
Немного истории
В 2011 году в DevOps-среде возникло движение, объединившееся под хештегом #monitoringsucks, и критиковавшее существующие системы мониторинга за отсутствие гибкости. Что именно их не устраивало — прекрасно иллюстрирует эта презентация.
Если вкратце — хочется людям некоего стандарта API для взаимодействия между компонентами мониторинга, ну и появления самих этих компонент, чтоб из них строить гибкий и умный мониторинг.
Итогом этой волны недовольства стали массовые обсуждения проблем и привлечение внимания к интересным утилитам типа Sensu и Riemann.
В 2013 году хештег в сообществе сменился — теперь это #monitoringlove. Произошло это благодаря развитию opensource-утилит для мониторинга.
Из новых утилит наибольший интерес представляет Sensu. Riemann я не стал всерьез рассматривать, поскольку на данный момент у него нет никаких средств для обеспечения отказоустойчивости, да и сама идея писать конфиг на Clojure мне не сильно нравится.
Именно о Sensu я и расскажу в этой статье, опишу базовые принципы работы и приведу пример решения типичной задачи мониторинга.
Основные факты о Sensu:
* Написан на Ruby, использует EventMachine (я бы предпочел Python, но ладно).
* Конфиги в JSON
* Может использовать плагины от Nagios.
* Работает через RabbitMQ, в PUSH-режиме, когда клиенты сами шлют серверу
результаты проверок по мере готовности.
* Есть пакеты DEB, RPM и даже MSI.
* Есть модули для puppet и cookbook для Chef.
На изображении ниже представлена схема работы Sensu. На мой взгляд, все очень логично, и такая схема работы дает масштабирование и отказоустойчивость «из коробки».
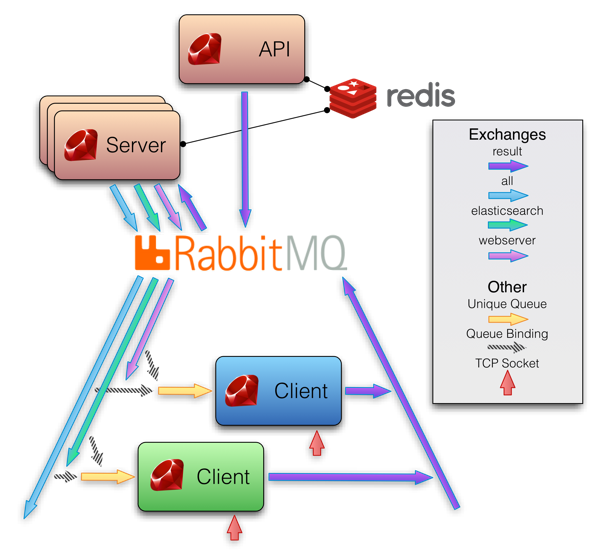
Система состоит из трех основных компонентов: sensu-server, sensu-api, и на клиентах sensu-client. Также доступна sensu-dashboard. Установка тривиальна и подробно освещена в документации, для последней на данный момент версии 0.12 она доступна тут. Как я уже упоминал, есть deb, rpm и msi пакеты.
Базовые понятия
Для того, чтобы понять, как все это работает, надо разобраться в терминологии. Я не ставлю целью перевод официальной документации, а хочу дать базовые понятия, чтоб было понятно, о чем будет в дальнейшем идти речь.
У нас есть следующие сущности:
Клиент (Client)
Это некий сервер с установленным и настроенным sensu-client, который публикует информацию о себе в RabbitMQ и таким образом регистрируется в системе мониторинга Sensu. От сервера Sensu он получает набор проверок, и выполняет их, складывая результат в RabbitMQ.
Для самоидентификации ему нужна конфигурация, которая выглядит примерно так (взято из документации):
{
"client": {
"name": "i-424242",
"address": "127.0.0.1",
"subscriptions": [
"production",
"webserver",
"mysql"
]
}
}
Все довольно очевидно, за исключением «подписок» (subscriptions). Подписки представляют собой список ролей, ассоциированных с этим сервером, и определяют список выполняющихся на нем проверок. Более тонкая настройка описана в официально документации, из полезного можно добавить любые поля, значения из которых можно будет использовать в проверках, а также интервал времени, который должен пройти для генерации события об уходе клиента в оффлайн.
Проверка (Check)
Проверки определяют команды, которые будут запускаться на клиентах, и их параметры. Полностью совместимы с плагинами Nagios, т.е. используют exit code как критерий успешности проверки, а STDOUT или STDERR как источник данных. Проверки настраиваются в конфигурации sensu-server, типичная проверка выглядит так (пример из документации):
{
"checks": {
"chef_client": {
"command": "check-chef-client.rb",
"subscribers": [
"production"
],
"interval": 60
"handlers": [
"pagerduty",
"irc"
]
}
}
}
Из интересного тут опять-таки подписки и хендлеры. Подписки определяют, на каких клиентах будет эта команда запущена.
А набор хендлеров определяют список команд, которые будут выполнены при обработке данных от этой проверки. О них мы дальше поговорим.
Стоит отметить, что проверка может быть «метрикой» (metric), т.е. данные из ее STDOUT будут всегда просто передаваться в хендлеры. Таким образом можно слать данные метрик куда-нибудь для хранения или рисования графиков (например, в Graphite). Подробности в документации.
Хендлеры (Handlers)
Хендлеры определяют команды, которые будут запускаться на сервере мониторинга при поступлении данных от проверок, и их параметры. Например, этот хендлер при получении от какой-либо проверки не-нулевого exit code выполнит команду
mail -s 'sensu event' email@address.com (пример из документации):{
"handlers": {
"mail": {
"type": "pipe",
"command": "mail -s 'sensu event' email@address.com"
}
}
}
Тут все очевидно, хендлеров в репозитории плагинов куча. Можно слать в Pagerduty, и письма отправлять, и в Graylog2 слать в gelf. Подробности в документации.
Всего вышеперечисленного уже достаточно, чтобы соорудить работающую систему. Есть еще мутаторы, расширения и API, но это нам сейчас не важно.
Приступаем к самому интересному
Sensu позиционируется именно как «фреймворк для мониторинга», и это значит, что «из коробки» в нем ничего привычного по энтерпрайз-системам типа Zabbix нет. Вся функциональность добавляется благодаря плагинам.
Попробуем сделать что-нибудь полезное. Возьмем простую задачу — выполнять проверки относительно Redis на клиентах, в случае проблем выводить алерт на панель Dashing, а также для истории слать сообщение в Graylog2 и email на адрес admin@example.com. А еще снимать метрики с Redis и отправлять на хранение в Graphite, а потом по агрегированным значениям keys тоже выполнять проверки.
Клиенты имеют адреса 192.168.1.2N, Graphite развернут на 192.168.1.80:8082, RabbitMQ и Redis тоже на 192.168.1.80. Graylog2 слушает на 192.168.1.81, там же развернута Dashing.
Конфигурация
Начнем с конфигурации клиентов.
Допустим, у нас есть N серверов в роли redis.
Конфигурация клиента выглядит так:
/etc/sensu/config.json
{
"client": {
"graphite_server": "192.168.1.80:8082",
"address": "192.168.1.2N",
"name": "clientN",
"subscriptions": [
"redis"
]
}
"rabbitmq": {
"vhost": "/sensu",
"host": "192.168.1.80",
"password": "password",
"port": 5672,
"user": "sensu"
}
}
и размещается на каждом из N клиентов.
Все остальные файлы конфигураций только на сервере Sensu.
Основные настройки:
/etc/sensu/conf.d/settings.json
{
"api": {
"host": "192.168.1.80",
"port": 4567
},
"redis": {
"host": "192.168.1.80",
"port": 6379
},
"rabbitmq": {
"vhost": "/sensu",
"host": "192.168.1.80",
"password": "password",
"port": 5672,
"user": "sensu"
},
"mailer": {
"mail_from": "sensu@example.com",
"smtp_port": "25",
"mail_to": "admin@example.com",
"smtp_address": "localhost"
},
"dashing": {
"auth_token": "YOUR_AUTH_TOKEN",
"host": "http://192.168.1.81:8088"
},
"gelf": {
"server": "192.168.1.81"
"port": "12201",
}
}
Как вы видите, мы настроили не только сам Sensu, но и параметры для хендлеров dashing, gelf и mailer.
Теперь определим сами эти хендлеры:
/etc/sensu/conf.d/handlers.json
{
"handlers": {
"default": {
"type": "set",
"handlers": [
"mailer",
"dashing",
"gelf"
]
},
"gelf": {
"type": "pipe",
"command": "/etc/sensu/handlers/gelf.rb"
},
"mailer": {
"type": "pipe",
"command": "/etc/sensu/handlers/mailer.rb"
},
"dashing": {
"type": "pipe",
"command": "/etc/sensu/handlers/dashing.rb"
},
"graphite": {
"mutator": "only_check_output",
"type": "amqp",
"exchange": {
"durable": true,
"type": "topic",
"name": "metrics"
}
}
}
}
Тут все просто. Заметьте, что в Graphite мы данные шлем через AMQP. Хендлеры надо разложить на сервере мониторинга в /etc/sensu/handlers.
Теперь настроим проверки, которые будут выполняться на клиентах:
/etc/sensu/conf.d/checks.json
{
"checks": {
"redis_processes": {
"interval": 60,
"command": "/etc/sensu/plugins/processes/check-procs.rb -p redis -c 8 -C 0 -w 7 -W 1",
"subscribers": [
"redis",
],
"handlers": [
"default"
]
},
"redis_memory": {
"dependencies": [
"redis_processes"
],
"command": "/etc/sensu/plugins/redis/check-redis-memory.rb -c 204800 -w 51200",
"interval": 60,
"subscribers": [
"redis",
],
"handlers": [
"default"
]
},
"redis_metric": {
"handlers": [
"graphite"
],
"interval": 60,
"dependencies": [
"redis_processes"
],
"command": "/etc/sensu/plugins/redis/redis-graphite.rb --scheme stats.:::name:::.redis",
"subscribers": [
"redis",
],
"type": "metric"
},
"redis_keys_from_graphite": {
"interval": 60,
"command": "/etc/sensu/plugins/graphite/check-data.rb -s :::graphite_server::: -t stats.:::name:::.redis.db0.keys -w 500 -c 900 -a 120",
"subscribers": [
"redis"
],
"dependencies": [
"redis_processes"
],
"handlers": [
"default"
]
}
}
}
Проверки осуществляются плагинами Sensu, которые надо разложить на клиентах в /etc/sensu/plugins. Для знакомых с Nagios тут ничего нового, интересна только метрика redis_metric, из которой мы в Graphite данные кладем, а потом в проверке redis_keys_from_graphite достаем и проверяем данные за последние 10 минут. Вообще, почти каждый плагин имеет ключ --help, который выдает вполне вменяемую справку по использованию.
Вот и вся конфигурация. Все наглядно, все можно хранить в репозитории, и это прекрасно.
Конечно, надо настроить еще Dashing и Graphite, но это я оставлю за рамками статьи. Инструкция по настройке Sensu + Graphite можно найти тут, а с Dashing все и так понятно.
А еще у Sensu есть простенький dashboard, на котором можно увидеть список клиентов, проверок, и сработавших алертов. Через API и с помощью dashboard можно выключать генерацию алертов для любых хостов или проверок, а также видеть общее состояние системы.
Выглядит он как-то так (скрин не мой):
Выводы
Как мы видим, Sensu берет на себя только роль маршрутизатора и организатора, а вся грязная работа делается внешними программами. Это позволяет сохранять небольшой размер исходного кода, и общую простоту системы. Регистрация клиентов через RabbitMQ позволяет избавиться от механизма «обнаружения» клиентов, что особенно удобно для облаков. Масштабируется все очень просто, пример HA + load balancing можно увидеть тут.
Я использую Sensu в продакшне, параллельно с Zabbix, уже около месяца, ну и в тестовом варианте пару месяцев использовал. Гибкость Sensu позволила настроить мониторинг ключевых параметров и метрик проекта с выводом на панель Dashing, в то время как Zabbix я использую уже очень давно, и занимается он сейчас более комплексным мониторингом. В общем, для многих проектов, особенно в облаках, Sensu будет прекрасным выбором, поскольку дает возможность гибко маршрутизировать события, а также хорошо приспособлен к динамической натуре облаков. В презентациях я встречал цифры в тысячи серверов под наблюдением Sensu, так что с производительностью проблем нет.
В заключение хочу указать на минусы и плюсы Sensu (все IMHO):
Минусы Sensu
- Имеющиеся хендлеры уведомлений куцые по настройкам. Это сейчас главный минус, если вы не пользуетесь сервисами типа PagerDuty. Единственное решение — писать свой хитрый хендлер.
- Конфиг в json, а не в yaml.
- Нужен внешний хранитель метрик, он же рисователь графиков.
- Не слишком полная документация. К счастью, проект простой, можно разобраться, просто читая код.
Плюсы Sensu
- Конфиг можно хранить в git, раскладывать все с помощью Chef/Puppet.
- Масштабируемость.
- Отказоустойчивость.
- Гибкость выбора системы хранения данных.
- Поддержка плагинов Nagios.
- Авто-подключение клиентов.
- Механизм подписок.
- Данные публикуются клиентами по мере генерации.
- Результаты проверок можно гибко направлять в разные хендлеры.
