Введение
Добрый день, уважаемые читатели.
Недавно, бродя по просторам глобальной паутины, я наткнулся на турнир, который проводился банком ТКС в начале этого года. Ознакомившись с заданиями, я решил проверить свои навыки в анализе данных на них.
Начать проверку я решил с задачи о скоринге (Задание №3). Для ее решения я, как всегда, использовал Python с аналитическими модулями pandas и scikit-learn.
Описание данных и постановка задачи
Банк запрашивает кредитную историю заявителя в трех крупнейших российских кредитных бюро. Предоставляется выборка клиентов Банка в файле SAMPLE_CUSTOMERS.CSV. Выборка разделена на части «train» и «test». По выборке «train» известно значение целевой переменной bad — наличие "дефолта" (допущение клиентом просрочки 90 и более дней в течение первого года пользования кредитом). В файле SAMPLE_ACCOUNTS.CSV предоставлены данные из ответов кредитных бюро на все запросы по соответствующим клиентам.
Формат данных SAMPLE_CUSTOMERS – информация о возможности дефолта определенного человека.
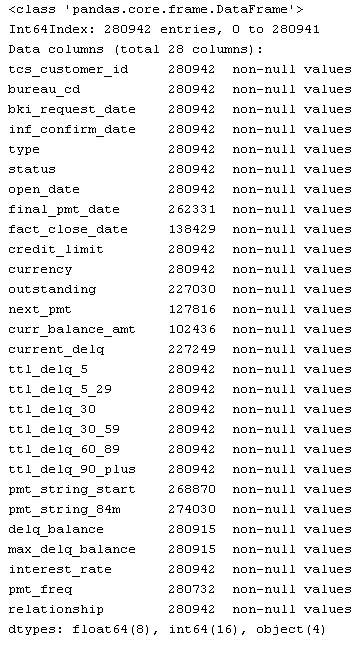
Описание формата набора данных SAMPLE_ACCOUNTS:
Описание набора
| Name | Description |
|---|---|
| TCS_CUSTOMER_ID | Идентификатор клиента |
| BUREAU_CD | Код бюро, из которого получен счет |
| BKI_REQUEST_DATE | Дата, в которую был сделан запрос в бюро |
| CURRENCY | Валюта договора (ISO буквенный код валюты) |
| RELATIONSHIP | Тип отношения к договору |
| 1 — Физическое лицо | |
| 2 — Дополнительная карта/Авторизованный пользователь | |
| 4 — Совместный | |
| 5 — Поручитель | |
| 9 — Юридическое лицо | |
| OPEN_DATE | Дата открытия договора |
| FINAL_PMT_DATE | Дата финального платежа (плановая) |
| TYPE | Код типа договора |
| 1 – Кредит на автомобиль | |
| 4 – Лизинг | |
| 6 – Ипотека | |
| 7 – Кредитная карта | |
| 9 – Потребительский кредит | |
| 10 – Кредит на развитие бизнеса | |
| 11 – Кредит на пополнение оборотных средств | |
| 12 – Кредит на покупку оборудования | |
| 13 – Кредит на строительство недвижимости | |
| 14 – Кредит на покупку акций (например, маржинальное кредитование) | |
| 99 – Другой | |
| PMT_STRING_84M | Дисциплина (своевременность) платежей. Строка составляется из кодов состояний счета на моменты передачи банком данных по счету в бюро, первый символ — состояние на дату PMT_STRING_START, далее последовательно в порядке убывания дат. |
| 0 – Новый, оценка невозможна | |
| X – Нет информации | |
| 1 – Оплата без просрочек | |
| A – Просрочка от 1 до 29 дней | |
| 2 – Просрочка от 30 до 59 дней | |
| 3 – Просрочка от 60 до 89 дней | |
| 4 – Просрочка от 90 до 119 дней | |
| 5 – Просрочка более 120 дней | |
| 7 – Регулярные консолидированные платежи | |
| 8 – Погашение по кредиту с использованием залога | |
| 9 – Безнадёжный долг/ передано на взыскание/ пропущенный платеж | |
| STATUS | Статус договора |
| 00 – Активный | |
| 12 – Оплачен за счет обеспечения | |
| 13 – Счет закрыт | |
| 14 – Передан на обслуживание в другой банк | |
| 21 – Спор | |
| 52 – Просрочен | |
| 61 – Проблемы с возвратом | |
| OUTSTANDING | Оставшаяся непогашенная задолженность. Сумма в рублях по курсу ЦБ РФ |
| NEXT_PMT |
Размер следующего платежа. Сумма в рублях по курсу ЦБ РФ |
| INF_CONFIRM_DATE | Дата подтверждения информации по счету |
| FACT_CLOSE_DATE |
Дата закрытия счета (фактическая) |
| TTL_DELQ_5 |
Количество просрочек до 5 дней |
| TTL_DELQ_5_29 |
Количество просрочек от 5 до 29 дней |
| TTL_DELQ_30_59 |
Количество просрочек от 30 до 59 дней |
| TTL_DELQ_60_89 |
Количество просрочек от 60 до 89 дней |
| TTL_DELQ_30 |
Количество просрочек до 30 дней |
| TTL_DELQ_90_PLUS |
Количество просрочек 90+ дней |
| PMT_FREQ |
Код частоты платежей |
| 1 – Еженедельно |
|
| 2 – Раз в две недели |
|
| 3 – Ежемесячно |
|
| A — Раз в 2 месяца |
|
| 4 – Поквартально |
|
| B — Раз в 4 месяца |
|
| 5 – Раз в полгода |
|
| 6 — Ежегодно |
|
| 7 – Другое |
|
| CREDIT_LIMIT |
Кредитный лимит. Сумма в рублях по курсу ЦБ РФ |
| DELQ_BALANCE |
Текущая просроченная задолженность. Сумма в рублях по курсу ЦБ РФ |
| MAX_DELQ_BALANCE |
Максимальный объем просроченной задолженности. Сумма в рублях по курсу ЦБ РФ |
| CURRENT_DELQ |
Текущее количество дней просрочки |
| PMT_STRING_START |
Дата начала строки PMT_STRING_84M |
| INTEREST_RATE |
Процентная ставка по кредиту |
| CURR_BALANCE_AMT |
Общая выплаченная сумма, включая сумму основного долга, проценты, пени и штрафы. Сумма в рублях по курсу ЦБ РФ |
Задача состоит в том, чтобы на выборке «train» необходимо построить модель, определяющую вероятность «дефолта», и проставить вероятности ее по клиентам из выборки «test». Для оценки модели будет использоваться характеристика Area Under ROC Curve (также указано в условиях задачи).
Предварительная обработка данных
Для начала загрузим исходные файлы и посмотрим на них:
from pandas import read_csv, DataFrame
from sklearn.metrics import roc_curve
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.cross_validation import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.decomposition import PCA
import ml_metrics, string, re, pylab as pl
SampleCustomers = read_csv("https://static.tcsbank.ru/documents/olymp/SAMPLE_CUSTOMERS.csv", ';')
SampleAccounts = read_csv("https://static.tcsbank.ru/documents/olymp/SAMPLE_ACCOUNTS.csv",";",decimal =',')
print SampleAccounts
SampleCustomers.head()| tcs_customer_id | bad | sample_type | |
|---|---|---|---|
| 0 | 1 | NaN | test |
| 1 | 2 | 0 | train |
| 2 | 3 | 1 | train |
| 3 | 4 | 0 | train |
| 4 | 5 | 0 | train |
Из условий задачи можно предположить, что набор SampleAccounts содержит несколько записей по одному заемщику давайте проверим это:
SampleAccounts.tcs_customer_id.drop_duplicates().count(), SampleAccounts.tcs_customer_id.count()Наше предположение оказалось верным. Уникальных заемщиков 50000 из 280942 записей. Это связано с тем, что у одно заемщика быть несколько кредитов и по каждому из них в разных бюро моте быть разная информация. Следовательно, надо выполнить преобразования над SampleAccounts, чтобы одному заемщику соответствовала одна строка.
Теперь давайте получим список все уникальных кредитов по каждому заемщику:
SampleAccounts[['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency']].drop_duplicates()Следовательно, когда мы получили список кредитов, мы сможем вывести какую-либо общую информацию по каждому элементу списка. Т.е. можно было бы взять связку из перечисленных выше полей и сделать ее индексом, относительно которого мы бы производили дальнейшие манипуляции, но, к сожалению, тут нас подстерегает один неприятный момент. Он заключается в том, что поле 'final_pmt_date' в наборе данных имеет незаполненные значения. Давайте попробуем избавиться от них.
У нас в наборе есть поле фактическая дата закрытия кредита, следовательно, если она есть, а поле 'final_pmt_date' не заполнено, то можно в него записать данное значение. Для остальных же просто запишем 0.
SampleAccounts.final_pmt_date[SampleAccounts.final_pmt_date.isnull()] = SampleAccounts.fact_close_date[SampleAccounts.final_pmt_date.isnull()].astype(float)
SampleAccounts.final_pmt_date.fillna(0, inplace=True)
Теперь, когда от пустых значений мы избавились, давайте получим самую свежую дату обращения в какое-либо из бюро по каждому из кредитов. Это пригодиться нам для определения его атрибутов, таких как статус договора, тип и т.д.
sumtbl = SampleAccounts.pivot_table(['inf_confirm_date'], ['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'], aggfunc='max')
sumtbl.head(15)
| inf_confirm_date | |||||
|---|---|---|---|---|---|
| tcs_customer_id | open_date | final_pmt_date | credit_limit | currency | |
| 1 | 39261 | 39629 | 19421 | RUB | 39924 |
| 39505 | 39870 | 30000 | RUB | 39862 | |
| 39644 | 40042 | 11858 | RUB | 40043 | |
| 39876 | 41701 | 300000 | RUB | 40766 | |
| 39942 | 40308 | 19691 | RUB | 40435 | |
| 40421 | 42247 | 169000 | RUB | 40756 | |
| 40428 | 51386 | 10000 | RUB | 40758 | |
| 40676 | 41040 | 28967 | RUB | 40764 | |
| 2 | 40472 | 40618 | 7551 | RUB | 40661 |
| 40652 | 40958 | 21186 | RUB | 40661 | |
| 3 | 39647 | 40068 | 22694 | RUB | 40069 |
| 40604 | 0 | 20000 | RUB | 40624 | |
| 4 | 38552 | 40378 | 75000 | RUB | 40479 |
| 39493 | 39797 | 5000 | RUB | 39823 | |
| 39759 | 40123 | 6023 | RUB | 40125 |
Теперь добавим полученные нами даты к основному набору:
SampleAccounts = SampleAccounts.merge(sumtbl, 'left',
left_on=['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'],
right_index=True,
suffixes=('', '_max'))Итак, далее мы разобьем столбы, в которых параметры строго определены, таким образом, чтобы каждому значению из этих полей соответствовал отдельный столбец. По условию столбцами с заданными значениями будут:
- pmt_string_84m
- pmt_freq
- type
- status
- relationship
- bureau_cd
Код для их преобразования приведен ниже:
# преобразуем pmt_string_84m
vals = list(xrange(10)) + ['A','X']
PMTstr = DataFrame([{'pmt_string_84m_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.pmt_string_84m])
SampleAccounts = SampleAccounts.join(PMTstr).drop(['pmt_string_84m'], axis=1)
# преобразуем pmt_freq
SampleAccounts.pmt_freq.fillna(7, inplace=True)
SampleAccounts.pmt_freq[SampleAccounts.pmt_freq == 0] = 7
vals = list(range(1,8)) + ['A','B']
PMTstr = DataFrame([{'pmt_freq_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.pmt_freq])
SampleAccounts = SampleAccounts.join(PMTstr).drop(['pmt_freq'], axis=1)
# преобразуем type
vals = [1,4,6,7,9,10,11,12,13,14,99]
PMTstr = DataFrame([{'type_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.type])
SampleAccounts = SampleAccounts.join(PMTstr).drop(['type'], axis=1)
# преобразуем status
vals = [0,12, 13, 14, 21, 52,61]
PMTstr = DataFrame([{'status_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.status])
SampleAccounts = SampleAccounts.join(PMTstr).drop(['status'], axis=1)
# преобразуем relationship
vals = [1,2,4,5,9]
PMTstr = DataFrame([{'relationship_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.relationship])
SampleAccounts = SampleAccounts.join(PMTstr).drop(['relationship'], axis=1)
# преобразуем bureau_cd
vals = [1,2,3]
PMTstr = DataFrame([{'bureau_cd_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.bureau_cd])
SampleAccounts = SampleAccounts.join(PMTstr).drop(['bureau_cd'], axis=1)
Следующим шагом, преобразуем поле 'fact_close_date', в котором содержится дата последнего фактического платежа, чтобы в нем содержалось только 2 значения:
- 0 — не было последнего платежа
- 1 — последний платеж был
Данную замену я сделал потому, что изначально поле было заполнено наполовину.
SampleAccounts.fact_close_date[SampleAccounts.fact_close_date.notnull()] = 1
SampleAccounts.fact_close_date.fillna(0, inplace=True)
Теперь из нашего набора данных нам надо вытащить свежие данные по всем кредитам. В этом нам поможет поле «inf_confirm_date_max», полученное выше. В него мы добавили крайнюю дату обновления информации по кредиту во всех бюро:
PreFinalDS = SampleAccounts[SampleAccounts.inf_confirm_date == SampleAccounts.inf_confirm_date_max].drop_duplicates()После вышеописанных действий наша выборка существенно сократилась, но теперь нам надо обобщить всю информацию по кредиту и заемщику полученную ранее. Для этого произведем группировку нашего набора данных:
PreFinalDS = PreFinalDS.groupby(['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency']).max().reset_index()Наши данные почти готовы к началу анализа. Осталось выполнить еще несколько действий:
- Убрать ненужные столбцы
- Привести все кредитные лимиты в рубли
- Посчитать какое количество кредитов у каждого заемщика по информации от бюро
Начнем с очистки таблицы от ненужных столбцов:
PreFinalDS = PreFinalDS.drop(['bki_request_date',
'inf_confirm_date',
'pmt_string_start',
'interest_rate',
'open_date',
'final_pmt_date',
'inf_confirm_date_max'], axis=1)
Далее переведем все кредитные лимиты к рублям. Для простоты я взял курсы валют на текущий момент. Хотя правильнее наверное было бы брать курс на момент открытия счета. Еще один нюанс, в том, что для анализа нам надо убрать текстовое поле «сurrency», поэтому после перевода валют в рубли мы проведем с этим полем манипуляцию, которые мы провели с полями выше:
curs = DataFrame([33.13,44.99,36.49,1], index=['USD','EUR','GHF','RUB'], columns=['crs'])
PreFinalDS = PreFinalDS.merge(curs, 'left', left_on='currency', right_index=True)
PreFinalDS.credit_limit = PreFinalDS.credit_limit * PreFinalDS.crs
#выделяем значения в отдельные столбцы
vals = ['RUB','USD','EUR','CHF']
PMTstr = DataFrame([{'currency_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in PreFinalDS.currency])
PreFinalDS = PreFinalDS.join(PMTstr).drop(['currency','crs'], axis=1)
Итак перед заключительной группировкой добавим к нашему набору поле заполненное единицами. Т.е. когда мы выполним последнюю группировку, сумма по нему даст количество кредитов у заемщика:
PreFinalDS['count_credit'] = 1Теперь, когда у нас в наборе данных все данные количественные, можно заполнить пробелы в данных 0 и выполнить заключительную группировку по клиенту:
PreFinalDS.fillna(0, inplace=True)
FinalDF = PreFinalDS.groupby('tcs_customer_id').sum()
FinalDF
Предварительный анализ
Ну что же первичная обработка данных завершена и можно приступить к их анализу. Для начала разделим наши данные на обучающую и тестовую выборки. В этом нам поможет столбец «sample_type» из SampleCustomers, по нему как раз сделано такое разделение.
Для того чтобы разбить наш обработанный DataFrame, достаточно объединить его с SampleCustomers поиграться фильтрами:
SampleCustomers.set_index('tcs_customer_id', inplace=True)
UnionDF = FinalDF.join(SampleCustomers)
trainDF = UnionDF[UnionDF.sample_type == 'train'].drop(['sample_type'], axis=1)
testDF = UnionDF[UnionDF.sample_type == 'test'].drop(['sample_type'], axis=1)
Далее давайте посмотрим, как признаки коррелирует между собой, для этого построим матрицу с коэффициентами корреляции признаков. С помощью pandas это можно сделать одной командой:
CorrKoef = trainDF.corr()После действия выше CorrKoef будет содержать матрицу размеров 61x61.
Строками и столбцами ее будут соответствующие имена полей, а на их пересечении — значение коэффициента корреляции. Например:
| fact_close_date | |
|---|---|
| status_13 | 0.997362 |
Возможен случай, когда коэффициента корреляции нет. Это значит, что в данные поля скорее всего заполнены только одним одинаковым значением и их можно опустить при анализе. Проверим:
FieldDrop = [i for i in CorrKoef if CorrKoef[i].isnull().drop_duplicates().values[0]]
На выходе мы получили список полей которые можно удалить:
- pmt_string_84m_6
- pmt_string_84m_8
- pmt_freq_5
- pmt_freq_A
- pmt_freq_B
- status_12
Следующим шагом мы найдем поля которые коррелируют между собой (у которых коэффициент корреляции больше 90%), используя нашу матрицу:
CorField = []
for i in CorrKoef:
for j in CorrKoef.index[CorrKoef[i] > 0.9]:
if i <> j and j not in CorField and i not in CorField:
CorField.append(j)
print "%s-->%s: r^2=%f" % (i,j, CorrKoef[i][CorrKoef.index==j].values[0])
На выходе получим следующие:
fact_close_date-->status_13: r^2=0.997362
ttl_delq_5_29-->ttl_delq_30: r^2=0.954740
ttl_delq_5_29-->pmt_string_84m_A: r^2=0.925870
ttl_delq_30_59-->pmt_string_84m_2: r^2=0.903337
ttl_delq_90_plus-->pmt_string_84m_5: r^2=0.978239
delq_balance-->max_delq_balance: r^2=0.986967
pmt_freq_3-->relationship_1: r^2=0.909820
pmt_freq_3-->currency_RUB: r^2=0.910620
pmt_freq_3-->count_credit: r^2=0.911109
Итак, исходя из связей которые мы получили на предыдущем шаге, мы можем добавить в список удаления следующие поля:
FieldDrop =FieldDrop + ['fact_close_date','ttl_delq_30',
'pmt_string_84m_5',
'pmt_string_84m_A',
'pmt_string_84m_A',
'max_delq_balance',
'relationship_1',
'currency_RUB',
'count_credit']
newtr = trainDF.drop(FieldDrop, axis=1)
Построение и выбор модели
Ну что же первичные данные обработаны и теперь можно перейти к построению модели.
Отделим признак класса от обучающей выборки:
target = newtr.bad.values
train = newtr.drop('bad', axis=1).values
Теперь давайте уменьшим размерность нашей выборки, дабы взять только значимые параметры. Для этого воспользуемся методом главных компонент и его реализацией PCA() в модуле sklearn. В параметре мы передаем количество компонент, которые мы хотим сохранить(я выбрал 20, т.к. при них результаты моделей практически не отличались от результатов по исходным данным)
coder = PCA(n_components=20)
train = coder.fit_transform(train)
Пришло время для определения моделей классификации. Возьмем несколько различных алгоритмов и сравним результаты их работы при помощи характеристики Area Under ROC Curve (auc). Для моделирования будут рассмотрены следующие алгоритмы:
models = []
models.append(RandomForestClassifier(n_estimators=165, max_depth=4, criterion='entropy'))
models.append(GradientBoostingClassifier(max_depth =4))
models.append(KNeighborsClassifier(n_neighbors=20))
models.append(GaussianNB())
Итак модели выбраны. Давайте сейчас разобьем нашу обучающую выборку на 2 подвыборки: тестовую и обучающую. Данное действие нужно чтобы мы могли посчитать характеристику auc для наших моделей. Разбиение можно провести функцией train_test_split() из модуля sklearn:
TRNtrain, TRNtest, TARtrain, TARtest = train_test_split(train, target, test_size=0.3, random_state=0)Осталось осталось обучить наши модели и оценить результат.
Для расчета характеристики auc есть 2 пути:
- Стандартными средствами модуля sklearn при помощи функции roc_auc_score или auc
- С помощью стороннего пакета ml_metrics и функции auc()
Я воспользуюсь вторым способом, т.к. первый был показан в предыдущей статье. Пакет ml_metrics является очень полезным дополнением к sklearn, т.к. в нем присутствуют некоторые метрики, которых нет в sklearn.
Итак, построим ROC кривые и посчитаем их площади:
plt.figure(figsize=(10, 10))
for model in models:
model.fit(TRNtrain, TARtrain)
pred_scr = model.predict_proba(TRNtest)[:, 1]
fpr, tpr, thresholds = roc_curve(TARtest, pred_scr)
roc_auc = ml_metrics.auc(TARtest, pred_scr)
md = str(model)
md = md[:md.find('(')]
pl.plot(fpr, tpr, label='ROC fold %s (auc = %0.2f)' % (md, roc_auc))
pl.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6))
pl.xlim([0, 1])
pl.ylim([0, 1])
pl.xlabel('False Positive Rate')
pl.ylabel('True Positive Rate')
pl.title('Receiver operating characteristic example')
pl.legend(loc="lower right")
pl.show()
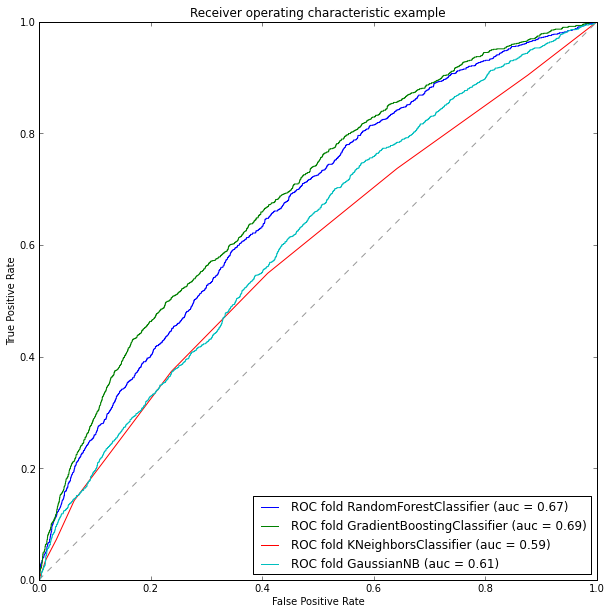
Итак, по результатам анализа наших моделей можно сказать, что лучше всего себя показал градиентный бустинг, его точность порядка 69%. Соответственно для обучения тестовой выборки мы выберем его. Давайте заполним информацию в тестовой выборке, предварительно обработав ее до нужного формата:
#приводим тестовую выборку к нужному формату
FieldDrop.append('bad')
test = testDF.drop(FieldDrop, axis=1).values
test = coder.fit_transform(test)
#обучаем модель
model = models[1]
model.fit(train, target)
#записываем результат
testDF.bad = model.predict(test)
Заключение
В качестве заключения хотелось бы отметить, что полученная точность модели в 69%, является недостаточно хорошей, но большей точности я добиться не смог. Хотелось бы отметить, тот факт, что при построении модели по полной размерности, т.е. без учета коррелируемых столбцов и сокращения размерности, она дала так же 69% точности (это можно легко проверить используя набор trainDF для обучения модели)
В данной статье, я постарался показать все основные этапы анализа данных от первичной обработки сырых данных до построения модели классификатора. Кроме того, хотелось бы отметить, что в анализируемые модели не был включен метод опорных векторов, это связано с тем, что после нормализации данных точность модели опустилась до 51% и лучший результат который мне удалось получить с ним был в районе 60%, при значительных затратах по времени.
Также хотелось бы отметить, что, к сожалению на тестовой выборке результат проверить не удалось, т.к. не уложился в сроки проведения турнира.
