
Я уже много раз писал о фреймворке PHPixie и программировании на нем. В этот раз мы заглянем внутрь и посмотрим жизненный цикл приложения, к счастью простота и линейность кода позволяют сделать это с относительной легкостью.
Как и например Symfony, PHPixie состоит из двух частей: библиотеки компонентов и базового проекта, правда в случае PHPixie базовый проект более тонкий и состоит всего из нескольких файлов. Он здесь исполняет роль примера и поэтому изменение его под себя не только приветствуется но в некоторых случаях даже необходимо. Именно для этого важно понимать что и как происходит в системе. Используя свои несколько ограниченные умения в области рисования я подготовил диаграмму обработки запроса
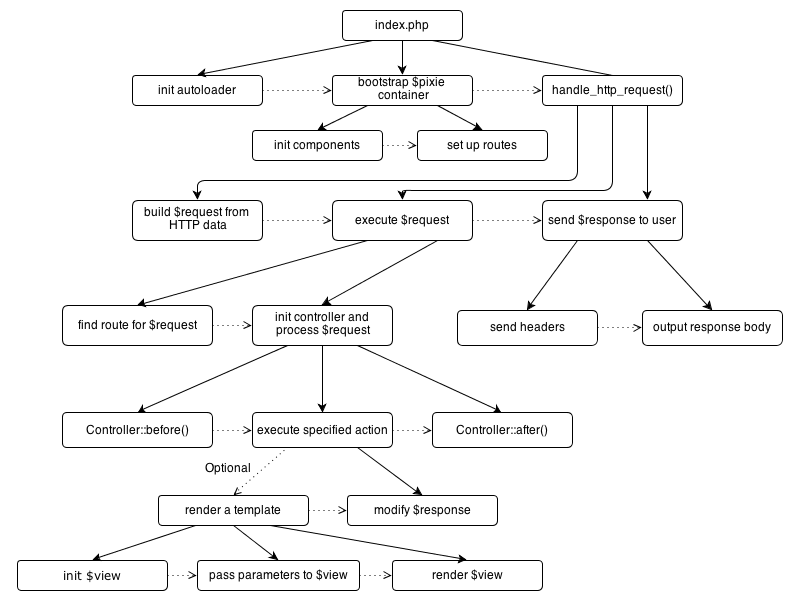
Конечно тем кто уже знаком с MVC (или даже VC в этом случае, так как модели я не нарисовал) наверняка эта схема уже покажется знакомой, но для новичков может быть очень полезна. Итак начнем c index.php куда и попадают все запросы, здесь самые важные строчки это:
$pixie = new \App\Pixie();
$pixie->bootstrap($root)->handle_http_request();
И сразу же мы попадаем на самую важную часть, класс App\Pixie который является сердцем фреймворка, его DI контейнером. Через него можно получить доступ ко всем другим компонентам. App\Pixie наследует от PHPixie\Pixie из библиотеки PHPixie-Core. Базовый проект оглашает этот класс вместо использования PHPixie\Pixie напрямую для предоставления разработчику возможности внести в него свои изменения ( например подключить модуль).
Сразу стоит отметить что добавлять новые сущности в этот контейнер на ходу, как например в Silex, нельзя, все надо описывать явно в классе. Хотя это и может показаться не таким удобным на первый взгляд, но зато позволяет добиться лучшей читабельности кода, полностью продокументировать все сущности (так как все они становятся атрибутами класса) а также получить подсказки по этим сущностям в IDE. Поскольку PHPixie\Pixie содержит также все фактори методы, то это позволят нам с легкостью заменить любой класс фреймворка на свой путем перегрузки соответствующего метода.
Метод bootstrap() инициализирует $pixie, считывает конфигурацию, подключает обработку исключений итд. Как раз в handle_http_request() проходит обработка запроса. Этот процесс состоит из трех этапов:
- Создание объекта $request класса PHPixie\Request
- Этот объект передается в соответствующий контроллер и выполняется соответствующий action
- В процессе исполнения екшена контроллер изменяет объект $response ( PHPixie\Response )
- Данные из $response (хедеры и контент) отсылаются пользователю
Все три самых важных объекта $request, $response и $pixie доступны как атрибуты класса PHPixie\Controller. Теперь отвлечемся немного на еще несколько парадигм написания кода на PHPixie:
Не использовать оператор «new» нигде кроме фактори методов. Каждый новый класс должен иметь фактори метод (например в App\Pixie) для создания его екземпляров. Такой подход позволяет легко заменить один класс другим, что особенно важно при написании юнит тестов. Так тестируя например контроллер вы теперь сможете передать в него замоканный App\Pixie который вместо реальных классов передаст их моки.
Не использовать статические проперти и методы. Использование статики сильно усложняет написание тестов. Используя PHPixie можно легко обойтись без них, достаточно добавить экземпляр как атрибут App\Pixie и вы сможете получить к нему доступ практически из любого места. Таким образом мы фактически получим синглтон. Кстати сделать это можно еще путем добавления его в $instance_classes.
namespace App;
class Pixie extends \PHPixie\Pixie {
public function __construct() {
$this->instance_classes['singleton'] = '\App\Singleton';
}
}
// Теперь мы можем использовать $pixie->singleton в любом месте,
// и всегда получить тот же объект. В качестве дополнительного бонуса
// объект будет создан только тогда когда он будет нужен
Как работают модули
Каждый модуль для PHPixie это дополнительная библиотека классов которая предоставляет свой DI контейнер очень похожий на главный PHPixe\Pixie, то есть он состоит из методов фабрик для создания экземпляров классов который входят в модуль. Потом мы просто добавляем его в массив модулей в главный контейнер:
namespace App;
class Pixie extends \PHPixie\Pixie {
protected $modules = array(
'db' => '\PHPixie\DB',
'orm' => '\PHPixie\ORM'
);
}
// Теперь мы можем использовать $pixie->db и $pixie->orm
А что делать если я например хочу подменить класс PHPixie\ORM\Model на свой App\Model? Все просто, надо еще сделать свой App\ORM (extends PHPixie\ORM ) метод get() которого вместо модели PHPixie\ORM\Model будет возвращать ту что нужна нам. в этом еще больше проявляется одна из идей фреймворка — как можно больше использовать стандартные приемы ООП вместо каких-то магий. Например чтобы подменить класс самого фреймворка приходится применять subclass_prefix и делать єто на уровне конфигурации а не собственно программирования. Такой подход позволяет намного улучшыть понимание системы, так как по большей части в флове можно разобраться не зная ничего о фреймворке, просто посмотрев на сами классы.
А как же хуки, ивенты и прочее?
Их нет и я так понимаю не будет. Такие вещи полностью из другой парадигмы так как делают код нелинейным, особенно это относится к ивентам, где всегда не до конца понятно который из листенеров запустится первым и что случится если он сам вызовет какой-то ивент. А также от их использования очень часто страдает читабельность бектрейсов, так как они вызываются самим фреймворком где-то там где сам программист кода точно не писал. Если нужно что-то сделать в каком-то месте гораздо проще перегрузить метод который как-раз это и делает и дописать к нему ту логику что нужно.
В следующей статье я либо более подробно рассмотрю как PHPixie работает с базами данных, либо более расширенно расскажу в чем плюсы и минусы линейного против event driven программирования.
