TCP (Transmission Control Protocol) — основной протокол интернета. Одна из его главных задач — бороться с перегрузками в сети (network congestion), когда возникают заторы из пакетов. Регулирование осуществляется путём взаимной подстройки скорости отправки запросов, причём для этого существует множество хитрых методов. Например, в Linux используется алгоритм под названием TCP Cubic, а под Windows — Compound TCP. Кроме них, существуют ещё TCP Tahoe, Reno, NewReno, Vegas, FAST, BIC и др.
Специалисты из Массачусетского технологического института разработали программу Remy, которая методом проб и ошибок пыталась улучшить существующие алгоритмы подавления заторов TCP. Результат превзошёл все ожидания. Эффективность алгоритмов RemyCC превзошла и TCP Cubic, и Compound TCP, и остальных «конкурентов» в различных сетевых условиях. Проблема только в том, что учёные не совсем понимают, за счёт чего именно Remy удалось показать такой феноменальный результат.
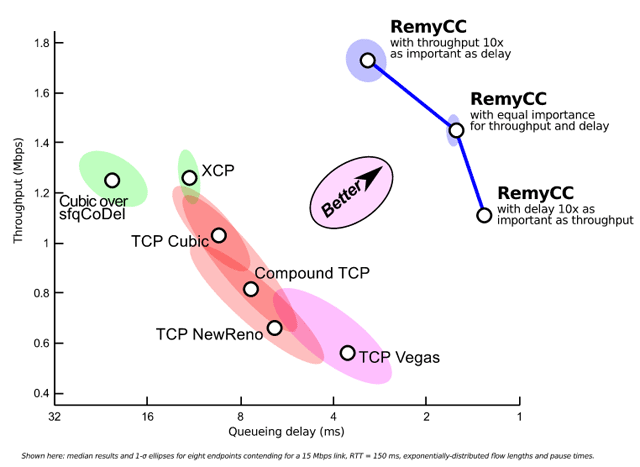
Remy был протестирован в различных сетевых окружениях и везде превзошёл алгоритмы, созданные человеком. Например, в конфигурации, где восемь пользователей делят канал 15 Мбит/с (см. схему вверху), алгоритм Remy обеспечил более чем вдвое превосходящую среднюю по медиане скорость передачи данных с задержкой запросов менее чем вполовину от той, которую обеспечивают Compound TCP и TCP NewReno. По сравнению со стандартным TCP Cubic, пропускная способность выросла на 70%, а задержка запросов уменьшилась более чем втрое.
Тесты проводились в популярном симуляторе ns-2. Если внедрить Remy на реальных компьютерах, то мы увидим резкое увеличение скорости скачивания, уменьшение задержек в видеочатах и гораздо более грамотное распределение сетевых ресурсов.
Программа Remy работает на конкретном компьютере несколько часов, анализируя сетевой трафик, после чего вырабатывает конкретную реализацию алгоритма, наиболее эффективную для данного ПК.

«Мы точно не знаем, почему сгенерированные компьютером алгоритмы демонстрируют такой результат, — пишут разработчики. — Алгоритмы Remy создаются с учётом более 150 правил, и нужно осуществить реверс-инжиниринг, чтобы понять, как и почему они работают».
В любом случае, если доверить компьютеру оптимизацию сетевого протокола, то можно получить более высокие скорости и меньший пинг. Жаль, но причины этого мы можем и не понять.
Специалисты из Массачусетского технологического института разработали программу Remy, которая методом проб и ошибок пыталась улучшить существующие алгоритмы подавления заторов TCP. Результат превзошёл все ожидания. Эффективность алгоритмов RemyCC превзошла и TCP Cubic, и Compound TCP, и остальных «конкурентов» в различных сетевых условиях. Проблема только в том, что учёные не совсем понимают, за счёт чего именно Remy удалось показать такой феноменальный результат.
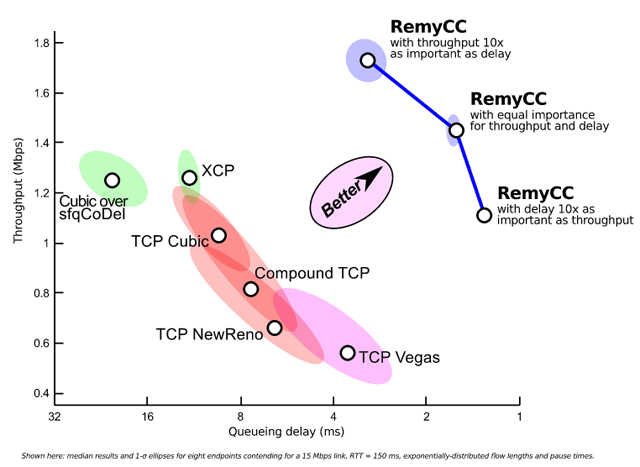
Remy был протестирован в различных сетевых окружениях и везде превзошёл алгоритмы, созданные человеком. Например, в конфигурации, где восемь пользователей делят канал 15 Мбит/с (см. схему вверху), алгоритм Remy обеспечил более чем вдвое превосходящую среднюю по медиане скорость передачи данных с задержкой запросов менее чем вполовину от той, которую обеспечивают Compound TCP и TCP NewReno. По сравнению со стандартным TCP Cubic, пропускная способность выросла на 70%, а задержка запросов уменьшилась более чем втрое.
Тесты проводились в популярном симуляторе ns-2. Если внедрить Remy на реальных компьютерах, то мы увидим резкое увеличение скорости скачивания, уменьшение задержек в видеочатах и гораздо более грамотное распределение сетевых ресурсов.
Программа Remy работает на конкретном компьютере несколько часов, анализируя сетевой трафик, после чего вырабатывает конкретную реализацию алгоритма, наиболее эффективную для данного ПК.

«Мы точно не знаем, почему сгенерированные компьютером алгоритмы демонстрируют такой результат, — пишут разработчики. — Алгоритмы Remy создаются с учётом более 150 правил, и нужно осуществить реверс-инжиниринг, чтобы понять, как и почему они работают».
В любом случае, если доверить компьютеру оптимизацию сетевого протокола, то можно получить более высокие скорости и меньший пинг. Жаль, но причины этого мы можем и не понять.
