
Построение lock-free структур данных зиждется на двух китах – атомарных операциях и способах упорядочения доступа к памяти. В этой статье речь пойдет об атомарности и атомарных примитивах.
Анонс. Спасибо за теплый прием Начал! Вижу, что тема lock-free интересна хабрасообществу, это меня радует. Я планировал построить цикл по академическому принципу, плавно переходя от основ к алгоритмам, попутно иллюстрируя текст кодом из libcds. Но часть читателей требует
А пока я судорожно готовлю начало Извне, — первая часть Основ. Статья во многом не о C++ (хотя и о нем тоже) и даже не о lock-free (хотя без atomic lock-free алгоритмы неработоспособны), а о реализации атомарных примитивов в современных процессорах и о базовых проблемах, возникающих при использовании таких примитивов.
Атомарность — это первый
Атомарные операции делятся на простые — чтение и запись — и операции атомарного изменения (read-modify-write, RMW). Атомарную операцию можно определить как неделимую операцию: она либо уже произошла, либо ещё нет; мы не можем увидеть никаких промежуточных стадий её выполнения, никаких частичных эффектов. В этом смысле даже простые операции чтения/записи, в принципе, могут быть не атомарными; например, чтение невыровненных данных является неатомарным: в архитектуре x86 такое чтение приведет к внутреннему исключению, заставляющему процессор читать данные частями, в других архитектурах (Sparc, Intel Itanium) – к фатальной ошибке (segmentation fault), которую, в принципе, можно перехватить и обработать, но об атомарности речи здесь быть уже не может. В современных процессорах гарантируется атомарность чтения/записи только выровненных простых (integral) типов – целых чисел и указателей. Современный компилятор гарантирует правильное выравнивание переменных базовых типов, хотя написать пример невыровненного обращения, например, к целому, не составляет труда. Если же вы хотите атомарно работать со структурой (по размеру влезающей в 4 – 8 байт), то следует самим позаботиться о правильном выравнивании с помощью директив (атрибутов) компилятора (каждый компилятор поддерживает свой уникальный способ указания выравнивания данных/типов). Кстати, библиотека libcds содержит набор вспомогательных типов и макросов, скрывающих компиляторно-зависимую часть при объявлении выровненных данных.
Compare-and-swap
Придумать алгоритм lock-free контейнера, использующего только чтение/запись, довольно сложно, если вообще возможно (мне такие структуры данных для произвольного числа потоков не известны). Поэтому разработчики процессорных архитектур внедрили RMW-операции, способные атомарно выполнить чтение выровненной ячейки памяти и запись в неё: compare-and-swap (CAS), fetch-and-add (FAA), test-and-set (TAS) и пр. В академической среде операция compare-and-swap (CAS) рассматривается как базовая; её псевдокод прост:
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
else
return false ;
}
Словами: если текущее значение переменной по адресу
pAddr равно ожидаемому nExpected, то присвоить переменной значение nNew и возвратить true, иначе возвратить false, значение переменной не изменяется. Всё это выполняется атомарно, то есть неделимо и без видимых частичных эффектов. Через CAS можно выразить все остальные RMW-операции, например, fetch-and-add будет выглядеть так:int FAA( int * pAddr, int nIncr )
{
int ncur ;
do {
ncur = *pAddr ;
} while ( !CAS( pAddr, ncur, ncur + nIncr ) ;
return ncur ;
}
“Академический” вариант операции CAS не всегда удобен на практике, ведь зачастую при неудаче CAS нам интересно, что же за значение содержится сейчас в ячейке. Поэтому часто рассматривают такой вариант CAS (так называемый valued CAS, также выполняется атомарно):
int CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return nExpected ;
}
else
return *pAddr
}
В C++11 функция
compare_exchange (строго говоря, в C++11 нет такой функции, есть её разновидности compare_exchange_strong и compare_exchange_weak, но об них я расскажу позже) покрывает оба эти варианта:bool compare_exchange( int volatile * pAddr, int& nExpected, int nNew );
Аргумент
nExpected передается по ссылке и на входе содержит ожидаемое значение переменной по адресу pAddr, а на выходе – значение перед изменением. Возвращает же функция признак успеха: true, если по адресу находится значение nExpected (в этом случае оно меняется на nNew), false в случае неудачи (тогда nExpected будет содержать текущее значение переменной по адресу pAddr). Такое универсальное построение операции CAS покрывает оба варианта “академического” определения CAS, но на практике применение compare_exchange чревато ошибками, так как надо помнить, что аргумент nExpected передается по ссылке и может быть изменен, что не всегда приемлемо. С использованием
compare_exchange примитив fetch-and-add, показанный выше, может быть написан так:int FAA( int * pAddr, int nIncr )
{
int ncur = *pAddr;
do {} while ( !compare_exchange( pAddr, ncur, ncur + nIncr ) ;
return ncur ;
}
ABA-проблема
Примитив CAS всем хорош, но при его применении возможна серьезная проблема, получившая название ABA-проблемы. Для её описания следует рассмотреть типичный паттерн использования операции CAS:
int nCur = *pAddr ;
while (true) {
int nNew = вычисляем новое значение
if ( compare_exchange( pAddr, nCur, nNew ))
break;
}
Фактически, мы “долбимся” в цикле до тех пор, пока CAS не сработает; цикл необходим, так как между чтением текущего значения переменной по адресу
pAddr и вычислением нового значения nNew переменная по адресу pAddr может быть изменена другим потоком.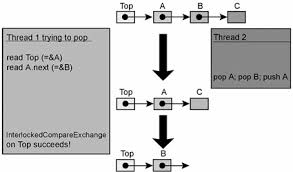
ABA-проблема описывается следующим образом: допустим, поток X читает значение A из некоторой разделяемой ячейки, содержащий указатель на некоторые данные. Затем другой поток, Y, изменяет значение этой ячейки на B и опять на A, но теперь указатель A указывает на другие данные. Когда поток X с помощью примитива CAS пытается поменять значение ячейки, сравнение указателя с предыдущим (прочтенным) значением A успешно, и результат CAS успешен, но A теперь указывает на совершенно другие данные! В результате поток может нарушить внутренние связи объекта (что, в свою очередь, может привести к краху).
Вот реализация lock-free стека, подверженного ABA-проблеме [Mic04]:
// Shared variables
static NodeType * Top = NULL; // Initially null
Push(NodeType * node) {
do {
/*Push1*/ NodeType * t = Top;
/*Push2*/ node->Next = t;
/*Push3*/ } while ( !CAS(&Top,t,node) );
}
NodeType * Pop() {
Node * next ;
do {
/*Pop1*/ NodeType * t = Top;
/*Pop2*/ if ( t == null )
/*Pop3*/ return null;
/*Pop4*/ next = t->Next;
/*Pop5*/ } while ( !CAS(&Top,t,next) );
/*Pop6*/ return t;
}
Следующая последовательность действий приводит к нарушению структуры стека (заметим, что эта последовательность не единственная, иллюстрирующая ABA-проблему):
| Thread X | Thread Y |
Вызывает Pop(). Выполнена строка Pop4, значения переменных: t == A next == A->next |
|
NodeType * pTop = Pop()pTop == вершине стека, то есть APop()Push( pTop )Теперь вершина стека – снова A Заметим, что A->next изменилось |
|
Выполняется строка Pop5. CAS успешен, но полю Top->next присваивается значение, несуществующее в стеке, так как поток Y вытолкнул из стека A и A->next,а локальная переменная nextхранит старое значение A->next |
ABA-проблема – это бич всех lock-free контейнеров, основанных на примитиве CAS. Она может возникнуть только в многопоточном коде вследствие удаления элемента A из контейнера и замены его на другой (B), а затем опять на A (отсюда и название "ABA-проблема"), в то время как другой поток держит указатель на удаляемый элемент. Даже если поток физически удалит A (
delete A), а затем вызовет new для создания нового элемента, нет никаких гарантий, что аллокатор не возвратит адрес A (хорошие аллокаторы именно так и сделают). Часто она проявляется более изощренным образом, чем описано выше, затрагивает не два, а более потоков (в этом смысле можно говорить о ABCBA-проблеме, ABABA-проблеме и т.д., насколько хватит фантазии), и её идентификация всегда является нетривиальной задачей. Средство борьбы с ABA-проблемой – отложенное физическое удаление (deferred deallocation, или safe memory reclamation) элемента в момент, когда есть полная гарантия, что никто (ни один из конкурирующих потоков) не имеет ни локальных, ни глобальных ссылок на удаляемый элемент. Таким образом, удаление элемента из lock-free структуры является двухфазным:
- Первая фаза – исключение элемента из lock-free контейнера;
- Вторая фаза (отложенная) – физическое удаление элемента, когда нет никаких ссылок на него.
Я подробно остановлюсь на различных схемах отложенного удаления в одной из следующих статей.
Load-Linked / Store-Conditional
Наверное, наличие ABA-проблемы при использовании CAS подтолкнуло проектировщиков процессоров к поиску других RMW-операций, не подверженных ABA-проблеме. И такие операции были найдены – пара load-linked/store-conditional (LL/SC). Эти операции очень просты – вот их псевдокод:
word LL( word * pAddr ) {
return *pAddr ;
}
bool SC( word * pAddr, word New ) {
if ( данные в pAddr не изменились с момента вызова LL) {
*pAddr = New ;
return true ;
}
else
return false ;
}
Пара LL/SC работает как операторные скобки. Операция load-linked (LL) просто возвращает текущее значение переменной по адресу
pAddr. Операция store-conditional (SC) выполняет сохранение в ранее прочитанный операцией LL адрес pAddr только в том случае, если данные в pAddr не изменились с момента чтения. При этом под изменением понимается любая модификация кеш-линии, к которой относится адрес pAddr. Для реализации пары LL/SC разработчикам процессоров пришлось изменить структуру кеша: грубо говоря, каждая кеш-линия должна иметь дополнительный бит статуса. При чтении операцией LL этот бит устанавливается (link), при любой записи в кеш-линию (или её вытеснении из кеша) бит сбрасывается, а операция SC перед сохранением проверяет, выставлен ли данный бит у кеш-линии: если бит = 1, то есть никто не изменил кеш-линию, значение по адресу pAddr меняется на новое и операция SC успешна, иначе операция неуспешна, значение по адресу pAddr не изменяется. Примитив CAS можно реализовать с помощью пары LL/SC примерно так:
bool CAS( word * pAddr, word nExpected, word nNew ) {
if ( LL( pAddr ) == nExpected )
return SC( pAddr, nNew ) ;
return false ;
}
Заметим, что, несмотря на многошаговость данного кода, он выполняет атомарный CAS: содержимое целевой ячейки памяти либо не меняется, либо атомарно изменяется. Реализация пары LL/SC на архитектурах, поддерживающих только примитив CAS, возможна, но не столь примитивна; я не буду здесь её рассматривать, интересующихся отсылаю к статье [Mic04].
Современные архитектуры процессоров делятся на два больших лагеря – одни поддерживают в своей системе команд CAS-примитив, другие – пару LL/SC. CAS реализован в архитектурах x86, Intel Itanium, Sparc; впервые примитив появился в архитектуре IBM System 370. Пара LL/SC – это архитектуры PowerPC, MIPS, Alpha, ARM; впервые предложена DEC. Стоит отметить, что примитив LL/SC реализован в современных архитектурах не самым идеальным образом: например, нельзя делать вложенные вызовы LL/SC с разными адресами, возможны ложные сбросы флага linked (так называемый false sharing, см. ниже), нет примитива валидации флага linked внутри пары LL/SC.
С точки зрения C++, стандарт C++11 не рассматривает пару LL/SC, а описывает только атомарный примитив
compare_exchange (CAS) и производные от него атомарные примитивы – fetch_add, fetch_sub, exchange и пр. Стандарт подразумевает, что реализовать CAS с помощью LL/SC довольно просто, а вот обратная реализация – LL/SC через CAS – весьма нетривиальна. Поэтому, чтобы не усложнять жизнь разработчикам стандартной библиотеки C++, комитет по стандартизации ввел в C++ только compare_exchange, которого, в принципе, достаточно для реализации lock-free алгоритмов.False sharing
В современных процессорах длина линии кэша L (cache line) составляет 64 – 128 байт и имеет тенденцию к увеличению в новых моделях. Обмен данными между основной памятью и кэшем осуществляется блоками по L байт (обычно L – степень двойки). При изменении хотя бы одного байта в линии кэша вся линия считается инвалидной и требует синхронизации с основной памятью. Этим управляет протокол поддержки когерентности кэшей в мультипроцессорной/ мультиядерной архитектуре.
Протокол MESI поддержки когерентности кэша
Например ([Cha05]), протокол MESI (Modified — Exclusive — Shared – Invalid) поддержки когерентности кэшей процессоров Intel помечает линию кэша как инвалидную при каждой записи в разделяемую (shared) линию, что приводит к интенсивному обмену с памятью. При первой загрузке данных в линию кэша, MESI помечает эту линию как E (Exclusive), что дает процессору возможность производить неограниченное число чтений/записи данных в линию кэша. Если другой процессор требует доступа к тем же самым данным, которые расположены в кэше этого другого процессора, MESI помечает линию кэша как S (Shared). Теперь любая инструкция записи в такую линию в любом кэше приводит к пометке линии как M (Modified), что, в свою очередь, приводит к отметке этой линии как I (Invalidate) в кэшах других процессоров и, как следствие, загрузке данных из основной памяти. Сейчас я не буду подробно останавливаться на протоколе MESI, так как планирую в одной из следующих заметок привести перевод замечательной статьи, посвященной внутренней организации современных процессоров, где в том числе будет рассмотрен и MESI.

Если разные разделяемые данные попадают в одну линию кэша (то есть расположены в смежных адресах), то изменение одних данных приводит, с точки зрения процессора, к инвалидации других, находящихся в той же линии кэша. Эта ситуация называется false sharing (ложное связывание). Для примитивов LL/SC false sharing губителен, так как реализация этих примитивов выполнена как раз в терминах линий кэша: операция Load-Linked помечает (link) линию кэша, а операция Store-Conditional перед записью проверяет, не сброшен ли флаг link для данной линии; если флаг сброшен, записи не выполняется и SC возвращает false. Так как длина линии L довольно большая, то ложное несрабатывание примитива SC (то есть сброс флага link) случается при любом изменении линии кэша, не связанном с целевыми данными. Как результат – мы можем получить livelock: ситуацию, когда процессоры/ядра заняты на 100%, но никакого прогресса нет.
Борьба с false sharing довольно проста (но расточительна): каждая shared-переменная должна занимать линию кэша целиком; для этого обычно используют заполнение (padding):
struct Foo {
int volatile nShared1;
char _padding1[64]; // padding for cache line=64 byte
int volatile nShared2;
char _padding2[64]; // padding for cache line=64 byte
};
Следует отметить, что физическая структура кэша влияет на все операции (в том числе и на CAS), а не только на примитивы LL/SC. В некоторых работах исследуются структуры данных, специальным образом построенные с учетом структуры кэша (в основном, с учетом длины линии кэша); при правильном (“под кэш”) построении структуры данных производительность может увеличиться на порядок.
Разновидности CAS
Кратко остановлюсь ещё на двух полезных атомарных примитивах – CAS двойной ширины (double-word CAS, dwCAS) и двойной CAS (DCAS).
CAS двойной ширины аналогичен обычному CAS, но оперирует с ячейкой памяти удвоенного размера: 64-битовой для 32-битовых архитектур и 128-битовой (точнее, как минимум 96-битовой) для 64-битовых. Для архитектур, предоставляющих пару LL/SC вместо CAS, LL/SC должны оперировать также словами двойной длины. Из знакомых мне архитектур только x86 поддерживает dwCAS. Чем же так полезен этот примитив? Он позволяет организовать одну из первых схем решения ABA-проблемы – tagged pointers. Эта схема была предложена IBM как раз для решения ABA-проблемы и заключается в сопоставлении каждому разделяемому указателю тега – целого числа; tagged pointer может быть описан следующей структурой:
template <typename T>
struct tagged_pointer {
T * ptr ;
uintptr_t tag ;
tagged_pointer()
: ptr( new T )
, tag( 1 )
{}
};
Для обеспечения атомарности, переменные этого типа должны быть выровнены по двойному слову: 8 байт для 32-битовых архитектур и 16 байт для 64-битовых. Тег содержит “номер версии” данных, на которые указывает
ptr. Я подробно расскажу о tagged pointers в одной из следующих статей, посвященной безопасному управлению памяти (safe memory reclamation, SMR), здесь же только отмечу тот факт, что tagged pointers подразумевает, что память, однажды выделенная под данные типа T (и соответствующий tagged_pointer) не должна физически удаляться (delete), а должна помещаться во free-list (отдельный для каждого типа T), из которого в дальнейшем данные будут вновь распределяться с инкрементированием тега. Именно это и дает решение ABA-проблемы: фактически, указатель у нас составной и содержит в теге номер версии (порядковый номер распределения); в этом случае dwCAS не будет успешным, если в его аргументах типа tagged_pointer указатели равны, а значения тегов отличаются.Второй атомарный примитив – двойной CAS (DCAS) – является в настоящий момент чисто гипотетическим и не реализован ни в одной из современных процессорных архитектур. Псевдокод DCAS таков:
bool DCAS( int * pAddr1, int nExpected1, int nNew1,
int * pAddr2, int nExpected2, int nNew2 )
atomically {
if ( *pAddr1 == nExpected1 && *pAddr2 == nExpected2 ) {
*pAddr1 = nNew1 ;
*pAddr2 = nNew2 ;
return true ;
}
else
return false
}
DCAS оперирует над двумя произвольными выровненными ячейками памяти и меняет значения в обоих, если текущие значения совпадают с ожидаемыми.
Почему данный примитив так интересен? Дело в том, что с его помощью довольно легко можно построить lock-free двусвязный список (deque, double-linked list), а такая структура данных является основой многих интересных алгоритмов. Существует большое число академических работ, посвящённых структурам данных, основанным на DCAS. Хотя этот примитив и не реализован “в железе”, есть работы (например, [Fra03] — наиболее известная из них), описывающие алгоритм построения DCAS (и вообще multi-CAS для сколь угодного числа адресов
pAddr1 … pAddrN) на основе обычного CAS.Производительность

А как обстоит дело с производительностью атомарных примитивов?
Современные процессоры настолько сложны и непредсказуемы, что изготовители не дают каких-то однозначных гарантий длительности тех или иных инструкций, тем более атомарных, в работе которых задействованы внутренняя синхронизация, сигнализация по шинам процессора и пр. Существует довольно большое число работ, в которых авторы пытаются замерить длительность инструкций процессоров. Я приведу измерения из [McKen05]. В этой работе авторы, помимо прочего, сравнивают длительность атомарного инкремента и примитива CAS с длительностью операции
nop (no-operation). Итак, для Intel Xeon 3.06 ГГц (образца 2005 года) атомарный инкремент имеет длительность 400 nop, CAS – 850 – 1000 nop. Процессор IBM Power4 1.45 ГГц: 180 nop для атомарного инкремента и 250 nop для CAS. Измерения довольно старые (2005 год), за прошедшее время архитектура процессоров сделала ещё несколько шагов вперед, но порядок цифр, я думаю, остался прежним. Как видите, атомарные примитивы довольно тяжеловесны. Поэтому применять их повсеместно довольно накладно: например, если алгоритм поиска по бинарному дереву использует CAS для чтения текущего узла дерева, ничего хорошего я от такого алгоритма не жду (а такие алгоритмы я видел). Справедливости ради стоит заметить, что, по моим ощущениям, с каждым новым поколением архитектуры Intel Core примитив CAS становится всё быстрее, видимо, инженеры Intel немало сил вкладывают в совершенствование микроархитектуры.
Volatile и атомарность
В C++ есть загадочное ключевое слово
volatile. Иногда volatile связывают с атомарностью и упорядочением — это неправильно, но имеет под собой некоторые исторические основания. По сути,
volatile гарантирует только, что компилятор не будет кэшировать значение в регистре (оптимизирующие компиляторы очень любят это делать: чем больше регистров — тем больше кэшируют). То есть чтение volatile-переменной всегда означает чтение из памяти, запись volatile-перемнной — всегда запись в память. Поэтому если кто-то параллельно будет изменять volatile-данные, мы это сразу увидим. На самом деле, не увидим. По причине как раз отсутствия барьеров памяти. В некоторых языках (Java, C#)
volatile присвоен магический статус, обеспечивающий упорядочение, но не в C++11. И никакого особого выравнивания volatile не гарантирует, а мы теперь знаем, что необходимым условием атомарности является как раз правильное выравнивание данных.Таким образом, для C++11-совместимого компилятора указание
volatile для атомарной переменной излишне. А вот для старого компилятора бывает необходимо, если вы сами реализуете atomic. В таком объявлении:class atomic_int {
int m_nAtomic;
//….
};
компилятор имеет полное право «оптимизировать» обращения к
m_nAtomic (несмотря на то, что обращение идет косвенно, через this). Поэтому нелишним будет указать здесь int volatile m_nAtomic.volatile-методы в C++
Изучая интерфейс
Что это? Указатель
По аналогии с
Ну и напомню, что спецификаторы
Это можно трактовать так:
atomic, вы наверняка обратите внимание, что многие его методы имеют спецификатор volatile:void store( T val ) volatile ;
Что это? Указатель
this является volatile (то есть, имеет тип T * volatile)? Вообще, это невозможно, — this часто передается в регистре, и это специфицировано в некоторых ABI. На самом деле, это тип T volatile * .По аналогии с
const-методами, этот спецификатор говорит, что this указывает на volatile-данные, то есть все данные-члены объекта являются volatile в таком методе. Что, в свою очередь, запрещает компилятору оптимизировать обращения к данным-членам. В принципе, то же самое, как если бы мы объявили эти данные как volatile.Ну и напомню, что спецификаторы
const и volatile — это не противоположности, они могут существовать вместе. Вот объявление метода чтения в atomic<T>:T load() const volatile ;
Это можно трактовать так:
const— метод сам не изменяет данные-члены объектаvolatile— но данные-члены могут быть параллельно изменены кем-то другим, поэтому не следует их кешировать
libcds
В заключение – что мы имеем в библиотеке libcds? А имеем мы
libcds использует свою реализацию атомарных примитивов. При этом основным атомарным примитивом при построении lock-free структур данных, помимо обычных атомарных чтения/записи, является CAS, очень редко где используется CAS над двойным словом (dwCAS). Реализации DCAS (и вообще multi-CAS) в libcds [пока] нет, но вполне возможно, что появится в будущем, – уж очень интересные структуры данных можно на нем построить. Останавливает только то, что, согласно многим исследованиям, реализация DCAS по алгоритму [Fra03] довольно неэффективна. Но ведь я уже отмечал, что критерий эффективности – вещь сугубо индивидуальная в мире lock-free: то, что неэффективно сейчас и на этом железе и для этой задачи, может оказаться крайне эффективным потом или на другом железе или для другой задачи!В следующей статье Основ речь пойдет об упорядочении обращения к памяти (memory ordering) – о барьерах памяти (memory fence, memory barrier).
Cсылки:
[Cha05] Dean Chandler Reduce False Sharing in .NET, 2005, Intel Corporation
[Fra03] Keir Fraser Practical Lock Freedom, 2004; technical report is based on a dissertation submitted September 2003 by K.Fraser for the degree of Doctor of Philosophy to the University of Cambridge, King's College
[McKen05] Paul McKenney, Thomas Hart, Jonathan Walpole Practical Concerns for Scalable Synchronization
[Mic04] Maged Michael ABA Prevention using single-word instruction, IBM Research Report, 2004
Lock-free структуры данных
