В данном посте я попытаюсь описать основания и особенности использования аппаратной поддержки виртуализации компьютеров. Начну с определения трёх необходимых условий виртуализации и формулировки теоретических оснований для их достижения. Затем перейду к описанию того, какое отражение теория находит в суровой реальности. В качестве иллюстраций будет кратко описано, как различные вендоры процессоров различных архитектур реализовали виртуализацию в своей продукции. В конце будет затронут вопрос рекурсивной виртуализации.
Сперва — несколько определений, может быть, не совсем типичных для статей по данной тематике, но используемых в этой заметке.
Остальную терминологию я постараюсь определять по мере появления в тексте.
Виртуализация представляла интерес ещё до изобретения микропроцессора, во времена преобладания больших систем — мейэнфреймов, ресурсы которых были очень дорогими, и их простой был экономически недопустим. Виртуализация позволяла повысить степень утилизации таких систем, при этом избавив пользователей и прикладных программистов от необходимости переписывать своё ПО, так как с их точки зрения виртуальная машина была идентична физической. Пионером в этой области являлась фирма IBM с мэйнфреймами System/360, System/370, созданными в 1960-1970-х гг.
Неудивительно, что критерии возможности создания эффективного монитора виртуальных машин были получены примерно в то же время. Они сформулированы в классической работе 1974 г. Жеральда Попека и Роберта Голдберга «Formal requirements for virtualizable third generation architectures» [8]. Рассмотрим её основные предпосылки и сформулируем её основной вывод.
В дальнейшем используется упрощённое представление «стандартной» ЭВМ из статьи, состоящей из одного центрального процессора и линейной однородной оперативной памяти. Периферийные устройства, а также средства взаимодействия с ними опускаются. Процессор поддерживает два режима работы: режим супервизора, используемый операционной системой, и режим пользователя, в котором исполняются прикладные приложения. Память поддерживает режим сегментации, используемый для организации виртуальной памяти.
Выдвигаемые требования на монитор виртуальных машин (ВМ):
Состояние процессора содержит минимум три регистра: M, определяющий, находится ли он в режиме супервизора s или пользователя u, P — указатель текущей инструкции и R — состояние, определяющее границы используемого сегмента памяти (в простейшем случае R задаёт отрезок, т.е. R = (l,b), где l — адрес начала диапазона, b — его длина).
Память E состоит из фиксированного числа ячеек, к которым можно обращаться по их номеру t, например, E[t]. Размер памяти и ячеек для данного рассмотрения несущественен.
При исполнении каждая инструкция i в общем случае может изменить как (M,P,R), так и память E, т.е. она является функцией преобразования: (M1,P1,R1,E1) -> (M2,P2,R2,E2).
Считается, что для некоторых входных условий инструкция вызывает исключение ловушки (англ. trap), если в результате её исполнения содержимое памяти не изменяется, кроме единственной ячейки E[0], в которую помещается предыдущее состояние процессора (M1,P1,R1). Новое состояние процессора (M2,P2,R2) при этом копируется из E[1]. Другими словами, ловушка позволяет сохранить полное состояние программы на момент до начала исполнения её последней инструкции и передать управление обработчику, в случае обычных систем обычно работающему в режиме супервизора и призванного обеспечить дополнительные действия над состоянием системы, а затем вернуть управление в программу, восстановив состояние из E[0].
Далее, ловушки могут иметь два признака.
Отметим, что эти признаки не взаимоисключающие. То есть результатом исполнения могут быть одновременно ловушка потока управления и защиты памяти.
Машинные инструкции рассматриваемого процессора можно классифицировать следующим образом:
Соблюдение трёх сформулированных выше условий возможности построения монитора виртуальных машин даётся в следующем предложении: множество служебных инструкций является подмножеством привилегированных инструкций (рис. 1). Опуская формальное доказательство теоремы 1 из статьи, отметим следующие обстоятельства.
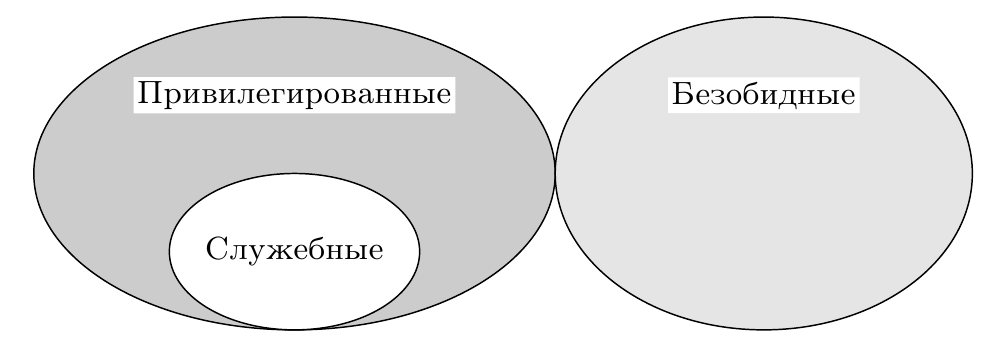
Рис. 1: Выполнение условия виртуализуемости. Множество служебных инструкций является подмножеством привилегированных
Несмотря на простоту использованной модели и полученных из неё выводов, работа Голдберга и Попека является актуальной до сих пор. Следует отметить, что несоблюдение описанных в ней условий вовсе не делает создание или использование виртуальных машин на некоторой архитектуре принципиально невозможным, и есть практические примеры реализаций, подтверждающие это. Однако соблюсти оптимальный баланс между тремя свойствами: изоляцией, эквивалентностью и эффективностью, — становится невозможным. Чаще всего расплачиваться приходится скоростью работы виртуальных машин из-за необходимости тщательного поиска и программного контроля за исполнением ими служебных, но не привилегированных инструкций, так как сама аппаратура не обеспечивает этого (рис. 2). Даже единственная такая инструкция, исполненная напрямую ВМ, угрожает стабильной работе монитора, и поэтому он вынужден сканировать весь поток гостевых инструкций.
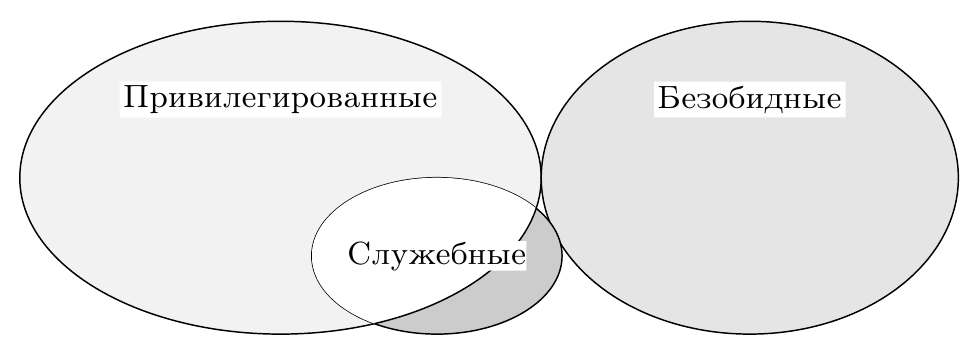
Рис. 2: Невыполнение условия виртуализуемости. Служебные, но не привилегированные инструкции требуют реализации сложной логики в мониторе
В самой работе [8] присутствуют как явно указанные упрощения исследуемой структуры реальных систем (отсутствие периферии и системы ввода-вывода), так и неявные предположения о структуре исполняемых гостевых программ (почти полностью состоящих из безвредных инструкций) и хозяйских систем (однопроцессорность).
Рассмотрим теперь данные ограничения более детально, а также предложим, каким образом можно расширить степень применимости критерия к дополнительным ресурсам, требующим виртуализации, и таким образом повысить его практическую ценность для архитекторов новых вычислительных систем.
Для эффективной работы программ внутри ВМ необходимо, чтобы большая часть их инструкций являлись безвредными. Как правило, это верно для прикладных приложений. Операционные системы, в свою очередь, предназначены для управления ресурсами системы, что подразумевает использование ими привилегированных и служебных инструкций, и монитору приходится их перехватывать и интерпретировать с соответствующим падением производительности. Поэтому в идеале в наборе инструкций должно быть как можно меньше привилегированных для того, чтобы частота возникновения ловушек была минимальной.
Поскольку периферийные устройства являются служебным ресурсом ЭВМ, очевидно, что для обеспечения условий изоляции и эквивалентности необходимо, чтобы все попытки доступа к ним были контролируемы монитором ВМ так же, как они контролируются в многозадачной операционной системе её ядром. В настоящее время доступ к устройствам чаще всего производится через механизм отражения их в физической памяти системы (англ. memory mapped I/O), что означает, что внутри монитора это чтение/запись некоторых регионов должно или вызывать ловушку защиты памяти, или быть не служебным, т.е. не вызывать ловушку и не влиять на состояние неконтролируемым образом.
Интенсивность взаимодействия приложений с периферией может быть различна и определяется их функциональностью, что сказывается на их замедлении при виртуализации. Кроме того, монитор ВМ может делать различные классы периферии, присутствующей на хозяине, доступными внутри нескольких ВМ различными способами.
Прерывания являются механизмом оповещения процессора о событиях внешних устройств, требующих внимания операционной системы. В случае использования виртуальных машин монитор должен иметь возможность контролировать доставку прерываний, так как часть или все из них необходимо обрабатывать именно внутри монитора. Например, прерывание таймера может быть использовано им для отслеживания/ограничения использования гостями процессорного времени и для возможности переключения между несколькими одновременно запущенными ВМ. Кроме того, в случае нескольких гостей заранее неясно, какому из них следует доставить прерывание, и принять решение должен монитор.
Простейшее решение, обеспечивающее изоляцию, — это направлять все прерывания в монитор ВМ. Эквивалентность при этом будет обеспечиваться им самим: прерывание при необходимости будет доставлено внутрь гостя через симуляцию изменения его состояния. Монитор может дополнительно создавать виртуальные прерывания, обусловленные только логикой его работы, а не внешними событиями. Однако эффективность такого решения не будет оптимальной. Как правило, реакция системы на прерывание должна произойти в течение ограниченного времени, иначе она потеряет смысл для внешнего устройства или будет иметь катастрофические последствия для системы в целом. Введение слоя виртуализации увеличивает задержку между моментом возникновения события и моментом его обработки в госте по сравнению с системой без виртуализации. Более эффективным является аппаратный контроль за доставкой прерываний, позволяющий часть из них сделать безвредными для состояния системы и не требовать каждый раз вмешательства программы монитора.
Практически все современные компьютеры содержат в себе более одного ядра или процессора. Кроме того, внутри одного монитора могут исполняться несколько ВМ, каждая из которых может иметь в своём распоряжении несколько виртуальных процессоров. Рассмотрим, как эти обстоятельства влияют на условия виртуализации.
Введение в рассмотрение нескольких хозяйских и гостевых процессоров оставляет условие эффективной виртуализуемости в силе. Однако необходимо обратить внимание на выполнение условий эффективности работы многопоточных приложений внутри ВМ. В отличие от однопоточных, для них характерны процессы синхронизации частей программы, исполняющихся на различных виртуальных процессорах. При этом все участвующие потоки ожидают, когда все они достигнут заранее определённой точки алгоритма, т.н. барьера. В случае виртуализации системы один или несколько гостевых потоков могут оказаться неактивными, вытесненными монитором, из-за чего остальные будут попусту тратить время.
Примером такого неэффективного поведения гостевых систем является синхронизация с задействованием циклических блокировок (англ. spin lock) внутри ВМ [9]. Будучи неэффективной и поэтому неиспользуемой для однопроцессорных систем, в случае нескольких процессоров она является легковесной альтернативой другим, более тяжеловесным замкам (англ. lock), используемым для входа в критические секции параллельных алгоритмов. Чаще всего они используются внутри операционной системы, но не пользовательских программ, так как только ОС может точно определить, какие из системных ресурсов могут быть эффективно защищены с помощью циклических блокировок. Однако в случае виртуальной машины планированием ресурсов на самом деле занимается не ОС, а монитор ВМ, который в общем случае не осведомлён о них и может вытеснить поток, способный освободить ресурс, тогда как второй поток будет выполнять циклическую блокировку, бесполезно тратя процессорное время. Оптимальным решением при этом является деактивация заблокированного потока до тех пор, пока нужный ему ресурс не освободится.
Существующие решения для данной проблемы описаны ниже.
Наконец, отметим, что схемы доставки и обработки прерываний в системах с несколькими процессорами также более сложны, и это приходится учитывать при создании монитора ВМ для таких систем, при этом его эффективность может оказаться ниже, чем у однопроцессорного эквивалента.
Модель машинных инструкций, использованная ранее для формулировки утверждения об эффективной виртуализации, использовала простую линейную схему трансляции адресов, основанную на сегментации, популярную в 70-х годах прошлого века. Она является вычислительно простой, не изменяется при введении монитора ВМ, и поэтому анализа влияния механизма преобразования адресов на эффективность не производилось.
В настоящее время механизмы страничной виртуальной памяти и применяют нелинейное преобразование виртуальных адресов пользовательских приложений в физические адреса, используемые аппаратурой. Участвующий при этом системный ресурс — регистр-указатель адреса таблицы преобразований (чаще всего на практике используется несколько таблиц, образующих иерархию, имеющую общий корень). В случае работы ВМ этот указатель необходимо виртуализовать, так как у каждой гостевой системы содержимое регистра своё, как и положение/содержимое таблицы. Стоимость программной реализации этого механизма внутри монитора высока, поэтому приложения, активно использующие память, могут терять в эффективности при виртуализации.
Для решения этой проблемы используется двухуровневая аппаратная трансляция адресов (рис. 3). Гостевые ОС видят только первый уровень, тогда как генерируемый для них физический адрес в дальнейшем транслируется вторым уровнем в настоящий адрес.
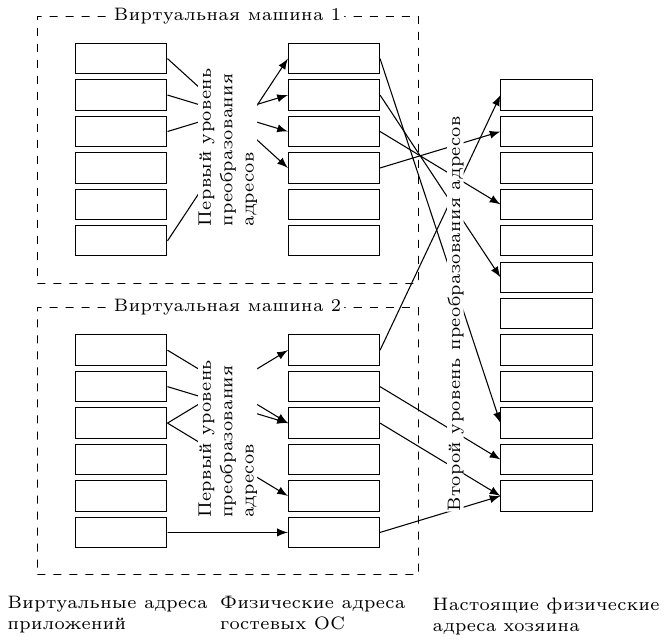
Рис. 3: Двухуровневая трансляция адресов. Первый уровень контролируется гостевыми ОС, второй — монитором виртуальных машин
Другой ресурс ЭВМ, отвечающий за преобразование адресов, — это буфер ассоциативной трансляции (англ. translation lookaside buffer, TLB), состоящий из нескольких записей. Каждая гостевая система имеет своё содержимое TLB, поэтому при смене активной ВМ или переходе в монитор он должен быть сброшен. Это негативно сказывается на производительности систем, так как восстановление его содержимого требует времени, в течение которого приходится использовать менее эффективное обращение к таблице трансляций адресов, расположенной в памяти.
Решение состоит в разделении ресурсов TLB между всеми системами [10]. Каждая строка буфера ассоциируется с идентификатором — тэгом, уникальным для каждой ВМ. При поиске в нём аппаратурой учитываются только строки, тэг которых соответствует текущей ВМ.
Кроме процессоров к оперативной памяти напрямую могут обращаться и периферийные устройства — с помощью технологии DMA (англ. direct memory access). При этом обращения в классических системах без виртуализации идёт по физическим адресам. Очевидно, что внутри виртуальной машины необходимо транслировать такие адреса, что превращается в накладные расходы и понижение эффективности монитора.
Решение состоит в использовании устройства IOMMU (англ. Input output memory management unit), позволяющего контролировать обращения хозяйских устройств к физической памяти.
Расширим условие виртуализуемости, заменив в нём слово «инструкция» на «операция»: множество служебных операций является подмножеством привилегированных. При этом под операцией будем подразумевать любую архитектурно определённую активность по чтению или изменению состояния системы, в том числе инструкции, прерывания, доступы к устройствам, преобразования адресов и т.п.
При этом условие повышения эффективности виртуализации будет звучать следующим образом: в архитектуре системы должно присутствовать минимальное число служебных операций. Достигать его можно двумя способами: переводя служебные инструкции в разряд безвредных или уменьшая число привилегированных. Для этого большинство архитектур пошло по пути добавления в регистр состояния M нового режима r — режима монитора ВМ (англ. root mode). Он соотносится с режимом s так, как s — с u; другими словами, обновлёный класс привилегированных инструкций теперь вызывает ловушку потока управления, переводящую процессор из s в r.
Рассмотрим основные современные архитектуры вычислительных систем, используемых на серверах, рабочих станциях, а также во встраиваемых системах, с точки зрения практической реализации описанных выше теоретических принципов. См. также серию статей [5,6,7].
Компания IBM была одной из первых, выведших архитектуру с аппаратной поддержкой виртуализации на рынок серверных микропроцессоров в серии POWER4 в 2001 году. Она предназначалась для создания изолированных логических разделов (англ. logical partitions, LPAR), с каждым из которых ассоциированы один или несколько процессоров и ресурсы ввода-вывода. Для этого в процессор был добавлен новый режим гипервизора к уже присутсвовавшим режимам супервизора и пользователя. Для защиты памяти каждый LPAR ограничен в режиме с отключенной трансляцией адресов и имеет доступ лишь к небольшому приватному региону памяти; для использования остальной памяти гостевая ОС обязана включить трансляцию, контролируемую монитором ВМ.
В 2004 году развитие этой архитектуры, названное POWER5, принесло серьёзные усовершенствования механизмов виртуализации. Так, было добавлено новое устройство таймера, доступное только для монитора ВМ, что позволило ему контролировать гостевые системы более точно и выделять им процессорные ресурсы с точностью до сотой доли от процессора. Также монитор ВМ получил возможность контролировать адрес доставки прерываний — в LPAR или в гипервизор. Самым важным же нововведением являлся тот факт, что присутствие гипервизора являлось обязательным — он загружался и управлял системными ресурсами, даже если в системе присутствовал единственный LPAR-раздел. Поддерживаемые ОС (AIX, Linux, IBM i) были модифицированы с учётом этого, чтобы поддерживать своеобразную паравиртуализационную схему. Для управления устройствами ввода-вывода один (или два, для балансировки нагрузки) из LPAR загружает специальную операционную систему — virtual I/O server (VIOS), предоставляющую эти ресурсы для остальных разделов.
Компания Sun, развивавшая системы UltraSPARC и ОС Solaris, предлагала виртуализацию уровня ОС (т.н. контейнеры или зоны) начиная с 2004 г. В 2005 году в многопоточных процессорах Niagara 1 была представлена аппаратная виртуализация. При этом гранулярность виртуализации была равна одному потоку (всего чип имел восемь ядер, четыре потока на каждом).
Для взаимодействия ОС и гипервизора был представлен публичный и стабильный интерфейс для привилегированных приложений [3], скрывающий от ОС большинство архитектурных регистров.
Для трансляции адресов используется описанная ранее двухуровневая схема с виртуальными, реальными и физическими адресами. При этом TLB не хранит промежуточный адрес трансляции.
В отличие от POWER и SPARC, архитектура IA-32 (и её расширение AMD64) никогда не была подконтрольна одной компании, которая могла бы добавлять функциональность (пара)виртуализации между аппаратурой и ОС, нарушающую обратную совместимость с существующими операционными системами. Кроме того, в ней явно нарушены условия эффективной виртуализации — около 17 служебных инструкций не являются привилегированными, что мешало создать аппаратно поддерживаемые мониторы ВМ. Однако программные мониторы существовали и до 2006 года, когда Intel представила технологию VT-x, а AMD — похожую, но несовместимую с ней AMD-V.
Были представлены новые режимы процессора — VMX root и non root, и уже существовавшие режимы привилегий 0-3 могут быть использованы в обоих из них. Переход между режимами может быть осуществлён с помощью новых инструкций vmxon и vmxoff.
Для хранения состояния гостевых систем и монитора используется новая структура VMCS (англ. virtual machine control structure), копии которой размещены в физической памяти и доступны для монитора ВМ.
Интересным решением является конфигурируемость того, какие события в госте будут вызывать событие ловушки и переход в гипервизор, а какие оставлены на обработку ОС. Например, для каждого гостя можно выбрать, будут ли внешние прерывания обрабатываться им или монитором; запись в какие биты контрольных регистров CR0 и CR4 будет перехватываться; какие исключения должны обрабатываться гостём, а какие — монитором и т.п. Данное решение позволяет добиваться компромисса между степенью контроля над каждой ВМ и эффективностью виртуализации. Таким образом, для доверенных гостей контроль монитора может быть ослаблен, тогда как одновременно исполняющиеся с ними сторонние ОС будут всё так же под его строгим наблюдением. Для оптимизации работы TLB используется описанная выше техника тэгирования его записей с помощью ASID (англ. address space identifier). Для ускорения процесса трансляции адресов двухуровневая схема трансляции получила имя Intel EPT (англ. extended page walk).
Intel добавила аппаратную виртуализацию в Itanium (технология VT-i [4]) одновременно с IA-32 — в 2006 году. Специальный режим включался с помощью нового бита в статусном регистре PRS.vm. С включенным битом ранее служебные, но не привилегированные инструкции начинают вызывать ловушку и выход в монитор. Для возвращения в режим гостевой ОС используется инструкция vmsw. Часть инструкций, являющаяся служебными, при включенном режиме виртуализации генерируют новый вид синхронного исключения, для которого выделен собственный обработчик.
Поскольку операционная система обращается к аппаратуре посредством специального интерфейса PAL (англ. processor abstraction level), последний был расширен, чтобы поддерживать такие операции, как создание и уничтожение окружений для гостевых систем, сохранение и загрузка их состояния, конфигурирование виртуальных ресурсов и т.д. Можно отметить, что добавление аппаратной виртуализации в IA-64 потребовало меньшего количества усилий по сравнению с IA-32.
Архитектура ARM изначально была предназначена для встраиваемых и мобильных систем, эффективная виртуализация которых, по сравнению с серверными системами, долгое время не являлась ключевым фактором коммерческого и технологического успеха. Однако в последние годы наметилась тенденция к использованию ВМ на мобильных устройствах для обеспечения защиты критически важных частей системного кода, например, криптографических ключей, используемых при обработке коммерческих транзакций. Кроме того, процессоры ARM стали продвигаться на рынок серверных систем, и это потребовало расширить архитектуру и добавить в неё такие возможности, как поддержка адресации больших объёмов памяти и виртуализация.
Оба аспекта были отражены в избранном компанией ARM подходе к развитию своей архитектуры. На рис. 4 представлена схема, подразумевающая вложенность двух уровней виртуализации, представленная в 2010 году в обновлении архитектуры Cortex A15 [1].
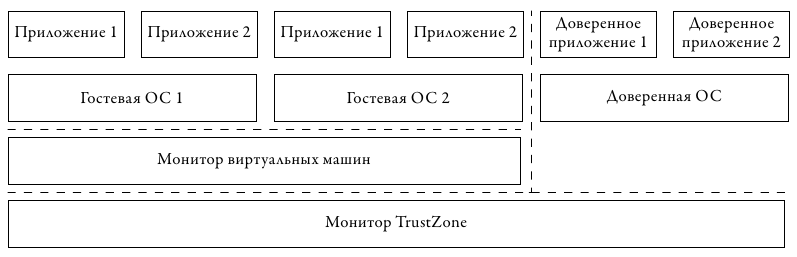
Рис. 4: Виртуализация ARM. Монитор TrustZone обеспечивает изоляцию и криптографическую аутентификацию доверенного «мира». В обычном «мире» используется собственный монитор ВМ
Для обеспечения изоляции критических компонент используется первый слой виртуализации, называемый TrustZone. С его помощью все запущенные программные компоненты делятся на два «мира» — доверенный и обычный. В первой среде исполняются те части системы, работа которых не должна быть подвластна внешним влияниям обычного кода. Во второй среде исполняются пользовательские приложения и операционная система, которые теоретически могут быть скомпрометированы. Однако обычный «мир» не имеет доступа к доверенному. Монитор TrustZone обеспечивает доступ в обратном направлении, что позволяет доверенному коду контролировать состояние аппаратуры.
Второй слой виртуализации исполняется под управлением недоверенного монитора и предоставляет возможности мультиплексирования работы нескольких пользовательских ОС. В нём добавлены новые инструкции HVC и ERET для входа и выхода в/из режим(а) гипервизора. Для событий ловушки использован ранее зарезервированный вектор прерываний 0x14, добавлены новые регистры: указатель стэка SPSR, состояние виртуальных ресурсов HCR и регистр «синдрома» HSR, в котором хранится причина выхода из гостя в монитор, что позволяет последнему быстро проанализировать ситуацию и проэмулировать необходимую функциональность без избыточного чтения состояния гостя.
Так же, как это сделано в рассмотренных ранее архитектурах, для ускорения механизмов трансляции адресов используется двухуровневая схема, в которой физические адреса гостевых ОС являются промежуточными. Внешние прерывания могут быть настроены как на доставку монитору, который потом перенаправляет их в гость с помощью механизма виртуальных прерываний, так и на прямую отправку в гостевую систему.
Процессоры MIPS развивались в направлении, обратном наблюдаемому для ARM: от высокопроизводительных систем к встраиваемым и мобильным. Тем не менее, аппаратная виртуализация для неё появилась относительно недавно, в 2012 г. Архитектура MIPS R5 принесла режим виртуализации MIPS VZ [2]. Он доступен как для 32-битного, так и для 64-битного варианта архитектуры.
Добавленное архитектурное состояние позволяет хранить контекст ВМ и монитора отдельно. Например, для нужд гипервизора введена копия системного регистра COP0, независимая от копии гостя. Это позволяет оптимизировать время переключения между ними, в то время как переключение между несколькими гостевыми ОС требует обновления COP0 содержимым из памяти и является менее эффективным. Кроме того, часть бит гостевого регистра, описывающие набор возможностей текущего варианта архитектуры и потому ранее используемые только для чтения, из режима монитора доступны для записи, что позволяет ему декларировать возможности, отличные от действительно присутствующих на хозяине.
Привилегии гипервизора, операционной системы и пользователя образуют т.н. луковую (англ. onion) модель. В ней обработка прерываний идёт снаружи внутрь, т.е. сначала каждое из них проверяется на соответствие правилам монитора, затем ОС. Синхронные исключения (ловушки), наоборот, обрабатываются сперва ОС, а затем монитором.
Так же, как это сделано в рассмотренных ранее архитектурах, для ускорения механизмов трансляции адресов используют тэги в TLB и двухуровневую трансляцию в MMU. Для поддержки разработки паравиртуализационных гостей добавлена новая инструкция hypercall, вызывающая ловушку и выход в режим монитора.
В заключение рассмотрим дополнительные вопросы обеспечения эффективной виртуализации, связанные с переключением между режимами монитора и ВМ.
Частые прерывания работы виртуальной машины из-за необходимости выхода в монитор негативно влияют на скорость симуляции. Несмотря на то, что производители процессоров работают над уменьшением связанных с этими переходами задержек (для примера см. таблицу 1), они всё же достаточно существенны, чтобы пытаться минимизировать их частоту возникновения.
Таблица 1. Длительность перехода между режимами аппаратной виртуализации для различных поколений микроархитектур процессоров Intel IA-32 (данные взяты из [11])
Если прямое исполнение с использованием виртуализации оказывается неэффективным, имеет смысл переключиться на другую схему работы, например, на интерпретацию или двоичную трансляцию (см. мою серию постов на IDZ: 1, 2, 3).
На практике исполнения ОС характерна ситуация, что инструкции, вызывающие ловушки потока управления, образуют кластера, в которых две или более из них находятся недалеко друг от друга, тогда как расстояние между кластерами значительно. В следующем блоке кода для IA-32 приведён пример такого кластера. Звёздочкой обозначены все инструкции, вызывающие выход в монитор.
Для того, чтобы избежать повторения сценария: выход из ВМ в монитор, интерпретация инструкции, обратный вход в ВМ только для того, чтобы на следующей инструкции вновь выйти в монитор, — используется предпросмотр инструкций [11]. После обработки ловушки, прежде чем монитор передаст управление обратно в ВМ, поток инструкций просматривается на несколько инструкций вперёд в поисках привилегированных инструкций. Если они обнаружены, симуляция на некоторое время переключается в режим двоичной трансляции. Тем самым избегается негативное влияние эффекта кластеризации привилегированных инструкций.
Ситуация, когда монитор виртуальных машин запускается под управлением другого монитора, непосредственно исполняющегося на аппаратуре, называется рекурсивной виртуализацией. Теоретически она может быть не ограничена только двумя уровнями — внутри каждого монитора ВМ может исполняться следующий, тем самым образуя иерархию гипервизоров.
Возможность запуска одного гипервизора под управлением монитора ВМ (или, что тоже самое, симулятора) имеет практическую ценность. Любой монитор ВМ — достаточно сложная программа, к которой обычные методы отладки приложений и даже ОС неприменимы, т.к. он загружается очень рано в процессе работы системы, когда отладчик подключить затруднительно. Исполнение под управлением симулятора позволяет инспектировать и контролировать его работу с самой первой инструкции.
Голдберг и Попек в своей упомянутой ранее работе рассмотрели вопросы эффективной поддержки в том числе и рекурсивной виртуализации. Однако их выводы, к сожалению, не учитывают многие из упомянутых выше особенностей современных систем.
Рассмотрим одно из затруднений, связанных со спецификой вложенного запуска мониторов ВМ — обработку ловушек и прерываний. В простейшем случае за обработку всех типов исключительных ситуаций всегда отвечает самый внешний монитор, задача которого — или обработать событие самостоятельно, тем самым «спрятав» его от остальных уровней, или передать его следующему.
Как для прерываний, так и для ловушек это часто оказывается неоптимальным — событие должно пройти несколько уровней иерархии, каждый из которых внесёт задержку на его обработку. На рис. 5 показана обработка двух типов сообщений — прерывания, возникшего во внешней аппаратуре, и ловушки потока управления, случившейся внутри приложения.
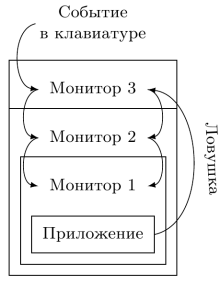
Рис. 5: Рекурсивная виртуализация. Все события должны обрабатываться внешним монитором, который спускает их вниз по иерархии, при этом формируется задержка
Для оптимальной обработки различных типов ловушек и прерываний для каждого из них должен быть выбран уровень иерархии мониторов ВМ, и при возникновении события управление должно передаваться напрямую этому уровню, минуя дополнительную обработку вышележащими уровнями и без связанных с этим накладных расходов.
Задаче аппаратной поддержки второго и более уровней вложенности виртуализации производители процессоров уделяют значительно меньше внимания, чем первому её уровню. Тем не менее такие работы существуют. Так, ещё в восьмидесятых годах двадцатого века для систем IBM/370 [13] была реализована возможность запуска копий системного ПО внутри уже работающей на аппаратуре операционной системы. Для этой задачи была введена инструкция SIE (англ. start interpreted execution) [14]. Существуют предложения об интерфейсе между вложенными уровнями виртуализации [12], который позволил бы эффективно поддерживать вложенность нескольких мониторов ВМ, и реализация рекурсивной виртуализации для IA-32 [15]. Однако современные архитектуры процессоров всё же ограничиваются аппаратной поддержкой максимум одного уровня виртуализации.
Сперва — несколько определений, может быть, не совсем типичных для статей по данной тематике, но используемых в этой заметке.
- Хозяин (англ. host) — аппаратная система, на которой запущен монитор виртуальных машин или симулятор.
- Гость (англ.guest) — виртуальная или моделируемая система, запущенная под управлением монитора или симулятора. Также иногда именуется как целевая система (англ. target system).
Остальную терминологию я постараюсь определять по мере появления в тексте.
Введение
Виртуализация представляла интерес ещё до изобретения микропроцессора, во времена преобладания больших систем — мейэнфреймов, ресурсы которых были очень дорогими, и их простой был экономически недопустим. Виртуализация позволяла повысить степень утилизации таких систем, при этом избавив пользователей и прикладных программистов от необходимости переписывать своё ПО, так как с их точки зрения виртуальная машина была идентична физической. Пионером в этой области являлась фирма IBM с мэйнфреймами System/360, System/370, созданными в 1960-1970-х гг.
Классический критерий виртуализуемости
Неудивительно, что критерии возможности создания эффективного монитора виртуальных машин были получены примерно в то же время. Они сформулированы в классической работе 1974 г. Жеральда Попека и Роберта Голдберга «Formal requirements for virtualizable third generation architectures» [8]. Рассмотрим её основные предпосылки и сформулируем её основной вывод.
Модель системы
В дальнейшем используется упрощённое представление «стандартной» ЭВМ из статьи, состоящей из одного центрального процессора и линейной однородной оперативной памяти. Периферийные устройства, а также средства взаимодействия с ними опускаются. Процессор поддерживает два режима работы: режим супервизора, используемый операционной системой, и режим пользователя, в котором исполняются прикладные приложения. Память поддерживает режим сегментации, используемый для организации виртуальной памяти.
Выдвигаемые требования на монитор виртуальных машин (ВМ):
- Изоляция — каждая виртуальная машина должна иметь доступ только к тем ресурсам, которые были ей назначены. Она не должна иметь возможности повлиять на работы как монитора, так и других ВМ.
- Эквивалентность — любая программа, исполняемая под управлением ВМ, должна демонстрировать поведение, полностью идентичное её исполнению на реальной системе, за исключением эффектов, вызванных двумя обстоятельствами: различием в количестве доступных ресурсов (например, ВМ может иметь меньший объём памяти) и длительностями операций (из-за возможности разделения времени исполнения с другими ВМ).
- Эффективность — в оригинальной работе условие сформулировано следующим образом: «статистически преобладающее подмножество инструкций виртуального процессора должно исполняться напрямую хозяйским процессором, без вмешательства монитора ВМ». Другими словами, значительная часть инструкций должна симулироваться в режиме прямого исполнения. Требование эффективности является самым неоднозначным из трёх перечисленных требований, и мы ещё вернёмся к нему. В случае симуляторов, основанных на интерпретации инструкций, условие эффективности не выполняется, т.к. каждая инструкция гостя требует обработки симулятором.
Классы инструкций
Состояние процессора содержит минимум три регистра: M, определяющий, находится ли он в режиме супервизора s или пользователя u, P — указатель текущей инструкции и R — состояние, определяющее границы используемого сегмента памяти (в простейшем случае R задаёт отрезок, т.е. R = (l,b), где l — адрес начала диапазона, b — его длина).
Память E состоит из фиксированного числа ячеек, к которым можно обращаться по их номеру t, например, E[t]. Размер памяти и ячеек для данного рассмотрения несущественен.
При исполнении каждая инструкция i в общем случае может изменить как (M,P,R), так и память E, т.е. она является функцией преобразования: (M1,P1,R1,E1) -> (M2,P2,R2,E2).
Считается, что для некоторых входных условий инструкция вызывает исключение ловушки (англ. trap), если в результате её исполнения содержимое памяти не изменяется, кроме единственной ячейки E[0], в которую помещается предыдущее состояние процессора (M1,P1,R1). Новое состояние процессора (M2,P2,R2) при этом копируется из E[1]. Другими словами, ловушка позволяет сохранить полное состояние программы на момент до начала исполнения её последней инструкции и передать управление обработчику, в случае обычных систем обычно работающему в режиме супервизора и призванного обеспечить дополнительные действия над состоянием системы, а затем вернуть управление в программу, восстановив состояние из E[0].
Далее, ловушки могут иметь два признака.
- Вызванные попыткой изменить состояние процессора (ловушка потока управления).
- Обращения к содержимому памяти, выходящему за пределы диапазона, определённого в (ловушка защиты памяти).
Отметим, что эти признаки не взаимоисключающие. То есть результатом исполнения могут быть одновременно ловушка потока управления и защиты памяти.
Машинные инструкции рассматриваемого процессора можно классифицировать следующим образом:
- Привилегированные (англ. privileged). Инструкции, исполнение которых с M = u всегда вызывает ловушку потока управления. Другими словами, такая инструкция может исполняться только в режиме супервизора, иначе она обязательно вызывает исключение.
- Служебные (англ. sensitive. Установившего русского термина для этого понятия я не знаю. Иногда в литературе встречается перевод «чувствительные» инструкции). Класс состоит из двух подклассов. 1. Инструкции, исполнение которых закончилось без ловушки защиты памяти и вызвало изменение M и/или R. Они могут менять режим процессора из супервизора в пользовательский или обратно или изменять положение и размер доступного сегмента памяти. 2. Инструкции, поведение которых в случаях, когда они не вызывают ловушку защиты памяти, зависят или от режима M, или от значения R.
- Безвредные (англ. innocuous). Не являющиеся служебными. Самый широкий класс инструкций, не манипулирующие ничем, кроме указателя инструкций P и памяти E, поведение которых не зависит от того, в каком режиме или с каким адресом в памяти они расположены.
Достаточное условие построения монитора ВМ
Соблюдение трёх сформулированных выше условий возможности построения монитора виртуальных машин даётся в следующем предложении: множество служебных инструкций является подмножеством привилегированных инструкций (рис. 1). Опуская формальное доказательство теоремы 1 из статьи, отметим следующие обстоятельства.
- Изоляция обеспечивается размещением монитора в режиме супервизора, а ВМ — только в пользовательском. При этом последние не могут самовольно изменить системные ресурсы — попытка вызовет ловушку потока управления на служебной инструкции и переход в монитор, а также память из-за того, что конфигурация не допускает этого, и процессор выполнит ловушку защиты памяти.
- Эквивалентность доказывается тем, что безвредные инструкции выполняются одинаково вне зависимости от того, присутствует ли в системе монитор или нет, а служебные всегда вызывают исключение и интерпретируются. Отметим, что даже в описанной выше простой схеме проявляется первое ослабляющее условие: даже без учёта памяти, необходимой для хранения кода и данных гипервизора, объём доступной для ВМ памяти будет как минимум на две ячейки меньше, чем имеется у хозяйской системы.
- Эффективность гарантируется тем, что все безвредные инструкции внутри ВМ исполняются напрямую, без замедления. При этом подразумевается, что их множество включает в себя «статистически преобладающее подмножество инструкций виртуального процессора».

Рис. 1: Выполнение условия виртуализуемости. Множество служебных инструкций является подмножеством привилегированных
Ограничения применимости критерия виртуализуемости
Несмотря на простоту использованной модели и полученных из неё выводов, работа Голдберга и Попека является актуальной до сих пор. Следует отметить, что несоблюдение описанных в ней условий вовсе не делает создание или использование виртуальных машин на некоторой архитектуре принципиально невозможным, и есть практические примеры реализаций, подтверждающие это. Однако соблюсти оптимальный баланс между тремя свойствами: изоляцией, эквивалентностью и эффективностью, — становится невозможным. Чаще всего расплачиваться приходится скоростью работы виртуальных машин из-за необходимости тщательного поиска и программного контроля за исполнением ими служебных, но не привилегированных инструкций, так как сама аппаратура не обеспечивает этого (рис. 2). Даже единственная такая инструкция, исполненная напрямую ВМ, угрожает стабильной работе монитора, и поэтому он вынужден сканировать весь поток гостевых инструкций.
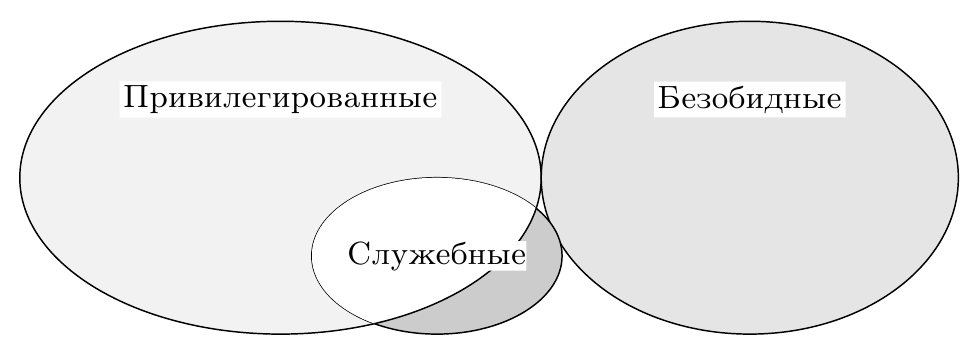
Рис. 2: Невыполнение условия виртуализуемости. Служебные, но не привилегированные инструкции требуют реализации сложной логики в мониторе
В самой работе [8] присутствуют как явно указанные упрощения исследуемой структуры реальных систем (отсутствие периферии и системы ввода-вывода), так и неявные предположения о структуре исполняемых гостевых программ (почти полностью состоящих из безвредных инструкций) и хозяйских систем (однопроцессорность).
Рассмотрим теперь данные ограничения более детально, а также предложим, каким образом можно расширить степень применимости критерия к дополнительным ресурсам, требующим виртуализации, и таким образом повысить его практическую ценность для архитекторов новых вычислительных систем.
Структура гостевых программ
Для эффективной работы программ внутри ВМ необходимо, чтобы большая часть их инструкций являлись безвредными. Как правило, это верно для прикладных приложений. Операционные системы, в свою очередь, предназначены для управления ресурсами системы, что подразумевает использование ими привилегированных и служебных инструкций, и монитору приходится их перехватывать и интерпретировать с соответствующим падением производительности. Поэтому в идеале в наборе инструкций должно быть как можно меньше привилегированных для того, чтобы частота возникновения ловушек была минимальной.
Периферия
Поскольку периферийные устройства являются служебным ресурсом ЭВМ, очевидно, что для обеспечения условий изоляции и эквивалентности необходимо, чтобы все попытки доступа к ним были контролируемы монитором ВМ так же, как они контролируются в многозадачной операционной системе её ядром. В настоящее время доступ к устройствам чаще всего производится через механизм отражения их в физической памяти системы (англ. memory mapped I/O), что означает, что внутри монитора это чтение/запись некоторых регионов должно или вызывать ловушку защиты памяти, или быть не служебным, т.е. не вызывать ловушку и не влиять на состояние неконтролируемым образом.
Интенсивность взаимодействия приложений с периферией может быть различна и определяется их функциональностью, что сказывается на их замедлении при виртуализации. Кроме того, монитор ВМ может делать различные классы периферии, присутствующей на хозяине, доступными внутри нескольких ВМ различными способами.
- Выделенное устройство — устройство, доступное исключительно внутри одной гостевой системы. Примеры: клавиатура, монитор.
- Разделяемое — общее для нескольких гостей. Такое устройство или имеет несколько частей, каждая из которых выделена для нужд одного из них (англ. partitioned mode), например, жёсткий диск с несколькими разделами, или подключается к каждому из них поочерёдно (англ. shared mode). Пример: сетевая карта.
- Полностью виртуальное — устройство, отсутствующее в реальной системе (или присутствующее, но в ограниченном количестве) и моделируемое программно внутри монитора. Примеры: таймеры прерываний — каждый гость имеет собственный таймер, несмотря на то, что в хозяйской системе есть только один, и он используется для собственных нужд монитора.
Прерывания
Прерывания являются механизмом оповещения процессора о событиях внешних устройств, требующих внимания операционной системы. В случае использования виртуальных машин монитор должен иметь возможность контролировать доставку прерываний, так как часть или все из них необходимо обрабатывать именно внутри монитора. Например, прерывание таймера может быть использовано им для отслеживания/ограничения использования гостями процессорного времени и для возможности переключения между несколькими одновременно запущенными ВМ. Кроме того, в случае нескольких гостей заранее неясно, какому из них следует доставить прерывание, и принять решение должен монитор.
Простейшее решение, обеспечивающее изоляцию, — это направлять все прерывания в монитор ВМ. Эквивалентность при этом будет обеспечиваться им самим: прерывание при необходимости будет доставлено внутрь гостя через симуляцию изменения его состояния. Монитор может дополнительно создавать виртуальные прерывания, обусловленные только логикой его работы, а не внешними событиями. Однако эффективность такого решения не будет оптимальной. Как правило, реакция системы на прерывание должна произойти в течение ограниченного времени, иначе она потеряет смысл для внешнего устройства или будет иметь катастрофические последствия для системы в целом. Введение слоя виртуализации увеличивает задержку между моментом возникновения события и моментом его обработки в госте по сравнению с системой без виртуализации. Более эффективным является аппаратный контроль за доставкой прерываний, позволяющий часть из них сделать безвредными для состояния системы и не требовать каждый раз вмешательства программы монитора.
Многопроцессорные системы
Практически все современные компьютеры содержат в себе более одного ядра или процессора. Кроме того, внутри одного монитора могут исполняться несколько ВМ, каждая из которых может иметь в своём распоряжении несколько виртуальных процессоров. Рассмотрим, как эти обстоятельства влияют на условия виртуализации.
Синхронизация и виртуализация
Введение в рассмотрение нескольких хозяйских и гостевых процессоров оставляет условие эффективной виртуализуемости в силе. Однако необходимо обратить внимание на выполнение условий эффективности работы многопоточных приложений внутри ВМ. В отличие от однопоточных, для них характерны процессы синхронизации частей программы, исполняющихся на различных виртуальных процессорах. При этом все участвующие потоки ожидают, когда все они достигнут заранее определённой точки алгоритма, т.н. барьера. В случае виртуализации системы один или несколько гостевых потоков могут оказаться неактивными, вытесненными монитором, из-за чего остальные будут попусту тратить время.
Примером такого неэффективного поведения гостевых систем является синхронизация с задействованием циклических блокировок (англ. spin lock) внутри ВМ [9]. Будучи неэффективной и поэтому неиспользуемой для однопроцессорных систем, в случае нескольких процессоров она является легковесной альтернативой другим, более тяжеловесным замкам (англ. lock), используемым для входа в критические секции параллельных алгоритмов. Чаще всего они используются внутри операционной системы, но не пользовательских программ, так как только ОС может точно определить, какие из системных ресурсов могут быть эффективно защищены с помощью циклических блокировок. Однако в случае виртуальной машины планированием ресурсов на самом деле занимается не ОС, а монитор ВМ, который в общем случае не осведомлён о них и может вытеснить поток, способный освободить ресурс, тогда как второй поток будет выполнять циклическую блокировку, бесполезно тратя процессорное время. Оптимальным решением при этом является деактивация заблокированного потока до тех пор, пока нужный ему ресурс не освободится.
Существующие решения для данной проблемы описаны ниже.
- Монитор ВМ может пытаться детектировать использование циклических блокировок гостевой ОС. Это требует анализа кода перед исполнением, установки точек останова по адресам замка. Способ не отличается универсальностью и надёжностью детектирования.
- Гостевая система может сигнализировать монитору о намерении использовать циклическую блокировку с помощью специальной инструкции. Способ более надёжный, однако требующий модификации кода гостевой ОС.
Прерывания в многопроцессорных системах
Наконец, отметим, что схемы доставки и обработки прерываний в системах с несколькими процессорами также более сложны, и это приходится учитывать при создании монитора ВМ для таких систем, при этом его эффективность может оказаться ниже, чем у однопроцессорного эквивалента.
Преобразование адресов
Модель машинных инструкций, использованная ранее для формулировки утверждения об эффективной виртуализации, использовала простую линейную схему трансляции адресов, основанную на сегментации, популярную в 70-х годах прошлого века. Она является вычислительно простой, не изменяется при введении монитора ВМ, и поэтому анализа влияния механизма преобразования адресов на эффективность не производилось.
В настоящее время механизмы страничной виртуальной памяти и применяют нелинейное преобразование виртуальных адресов пользовательских приложений в физические адреса, используемые аппаратурой. Участвующий при этом системный ресурс — регистр-указатель адреса таблицы преобразований (чаще всего на практике используется несколько таблиц, образующих иерархию, имеющую общий корень). В случае работы ВМ этот указатель необходимо виртуализовать, так как у каждой гостевой системы содержимое регистра своё, как и положение/содержимое таблицы. Стоимость программной реализации этого механизма внутри монитора высока, поэтому приложения, активно использующие память, могут терять в эффективности при виртуализации.
Для решения этой проблемы используется двухуровневая аппаратная трансляция адресов (рис. 3). Гостевые ОС видят только первый уровень, тогда как генерируемый для них физический адрес в дальнейшем транслируется вторым уровнем в настоящий адрес.
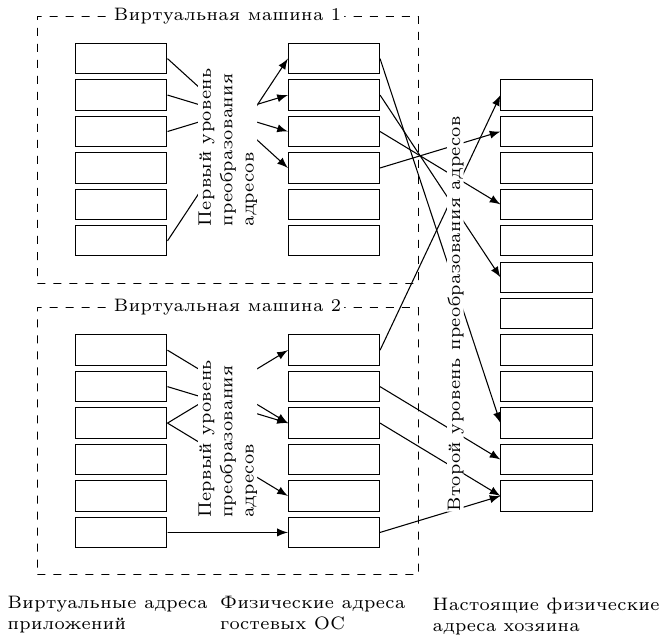
Рис. 3: Двухуровневая трансляция адресов. Первый уровень контролируется гостевыми ОС, второй — монитором виртуальных машин
TLB
Другой ресурс ЭВМ, отвечающий за преобразование адресов, — это буфер ассоциативной трансляции (англ. translation lookaside buffer, TLB), состоящий из нескольких записей. Каждая гостевая система имеет своё содержимое TLB, поэтому при смене активной ВМ или переходе в монитор он должен быть сброшен. Это негативно сказывается на производительности систем, так как восстановление его содержимого требует времени, в течение которого приходится использовать менее эффективное обращение к таблице трансляций адресов, расположенной в памяти.
Решение состоит в разделении ресурсов TLB между всеми системами [10]. Каждая строка буфера ассоциируется с идентификатором — тэгом, уникальным для каждой ВМ. При поиске в нём аппаратурой учитываются только строки, тэг которых соответствует текущей ВМ.
Преобразование адресов для периферийных устройств
Кроме процессоров к оперативной памяти напрямую могут обращаться и периферийные устройства — с помощью технологии DMA (англ. direct memory access). При этом обращения в классических системах без виртуализации идёт по физическим адресам. Очевидно, что внутри виртуальной машины необходимо транслировать такие адреса, что превращается в накладные расходы и понижение эффективности монитора.
Решение состоит в использовании устройства IOMMU (англ. Input output memory management unit), позволяющего контролировать обращения хозяйских устройств к физической памяти.
Расширение принципа
Расширим условие виртуализуемости, заменив в нём слово «инструкция» на «операция»: множество служебных операций является подмножеством привилегированных. При этом под операцией будем подразумевать любую архитектурно определённую активность по чтению или изменению состояния системы, в том числе инструкции, прерывания, доступы к устройствам, преобразования адресов и т.п.
При этом условие повышения эффективности виртуализации будет звучать следующим образом: в архитектуре системы должно присутствовать минимальное число служебных операций. Достигать его можно двумя способами: переводя служебные инструкции в разряд безвредных или уменьшая число привилегированных. Для этого большинство архитектур пошло по пути добавления в регистр состояния M нового режима r — режима монитора ВМ (англ. root mode). Он соотносится с режимом s так, как s — с u; другими словами, обновлёный класс привилегированных инструкций теперь вызывает ловушку потока управления, переводящую процессор из s в r.
Статус поддержки в современных архитектурах
Рассмотрим основные современные архитектуры вычислительных систем, используемых на серверах, рабочих станциях, а также во встраиваемых системах, с точки зрения практической реализации описанных выше теоретических принципов. См. также серию статей [5,6,7].
IBM POWER
Компания IBM была одной из первых, выведших архитектуру с аппаратной поддержкой виртуализации на рынок серверных микропроцессоров в серии POWER4 в 2001 году. Она предназначалась для создания изолированных логических разделов (англ. logical partitions, LPAR), с каждым из которых ассоциированы один или несколько процессоров и ресурсы ввода-вывода. Для этого в процессор был добавлен новый режим гипервизора к уже присутсвовавшим режимам супервизора и пользователя. Для защиты памяти каждый LPAR ограничен в режиме с отключенной трансляцией адресов и имеет доступ лишь к небольшому приватному региону памяти; для использования остальной памяти гостевая ОС обязана включить трансляцию, контролируемую монитором ВМ.
В 2004 году развитие этой архитектуры, названное POWER5, принесло серьёзные усовершенствования механизмов виртуализации. Так, было добавлено новое устройство таймера, доступное только для монитора ВМ, что позволило ему контролировать гостевые системы более точно и выделять им процессорные ресурсы с точностью до сотой доли от процессора. Также монитор ВМ получил возможность контролировать адрес доставки прерываний — в LPAR или в гипервизор. Самым важным же нововведением являлся тот факт, что присутствие гипервизора являлось обязательным — он загружался и управлял системными ресурсами, даже если в системе присутствовал единственный LPAR-раздел. Поддерживаемые ОС (AIX, Linux, IBM i) были модифицированы с учётом этого, чтобы поддерживать своеобразную паравиртуализационную схему. Для управления устройствами ввода-вывода один (или два, для балансировки нагрузки) из LPAR загружает специальную операционную систему — virtual I/O server (VIOS), предоставляющую эти ресурсы для остальных разделов.
SPARC
Компания Sun, развивавшая системы UltraSPARC и ОС Solaris, предлагала виртуализацию уровня ОС (т.н. контейнеры или зоны) начиная с 2004 г. В 2005 году в многопоточных процессорах Niagara 1 была представлена аппаратная виртуализация. При этом гранулярность виртуализации была равна одному потоку (всего чип имел восемь ядер, четыре потока на каждом).
Для взаимодействия ОС и гипервизора был представлен публичный и стабильный интерфейс для привилегированных приложений [3], скрывающий от ОС большинство архитектурных регистров.
Для трансляции адресов используется описанная ранее двухуровневая схема с виртуальными, реальными и физическими адресами. При этом TLB не хранит промежуточный адрес трансляции.
Intel IA-32 и AMD AMD64
В отличие от POWER и SPARC, архитектура IA-32 (и её расширение AMD64) никогда не была подконтрольна одной компании, которая могла бы добавлять функциональность (пара)виртуализации между аппаратурой и ОС, нарушающую обратную совместимость с существующими операционными системами. Кроме того, в ней явно нарушены условия эффективной виртуализации — около 17 служебных инструкций не являются привилегированными, что мешало создать аппаратно поддерживаемые мониторы ВМ. Однако программные мониторы существовали и до 2006 года, когда Intel представила технологию VT-x, а AMD — похожую, но несовместимую с ней AMD-V.
Были представлены новые режимы процессора — VMX root и non root, и уже существовавшие режимы привилегий 0-3 могут быть использованы в обоих из них. Переход между режимами может быть осуществлён с помощью новых инструкций vmxon и vmxoff.
Для хранения состояния гостевых систем и монитора используется новая структура VMCS (англ. virtual machine control structure), копии которой размещены в физической памяти и доступны для монитора ВМ.
Интересным решением является конфигурируемость того, какие события в госте будут вызывать событие ловушки и переход в гипервизор, а какие оставлены на обработку ОС. Например, для каждого гостя можно выбрать, будут ли внешние прерывания обрабатываться им или монитором; запись в какие биты контрольных регистров CR0 и CR4 будет перехватываться; какие исключения должны обрабатываться гостём, а какие — монитором и т.п. Данное решение позволяет добиваться компромисса между степенью контроля над каждой ВМ и эффективностью виртуализации. Таким образом, для доверенных гостей контроль монитора может быть ослаблен, тогда как одновременно исполняющиеся с ними сторонние ОС будут всё так же под его строгим наблюдением. Для оптимизации работы TLB используется описанная выше техника тэгирования его записей с помощью ASID (англ. address space identifier). Для ускорения процесса трансляции адресов двухуровневая схема трансляции получила имя Intel EPT (англ. extended page walk).
Intel IA-64 (Itanium)
Intel добавила аппаратную виртуализацию в Itanium (технология VT-i [4]) одновременно с IA-32 — в 2006 году. Специальный режим включался с помощью нового бита в статусном регистре PRS.vm. С включенным битом ранее служебные, но не привилегированные инструкции начинают вызывать ловушку и выход в монитор. Для возвращения в режим гостевой ОС используется инструкция vmsw. Часть инструкций, являющаяся служебными, при включенном режиме виртуализации генерируют новый вид синхронного исключения, для которого выделен собственный обработчик.
Поскольку операционная система обращается к аппаратуре посредством специального интерфейса PAL (англ. processor abstraction level), последний был расширен, чтобы поддерживать такие операции, как создание и уничтожение окружений для гостевых систем, сохранение и загрузка их состояния, конфигурирование виртуальных ресурсов и т.д. Можно отметить, что добавление аппаратной виртуализации в IA-64 потребовало меньшего количества усилий по сравнению с IA-32.
ARM
Архитектура ARM изначально была предназначена для встраиваемых и мобильных систем, эффективная виртуализация которых, по сравнению с серверными системами, долгое время не являлась ключевым фактором коммерческого и технологического успеха. Однако в последние годы наметилась тенденция к использованию ВМ на мобильных устройствах для обеспечения защиты критически важных частей системного кода, например, криптографических ключей, используемых при обработке коммерческих транзакций. Кроме того, процессоры ARM стали продвигаться на рынок серверных систем, и это потребовало расширить архитектуру и добавить в неё такие возможности, как поддержка адресации больших объёмов памяти и виртуализация.
Оба аспекта были отражены в избранном компанией ARM подходе к развитию своей архитектуры. На рис. 4 представлена схема, подразумевающая вложенность двух уровней виртуализации, представленная в 2010 году в обновлении архитектуры Cortex A15 [1].
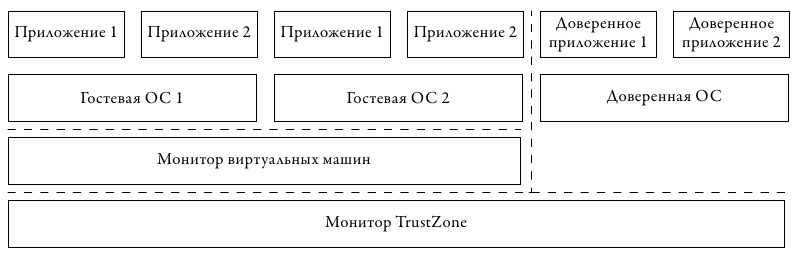
Рис. 4: Виртуализация ARM. Монитор TrustZone обеспечивает изоляцию и криптографическую аутентификацию доверенного «мира». В обычном «мире» используется собственный монитор ВМ
Для обеспечения изоляции критических компонент используется первый слой виртуализации, называемый TrustZone. С его помощью все запущенные программные компоненты делятся на два «мира» — доверенный и обычный. В первой среде исполняются те части системы, работа которых не должна быть подвластна внешним влияниям обычного кода. Во второй среде исполняются пользовательские приложения и операционная система, которые теоретически могут быть скомпрометированы. Однако обычный «мир» не имеет доступа к доверенному. Монитор TrustZone обеспечивает доступ в обратном направлении, что позволяет доверенному коду контролировать состояние аппаратуры.
Второй слой виртуализации исполняется под управлением недоверенного монитора и предоставляет возможности мультиплексирования работы нескольких пользовательских ОС. В нём добавлены новые инструкции HVC и ERET для входа и выхода в/из режим(а) гипервизора. Для событий ловушки использован ранее зарезервированный вектор прерываний 0x14, добавлены новые регистры: указатель стэка SPSR, состояние виртуальных ресурсов HCR и регистр «синдрома» HSR, в котором хранится причина выхода из гостя в монитор, что позволяет последнему быстро проанализировать ситуацию и проэмулировать необходимую функциональность без избыточного чтения состояния гостя.
Так же, как это сделано в рассмотренных ранее архитектурах, для ускорения механизмов трансляции адресов используется двухуровневая схема, в которой физические адреса гостевых ОС являются промежуточными. Внешние прерывания могут быть настроены как на доставку монитору, который потом перенаправляет их в гость с помощью механизма виртуальных прерываний, так и на прямую отправку в гостевую систему.
MIPS
Процессоры MIPS развивались в направлении, обратном наблюдаемому для ARM: от высокопроизводительных систем к встраиваемым и мобильным. Тем не менее, аппаратная виртуализация для неё появилась относительно недавно, в 2012 г. Архитектура MIPS R5 принесла режим виртуализации MIPS VZ [2]. Он доступен как для 32-битного, так и для 64-битного варианта архитектуры.
Добавленное архитектурное состояние позволяет хранить контекст ВМ и монитора отдельно. Например, для нужд гипервизора введена копия системного регистра COP0, независимая от копии гостя. Это позволяет оптимизировать время переключения между ними, в то время как переключение между несколькими гостевыми ОС требует обновления COP0 содержимым из памяти и является менее эффективным. Кроме того, часть бит гостевого регистра, описывающие набор возможностей текущего варианта архитектуры и потому ранее используемые только для чтения, из режима монитора доступны для записи, что позволяет ему декларировать возможности, отличные от действительно присутствующих на хозяине.
Привилегии гипервизора, операционной системы и пользователя образуют т.н. луковую (англ. onion) модель. В ней обработка прерываний идёт снаружи внутрь, т.е. сначала каждое из них проверяется на соответствие правилам монитора, затем ОС. Синхронные исключения (ловушки), наоборот, обрабатываются сперва ОС, а затем монитором.
Так же, как это сделано в рассмотренных ранее архитектурах, для ускорения механизмов трансляции адресов используют тэги в TLB и двухуровневую трансляцию в MMU. Для поддержки разработки паравиртуализационных гостей добавлена новая инструкция hypercall, вызывающая ловушку и выход в режим монитора.
Дополнительные темы
В заключение рассмотрим дополнительные вопросы обеспечения эффективной виртуализации, связанные с переключением между режимами монитора и ВМ.
Уменьшение частоты и выходов в режим монитора с помощью предпросмотра инструкций
Частые прерывания работы виртуальной машины из-за необходимости выхода в монитор негативно влияют на скорость симуляции. Несмотря на то, что производители процессоров работают над уменьшением связанных с этими переходами задержек (для примера см. таблицу 1), они всё же достаточно существенны, чтобы пытаться минимизировать их частоту возникновения.
| Микроархитектура | Дата запуска | Задержка, тактов |
|---|---|---|
| Prescott | 3 кв. 2005 | 3963 |
| Merom | 2 кв. 2006 | 1579 |
| Penryn | 1 кв. 2008 | 1266 |
| Nehalem | 3 кв. 2009 | 1009 |
| Westmere | 1 кв. 2010 | 761 |
| Sandy Bridge | 1 кв. 2011 | 784 |
Таблица 1. Длительность перехода между режимами аппаратной виртуализации для различных поколений микроархитектур процессоров Intel IA-32 (данные взяты из [11])
Если прямое исполнение с использованием виртуализации оказывается неэффективным, имеет смысл переключиться на другую схему работы, например, на интерпретацию или двоичную трансляцию (см. мою серию постов на IDZ: 1, 2, 3).
На практике исполнения ОС характерна ситуация, что инструкции, вызывающие ловушки потока управления, образуют кластера, в которых две или более из них находятся недалеко друг от друга, тогда как расстояние между кластерами значительно. В следующем блоке кода для IA-32 приведён пример такого кластера. Звёздочкой обозначены все инструкции, вызывающие выход в монитор.
* in %al,%dx
* out $0x80,%al
mov %al,%cl
mov %dl,$0xc0
* out %al,%dx
* out $0x80,%al
* out %al,%dx
* out $0x80,%al
Для того, чтобы избежать повторения сценария: выход из ВМ в монитор, интерпретация инструкции, обратный вход в ВМ только для того, чтобы на следующей инструкции вновь выйти в монитор, — используется предпросмотр инструкций [11]. После обработки ловушки, прежде чем монитор передаст управление обратно в ВМ, поток инструкций просматривается на несколько инструкций вперёд в поисках привилегированных инструкций. Если они обнаружены, симуляция на некоторое время переключается в режим двоичной трансляции. Тем самым избегается негативное влияние эффекта кластеризации привилегированных инструкций.
Рекурсивная виртуализация
Ситуация, когда монитор виртуальных машин запускается под управлением другого монитора, непосредственно исполняющегося на аппаратуре, называется рекурсивной виртуализацией. Теоретически она может быть не ограничена только двумя уровнями — внутри каждого монитора ВМ может исполняться следующий, тем самым образуя иерархию гипервизоров.
Возможность запуска одного гипервизора под управлением монитора ВМ (или, что тоже самое, симулятора) имеет практическую ценность. Любой монитор ВМ — достаточно сложная программа, к которой обычные методы отладки приложений и даже ОС неприменимы, т.к. он загружается очень рано в процессе работы системы, когда отладчик подключить затруднительно. Исполнение под управлением симулятора позволяет инспектировать и контролировать его работу с самой первой инструкции.
Голдберг и Попек в своей упомянутой ранее работе рассмотрели вопросы эффективной поддержки в том числе и рекурсивной виртуализации. Однако их выводы, к сожалению, не учитывают многие из упомянутых выше особенностей современных систем.
Рассмотрим одно из затруднений, связанных со спецификой вложенного запуска мониторов ВМ — обработку ловушек и прерываний. В простейшем случае за обработку всех типов исключительных ситуаций всегда отвечает самый внешний монитор, задача которого — или обработать событие самостоятельно, тем самым «спрятав» его от остальных уровней, или передать его следующему.
Как для прерываний, так и для ловушек это часто оказывается неоптимальным — событие должно пройти несколько уровней иерархии, каждый из которых внесёт задержку на его обработку. На рис. 5 показана обработка двух типов сообщений — прерывания, возникшего во внешней аппаратуре, и ловушки потока управления, случившейся внутри приложения.
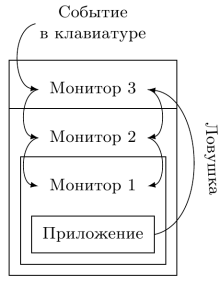
Рис. 5: Рекурсивная виртуализация. Все события должны обрабатываться внешним монитором, который спускает их вниз по иерархии, при этом формируется задержка
Для оптимальной обработки различных типов ловушек и прерываний для каждого из них должен быть выбран уровень иерархии мониторов ВМ, и при возникновении события управление должно передаваться напрямую этому уровню, минуя дополнительную обработку вышележащими уровнями и без связанных с этим накладных расходов.
Поддержка рекурсивной виртуализации в существующих решениях
Задаче аппаратной поддержки второго и более уровней вложенности виртуализации производители процессоров уделяют значительно меньше внимания, чем первому её уровню. Тем не менее такие работы существуют. Так, ещё в восьмидесятых годах двадцатого века для систем IBM/370 [13] была реализована возможность запуска копий системного ПО внутри уже работающей на аппаратуре операционной системы. Для этой задачи была введена инструкция SIE (англ. start interpreted execution) [14]. Существуют предложения об интерфейсе между вложенными уровнями виртуализации [12], который позволил бы эффективно поддерживать вложенность нескольких мониторов ВМ, и реализация рекурсивной виртуализации для IA-32 [15]. Однако современные архитектуры процессоров всё же ограничиваются аппаратной поддержкой максимум одного уровня виртуализации.
Литература
- Goodacre John. Hardware accelerated Virtualization in the ARM Cortex Processors. 2011. xen.org/files/xensummit_oul11/nov2/2_XSAsia11_JGoodacre_HW_accelerated_virtualization_in_the_ARM_Cortex_processors.pdf
- Hardware-assisted Virtualization with the MIPS Virtualization Module. 2012. www.mips.com/application/login/login.dot?product_name=/auth/MD00994-2B-VZMIPS-WHT-01.00.pdf
- Hypervisor/Sun4v Reference Materials. 2012. kenai.com/projects/hypervisor/pages/ReferenceMaterials
- Intel Virtualization Technology / F. Leung, G. Neiger, D. Rodgers et al. // Intel Technology Journal. 2006. Vol. 10. www.intel.com/technology/itj/2006/v10i3
- McGhan Harlan. The gHost in the Machine: Part 1 // Microprocessor Report. 2007. mpronline.com
- McGhan Harlan. The gHost in the Machine: Part 2 // Microprocessor Report. 2007. mpronline.com
- McGhan Harlan. The gHost in the Machine: Part 3 // Microprocessor Report. 2007. mpronline.com
- Popek Gerald J., Goldberg Robert P. Formal requirements for virtualizable third generation architectures // Communications of the ACM. Vol. 17. 1974.
- Southern Gabriel. Analysis of SMP VM CPU Scheduling. 2008. cs.gmu.edu/~hfoxwell/cs671projects/southern_v12n.pdf
- Yang Rongzhen. Virtual Translation Lookaside Buffer. 2008. www.patentlens.net/patentlens/patent/US_2008_0282055_A1/en.
- Software techniques for avoiding hardware virtualization exits / Ole Agesen, Jim Mattson, Radu Rugina, Jeffrey Sheldon // Proceedings of the 2012 USENIX conference on Annual Technical Conference. USENIX ATC'12. Berkeley, CA, USA : USENIX Association, 2012. P. 35-35. www.usenix.org/system/files/conference/atc12/atc12-final158.pdf
- Poon Wing-Chi, Mok A.K. Improving the Latency of VMExit Forwarding in Recursive Virtualization for the x86 Architecture // System Science (HICSS), 2012 45th Hawaii International Conference on. 2012. P. 5604-5612.
- Osisek D. L., Jackson K. M., Gum P. H. ESA/390 interpretive execution architecture, foundation for VM/ESA // IBM Syst. J. — 1991— V. 30, No 1. — Pp. 34–51. — ISSN: 0018-8670. —DOI: 10.1147/sj.301.0034.
- Andy Glew. SIE. — semipublic.comp-arch.net/wiki/SIE
- The Turtles Project: Design and Implementation of Nested Virtualization / Muli Ben-Yehuda [et al.] //. — 2010. — P. 423–436. www.usenix.org/event/osdi10/tech/full_papers/Ben-Yehuda.pdf
