Добрый день уважаемые читатели. В сегодняшней посте я продолжу свой цикл статей посвященный анализу данных на python c помощью модуля Pandas и расскажу один из вариантов использования данного модуля в связке с модулем для машинного обучения scikit-learn. Работа данной связки будет показана на примере задачи про спасенных с "Титаника". Данное задание имеет большую популярность среди людей, только начинающих заниматься анализом данных и машинным обучением.
Итак суть задачи состоит в том, чтобы с помощью методов машинного обучения построить модель, которая прогнозировала бы спасется человек или нет. К задаче прилагаются 2 файла:
Как было написано выше, для анализ понадобятся модули Pandas и scikit-learn. С помощью Pandas мы проведем начальный анализ данных, а sklearn поможет в вычислении прогнозной модели. Итак, для начала загрузим нужные модули:
Кроме того даются пояснения по некоторым полям:
>Итак, задача сформирована и можно приступить к ее решению.
Для начала загрузим тестовую выборку и посмотрим как она выглядит::
Можно предположить, что чем выше социальный статус, тем больше вероятность спасения. Давайте проверим это взглянув на количество спасшихся и утонувших в зависимости в разрезе классов. Для этого нужно построить следующую сводную:
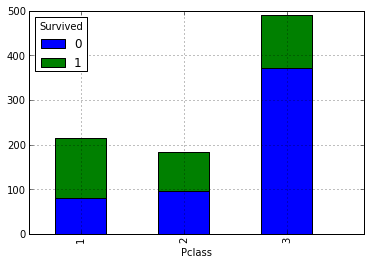
Наше вышеописанное предположение про то, что чем выше у пассажиров их социальное положение, тем выше их вероятность спасения. Теперь давайте взглянем, как количество родственников влияет на факт спасения:
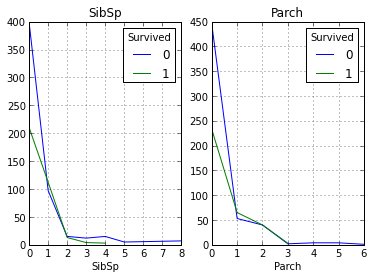
Как видно из графиков наше предположение снова подтвердилось, и из людей имеющих больше 1 родственников спаслись не многие.
Сейчас порассуждаем на предмет данных, которые находятся номера кают. Теоретически данных о каютах пользователей может не быть, так что давайте посмотрим на столько это поле заполнено:
В итоге заполнено всего 204 записи и 890, на основании этого можно сделать вывод, что данное поле при анализе можно опустить.
Следующее поле, которое мы разберем будет поле с возрастом (Age). Посмотрим на сколько оно заполнено:
Данное поле практически все заполнено (714 непустых записей), но есть пустые значения, которые не определены. Давайте зададим ему значение равное медиане по возрасту из всей выборки. Данный шаг нужен для более точного построения модели:
У нас осталось разобраться с полями Ticket, Embarked, Fare, Name. Давайте посмотрим на поле Embarked, в котором находится порт посадки и проверим есть ли такие пассажиры у которых порт не указан:
Итак у нас нашлось 2 таких пассажира. Давайте присвоим эти пассажирам порт в котором село больше всего людей:
Ну что же разобрались еще с одним полем и теперь у нас остались поля с имя пассажира, номером билета и ценой билета.
По сути нам из этих трех полей нам нужна только цена(Fare), т.к. она в какой-то мере определяем ранжирование внутри классов поля Pclass. Т. е. например люди внутри среднего класса могут быть разделены на тех, кто ближе к первому(высшему) классу, а кто к третьему(низший). Проверим это поле на пустые значения и если таковые имеются заменим цену медианой по цене из все выборки:
В нашем случае пустых записей нет.
В свою очередь номер билета и имя пассажира нам никак не помогут, т. к. это просто справочная информация. Единственное для чего они могут пригодиться — это определение кто из пассажиров потенциально являются родственниками, но так как люди у которых есть родственники практически не спаслись (это было показано выше) можно пренебречь этими данными.
Теперь, после удаления всех ненужных полей, наш набор выглядит так:
Предварительный анализ данных завершен, и по его результатам у нас получилась некая выборка, в которой содержатся несколько полей и вроде бы можно преступить к построению модели, если бы не одно «но»: наши данные содержат не только числовые, но и текстовые данные.
Поэтому переде тем, как строить модель, нужно закодировать все наши текстовые значения.
Можно это сделать в ручную, а можно с помощью модуля sklearn.preprocessing. Давайте воспользуемся вторым вариантом.
Закодировать список с фиксированными значениями можно с помощью объекта LabelEncoder(). Суть данной функции заключается в том, что на вход ей подается список значений, который надо закодировать, на выходе получается список классов индексы которого и являются кодами элементов поданного на вход списка.
В итоге наши исходные данные будут выглядеть так:
Теперь нам надо написать код для приведения проверочного файла в нужный нам вид. Для этого можно просто скопировать куски кода которые были выше(или просто написать функцию для обработки входного файла):
Код описанный выше выполняет практически те же операции, что мы проделали с обучающей выборкой. Отличие в том, что добавилась строка для обработки поля Fare, если оно вдруг не заполнено.
Ну что же, данные обработаны и можно приступить к построению модели, но для начала нужно определиться с тем, как мы будем проверять точность полученной модели. Для данной проверки мы будем использовать скользящий контроль и ROC-кривые. Проверку будем выполнять на обучающей выборке, после чего применим ее на тестовую.
Итак рассмотрим несколько алгоритмов машинного обучения:
Загрузим нужные нам библиотеки:
Для начала, надо разделить нашу обучаюшую выборку на показатель, который мы исследуем, и признаки его определяющие:
Теперь наша обучающая выборка выглядит так:
Теперь разобьем показатели полученные ранее на 2 подвыборки(обучающую и тестовую) для расчет ROC кривых (для скользящего контроля этого делать не надо, т.к. функция проверки это делает сама. В этом нам поможет функция train_test_split модуля cross_validation:
В качестве параметров ей передается:
На выходе функция выдает 4 массива:
Далее представлены перечисленные методы с наилучшими параметрами подобранные опытным путем:
Теперь проверим полученные модели с помощью скользящего контроля. Для этого нам необходимо воcпользоваться функцией cross_val_score
Давайте посмотрим на графике средний показатель тестов перекрестной проверки каждой модели:
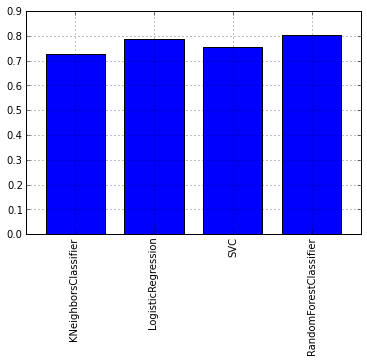
Как можно увидеть из графика лучше всего себя показал алгоритм RandomForest. Теперь же давайте взглянем на графики ROC-кривых, для оценки точности работы классификатора. Графики будем рисовать с помощью библиотеки matplotlib:
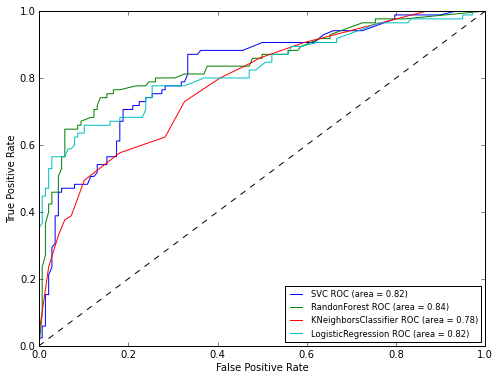
Как видно по результатам ROC-анализа лучший результат опять показал RandomForest. Теперь осталось только применить нашу модель к тестовой выборке:
В данной статье я постарался показать, как можно использовать пакет pandas в связке с пакетом для машинного обучения sklearn. Полученная модель при сабмите на Kaggle показала точность 0.77033. В статье я больше хотел показать именно работу с инструментарием и ход выполнения исследования, а не построение подробного алгоритма, как например в этой серии статей.
Постановка задачи
Итак суть задачи состоит в том, чтобы с помощью методов машинного обучения построить модель, которая прогнозировала бы спасется человек или нет. К задаче прилагаются 2 файла:
- train.csv — набор данных на основании которого будет строиться модель (обучающая выборка)
- test.csv — набор данных для проверки модели
Как было написано выше, для анализ понадобятся модули Pandas и scikit-learn. С помощью Pandas мы проведем начальный анализ данных, а sklearn поможет в вычислении прогнозной модели. Итак, для начала загрузим нужные модули:
Кроме того даются пояснения по некоторым полям:
- PassengerId — идентификатор пассажира
- Survival — поле в котором указано спасся человек (1) или нет (0)
- Pclass — содержит социально-экономический статус:
- высокий
- средний
- низкий
- Name — имя пассажира
- Sex — пол пассажира
- Age — возраст
- SibSp — содержит информацию о количестве родственников 2-го порядка (муж, жена, братья, сетры)
- Parch — содержит информацию о количестве родственников на борту 1-го порядка (мать, отец, дети)
- Ticket — номер билета
- Fare — цена билета
- Cabin — каюта
- Embarked — порт посадки
- C — Cherbourg
- Q — Queenstown
- S — Southampton
Анализ входных данных
>Итак, задача сформирована и можно приступить к ее решению.
Для начала загрузим тестовую выборку и посмотрим как она выглядит::
from pandas import read_csv, DataFrame, Series
data = read_csv('Kaggle_Titanic/Data/train.csv')| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35 | 0 | 0 | 373450 | 8.0500 | NaN | S |
Можно предположить, что чем выше социальный статус, тем больше вероятность спасения. Давайте проверим это взглянув на количество спасшихся и утонувших в зависимости в разрезе классов. Для этого нужно построить следующую сводную:
data.pivot_table('PassengerId', 'Pclass', 'Survived', 'count').plot(kind='bar', stacked=True)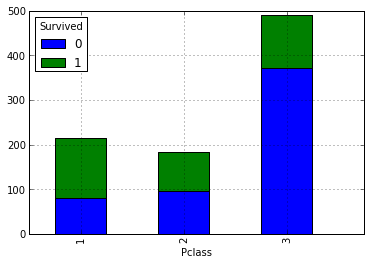
Наше вышеописанное предположение про то, что чем выше у пассажиров их социальное положение, тем выше их вероятность спасения. Теперь давайте взглянем, как количество родственников влияет на факт спасения:
fig, axes = plt.subplots(ncols=2)
data.pivot_table('PassengerId', ['SibSp'], 'Survived', 'count').plot(ax=axes[0], title='SibSp')
data.pivot_table('PassengerId', ['Parch'], 'Survived', 'count').plot(ax=axes[1], title='Parch')
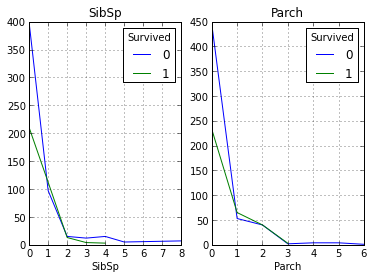
Как видно из графиков наше предположение снова подтвердилось, и из людей имеющих больше 1 родственников спаслись не многие.
Сейчас порассуждаем на предмет данных, которые находятся номера кают. Теоретически данных о каютах пользователей может не быть, так что давайте посмотрим на столько это поле заполнено:
data.PassengerId[data.Cabin.notnull()].count()В итоге заполнено всего 204 записи и 890, на основании этого можно сделать вывод, что данное поле при анализе можно опустить.
Следующее поле, которое мы разберем будет поле с возрастом (Age). Посмотрим на сколько оно заполнено:
data.PassengerId[data.Age.notnull()].count()Данное поле практически все заполнено (714 непустых записей), но есть пустые значения, которые не определены. Давайте зададим ему значение равное медиане по возрасту из всей выборки. Данный шаг нужен для более точного построения модели:
data.Age = data.Age.median()У нас осталось разобраться с полями Ticket, Embarked, Fare, Name. Давайте посмотрим на поле Embarked, в котором находится порт посадки и проверим есть ли такие пассажиры у которых порт не указан:
data[data.Embarked.isnull()]| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 62 | 1 | 1 | Icard, Miss. Amelie | female | 28 | 0 | 0 | 113572 | 80 | B28 | NaN |
| 830 | 1 | 1 | Stone, Mrs. George Nelson (Martha Evelyn) | female | 28 | 0 | 0 | 113572 | 80 | B28 | NaN |
Итак у нас нашлось 2 таких пассажира. Давайте присвоим эти пассажирам порт в котором село больше всего людей:
MaxPassEmbarked = data.groupby('Embarked').count()['PassengerId']
data.Embarked[data.Embarked.isnull()] = MaxPassEmbarked[MaxPassEmbarked == MaxPassEmbarked.max()].index[0]
Ну что же разобрались еще с одним полем и теперь у нас остались поля с имя пассажира, номером билета и ценой билета.
По сути нам из этих трех полей нам нужна только цена(Fare), т.к. она в какой-то мере определяем ранжирование внутри классов поля Pclass. Т. е. например люди внутри среднего класса могут быть разделены на тех, кто ближе к первому(высшему) классу, а кто к третьему(низший). Проверим это поле на пустые значения и если таковые имеются заменим цену медианой по цене из все выборки:
data.PassengerId[data.Fare.isnull()]В нашем случае пустых записей нет.
В свою очередь номер билета и имя пассажира нам никак не помогут, т. к. это просто справочная информация. Единственное для чего они могут пригодиться — это определение кто из пассажиров потенциально являются родственниками, но так как люди у которых есть родственники практически не спаслись (это было показано выше) можно пренебречь этими данными.
Теперь, после удаления всех ненужных полей, наш набор выглядит так:
data = data.drop(['PassengerId','Name','Ticket','Cabin'],axis=1)| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked |
|---|---|---|---|---|---|---|---|
| 0 | 3 | male | 28 | 1 | 0 | 7.2500 | S |
| 1 | 1 | female | 28 | 1 | 0 | 71.2833 | C |
| 1 | 3 | female | 28 | 0 | 0 | 7.9250 | S |
| 1 | 1 | female | 28 | 1 | 0 | 53.1000 | S |
| 0 | 3 | male | 28 | 0 | 0 | 8.0500 | S |
Предварительная обработка входных данных
Предварительный анализ данных завершен, и по его результатам у нас получилась некая выборка, в которой содержатся несколько полей и вроде бы можно преступить к построению модели, если бы не одно «но»: наши данные содержат не только числовые, но и текстовые данные.
Поэтому переде тем, как строить модель, нужно закодировать все наши текстовые значения.
Можно это сделать в ручную, а можно с помощью модуля sklearn.preprocessing. Давайте воспользуемся вторым вариантом.
Закодировать список с фиксированными значениями можно с помощью объекта LabelEncoder(). Суть данной функции заключается в том, что на вход ей подается список значений, который надо закодировать, на выходе получается список классов индексы которого и являются кодами элементов поданного на вход списка.
from sklearn.preprocessing import LabelEncoder
label = LabelEncoder()
dicts = {}
label.fit(data.Sex.drop_duplicates()) #задаем список значений для кодирования
dicts['Sex'] = list(label.classes_)
data.Sex = label.transform(data.Sex) #заменяем значения из списка кодами закодированных элементов
label.fit(data.Embarked.drop_duplicates())
dicts['Embarked'] = list(label.classes_)
data.Embarked = label.transform(data.Embarked)В итоге наши исходные данные будут выглядеть так:
| Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked |
|---|---|---|---|---|---|---|---|
| 0 | 3 | 1 | 28 | 1 | 0 | 7.2500 | 2 |
| 1 | 1 | 0 | 28 | 1 | 0 | 71.2833 | 0 |
| 1 | 3 | 0 | 28 | 0 | 0 | 7.9250 | 2 |
| 1 | 1 | 0 | 28 | 1 | 0 | 53.1000 | 2 |
| 0 | 3 | 1 | 28 | 0 | 0 | 8.0500 | 2 |
Теперь нам надо написать код для приведения проверочного файла в нужный нам вид. Для этого можно просто скопировать куски кода которые были выше(или просто написать функцию для обработки входного файла):
test = read_csv('Kaggle_Titanic/Data/test.csv')
test.Age[test.Age.isnull()] = test.Age.mean()
test.Fare[test.Fare.isnull()] = test.Fare.median() #заполняем пустые значения средней ценой билета
MaxPassEmbarked = test.groupby('Embarked').count()['PassengerId']
test.Embarked[test.Embarked.isnull()] = MaxPassEmbarked[MaxPassEmbarked == MaxPassEmbarked.max()].index[0]
result = DataFrame(test.PassengerId)
test = test.drop(['Name','Ticket','Cabin','PassengerId'],axis=1)
label.fit(dicts['Sex'])
test.Sex = label.transform(test.Sex)
label.fit(dicts['Embarked'])
test.Embarked = label.transform(test.Embarked)
Код описанный выше выполняет практически те же операции, что мы проделали с обучающей выборкой. Отличие в том, что добавилась строка для обработки поля Fare, если оно вдруг не заполнено.
| Pclass | Sex | Age | SibSp | Parch | Fare | Embarked |
|---|---|---|---|---|---|---|
| 3 | 1 | 34.5 | 0 | 0 | 7.8292 | 1 |
| 3 | 0 | 47.0 | 1 | 0 | 7.0000 | 2 |
| 2 | 1 | 62.0 | 0 | 0 | 9.6875 | 1 |
| 3 | 1 | 27.0 | 0 | 0 | 8.6625 | 2 |
| 3 | 0 | 22.0 | 1 | 1 | 12.2875 | 2 |
Построение моделей классификации и их анализ
Ну что же, данные обработаны и можно приступить к построению модели, но для начала нужно определиться с тем, как мы будем проверять точность полученной модели. Для данной проверки мы будем использовать скользящий контроль и ROC-кривые. Проверку будем выполнять на обучающей выборке, после чего применим ее на тестовую.
Итак рассмотрим несколько алгоритмов машинного обучения:
Загрузим нужные нам библиотеки:
from sklearn import cross_validation, svm
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
import pylab as pl
Для начала, надо разделить нашу обучаюшую выборку на показатель, который мы исследуем, и признаки его определяющие:
target = data.Survived
train = data.drop(['Survived'], axis=1) #из исходных данных убираем Id пассажира и флаг спасся он или нет
kfold = 5 #количество подвыборок для валидации
itog_val = {} #список для записи результатов кросс валидации разных алгоритмов
Теперь наша обучающая выборка выглядит так:
| Pclass | Sex | Age | SibSp | Parch | Fare | Embarked |
|---|---|---|---|---|---|---|
| 3 | 1 | 28 | 1 | 0 | 7.2500 | 2 |
| 1 | 0 | 28 | 1 | 0 | 71.2833 | 0 |
| 3 | 0 | 28 | 0 | 0 | 7.9250 | 2 |
| 1 | 0 | 28 | 1 | 0 | 53.1000 | 2 |
| 3 | 1 | 28 | 0 | 0 | 8.0500 | 2 |
Теперь разобьем показатели полученные ранее на 2 подвыборки(обучающую и тестовую) для расчет ROC кривых (для скользящего контроля этого делать не надо, т.к. функция проверки это делает сама. В этом нам поможет функция train_test_split модуля cross_validation:
ROCtrainTRN, ROCtestTRN, ROCtrainTRG, ROCtestTRG = cross_validation.train_test_split(train, target, test_size=0.25)
В качестве параметров ей передается:
- Массив параметров
- Массив значений показателей
- Соотношение в котором будет разбита обучающая выборка (в нашем случае для тестового набора будет выделена 1/4 часть данных исходной обучающей выборки)
На выходе функция выдает 4 массива:
- Новый обучающий массив параметров
- тестовый массив параметров
- Новый массив показателей
- тестовый массив показателей
Далее представлены перечисленные методы с наилучшими параметрами подобранные опытным путем:
model_rfc = RandomForestClassifier(n_estimators = 70) #в параметре передаем кол-во деревьев
model_knc = KNeighborsClassifier(n_neighbors = 18) #в параметре передаем кол-во соседей
model_lr = LogisticRegression(penalty='l1', tol=0.01)
model_svc = svm.SVC() #по умолчанию kernek='rbf'
Теперь проверим полученные модели с помощью скользящего контроля. Для этого нам необходимо воcпользоваться функцией cross_val_score
scores = cross_validation.cross_val_score(model_rfc, train, target, cv = kfold)
itog_val['RandomForestClassifier'] = scores.mean()
scores = cross_validation.cross_val_score(model_knc, train, target, cv = kfold)
itog_val['KNeighborsClassifier'] = scores.mean()
scores = cross_validation.cross_val_score(model_lr, train, target, cv = kfold)
itog_val['LogisticRegression'] = scores.mean()
scores = cross_validation.cross_val_score(model_svc, train, target, cv = kfold)
itog_val['SVC'] = scores.mean()
Давайте посмотрим на графике средний показатель тестов перекрестной проверки каждой модели:
DataFrame.from_dict(data = itog_val, orient='index').plot(kind='bar', legend=False)
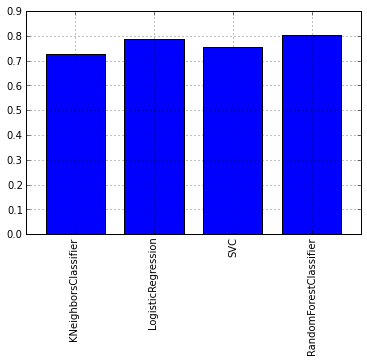
Как можно увидеть из графика лучше всего себя показал алгоритм RandomForest. Теперь же давайте взглянем на графики ROC-кривых, для оценки точности работы классификатора. Графики будем рисовать с помощью библиотеки matplotlib:
pl.clf()
plt.figure(figsize=(8,6))
#SVC
model_svc.probability = True
probas = model_svc.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('SVC', roc_auc))
#RandomForestClassifier
probas = model_rfc.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('RandonForest',roc_auc))
#KNeighborsClassifier
probas = model_knc.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('KNeighborsClassifier',roc_auc))
#LogisticRegression
probas = model_lr.fit(ROCtrainTRN, ROCtrainTRG).predict_proba(ROCtestTRN)
fpr, tpr, thresholds = roc_curve(ROCtestTRG, probas[:, 1])
roc_auc = auc(fpr, tpr)
pl.plot(fpr, tpr, label='%s ROC (area = %0.2f)' % ('LogisticRegression',roc_auc))
pl.plot([0, 1], [0, 1], 'k--')
pl.xlim([0.0, 1.0])
pl.ylim([0.0, 1.0])
pl.xlabel('False Positive Rate')
pl.ylabel('True Positive Rate')
pl.legend(loc=0, fontsize='small')
pl.show()
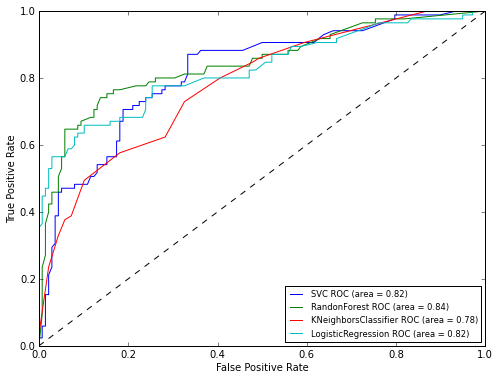
Как видно по результатам ROC-анализа лучший результат опять показал RandomForest. Теперь осталось только применить нашу модель к тестовой выборке:
model_rfc.fit(train, target)
result.insert(1,'Survived', model_rfc.predict(test))
result.to_csv('Kaggle_Titanic/Result/test.csv', index=False)
Заключение
В данной статье я постарался показать, как можно использовать пакет pandas в связке с пакетом для машинного обучения sklearn. Полученная модель при сабмите на Kaggle показала точность 0.77033. В статье я больше хотел показать именно работу с инструментарием и ход выполнения исследования, а не построение подробного алгоритма, как например в этой серии статей.
