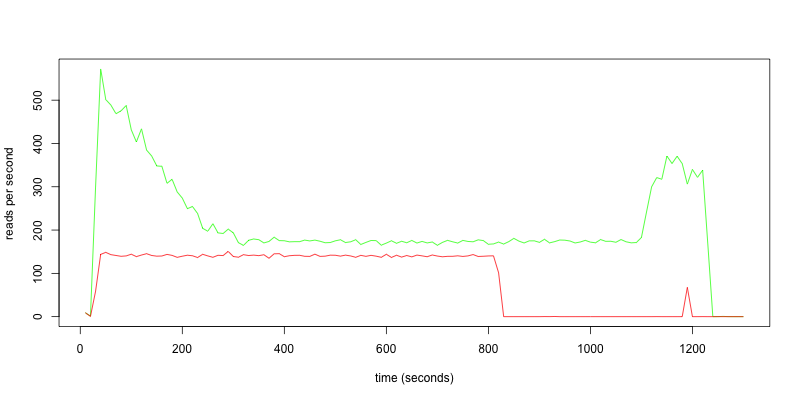
Выигрыш от backpack в сравнении с nginx можно понять по тесту. Мы взяли 1 700 000 случайных фотографий и сохранили в backpack и nginx на одинаковых серверах. Выбрали 100 000 случайных файлов и решили их прочитать в 20 потоков.
Красная линия — backpack, зелёная — nginx.

У backpack ушло 732 секунды на всё про всё, в то время как у nginx 1200 секунд, разница в 33%.
Тут становится понятно, почему: nginx делает гораздо больше чтений с диска, больше перемещает головку диска, а операция эта не бесплатная. Со временем nginx заполняет дисковый кеш метаданными и ускоряется, но даже этого недостаточно. Если бы данных было ещё больше, вероятность попадания в дисковый кеш у nginx была бы ещё меньше. А данных у нас гораздо больше.

Чтобы вы не подумали, что я вас обманываю, на графиках i/o видно, что всё время работы каждый вариант использовал диск на 100%.
Все проекты поддерживают node.js 0.10 и вроде бы не утекают, по крайней мере heap остаётся постоянным после недель работы. Запускаем демоны мы через mon.
Будем рады, если вы решите развернуть стек backpack у себя!

В open-source мы решили отдать ту часть инфраструктуры, которая непосредственно взаимодействует с дисками. Остальным у нас заведует nginx, и его улучшения уже либо в основной ветке nginx (прогрессивный jpeg в модуле image_filter и поддержка переменных в нём же), либо ждут своего часа в рассылке nginx-devel (возможность «прилипания» к определённому краю изображения при crop).
Хранилище подходит не только для фотографий, но и для любых данных, которые склонны к бесконечному сроку жизни и имеют конечный, достаточно малый размер. Хранить большие объёмы данных типа видео проще и выгоднее, просто укладывая его на файловую систему. Данные должны быть неизменяемыми. Если вы наложили фильтр на фотографию — сохраните под новым именем.
Во всей инфраструктуре нет единой точки отказа, так что попадание метеоритов в пару серверов для нас не является проблемой. Диски разваливаются куда чаще, чем хотелось бы, так что такая фича была заложена с самого начала.
Попробую рассказать вкратце о составных частях.
backpack-coordinator
Ссылка на GitHub. Тут же можно узнать, как развернуть систему в целом.
Координаторы — уровень, с которым общается приложение для сохранения данных в сторадж. Умеет команды:
- Положить и попросить реплицировать
- Рассказать статистику
Инстансы координаторов равноправны и взаимозаменяемы, они заведуют шардингом данных, общаясь через zookeeper. Они знают, куда нужно положить следующую фотографию. Количество инстансов в шарде определяет количество копий данных, количество шардов и их размер — общий размер хранилища.
Шард — несколько инстансов backpack, имеющих одинаковый набор данных.
При загрузке фотографии в хранилище, она сохраняется на одном инстансе шарда, после чего создаются задачи на репликацию на остальные инстансы того же шарда. У нас на каждый шард по 3 инстанса backpack на разных физических машинах, чтобы в случае падения метеорита в один сервер, шард продолжал функционировать.
Стоит отметить, что мы всеми силами стараемся не делать лишних движений, поэтому при добавлении нового шарда в хранилище, не происходит перебалансировки. Просто мы более активно пишем в новый шард. Это не потому, что перебалансировка — это сложно (на самом деле да) или потому что мы не осилили (на самом деле осилили, потом передумали), а потому что это на самом деле не нужно.
backpack-replicator
Ссылка на GitHub.
Уровень репликации, который только и делает, что расладывает картинки по инстансам backpack. Недоступные инстансы получают свои данные после того, как очнутся. Использует модуль zk-redis-queue, чтобы гарантировать обработку сообщений хотя бы однажды.
Инстансы репликаторов также взаимозаменяемы и равноправны, что позволяет запускать их столько, сколько требует ваша нагрузка.
backpack
Ссылка на GitHub.
Уровень хранения данных, самая соль хранилища. Умеет команды webdav (GET, PUT):
- Сохранить файл
- Получить файл
- Рассказать статистику — уже не webdav, но дело нужное
При желании может быть заменён nginx с модулем webdav или чем-нибудь, что умеет webdav. Нам nginx не хватило, поэтому пришлось делать сам backpack. Вдохновлялись haystack от facebook, где они хранят свои фотографии. Haystack оказался закрытой разработкой, но к нему есть whitepaper, из которого и были почерпнуты драгоценные знания.
Суть backpack в хранении индекса полностью в памяти (redis) и записи многих мелких файлов в большие. Таким образом нам для чтения файла нужно только получить его данные (offset и length) из индекса и сделать один pread. Не нужно поднимать информацию по метаданным фотографий (права файла и подобные), любые данные на расстоянии одного disk seek. Помимо прочего мы используем O_DIRECT, чтобы выравнивать чтения по диску, это даёт несколько бонусных процентов к производительности.
Выигрыш от backpack в сравнении с nginx можно понять по тесту. Мы взяли 1 700 000 случайных фотографий и сохранили в backpack и nginx на одинаковых серверах. Выбрали 100 000 случайных файлов и решили их прочитать в 20 потоков.
Красная линия — backpack, зелёная — nginx.
Запросы в секунду

У backpack ушло 732 секунды на всё про всё, в то время как у nginx 1200 секунд, разница в 33%.
Чтения с диска в секунду

Тут становится понятно, почему: nginx делает гораздо больше чтений с диска, больше перемещает головку диска, а операция эта не бесплатная. Со временем nginx заполняет дисковый кеш метаданными и ускоряется, но даже этого недостаточно. Если бы данных было ещё больше, вероятность попадания в дисковый кеш у nginx была бы ещё меньше. А данных у нас гораздо больше.
Использование i/o

Чтобы вы не подумали, что я вас обманываю, на графиках i/o видно, что всё время работы каждый вариант использовал диск на 100%.
Все проекты поддерживают node.js 0.10 и вроде бы не утекают, по крайней мере heap остаётся постоянным после недель работы. Запускаем демоны мы через mon.
Будем рады, если вы решите развернуть стек backpack у себя!
