Вступительное слово
Считается, что «киллер фичей» СКВ Git является легковесное ветвление. Я ощутил это преимущество в полной мере, ведь я перешел на Git с SVN, где ветвление было достаточно дорогим процессом: для создания ветки нужно было скопировать весь рабочий каталог. В Git все проще: создание ветки подразумевает лишь создание нового указателя на определенный коммит в папке
.git/refs/heads, который является файлом с 40 байтами текста, хешем коммита.Основными командами пользовательского уровня для ветвления в Git являются git-branch, git-checkout, git-rebase, git-log и, конечно же, git-merge. Для себя я считаю git-merge зоной наибольшей ответственности, точкой огромной магической энергии и больших возможностей. Но это достаточно сложная команда, и даже достаточно длительный опыт работы с Git порой бывает недостаточным для освоение всех ее тонкостей и умения применить ее наиболее эффективно в какой-либо нестандартной ситуации.
Попробуем же разобраться в тонкостях git-merge и приручить эту великую магию.
Здесь я хочу рассмотреть только случай благополучного слияния, под которым я понимаю слияние без конфликтов. Обработка и разрешение конфликтов — отдельная интересная тема, достойная отдельной статьи. Я очень рекомендую так же ознакомиться со статьей Внутреннее устройство Git: хранение данных и merge, содержащей много важной информации, на которую я опираюсь.
Анатомия команды
Если верить мануалу, команда имеет следующий синтаксис:
git merge [-n] [--stat] [--no-commit] [--squash] [--[no-]edit] [-s <strategy>] [-X <strategy-option>] [--[no-]rerere-autoupdate] [-m <msg>] [<commit>...] git merge <msg> HEAD <commit>... git merge --abort
По большому счету, в Git есть два вида слияния: перемотка (fast-forward merge) и «истинное» слияние (true merge). Рассмотрим несколько примеров обоих случаев.
«Истинное» слияние (true merge)
Мы отклоняемся от ветки master, чтобы внести несколько
master: A - B - C - D
\
feature: X - Y
Выполним на ветке master
git merge feature:
master: A - B - C - D - (M)
\ /
feature: X - Y
Это наиболее частый паттерн слияния. В данном случае в ветке master создается новый коммит (M), который будет ссылаться на двух родителей: коммит D и коммит Y; а указатель master установится на коммит (M). Таким образом Git будет понимать, какие изменения соответствуют коммиту (M) и какой коммит последний в ветке master. Обычно коммит слияния делается с сообщением вроде «Merge branch 'feature'», но можно определить и свое сообщение коммита с помощью ключа
-m.Посмотрим историю коммитов в тестовом репозитории, который я создал специально для этого случая:
$ git log --oneline 92384bd (M) bceb5a4 D 5dce5b1 Y 76f13e7 X d1920dc C 3a5c217 B 844af94 A
А теперь посмотрим информацию о коммите (M):
$ git cat-file -p 92384bd tree 2b5c78f9086384bd86a2ab9d00c7e41a56f01d04 parent bceb5a4ad88e80467404473b94c3e0758dd8e0be parent 5dce5b1edef64bd0d4e1039061a77be4d7182678 author Andre <andrey.prokopyuk@gmail.com> 1380475972 +0400 committer Andre <andrey.prokopyuk@gmail.com> 1380475972 +0400 (M)
Мы видим двух родителей, объект-дерево, соответствующее данному состоянию файлов репозитория, а так же информацию о том, кто виновен в коммите.
Посмотрим, куда ссылается указатель master:
$ cat .git/refs/heads/master 92384bd77304c09b81dcc4485da165923b96ed5f
Действительно, он теперь передвинут на коммит (M).
Squash и no-commit
Но что делать, если за содержимое ветки feature вас могут побить? К примеру, улучшение было небольшим, и вполне могло уместиться в один логичный коммит, но так вышло, что посреди работы вам было нужно убегать на электричку, а продолжать уже дома? В таком случае есть два выхода: экспорт репозитория с последующим импортом на другой машине, либо (особенно когда до электрички 10 минут, а до вокзала около километра) — сделать
push origin feature.Заливать незаконченные коммиты в основную ветку плохо, и с этим нужно что-то делать. Одним из способов, и, пожалуй самым простым, является опция
--squash. git merge feature --squash объединит изменения всех коммитов ветки feature, перенесет их в ветку master и добавит в индекс. При этом коммит слияния не будет создан, вам нужно будет сделать его вручную. Такого же поведения без параметра squash можно добиться, передав при слиянии параметр
--no-commit.В случае применения такого слияния коммиты ветки feature не будут включены в нашу историю, но коммит Sq будет содержать все их изменения:
master: A - B - C - D - Sq
\
feature: X - Y
Позже, в случае выполнения «классического»
git merge feature можно исправить это. Тогда история примет следующий вид:
master: A - B - C - D - Sq - (M)
\ /
feature: X - Y
В случае, если вы выполнили слияние без коммита, а потом поняли, что совершили фатальную ошибку, все можно отменить простой командой:
git merge --abort. Эта же команда может быть применена, если во время слияния произошли конфликты, а разрешать их в данный момент не хочется.Перемотка (fast-forward merge)
Рассмотрим другой случай истории коммитов:
master: A - B - C
\
feature: X - Y
Все как и в прошлый раз, но теперь в ветке master нет коммитов после ответвления. В этом случае происходит слияние fast-forward (перемотка). В этом случае отсутствует коммит слияния, указатель (ветка) master просто устанавливается на коммит Y, туда же указывает и ветка feature:
master, feature: A - B - C - X - Y
Чтобы предотвратить перемотку, можно использовать параметр
--no-ff. В случае, если мы выполним
git merge feature --no-ff -m '(M)', мы получим уже такую картину:
master: A - B - C - (M)
\ /
feature: X - Y
Если же для нас единственным приемлемым поведением является fast-forward, мы можем указать опцию
--ff-only. В этом случае, если к слиянию не применима перемотка, будет выведено сообщение о невозможности совершить слияние. Именно так было бы, если бы мы добавили опцию --ff-only в самом первом примере, где после ответвления feature в ветке master был сделано коммит C.Можно добавить, что при выполнении
git pull origin branch_name применяется как раз что-то вроде --ff-only. То есть, в случае, если при слиянии с веткой origin/branch_name не приемлема перемотка, операция отменяется и выводится сообщении о невозможности выполнения.Стратегии слияния
У команды git-merge есть интересный параметр,
--strategy, стратегия. Git поддерживает следующие стратегии слияния:- resolve
- recursive
- ours
- octopus
- subtree
Стратегия resolve
Стратегия resolve — классическое трехсторонее слияние (three-way merge). Стандартный алгоритм трехстороннего слияния применяется для двух файлов с общим предком. Условно этот алгоритм можно представить в виде следующих шагов:
- поиск общего предка,
- поиск блоков, изменившихся в обеих версиях относительно общего предка,
- записываются блоки, оставшиеся без изменения,
- блоки, изменившиеся только в одном из потомков, записываются как измененные,
- блоки, изменившиеся в обеих версиях, записываются только если изменения идентичны, в ином случае объявляется конфликт, разрешение которого предоставляется пользователю.
Эта стратегия имеет один недостаток: в качестве общего предка двух веток всегда выбирается наиболее ранний общий коммит. Для случая из нашего первого примера это не страшно, можно смело применять
git merge feature -s resolve, и результат будет ожидаемым:
master: A - B - C - D - (M)
\ /
feature: X - Y
Здесь C — общий коммит двух веток, дерево файлов, соответствующее этому коммиту, принимается за общего предка. Анализируются изменения, произведенные в ветках master и feature со времен этого коммита, после чего для коммита (M) создается новая версия дерева файлов в соответствии с пунктами 4 и 5 нашего условного алгоритма.
В каком же случае проявляется недостаток стратегии resolve? Он проявляется в том случае, если для коммита (M) нам пришлось разрешить конфликты, после чего мы продолжили разработку и еще раз хотим выполнить
git merge feature -s resolve. В этом случае в качестве общего предка снова будет использован коммит C, и конфликты произойдут снова и будут нуждаться в нашем вмешательстве.Стратегия recursive
Данная стратегия решает проблемы стратегии resolve. Она так же реализует трехстороннее слияние, но в качестве предка используется не реальный, а «виртуальный» предок, который конструируется по следующему условному алгоритму:
- проводится поиск всех кандидатов на общего предка,
- по цепочке проводится слияние кандидатов, в результате чего появляется новый «виртуальный» предок, причем более свежие коммиты имеют более высокий приоритет, что позволяет избежать повторного проявления конфликтов.
Результат этого действия принимается за общего предка и проводится трехсторонее слияние.
Для иллюстрации этой стратегии позаимствуем пример из статьи Merge recursive strategy из блога «The plasticscm blog»:

Итак, у нас есть две ветки: main и task001. И так вышло, что наши разработчики знают толк в извращениях: они слили коммит 15 из ветки main с коммитом 12 из ветки task001, а так же коммит 16 с коммитом 11. Когда нам понадобилось слить ветки, оказалось, что поиск реального предка — дело неблагодарное, но стратегия recursive с ее конструированием «виртуального» предка нам поможет. В результате мы получим следующую картину:
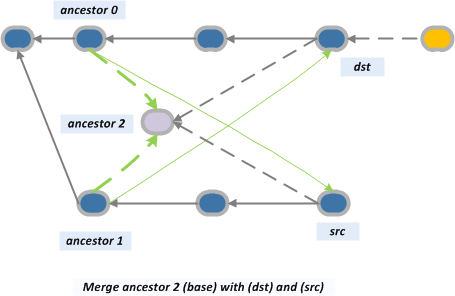
Стратегия recursive имеет множество опций, которые передаются команде
git-merge с помощью ключа -X:- ours и theirs
Используются для автоматического разрешения конфликтов. Ours — предпочитать «нашу» версию, версию «dst», theirs — предпочитать «их» версию.
- renormalize (no-renormalize)
Предотвращает ложные конфликты при слиянии вариантов с разными типами перевода строк.
- diff-algorithm=[patience|minimal|histogram|myers], а так же опция patience
Выбор алгоритма дифференциации файлов.
Дополнительную информацию об этих опциях можно найти в документации по git-diff. Если кратко, свойства этих алгоритмов следующие:
default, myers — стандартный, жадный алгоритм. Он используется по умолчанию.
minimal — производится поиск минимальнейших изменений, что занимает дополнительное время.
patience — использовать алгоритм «patience diff». О нем можно почитать у автора алгоритма, либо в сокращенном варианте на SO.
histogram — расширяет алгоритм patience с целью, описанной как «support low-occurrence common elements». Сказать честно, я не смог найти достаточно ясного ответа на вопрос, какие конкретно случаи подразумеваются и буду очень рад, если кто-нибудь поможет найти этот ответ.
- ignore-space-change, ignore-all-space, ignore-space-at-eol
Корни этих опций лежат, опять же, в git-diff и относятся к дифференциации файлов при слиянии.
ignore-space-change — игнорируются различия в количестве пробелов, идущих подряд, а так же пробелы в конце строки,
ignore-all-space — пробелы абсолютно игнорируются при сравнении,
ignore-space-at-eol — игнорируются различия в пробелах в конце строки.
- rename-threshold=<n>
Данная опция задает порог, по достижении которого файл может считаться не новым, а переименованным файлом, которого git-diff не досчитался. Например,-Xrename-threshold=90%подразумевает, что переименованным считается файл, который содержит от 90% контента некоторого удаленного файла.
- subtree[=<path>]
Выполнение рекурсивного слияния с этой опцией будет более продвинутым вариантом стратегии subtree, где алгоритм основывается на предположении, как деревья должны совместиться при слиянии. Вместо этого в этом случае указывается конкретный вариант.
Стратегия octopus
Эта стратегия используется для слияние более чем двух веток. Получившийся в итоге коммит будет иметь, соответственно, больше двух родителей.
Данная стратегия предполагает большую осторожность относительно потенциальных конфликтов. В связи с этим порой можно получить отказ в слиянии при применении стратегии octopus.
Стратегия ours
Не следует путать стратегию ours и опцию ours стратегии recursive.
Выполняя
git merge -s ours obsolete, вы как бы говорите: я хочу слить истории веток, но проигнорировать все изменения, которые произошли в ветке obsolete. Иногда рекомендуют вместо стратегии ours использовать следующий вариант: $ git checkout obsolete $ git merge -s recursive -Xtheirs master
Стратегия ours — более радикальное средство.
Стратегия subtree
Для иллюстрации данной стратегии возьмем пример из главы Слияние поддеревьев книги «Pro Git».
Добавим в наш проект новые удаленный репозиторий, rack:
$ git remote add rack_remote git@github.com:schacon/rack.git $ git fetch rack_remote warning: no common commits remote: Counting objects: 3184, done. remote: Compressing objects: 100% (1465/1465), done. remote: Total 3184 (delta 1952), reused 2770 (delta 1675) Receiving objects: 100% (3184/3184), 677.42 KiB | 4 KiB/s, done. Resolving deltas: 100% (1952/1952), done. From git@github.com:schacon/rack * [new branch] build -> rack_remote/build * [new branch] master -> rack_remote/master * [new branch] rack-0.4 -> rack_remote/rack-0.4 * [new branch] rack-0.9 -> rack_remote/rack-0.9 $ git checkout -b rack_branch rack_remote/master Branch rack_branch set up to track remote branch refs/remotes/rack_remote/master. Switched to a new branch "rack_branch"
Ясно, что ветки master и rack_branch имеют абсолютно разные рабочие каталоги. Добавим файлы из rack_branch в master с использованием squash, чтобы избежать засорения истории ненужными нам фактами:
$ git checkout master $ git merge --squash -s subtree --no-commit rack_branch Squash commit -- not updating HEAD Automatic merge went well; stopped before committing as requested
Теперь файлы проекта rack у нас в рабочем каталоге.
Заключительное слово
Итак, я собрал вместе все знания, которые я получил за время работы с Git относительно благополучного git-merge. Я буду рад, если кому-то это поможет, но так же я буду рад, если кто-то поможет мне дополнить материал или исправить неточности и ошибки, если вдруг я допустил такие.
