
Любое приложение для Android, даже написанное только на скриптовых и ненативных языках (таких как Java или HTML5), в конечном счёте использует базисные компоненты среды исполнения, которые должны быть оптимизированы. Хорошими примерами для иллюстрации оптимизационных подходов и потребностей являются приложения, использующие технологии мультимедиа и дополненной реальности, описанные ниже. Для платформы Android (смартфоны и планшеты) Intel использует различные виды процессоров Atom, имеющих SSSE3 уровень векторизации и обычно 2 ядра с гипертредингом – считайте это намеком :) Для тех, кто намек понял, под катом – история оптимизации и распараллеливания одного конкретного приложения израильской компании iOnRoad — iOnRoad.
Постановка задачи
iOnRoad представляет из себя приложение дополненной реальности для смартфонов, помогающее безопасному вождению автомобиля. Используя GPS, сенсоры и видеокамеру смартфона, а также современные алгоритмы компьютерного зрения, приложение предупреждает водителя об уходе с полосы, а также возможном столкновении с другими машинами и препятствиями. Приложение крайне популярно (более миллиона загрузок!), отмечено всевозможными наградами, и имело всего два недостатка:1. Не предупреждает о пьяных водителях соседних машин и красивых девушках, а также иных интересных попутчиках, голосующих на дороге по ходу следования вашего авто.
2. Требует оптимизации, в том числе и по энергопотреблению, так как исходная версия не могла использоваться без подключения смартфона к питанию более 30-40 минут, за это время батарея полностью садилась.
На данный момент недостаток остался только один. Первый.
Итак, работая в реальном времени, приложение конвертирует каждый исходный фрейм формата YUV420/NV21 с камеры смартфона в формат RGB перед дальнейшей его обработкой.
 Изначально функция, реализующая данную трансформацию, использовала до 40% ресурсов процессора, тем самым ограничивая возможности дальнейшей обработки изображений. Таким образом, потребность в оптимизации выглядела настоятельной.
Изначально функция, реализующая данную трансформацию, использовала до 40% ресурсов процессора, тем самым ограничивая возможности дальнейшей обработки изображений. Таким образом, потребность в оптимизации выглядела настоятельной.Единственная существующая оптимизированная функция, которую мы нашли, это функция YUV420ToRGB из пакета IPP (Intel Integrated Performance Primitives library), но она не имеет необходимого для iOnRoad сочетания поддерживаемых входных и выходных форматов. Кроме того, она не многопоточная.
Поэтому было принято решение написать новый оптимизированный код, реализующий необходимую трансформацию.
Трансформация из YUV420/NV21 в RGB
Формат YUV420/NV21 содержит три 8-битные компоненты – яркости Y (чёрно-белую) и две компоненты цветности U и V.
Для получения четвёрки пикселей в стандартном формате RGB (с его тремя цветными компонентами для каждого пикселя), каждой четверке компонент Y требуется только одна пара соответствующих компонент U и V.
На картинке выше соответствующие четверки Y и обслуживающие их пары U и V помечены одним цветом. Данный формат (обычно называемый YUV) обеспечивает двукратную компрессию по сравнению с RGB.
Трансформация YUV в RGB — целочисленный подход с использованием таблиц (look-up table, LUT)
Трансформация YUV в RGB производится по простой линейной формуле. Чтобы избежать преобразования в числа с плавающей точкой, в iOnRoad воспользовались следующей хорошо известной целочисленной аппроксимацией: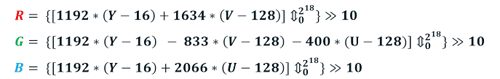
Промежуточные результаты вычислений по этой формуле больше, чем 216 – это важный момент для дальнейших обсуждения векторизации.
Для скалярных вычислений в iOnRoad использовали так называемые таблицы преобразований (look-up table, LUT): поскольку все компоненты Y, U и V — 8-битные, то умножения в приведённых выше формулах могут быть вычислены заранее и 32-битные результаты сохранены в пяти таблицах с 256-ю входами.
Трансформация YUV в RGB – общая идея использования вычислений с фиксированной точкой на базе SSE
SSE не имеет векторных инструкций «сборки» (gather) для работы с LUT; использование векторного умножения 16-битных упакованных чисел представляется более быстрым, чем комбинация из скалярных LUT операций и последующего упаковывания. Однако простое 16-битное SSE умножение (PMULLW) не может быть использовано, так как ожидаемые промежуточные результаты могут быть больше, чем 216. В SSE есть инструкция PMULHRSW, которая комбинирует полное 16-битное умножение и сдвиг вправо 32-битного промежуточного результата до требуемых 16-ти битов с округлением. Для использования этой инструкции, операнды должны быть предварительно сдвинуты влево, обеспечивая максимальное количество значимых битов в конечном результате (в нашем конкретном случае мы можем получить 13-битный конечный результат).Встроенные функции (intrinsics) как средство написания ручного SSE кода
Чтобы помочь избежать написания ручного SSE кода с использованием ассемблера, все известные компиляторы C/C++ (MS, GNU, Intel) имеют набор специальных API, называемых встроенными функциями (intrinsic functions).С точки зрения программиста, встроенная функция выглядит и ведет себя как обычная функция C/C++. На самом деле она представляет из себя обертку одной ассемблерной инструкции SSE и в большинстве случаев компилируется только как эта инструкция. Использование встроенных функций заменяет написание ассемблерного кода со всеми его сложностями при тех же самых показателях производительности.
Например, чтобы вызвать PMULHRSW инструкцию, о которой говорилось выше, в С коде мы использовали встроенную функцию _mm_mulhrs_epi16().
Каждая SSE инструкция имеет соответствующую встроенную функцию, так что необходимый SSE код может быть полностью написан с использованием встроенных функций.
Трансформация YUV в RGB – реализация вычислений с фиксированной точкой на базе SSE
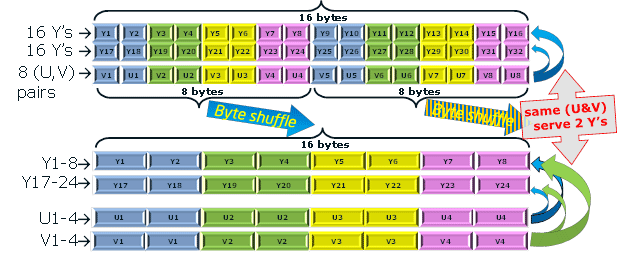
Процесс начинается с загрузки 2-х порций из 16-ти 8-битных Y и 8-ми 8-битных пар (U,V).В результате эти данные будут сконвертированы в 16 32-битных RGB пикселей (в форме FRGB, когда старший байт имеет значение 0xff).
Число 16 вычитается из 16-ти 8-битных Y с использованием операции 8-битного вычитания с насыщением, таким образом отпадает необходимость в проверке результата на отрицательность.
8 пар (U,V) «обслуживают» 2 строки с 16-ю значениями Y.
Для распаковки входных данных используется операция перестановки (shuffle), при этом получается 2 порции из:
- 2-x наборов из 8-ми 16-битных Y;
- 1-го набора из 4-х 16-битных удвоенных U;
- 1-го набора из 4-х 16-битных удвоенных V.
Ниже показана детальная схема изготовления одной порции.
Перед использованием U и V, из них вычитается 128 с помощью 16-битной инструкции _mm_sub_epi16().
После вычитания, все 8 16-битных значений Y, U и V сдвигаются влево, чтобы оптимально подходить для _mm_mulhrs_epi16(); эта инструкция используется с соответствующим образом упакованными коэффициентами.
Замечание: Эти подготовительные шаги (вычитания и сдвиги), упомянутые выше, используются вместо LUT операций в скалярном алгоритме.
Результаты умножения суммируются для получения окончательных 16-битных значений, ограниченных на отрезке между 0 и 213-1 (8191) с использованием _mm_min_epi16() и _mm_max_epi16().
После завершения всех вычислений, мы получаем результат в виде упакованных раздельно 16-битных значений R, G и B.
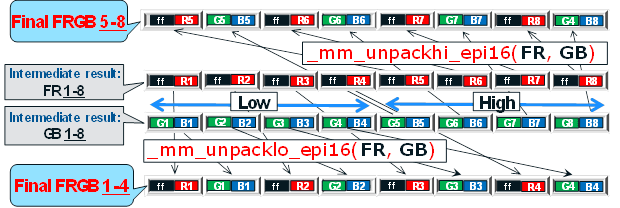
Переупаковка их в формат FRGB (где F – альфа-канал, заполненный единицами согласно требованиям iOnRoad) производится за два шага.
На первом шаге мы переупаковываем 16-битные раздельные значения R, G и B в 16-битные FR и GB с использованием дополнительного регистра, заполненного 16-битным <0xff00>. Эта фаза переупаковки производится с помощью логических сдвигов влево и вправо и логических операций ИЛИ/И, как показано на рисунке:

На втором шаге промежуточные результаты FR и GB окончательно пакуются в FRGB с использованием инструкций распаковки _mm_unpacklo_epi16() и _mm_unpackhi_epi16():
Код, описанный выше, реализующий конверсию YUV в RGB с использованием встроенных векторных функций SSE, даёт 4-х кратное ускорение в сравнении с исходным скалярным кодом, использующим предварительно вычисленные таблицы (LUT).
Использование CILK+ для параллелизации: тривиально
Все версии процессоров Atom, используемые в смартфонах и планшетах, имеют не менее двух ядер (как минимум, логических — HT), а в будущем будут иметь еще больше, поэтому параллелизация алгоритмов для них очень важна.Простейший подход к параллелизации реализован в расширении CILK+ компилятора Intel для языков C и C++ (знаменитый TBB работает только для C++!). Самый простой оператор параллелизации cilk_for (используемый для внешнего цикла конвертации YUV в RGB вместо стандартного for языка C/C++) обеспечивает двукратный прирост производительности на двухядерном процессоре Clover Trail+.
Использование внутренних функций SSE для векторизации совместно с параллелизацией CILK+ дает 8-кратное общее ускорение.
Использование CILK+ для векторизации: Array Notation, function mapping и редукция
CILK+ содержит очень важное расширение, называемое Array Notation, позволяющее существенно повысить эффективность векторизации и в то же время улучшить читаемость кода.Array Notation обеспечивает масштабируемость платформ: один и тот же код может быть оптимально векторизован и под 128-битный Atom, и под 256-битный Haswell, и под 512-битный MIC/Skylake – в отличие от кода, основанного на внутренних функциях SSE/AVX: его приходится переписывать вручную под каждую конкретную платформу. Array Notation позволяет использовать так называемые секции массива в качестве аргументов функции (function mapping), а также для редукции (суммирование, поиск максимума/минимума и т.д.).
Пример использования CILK+ Array Notation
Посмотрите на два фрагмента кода.Исходный код со сложными определениями и разверткой (взято из реального приложения):

И однострочную комбинацию с элементами CILK+, состоящую из секции Array Notation, function mapping и редукции:

Эти два варианта полностью идентичны с функциональной точки зрения, но CILK+ версия работает в 6 раз быстрее!
Выводы и призыв к разработчикам
Внутренние функции SSE (уровень SSSE3) значительно улучшают производительность приложений на устройствах Atom/Intel.Использование CILK+ Array Notation (встроенного в компилятор Intel) обеспечивает большие возможности для автоматической векторизации.
CILK+ — отличное средство для параллелизации приложений на устройствах Atom/Intel.
Наша рекомендация для Atom/Android разработчиков в новом «андроидном» мире: не стесняйтесь оптимизировать свои мультимедийные приложения и игры с помощью SSE и CILK+ — эти проверенные средства обеспечат вам огромный скачок в производительности!
Автор текста — Григорий Данович, Старший Инженер по Прикладным Решениям, Intel Израиль.
