Хочу задать этот вопрос Хабровчанам.
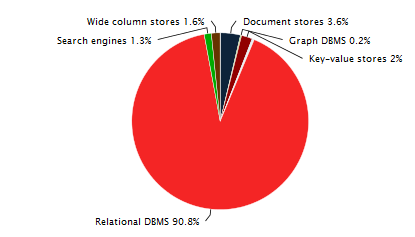
Современные информационные системы строятся на различных видах СУБД и все же реляционные СУБД остаются самыми распространенными и используемыми. Интересная статистика на эту тему ТУТ и ТУТ.
При разработке и модификации систем уровень формализации знаний аналитиков и разработчиков остается небольшим (автоматизации создания умных запросов или с учетом ряда четких правил) и чаще всего результирующие SQL запросы написаны «нормально», «как привык», «так пишут у нас на фирме», а вопросы оптимизации остаются на этап выполнения запросов в СУБД и последующие этапы оптимизации (в худшем случае ждут, когда все начинает тормозить).
Объем ручного кода остается большим даже несмотря на наличие большого количества удобных инструментов, позволяющих избежать их ручного написания (в т.ч. и ORM). Да и не всегда есть возможность использовать такие инструменты, особенно когда речь идет об очень сложных аналитических запросах, включающих сложный анализ данных. А такие инструменты как ORM используют в более менее свежих проектах и только для тривиальных запросов.
В любом случае необходимость в оптимизации запросов и, возможно, структуры СУБД постоянна на промышленной базе. Даже при «идеальном» проектировании этого не избежать т.к. окружающая среда меняется и сам заказчик не всегда знает что будет завтра (как поменяются законы, рынок, клиенты, какие новые идеи появятся и т.д.).

При оптимизации в СУБД возникает ряд таких же проблем, как и при оптимизации кода для обычного языка программирования — поиск и отслеживание одинакового кода, замена его во всех местах на новый, оптимизированный и т.п… И хорошо если бы все SQL запросы лежали в одном месте и можно было бы пройтись простым поиском и заменить ))) Но так уж исторически сложилось, что большинство технологий не выделяют слой запросов в отдельные структуры/объекты/файлы/ и т.д. В лучшем случае запросы действительно выделены в отдельные файлы.
Вариантом получения всех запросов может быть, например, SQL-логгер (почти во всех СУБД есть или встроенный или можно прикрутить). Но в таком случае надо выбрать период получения всех запросов например в год, что долго (для обычного предприятия за год проходят все основные операции которые могут быть… почти :) ), да и проблема определения параметров останется открытой…
Тут, на Хабре, и в интернете на рус. и англ. языках очень много информации на тему оптимизации запросов и отдельно структуры СУБД, а вот материалов на тему анализа всех запросов для последующей оптимизации действительно мало. А то что есть касается больше рекомендаций аналитических, автоматизированных средств для этого я не нашла…
Скажите, хабровчане, встречались ли вы с комплексным анализом всей популяции SQL-запросов приложения?
На мой взгляд есть три основные причины для комплексного анализа структуры SQL запросов:
1. оптимизация кода: выделение дублирующегося кода, замена дублирующегося кода при его оптимизации, выдача различных автоматических подсказок по улучшению структуры кода.
2. рефакторинг кода (оптимизация в данном случае не обязательный эффект).
3. научный интерес, например, анализ лесов SQL промышленных систем для последующего исследования, например иммитационного моделирования леса запросов SQL для анализа новых алгоритмов оптимизации работы СУБД.
На мой взгляд наличие средства такого анализа позволило бы значительно упростить работу многих программистов и некоторых ученых, работающих над алгоритмами оптимизации в СУБД.
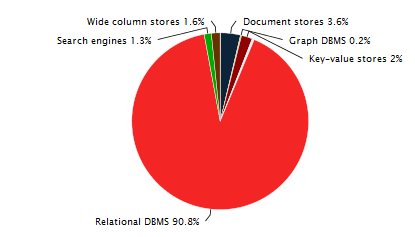
Современные информационные системы строятся на различных видах СУБД и все же реляционные СУБД остаются самыми распространенными и используемыми. Интересная статистика на эту тему ТУТ и ТУТ.
При разработке и модификации систем уровень формализации знаний аналитиков и разработчиков остается небольшим (автоматизации создания умных запросов или с учетом ряда четких правил) и чаще всего результирующие SQL запросы написаны «нормально», «как привык», «так пишут у нас на фирме», а вопросы оптимизации остаются на этап выполнения запросов в СУБД и последующие этапы оптимизации (в худшем случае ждут, когда все начинает тормозить).
Объем ручного кода остается большим даже несмотря на наличие большого количества удобных инструментов, позволяющих избежать их ручного написания (в т.ч. и ORM). Да и не всегда есть возможность использовать такие инструменты, особенно когда речь идет об очень сложных аналитических запросах, включающих сложный анализ данных. А такие инструменты как ORM используют в более менее свежих проектах и только для тривиальных запросов.
В любом случае необходимость в оптимизации запросов и, возможно, структуры СУБД постоянна на промышленной базе. Даже при «идеальном» проектировании этого не избежать т.к. окружающая среда меняется и сам заказчик не всегда знает что будет завтра (как поменяются законы, рынок, клиенты, какие новые идеи появятся и т.д.).
При оптимизации в СУБД возникает ряд таких же проблем, как и при оптимизации кода для обычного языка программирования — поиск и отслеживание одинакового кода, замена его во всех местах на новый, оптимизированный и т.п… И хорошо если бы все SQL запросы лежали в одном месте и можно было бы пройтись простым поиском и заменить ))) Но так уж исторически сложилось, что большинство технологий не выделяют слой запросов в отдельные структуры/объекты/файлы/ и т.д. В лучшем случае запросы действительно выделены в отдельные файлы.
Вариантом получения всех запросов может быть, например, SQL-логгер (почти во всех СУБД есть или встроенный или можно прикрутить). Но в таком случае надо выбрать период получения всех запросов например в год, что долго (для обычного предприятия за год проходят все основные операции которые могут быть… почти :) ), да и проблема определения параметров останется открытой…
Тут, на Хабре, и в интернете на рус. и англ. языках очень много информации на тему оптимизации запросов и отдельно структуры СУБД, а вот материалов на тему анализа всех запросов для последующей оптимизации действительно мало. А то что есть касается больше рекомендаций аналитических, автоматизированных средств для этого я не нашла…
Скажите, хабровчане, встречались ли вы с комплексным анализом всей популяции SQL-запросов приложения?
На мой взгляд есть три основные причины для комплексного анализа структуры SQL запросов:
1. оптимизация кода: выделение дублирующегося кода, замена дублирующегося кода при его оптимизации, выдача различных автоматических подсказок по улучшению структуры кода.
2. рефакторинг кода (оптимизация в данном случае не обязательный эффект).
3. научный интерес, например, анализ лесов SQL промышленных систем для последующего исследования, например иммитационного моделирования леса запросов SQL для анализа новых алгоритмов оптимизации работы СУБД.
На мой взгляд наличие средства такого анализа позволило бы значительно упростить работу многих программистов и некоторых ученых, работающих над алгоритмами оптимизации в СУБД.
Only registered users can participate in poll. Log in, please.
Встречались ли вы с комплексным анализом всей популяции SQL-запросов большого приложения?
2.17% Да, использовал автоматические средства оптимизации (напишите, пожалуйста, о них в комментариях)2
22.83% Да, но только аналитические методы оптимизации… (напишите, пожалуйста, о них в комментариях)21
64.13% Нет59
16.3% Затрудняюсь ответить15
92 users voted. 48 users abstained.
