Код исправления ошибок (Error Correction Code или ECC) добавляется к передаваемому сигналу и позволяет не только выявить ошибки при передаче, но и при необходимости исправить их (что в общем-то очевидно из названия), без повторного запроса данных у передатчика. Такой алгоритм работы позволяет передавать данные с постоянной скоростью, что может быть важно во многих случаях. Например, когда вы смотрите цифровое телевидение — смотреть на застывшую картинку, ожидая, пока осуществляются многократные повторные запросы данных, было бы весьма неинтересно.

В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.

Клод Шеннон
LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.

Роберт Галлагер
В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
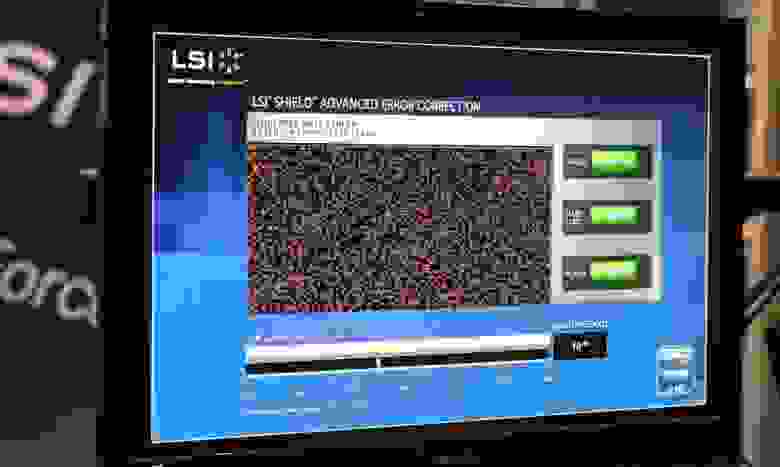
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.

В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.

Клод Шеннон
LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.

Роберт Галлагер
В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
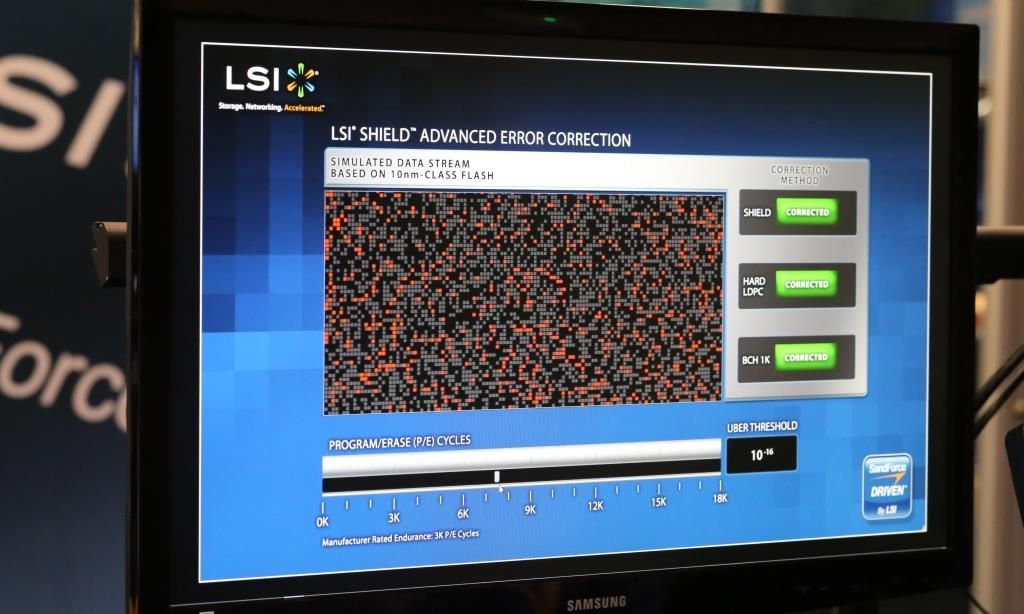
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.
