От переводчика: данный текст даётся с незначительными сокращениями по причине местами излишней «разжёванности» материала. Автор абсолютно справедливо предупреждает, что отдельные темы могут показаться читателю чересчур простыми или общеизвестными. Тем не менее, лично мне этот текст помог упорядочить имеющиеся знания по анализу сложности алгоритмов. Надеюсь, что он окажется полезен и кому-то ещё.
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2
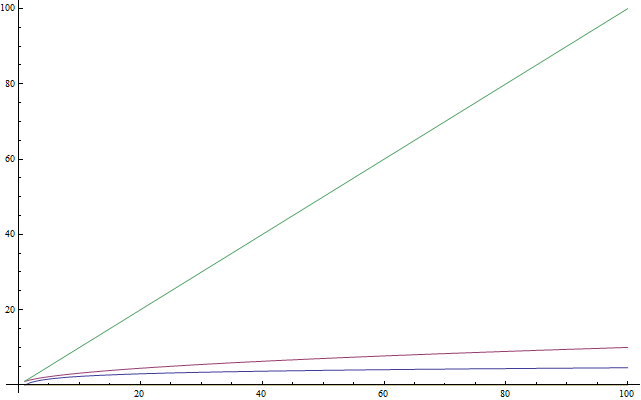
Если вы знаете, что такое логарифмы, то можете спокойно пропустить этот раздел. Глава предназначается тем, кто незнаком с данным понятием или пользуется им настолько редко, что уже забыл что там к чему. Логарифмы важны, поскольку они очень часто встречаются при анализе сложности. Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция
Поясню на примере. Рассмотрим уравнение
Чтобы найти из него
Практическая рекомендация: на соревнованиях алгоритмы часто реализуются на С++. Как только вы проанализировали сложность вашего алгоритма, так сразу можете получить и грубую оценку того, как быстро он будет работать, приняв, что в секунду выполняется 1 000 000 команд. Их количество считается из полученной вами функции асимптотической оценки, описывающей алгоритм. Например, вычисление по алгоритму с Θ( n ) займёт около секунды при n = 1 000 000.
А теперь давайте обратимся к рекурсивным функциям. Рекурсивная функция — это функция, которая вызывает сама себя. Можем ли мы проанализировать её сложность? Следующая функция, написанная на Python, вычисляет факториал заданного числа. Факториал целого положительного числа находится как произведение всех предыдущих положительных целых чисел. Например, факториал 5 — это
Давайте проанализируем эту функцию. Она не содержит циклов, но её сложность всё равно не является константной. Что ж, придётся вновь заняться подсчётом инструкций. Очевидно, что если мы применим эту функцию к некоторому
Если вы всё же не уверены в этом, то вы всегда можете найти точную сложность путём подсчёта количества инструкций. Примените этот метод к данной функции, чтобы найти её f( n ), и убедитесь, что она линейная (напомню, что линейность означает
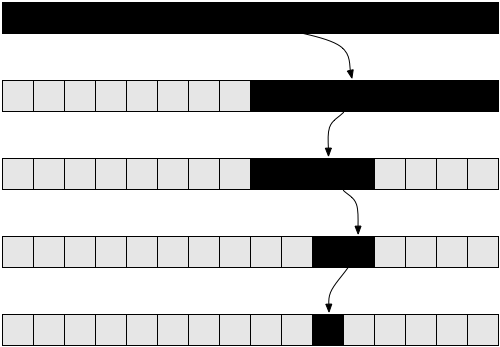
Одной из известнейших задач в информатике является поиск значения в массиве. Мы уже решали её ранее для общего случая. Задача становится интереснее, если у нас есть отсортированный массив, в котором мы хотим найти заданное значение. Одним из способов сделать это является бинарный поиск. Мы берём средний элемент из нашего массива: если он совпадает с тем, что мы искали, то задача решена. В противном случае, если заданное значение больше этого элемента, то мы знаем, что оно должно лежать в правой части массива. А если меньше — то в левой. Мы будем разбивать эти подмассивы до тех пор, пока не получим искомое.
Вот реализация такого метода в псевдокоде:
Приведённый псевдокод — упрощение настоящей реализации. На практике этот метод описать проще, чем воплотить, поскольку программисту нужно решить некоторые дополнительные вопросы. Например, защиту от ошибок на одну позицию (off-by-one error, OBOE), да и деление на два не всегда может давать целое число, поэтому потребуется применять функции
Если вы не уверены, что метод работает в принципе, то отвлекитесь и решите вручную какой-нибудь простой пример.
Теперь давайте попробуем проанализировать этот алгоритм. Ещё раз, в этом случае мы имеем рекурсивный алгоритм. Давайте для простоты предположим, что массив всегда разбивается ровно пополам, игнорируя +1 и -1 части в рекурсивном вызове. К этому моменту вы должны быть уверены, что такое небольшое изменение, как игнорирование +1 и -1, не повлияет на конечный результат оценки сложности. В принципе, обычно этот факт необходимо доказывать, если мы хотим проявить осторожность с математической точки зрения. Но на практике это очевидно на уровне интуиции. Также для простоты давайте предположим, что наш массив имеет размер одной из степеней двойки. Опять-таки, это предположение никоим образом не повлияет на конечный результат расчёта сложности алгоритма. Наихудшим сценарием для данной задачи будет вариант, когда массив в принципе не содержит искомое значение. В этом случае мы начинаем с массива размером
0-я итерация:
1-я итерация:
2-я итерация:
3-я итерация:
…
i-я итерация:
…
последняя итерация:
Заметьте, что на i-й итерации массив имеет
Равенство будет истинным только тогда, когда мы достигнем конечного вызова функции
Если вы прочли раздел о логарифмах выше, то такое выражение будет для вас знакомым. Решив его, мы получим:
Этот ответ говорит нам, что количество итераций, необходимых для бинарного поиска, равняется
Если немного подумать, то это имеет смысл. Например, возьмём
Последний результат позволяет нам сравнивать бинарный поиск с линейным (нашим предыдущим методом). Несомненно,
Практическая рекомендация: улучшение асимптотического времени выполнения программы часто чрезвычайно повышает её производительность. Намного сильнее, чем небольшая «техническая» оптимизация в виде использования более быстрого языка программирования.
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2
Логарифмы

Если вы знаете, что такое логарифмы, то можете спокойно пропустить этот раздел. Глава предназначается тем, кто незнаком с данным понятием или пользуется им настолько редко, что уже забыл что там к чему. Логарифмы важны, поскольку они очень часто встречаются при анализе сложности. Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция
f(n) = n, красный — f(n) = sqrt(n), а наименее быстро возрастающий — f(n) = log(n). Далее: подобно тому, как взятие квадратного корня является операцией, обратной возведению в квадрат, логарифм — обратная операция возведению чего-либо в степень. Поясню на примере. Рассмотрим уравнение
2x = 1024Чтобы найти из него
x, спросим себя: в какую степень надо возвести 2, чтобы получить 1024? Ответ: в десятую. В самом деле, 210 = 1024, что легко проверить. Логарифмы помогают нам описать данную задачу, используя новую нотацию. В данном случае, 10 является логарифмом 1024 и записывается, как log( 1024 ). Читается: «логарифм 1024». Поскольку мы использовали 2 в качестве основания, то такие логарифмы называются «по основанию 2». Основанием может быть любое число, но в этой статье мы будем использовать только двойку. Если вы ученик-олимпиадник и не знакомы с логарифмами, то я рекомендую вам попрактиковаться после того, как закончите чтение этой статьи. В информатике логарифмы по основанию 2 распространены больше, чем какие-либо другие, поскольку часто мы имеем всего две сущности: 0 и 1. Также существует тенденция разбивать объёмные задачи пополам, а половин, как известно, тоже бывает всего две. Поэтому для дальнейшего чтения статьи вам достаточно иметь представление только о логарифмах по основанию 2.Упражнение 7
Решите уравнения ниже, записывая логарифмы, которые вы ищете. Используйте только логарифмы по основанию 2.
- 2x = 64
- (22)x = 64
- 4x = 4
- 2x = 1
- 2x + 2x = 32
- (2x) * (2x) = 64
Решение
Здесь не нужно ничего сверх идей, изложенных выше.
- Методом проб и ошибок, находим, что
x = 6. Таким образом,log( 64 ) = 6 - По свойству степеней (22)x можно записать как 22x. Таким образом, получим, что
2x = 6(потому чтоlog( 64 ) = 6из предыдущего примера) и, следовательно,x = 3 - Используя знания, полученные при решении предыдущего примера, запишем 4 как 22. Тогда наше уравнение превратится в (22)x = 4, что эквивалентно 22x. Заметим, что log( 4 ) = 2 (поскольку 22 = 4), так что мы получаем
2x = 2, откудаx = 1. Это легко заметить по исходному уравнению, поскольку степень 1 даёт основание в качестве результата - Вспомнив, что степень 0 даёт результатом 1 (т.е.
log( 1 ) = 0), получимx = 0 - Здесь мы имеем дело с суммой, поэтому непосредственно взять логарифм не получится. Однако, мы замечаем, что
2x+ 2x — это тоже самое, что и2 * (2x). Умножение на 2 даст2x + 1, и мы получим уравнение2x + 1= 32. Находим, чтоlog( 32 ) = 5, откудаx + 1 = 5иx = 4. - Мы перемножаем две степени двойки, следовательно, можем объединить их в 22x. Остаётся просто решить уравнение
22x= 64, что мы уже делали выше. Ответ:x = 3
Практическая рекомендация: на соревнованиях алгоритмы часто реализуются на С++. Как только вы проанализировали сложность вашего алгоритма, так сразу можете получить и грубую оценку того, как быстро он будет работать, приняв, что в секунду выполняется 1 000 000 команд. Их количество считается из полученной вами функции асимптотической оценки, описывающей алгоритм. Например, вычисление по алгоритму с Θ( n ) займёт около секунды при n = 1 000 000.
Рекурсивная сложность
А теперь давайте обратимся к рекурсивным функциям. Рекурсивная функция — это функция, которая вызывает сама себя. Можем ли мы проанализировать её сложность? Следующая функция, написанная на Python, вычисляет факториал заданного числа. Факториал целого положительного числа находится как произведение всех предыдущих положительных целых чисел. Например, факториал 5 — это
5 * 4 * 3 * 2 * 1. Обозначается он как «5!» и произносится «факториал пяти» (впрочем, некоторые предпочитают «ПЯТЬ!!!11»).def factorial( n ):
if n == 1:
return 1
return n * factorial( n - 1 )
Давайте проанализируем эту функцию. Она не содержит циклов, но её сложность всё равно не является константной. Что ж, придётся вновь заняться подсчётом инструкций. Очевидно, что если мы применим эту функцию к некоторому
n, то она будет вычисляться n раз. (Если вы в этом не уверены, то можете вручную расписать ход вычисления при n = 5, чтобы определить, как это на самом деле работает.) Таким образом, мы видим, что эта функция является Θ( n ).Если вы всё же не уверены в этом, то вы всегда можете найти точную сложность путём подсчёта количества инструкций. Примените этот метод к данной функции, чтобы найти её f( n ), и убедитесь, что она линейная (напомню, что линейность означает
Θ( n )).Логарифмическая сложность
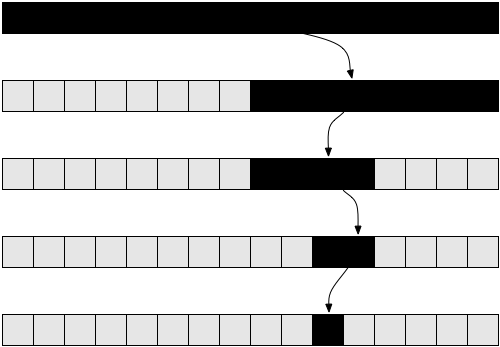
Одной из известнейших задач в информатике является поиск значения в массиве. Мы уже решали её ранее для общего случая. Задача становится интереснее, если у нас есть отсортированный массив, в котором мы хотим найти заданное значение. Одним из способов сделать это является бинарный поиск. Мы берём средний элемент из нашего массива: если он совпадает с тем, что мы искали, то задача решена. В противном случае, если заданное значение больше этого элемента, то мы знаем, что оно должно лежать в правой части массива. А если меньше — то в левой. Мы будем разбивать эти подмассивы до тех пор, пока не получим искомое.
Вот реализация такого метода в псевдокоде:
def binarySearch( A, n, value ):
if n = 1:
if A[ 0 ] = value:
return true
else:
return false
if value < A[ n / 2 ]:
return binarySearch( A[ 0...( n / 2 - 1 ) ], n / 2 - 1, value )
else if value > A[ n / 2 ]:
return binarySearch( A[ ( n / 2 + 1 )...n ], n / 2 - 1, value )
else:
return true
Приведённый псевдокод — упрощение настоящей реализации. На практике этот метод описать проще, чем воплотить, поскольку программисту нужно решить некоторые дополнительные вопросы. Например, защиту от ошибок на одну позицию (off-by-one error, OBOE), да и деление на два не всегда может давать целое число, поэтому потребуется применять функции
floor() или ceil(). Однако, предположим, что в нашем случае деление всегда будет успешным, наш код защищён от ошибок off-by-one, и всё, что мы хотим — это проанализировать сложность данного метода. Если вы никогда раньше не реализовывали бинарный поиск, то можете сделать это на вашем любимом языке программирования. Такая задача по-настоящему поучительна.Если вы не уверены, что метод работает в принципе, то отвлекитесь и решите вручную какой-нибудь простой пример.
Теперь давайте попробуем проанализировать этот алгоритм. Ещё раз, в этом случае мы имеем рекурсивный алгоритм. Давайте для простоты предположим, что массив всегда разбивается ровно пополам, игнорируя +1 и -1 части в рекурсивном вызове. К этому моменту вы должны быть уверены, что такое небольшое изменение, как игнорирование +1 и -1, не повлияет на конечный результат оценки сложности. В принципе, обычно этот факт необходимо доказывать, если мы хотим проявить осторожность с математической точки зрения. Но на практике это очевидно на уровне интуиции. Также для простоты давайте предположим, что наш массив имеет размер одной из степеней двойки. Опять-таки, это предположение никоим образом не повлияет на конечный результат расчёта сложности алгоритма. Наихудшим сценарием для данной задачи будет вариант, когда массив в принципе не содержит искомое значение. В этом случае мы начинаем с массива размером
n на первом рекурсивном вызове, n / 2 на втором, n / 4 на третьем и так далее. В общем, наш массив разбивается пополам на каждом вызове до тех пор, пока мы не достигнем единицы. Давайте запишем количество элементов в массиве на каждом вызове:0-я итерация:
n1-я итерация:
n / 22-я итерация:
n / 43-я итерация:
n / 8…
i-я итерация:
n / 2i…
последняя итерация:
1Заметьте, что на i-й итерации массив имеет
n / 2i элементов. Мы каждый раз разбиваем его пополам, что подразумевает деление количества элементов на два (равноценно умножению знаменателя на два). Проделав это i раз, получим n / 2i. Процесс будет продолжаться, и из каждого большого i мы будем получать меньшее количество элементов до тех пор, пока не достигнем единицы. Если мы захотим узнать, на какой итерации это произошло, нам нужно будет просто решить следующее уравнение:1 = n / 2iРавенство будет истинным только тогда, когда мы достигнем конечного вызова функции
binarySearch(), так что узнав из него i, мы будем знать номер последней рекурсивной итерации. Умножив обе части на 2i, получим:2i = nЕсли вы прочли раздел о логарифмах выше, то такое выражение будет для вас знакомым. Решив его, мы получим:
i = log( n )Этот ответ говорит нам, что количество итераций, необходимых для бинарного поиска, равняется
log( n ), где n — размер оригинального массива. Если немного подумать, то это имеет смысл. Например, возьмём
n = 32 (массив из 32-х элементов). Сколько раз нам потребуется разделить его, чтобы получить один элемент? Считаем: 32 → 16 → 8 → 4 → 2 → 1 — итого 5 раз, что является логарифмом 32. Таким образом, сложность бинарного поиска равна Θ( log( n ) ).Последний результат позволяет нам сравнивать бинарный поиск с линейным (нашим предыдущим методом). Несомненно,
log( n ) намного меньше n, из чего правомерно заключить, что первый намного быстрее второго. Так что имеет смысл хранить массивы в отсортированном виде, если мы собираемся часто искать в них значения.Практическая рекомендация: улучшение асимптотического времени выполнения программы часто чрезвычайно повышает её производительность. Намного сильнее, чем небольшая «техническая» оптимизация в виде использования более быстрого языка программирования.
