Spanner – географически распределенная высокомасштабируемая мультиверсионная база данных с поддержкой распределенных транзакций. Хранилище было разработана инженерами Google для внутренних сервисов корпорации. Research paper [8], описывающий базовые принципы и архитектуру Spanner, был представлен на научной конференции 10th USENIX Symposium on Operating Systems Design and Implementation в 2012 году.
Spanner является эволюционным развитием NoSQL-предшественника – Google Bigtable. Сам же c Spanner относят к семейству NewSQL-решений. В research paper [8] заявляется, что дизайн Spanner позволяет системе масштабироваться на миллионы вычислительных узлов через сотни дата-центров и работать с триллионами строк данных.

Spanner использует Colossus (GFS нового поколения) как слой хранения (storage) и алгоритм разрешения коллизий Paxos. В свою очередь на основе (on top) Spanner построена распределенная СУБД Google F1.
Spanner используется в социальной сети Google+, в почтовом сервисе GMail. Построенная на основе Spanner СУБД Google F1 использовалась на момент публикации [8] в сервисе Google Ad Service.
Данные в Spanner хранятся в полуреляционных таблицах, имеющих схему. Все данные имеют версию – временную метку (timestamp) подтверждения записи этих данных (commit). Spanner имеет SQL-подобный язык запросов, возможность конфигурировать количество реплик и политики Garbage Collector, ответственного за удаление записей со «старыми» временными метками.
Кроме уже «привычных» для NoSQL-мира возможностей, Spanner обладает и рядом сложно реализуемых в распределенных системах свойств. Таких как:
Кроме того Spanner обладает возможностями, больше свойственными для СУБД, такими как:
Каждый развернутый экземпляр (deployment) Spanner именуется Universe и содержит в себе:
Каждый из Zone, в свою очередь, содержит в себе:
В research paper [8] подробно описаны функции и внутренне устройство только Spanserver.
Каждый Spanserver содержит в себе от 100 до 1000 структур данных называемых tablet.
В отличии от Bigtable, Spanner добавляет к структуре хранимых данных метку времени добавления этих данных, что является важным введением для реализации поддержки мульти-версионности данных.
Модель данных в Spanner – полуреляционные таблицы с поддержкой схем данных (schematized), SQL-подобного языка запросов и распределенных транзакций.
Реализация последних (транзакций) стала возможна благодаря одному из наиболее инновационных нововведений для такого рода программных систем – программного интерфейса TrueTime API.
Обычная задача для систем предоставления глобального времени (в частности атомных часов) – это предоставление максимально точного времени. TrueTime API же предоставляет клиентам глобальное время + некоторую неопределенность – TTinterval.
Это нужно потому, что для распределенных систем очень сложно гарантировать мгновенность отклика узлов, что важно для обеспечения согласованности данных в распределенном хранилище.
При подходе, когда вместо точного времени, возвращается некоторых временной интервал выполнение 2-ух конкурентных транзакций сводится (упрощенно) к сравнению TTinterval этих транзакций. Если TTinterval транзакций не пересекается, то можно однозначно узнать, какая из транзакций должна быть выполнена раньше. Если TTinterval – пересекается, то сказать можно только с определенной степенью вероятности. (Подробнее о аппаратной части сервиса TrueTime.)
В самом же Spanner согласованность данных при проведении транзакций обеспечивается протоколом двухфазной фиксации транзакции (2-Phase Commit Protocol), реализованным с помощью алгоритма Paxos.
На момент публикации research paper [8] Spanner не поддерживал вторичные индексы и автоматический resharding для целей балансировки нагрузки. Кроме того, авторы [8] отмечают, что Spanner не способен эффективно исполнять сложные SQL-запросы.
Spanner также не является «опровержением» CAP-теоремы. Spanner не является AP-системой, несмотря на свою NoSQL-природу; как и не является CA-системой, несмотря наподдержку стремление поддержки принципов ACID. Spanner «жертвует» доступностью (availability) для поддержания целостности данных (consistency) и поэтому является CP-системой.
Spanner взял лучшие идеи двух миров — реляционных СУБД и NoSQL – и представляет из себя СУБД поколения NewSQL.
Поддержка распределенных транзакций между дата-центрами на объеме данных, идущим на петабайты, с такой способностью к масштабированию – безусловно крайне впечатляющее свойство для любой системы хранения структурированных и полуструктурированных данных. Данная возможность во многом стала следствием симбиоза двух подходов: подхода к хранению данных – данные иммутабельны и содержат метку времени коммита – и инновационной концепции получения глобального времени – TrueTime.
[8] James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, et al. Spanner: Google’s Globally-Distributed Database. Proceedings of OSDI, 2012.
* Полный список источников, используемый для подготовки цикла.
Дмитрий Петухов,
MCP,PhD Student, IT-зомби,
человек с кофеином вместо эритроцитов.
Spanner является эволюционным развитием NoSQL-предшественника – Google Bigtable. Сам же c Spanner относят к семейству NewSQL-решений. В research paper [8] заявляется, что дизайн Spanner позволяет системе масштабироваться на миллионы вычислительных узлов через сотни дата-центров и работать с триллионами строк данных.

Spanner использует Colossus (GFS нового поколения) как слой хранения (storage) и алгоритм разрешения коллизий Paxos. В свою очередь на основе (on top) Spanner построена распределенная СУБД Google F1.
Spanner используется в социальной сети Google+, в почтовом сервисе GMail. Построенная на основе Spanner СУБД Google F1 использовалась на момент публикации [8] в сервисе Google Ad Service.
Базовые принципы
Данные в Spanner хранятся в полуреляционных таблицах, имеющих схему. Все данные имеют версию – временную метку (timestamp) подтверждения записи этих данных (commit). Spanner имеет SQL-подобный язык запросов, возможность конфигурировать количество реплик и политики Garbage Collector, ответственного за удаление записей со «старыми» временными метками.
Кроме уже «привычных» для NoSQL-мира возможностей, Spanner обладает и рядом сложно реализуемых в распределенных системах свойств. Таких как:
- поддержка распределенных транзакций;
- глобальная согласованность операций чтения между географически распределенными ДЦ, т.о. данные, которые возвращают операции чтения из разных ДЦ, всегда согласованны и непротиворечивы.
Кроме того Spanner обладает возможностями, больше свойственными для СУБД, такими как:
- неблокирующее чтение данных «из прошлого» (in past);
- отсутствие блокировок для read-only транзакций;
- атомарное изменение схемы таблиц данных;
- синхронная репликация;
- автоматическая обработка отказов как вычислительных узлов, так и ДЦ;
- автоматическая миграция данных как между вычислительными узлами, так и между ДЦ.
Архитектура
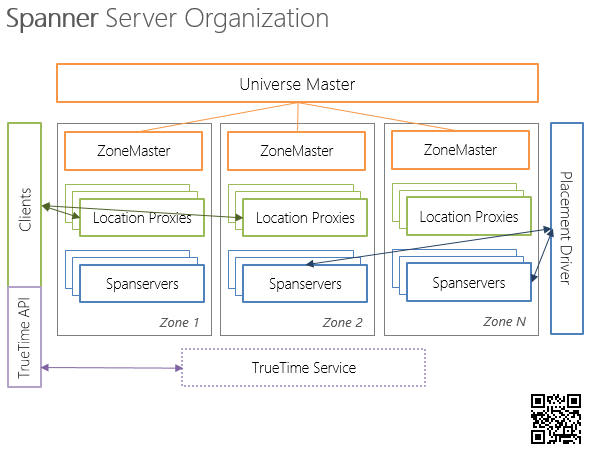
Каждый развернутый экземпляр (deployment) Spanner именуется Universe и содержит в себе:
- Universe master – мастер-процесс, координирующий работу множества зон (в терминологии Spanner — Zone);
- Множество Zone – географически распределенные (в общем случае) зоны Spanner. Zone – это единица как логической изоляции, так и физической.
Каждый из Zone, в свою очередь, содержит в себе:
- ZoneMaster – мастер-процесс зоны (синглтон);
- Множество — от сотни до нескольких тысяч — Spanservers;
- Location proxy – раскрывают клиентам расположение Spanservers, ответственных за необходимые данные;
- Placement driver – процесс (также, как и Zonemaster, синглтон), управляющий перемещением данных между различными Zone.

В research paper [8] подробно описаны функции и внутренне устройство только Spanserver.
Каждый Spanserver содержит в себе от 100 до 1000 структур данных называемых tablet.
(key: string, timestamp: int64) -> string
В отличии от Bigtable, Spanner добавляет к структуре хранимых данных метку времени добавления этих данных, что является важным введением для реализации поддержки мульти-версионности данных.
Модель данных в Spanner – полуреляционные таблицы с поддержкой схем данных (schematized), SQL-подобного языка запросов и распределенных транзакций.
Реализация последних (транзакций) стала возможна благодаря одному из наиболее инновационных нововведений для такого рода программных систем – программного интерфейса TrueTime API.
TrueTime
Обычная задача для систем предоставления глобального времени (в частности атомных часов) – это предоставление максимально точного времени. TrueTime API же предоставляет клиентам глобальное время + некоторую неопределенность – TTinterval.
Это нужно потому, что для распределенных систем очень сложно гарантировать мгновенность отклика узлов, что важно для обеспечения согласованности данных в распределенном хранилище.
При подходе, когда вместо точного времени, возвращается некоторых временной интервал выполнение 2-ух конкурентных транзакций сводится (упрощенно) к сравнению TTinterval этих транзакций. Если TTinterval транзакций не пересекается, то можно однозначно узнать, какая из транзакций должна быть выполнена раньше. Если TTinterval – пересекается, то сказать можно только с определенной степенью вероятности. (Подробнее о аппаратной части сервиса TrueTime.)
В самом же Spanner согласованность данных при проведении транзакций обеспечивается протоколом двухфазной фиксации транзакции (2-Phase Commit Protocol), реализованным с помощью алгоритма Paxos.
Ограничения и CAP
На момент публикации research paper [8] Spanner не поддерживал вторичные индексы и автоматический resharding для целей балансировки нагрузки. Кроме того, авторы [8] отмечают, что Spanner не способен эффективно исполнять сложные SQL-запросы.
Spanner также не является «опровержением» CAP-теоремы. Spanner не является AP-системой, несмотря на свою NoSQL-природу; как и не является CA-системой, несмотря на
Итоги
Spanner взял лучшие идеи двух миров — реляционных СУБД и NoSQL – и представляет из себя СУБД поколения NewSQL.
Поддержка распределенных транзакций между дата-центрами на объеме данных, идущим на петабайты, с такой способностью к масштабированию – безусловно крайне впечатляющее свойство для любой системы хранения структурированных и полуструктурированных данных. Данная возможность во многом стала следствием симбиоза двух подходов: подхода к хранению данных – данные иммутабельны и содержат метку времени коммита – и инновационной концепции получения глобального времени – TrueTime.
Список источников*
[8] James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, et al. Spanner: Google’s Globally-Distributed Database. Proceedings of OSDI, 2012.
* Полный список источников, используемый для подготовки цикла.
Дмитрий Петухов,
MCP,
человек с кофеином вместо эритроцитов.
