
Напомню, основной целью Incident Management является как можно быстрое восстановление услуги, что иногда становиться похожим на попытки тушения лесного пожара лопатой. Так как, затушив возгорание на отдельно взятой сопке, мы не устраним общее бедствие, а, затушив всю площадь возгорания, не решим вопрос с появлением нового очага в следующем сезоне или даже на следующий день. Необходимо разобраться с причиной пожара, то ли это туристы и необходимо провести агитацию (обучение), то ли это заболоченный, высохший лес, и необходимо провести его очистку (модернизацию).
Или еще, например, случай из жизни: при печати на принтере с несколькими лотками происходило замятие бумаги из одного лотка, как результат, в рамках Incident Management происходила смена лотков, тем самым временно устранялся вопрос с замятием. И повторялось эта ситуация несколько дней, доставляя неудобство пользователям, и отвлекая ИТ-специалистов. В этом примере Problem Manegement показал, что причина была в износе роликов подачи бумаги и после их замены принтер начал работать в штатном режиме.
Go deeper!

Немного теории
В соответствии с ITIL проблема (problem) – неизвестная причина одного или нескольких инцидентов. Как раз то, что надо!
Так, а если посмотреть основную задачу Problem Management – предупреждать появление проблем, устранять появление повторяющихся инцидентов и минимизировать влияние инцидентов, которые не могут быть предупреждены.
Для чего необходимо управлять проблемами с точки зрения бизнеса, наверное, это более высокая доступность ИТ услуг, более высокая производительность персонала, в том числе и ИТ, снижение стоимости за счет отсутствия повторяющихся инцидентов.
Здесь мы будем рассматривать реактивное управление проблемами, т. е. реагирование по факту обнаружения проблемы.
Перейдем к реализации
— Чё, проблемы?

Как ищем проблемы? Здесь в помощники нам выступают средства мониторинга, ServiceDesk, инциденты, данные от поставщиков или данные, поступившие из Proactive Problem Management
Когда стало понятно что перед нами действительно проблема регистрируем в агентском интерфейсе, для чего необходимо проделать ряд манипуляций в админской части OTRS.
Для регистрации проблем необходимо активировать тип заявки Problem (Проблема).
Далее необходимо скрыть от пользователей типы заявок.
Ticket -> Frontend::Customer::Ticket::ViewNew выставляем параметр Ticket::Frontend::CustomerTicketMessage###TicketType — Нет
Тем самым, упростив задачу пользователю, и усложнив задачу ServiceDesk.
Для разгрузки агентского интерфейса вводим очередь «Очередь проблем». Теперь все проблемы доступны только тем, агентам, которым это разрешено на отдельной вкладке.
Описание заявки при этом возлагаем на ServiceDesk или на Problem Manager'а в случае описания проблемы. т. е. добавлем для агента права на «Очередь проблем»
Классификация

Мы решили остановиться на классификации по услугам, хотя можно классифицировать по очередям. Классификация должна быть такой же, как и в Incident Management для более удобного представления и дальнейшего разбора полетов совместно с Incident Management.
В правом окне «Информация о заявке» содержится информация об услуге, SLA, времени решения по заявке в соответствии со SLA.
В нижней части отображаются инциденты, которые относятся к данной проблеме, так же привязан ConfigItem, т. е. тот принтер, по которому мы работаем в контексте данной проблемы, при переходе по ссылке можем посмотреть дополнительную информацию по нему.
Приоритеты
Уровень 5. Major problem – требующие немедленного решения, как правило — это проблемы, затрагивающие топ-менеджмент, либо затрагивающие большое количество пользователей.
Уровень 2-4. Все остальные проблемы
Уровень 1. Затрагивающие малое количество пользователей.
Поиск причины
Вот здесь и начинается самая работа. Необходимо определить причину появления проблемы.
Вся выполняемая работа фиксируется через заметки, пополняя лог проблемы, который может говорить об эффективности работников службы ИТ, а так же пригодиться при появлении схожих проблем. Здесь же фиксируется время затраченное на выполнение работ. Общее время по проблеме суммируется из времени по всем заметкам.
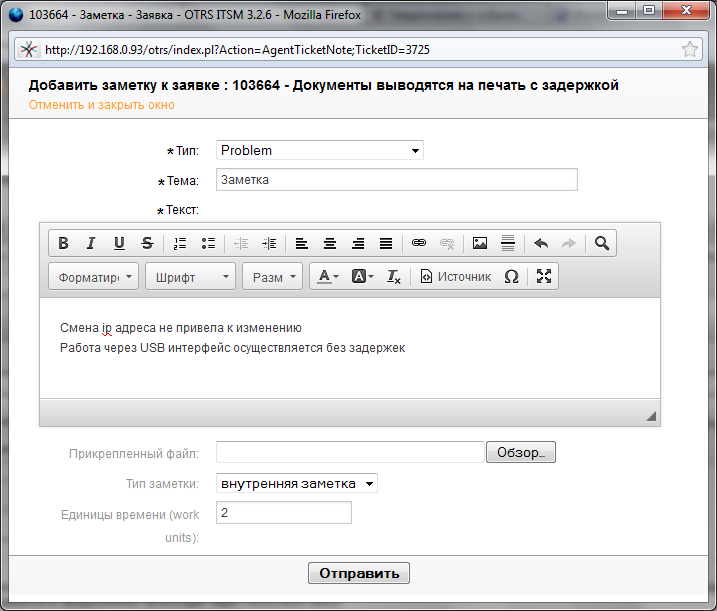
Если нам повезло и мы определили причину идем в агентский интерфейс и описываем ее.
Необходимо указать код причины для глобального анализа причин появления всех проблем, при необходимости, добавив описание.
Если до причины проблемы мы еще не докопались, но нашли обходной путь, необходимо его зафиксировать для того, чтобы повысить время решения вновь происходящих инцидентов. По ITIL рекомендуется создавать Known Error Record (Запись об известной ошибке). Однако я использую смену типа заявки с Problem на Problem.Known Error.
Опять проделываем некоторые манипуляции, а именно добавляем необходимые поля для заявок и их значения.
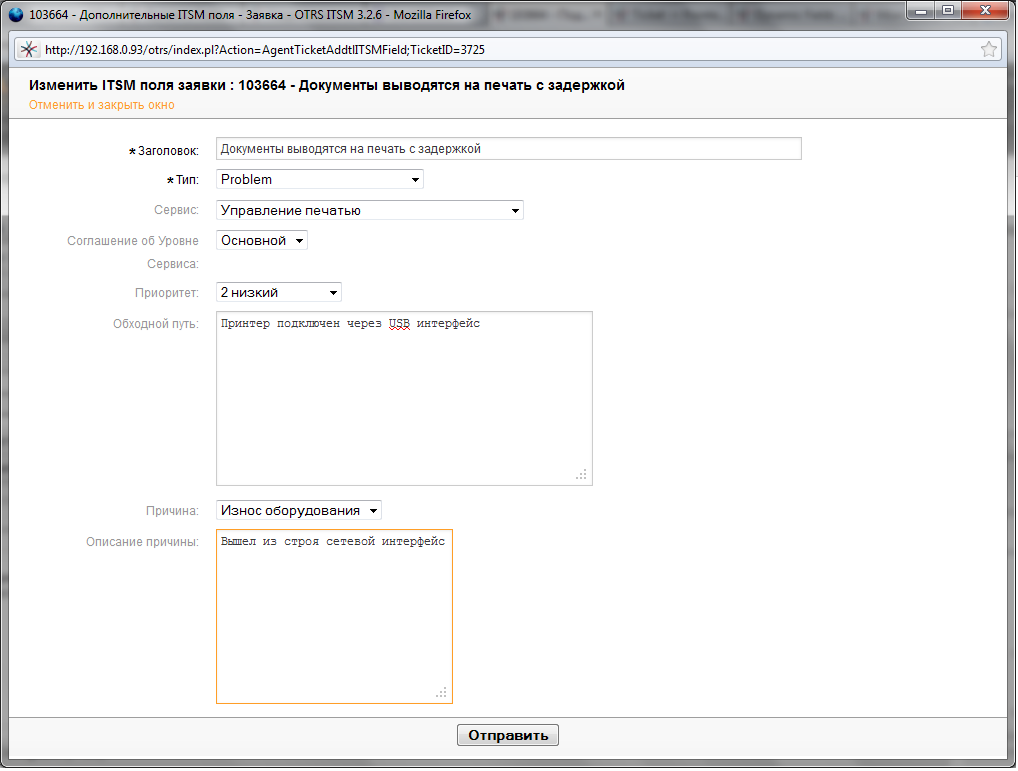
За эти настройки отвечают DynamicField (Динамические поля), перерабанный функционал, появившийся в версии 3.2 OTRS
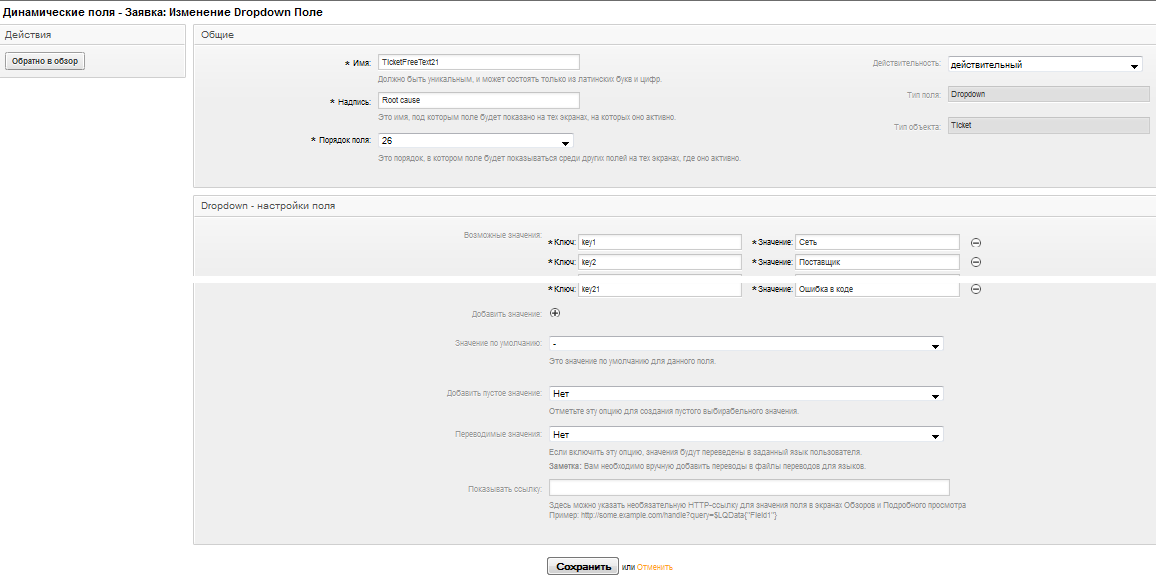
Нам понадобятся поля Причина (Dropdown), Описание причины (TextArea), Обходной путь (TextArea)
Описание всех полей делаем на английском языке, а перевод делаем через файл ru.pm, расположенный в папке /opt/otrs/Kernel/Language/
Для поля Dropdown задаем предопределенные значения
Добавляем в конфигурации Ticket ->Frontend::Agent::Ticket::ViewAddtlITSMField

Так это выглядет в агентском интерфейсе.
Решение
После того как решение проблемы найдено мы должны формально закрыть проблему, поменяв ее статус на «Закрыто успешно».
Отчетность
Управленческая отчетность
- Количество проблем, зарегистрированных за определенный период.
- Стоимость решения проблем за отчетный период
- % проблем с приоритетом 5
Отчетность Problem Manager'а
- Причина проблем за определенный период, по услугам, по типу CI.
PS В версии 3.2 появилась новая фича: ProcessManagment, которая позволяет управлять заявками с помощью WorkFlow, так что придется вернуться к процессу Request Fulfillment
