От B2C-порталов ожидается прежде всего масштабирование. К сожалению, масштабирование слишком часто объявляется вопросом Технологии — достаточно выбрать модную технологию и все проблемы решены. То, что это не так, может проявиться, позднее всего, уже в production mode (на рабочей системе).
Вместо того, чтобы махать технологической булавой, расскажу о том, как при помощи продуманной архитектуры и сознательного отказа от модели данных разработать высоко доступный (highly available), масштабируемый (scalable) портал. Первая часть опишет общие концепты, а возможные сценарии и их решения последуют.
Давным-давно, в темные времена начала интернета, то есть где-то в конце прошлого — начале этого тысячелетия, вопрос выбора правильной архитектуры часто сводился к выбору правильной базы данных. Когда директор какого-нибудь стартапчика ставил перед разработчиками задачу построить новый портал, команда в основном дискутировала о том, надо ли покупать Oracle Enterprise Edition, или можно обойтись стандартной лицензией. Продвинутые товарищи экспериментировали с Роеt, Versant или другими объектно-ориентированными базами данных. После этого создавались модели данных, которые в большинстве случаев были моделями баз данных, и всё это еще до того, как задаться вопросом: а что, собственно, система должна делать, и как?
Сегодня, 10 лет и кучу интересных разработок в области ПО спустя, всё происходит очень похоже, разве что вместо выбора Oracle или Informix спорят о том, брать ли Mongo, Hadoop или ElasticSearch. Без сомнения, это хорошие и очень полезные технологии. Однако выбор технологии не должен предшествовать выбору архитектуры! Другими словами: технология, какой бы продвинутой она не была, должна служить архитектуре, выполняя определённые задачи в ее рамках. Эти задачи должны определятся архитектурой и требованиями к системе.
Подход Technology First, который можно часто встретить в окопах разработки ПО, очень привлекателен для руководства, плохо подкованного технически: «Если стартап Х использует Mongo, Bootstrap, ElasticSearch и/или Ruby, то и мне этот коктейль поможет, а если нет, то я всегда отмажусь перед инвесторами: мол, использовал все самые модные технологии и значит — не виноват!» К сожалению (для судьбы стартапа и к счастью для всех остальных), такой подход редко приводит к правильному решению конкретной проблемы.
Я же ратую за противоположный подход: Architecture First. Это означает, что проблема решается в первую очередь архитектурно, а технология является лишь способом реализации архитектуры. Соответственно, технология — только часть решения и только тогда, когда она приносит конкретную пользу в контексте данного решения.
Вот пример.
Долгие годы люди пытались решить все проблемы порталостроения при помощи реляционных СУБД, и долгие же годы все попытки масштабирования этих порталов венчались прахом, как только Schema (Схема БД) становилась достаточно сложной. В результате этой беды и появилось поколение наследников РСУБД — NoSQL СУБД (являются ли базы NoSQL чем-то принципиально новым или лишь реанимацией старых идей, в данном контексте не суть важно). Интересно другое: успех NoSQL СУБД основан на том, что они распознали главную проблему SQL СУБД, — а именно Joins, и попросту их не поддерживают. Но если построить архитектуру так, чтобы обойтись без Joins, то есть сознательно от них отказаться, то и старые добрые базы SQL масштабируются без особых проблем.
Прежде чем говорить о том, как найти правильную архитектуру, которая будет поддерживать такие стандартные требования как flexibility (гибкость), scalability (масштабируемость) и manageability (управляемость), нужно определиться: а что, собственно, является архитектурой? Тут мнения расходятся. Одни рассматривают архитектуру как очень абстрактный вид описаний требований к системе, эдакий requirement analysis; другие — как распределение классов по пакетам (packages). Большой выбор разнообразных определений понятия «архитектура программного обеспечения» можно найти на этой странице.
Я считаю наиболее удачным следующее:
Иными словами, архитектура занимается компонентами системы и коммуникацией между ними. Это определение основывается на понятии компонент, а что же такое компонент?
Компоненты — это составляющие нашей архитектурной мысли, которые мы определяем по различным признакам: в частности, я — по ответственности за какой-либо бизнес процесс или данные.
Отдельный компонент — совокупность сущностей (например классов/объектов), выполняющих общую задачу. Например, MessagingService — компонент, отвечающий за отправку сообщений и состоящий из нескольких классов (в том числе и самого MessagingService interface).
Размер компонента должен быть максимально маленьким, но достаточным, чтобы решить задачу (для Messaging — отправка и прием сообщений).
Возвращаясь к B2C порталам, отметим их общие, с точки зрения архитектуры, свойства:
Одна из самых популярных архитектур для построения таких порталов — сервисно-ориентированная (SOA). В недалеком прошлом её реноме пострадало от популярности WebServices, архитектуры, с SOA имеющей мало общего, но которую часто с ней путают. SOA, будучи архитектурой гораздо старшей и более зрелой, чем WebServices, при правильном использовании предлагает решение многих проблем масштабирования.
С архитектурной точки зрения, компоненты в SOA — это сервисы и клиенты, причем каждый компонент может быть тем и другим одновременно. Внешне видимые свойства компонента — это интерфейсы, которые он публикует. Что касается отношений между компонентами, то их два вида:
Прямая коммуникация похожа на телефонный звонок в службу заказа такси или пиццы, косвенная сравнима с бегущей строкой на биржевом табло, которая появляется независимо от того, читает её кто-то или нет. Опрашиваемые методы, так же, как и прослушиваемые данные, являются интерфейсами с точки зрения архитектуры, то есть средствами коммуникации с компонентом.
Один из основных и наиболее полезных принципов SOA: изоляция компонентов друг от друга. Помимо прочего, это означает, что каждый компонент является абсолютным хозяином своих данных. Никто не имеет права их изменять, не поставив, как минимум, хозяина в известность, а лучше — попросив его сделать модификацию самому.
Сервисно-ориентированная архитектура умеет много гитик, но основное её преимущество — в отсутствии глобальной модели данных. Интерфейсы каждого конкретного компонента — это всё, что о нём известно «снаружи». Внутренняя же его жизнь остаётся делом сугубо личным, никому не ведомым. У этого принципа есть не только сторонники — ведь провести сложное расследование при помощи одного (трехэтажного) SQL запроса так удобно! Да, это правда, связь между данными разных сервисов на уровне СУБД могла бы принести определенную пользу при расследовании, статистическом анализе и дата майнинге (data mining, глубинном, или интеллектуальном анализе данных). Но где сказано, что эти связи должны существовать в рабочей среде? Если кому-то нужны данные для анализа, никто не мешает регулярно переносить их из рабочей системы в аналитическую, и при этом создавать сколько угодно и какие угодно связи, а также переворачивать данные боком, вверх головой или как еще понравится. Но сама рабочая система не должна быть загрязнена этими «субпродуктами» — балластом, делающим из юркого, быстрого «Феррари» грузный и неповоротливый «Пассат».
Добровольный отказ от глобальной модели данных с точки зрения архитектуры системы означает следующее:
Чтобы в полноте насладиться преимуществами SOA, сервисы должны быть грамотно «нарезаны». Большие, монстроподобные сервисы часто превращаются в «приложениe в приложении», и сами подвержены тем проблемам, которые мы собирались побороть. Слишком мелконарезанные сервисы приводят к переизбытку (overhead) коммуникации, которая убивает всё масштабирование в корне. Как же найти правильный размер сервиса?
Проще всего это сделать, придерживаясь двух следующих парадигм разработки ПО: Design by Responsibility и Layer Isolation. С помощью последнего можно определить основополагающие границы ответственности сервисов — что является сервисом (как business logic), а что нет (например, презентационная логика). Design by Responsibility помогает нарезать сервисы по вертикали, разбивая их по предметной или функциональной специализации (messaging, search и т.д.).
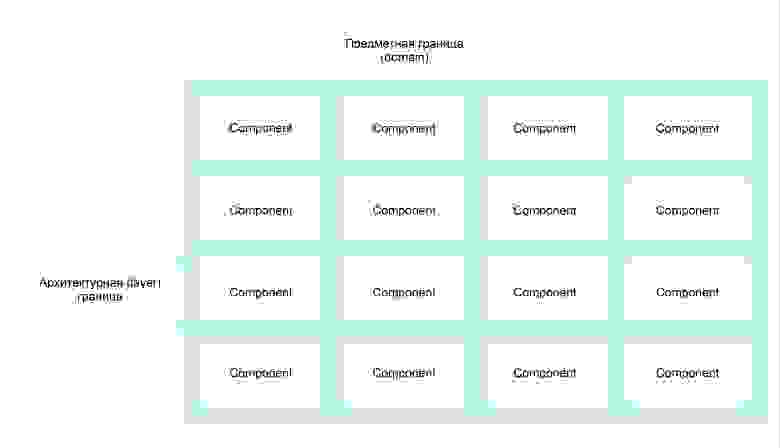
Схема 1: Правильная нарезка сервисов
После корректной идентификации сервисов нужно подумать о том, как они должны между собой «общаться».
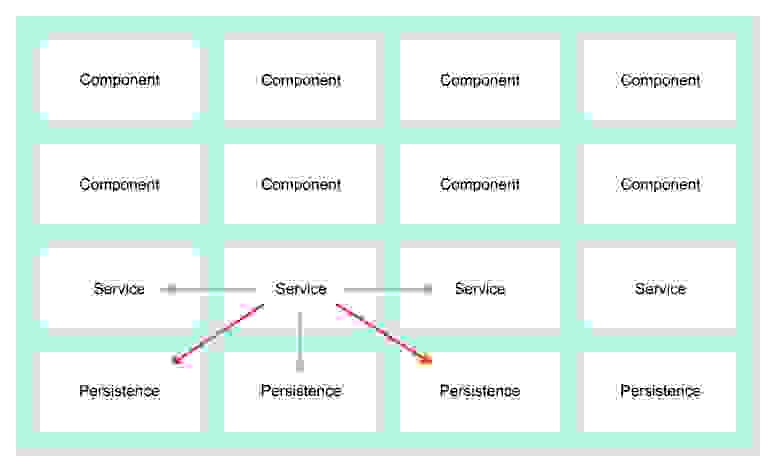
Схема 2: Разрешенные (зеленые) и запрещенные (красные) пути коммуникации
Общепринятая модель слоев — вертикальная. Наверху находится презентационный слой, внизу — персистентный. Поэтому разработчики обычно начинают с персистентости и создают глобальную модель данных. На самом же деле, в SOA надо начинать с середины:
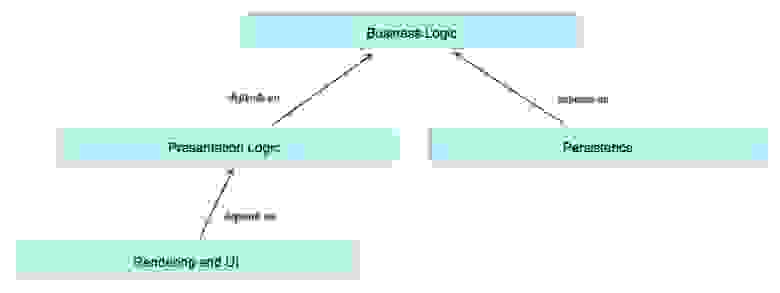
Схема 3: Зависимости между слоями
Таким образом, мы сможем создать настоящую сервисную модель, в которой каждая конкретная персистентность удовлетворяет потребности своего сервиса, и только его. Это приводит к строгой изоляции, необходимой для масштабирования:
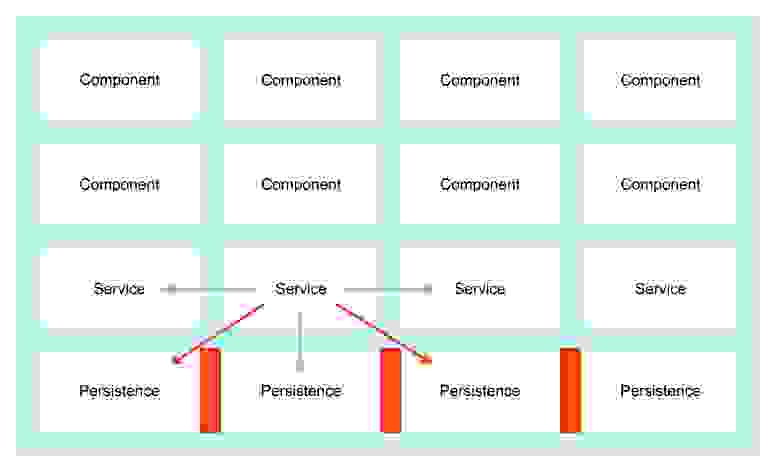
Схема 4: Изоляция персистентностей
Другая парадигма, следование которой абсолютно необходимо — это KISS (Keep it Simple, Stupid). Касательно архитектуры ПО, KISS означает, что лишь абсолютно необходимые компоненты должны быть частью нашей архитектуры. Всё, что не приносит непосредственной пользы, и к этому могут относиться модные технологии, должно быть исключено. Другими словами, лишь те технологии, которые оправдывают расходы на свою поддержку, заслуживают право входить в конечное решение.
Но вот, наконец, настал тот час, когда сервисы спроектированы и написаны, и пора бросаться грудью на амбразуру — то есть под реальную нагрузку реальных пользователей. До запуска мы часто не знаем, какую нагрузку выдержит тот или иной компонент. Конечно, хорошо иметь реалистичный нагрузочный тест. Проблема в том, что для написания хорошего теста нам нужно знать реальное поведение пользователей, а чтобы узнать реальное поведение пользователей, нам надо… запуститься.
Тем не менее, совсем не страшно заниматься тюнингом уже после запуска в рабочем режиме, ведь все мы хорошо помним, что такое преждевременная оптимизация (premature optimization). Важно мониторить (Привет MoSKito!) каждый компонент, чтобы вовремя распознавать «узкие места» и реагировать до полной перегрузки этого компонента. Зная такое «узкое место», у нас есть разные возможности реагирования. О двух из них, Кэшах и Маршрутизации, мы поговорим в следующих частях.
Вместо того, чтобы махать технологической булавой, расскажу о том, как при помощи продуманной архитектуры и сознательного отказа от модели данных разработать высоко доступный (highly available), масштабируемый (scalable) портал. Первая часть опишет общие концепты, а возможные сценарии и их решения последуют.
Часть первая. Теория.
Давным-давно, в темные времена начала интернета, то есть где-то в конце прошлого — начале этого тысячелетия, вопрос выбора правильной архитектуры часто сводился к выбору правильной базы данных. Когда директор какого-нибудь стартапчика ставил перед разработчиками задачу построить новый портал, команда в основном дискутировала о том, надо ли покупать Oracle Enterprise Edition, или можно обойтись стандартной лицензией. Продвинутые товарищи экспериментировали с Роеt, Versant или другими объектно-ориентированными базами данных. После этого создавались модели данных, которые в большинстве случаев были моделями баз данных, и всё это еще до того, как задаться вопросом: а что, собственно, система должна делать, и как?
Сегодня, 10 лет и кучу интересных разработок в области ПО спустя, всё происходит очень похоже, разве что вместо выбора Oracle или Informix спорят о том, брать ли Mongo, Hadoop или ElasticSearch. Без сомнения, это хорошие и очень полезные технологии. Однако выбор технологии не должен предшествовать выбору архитектуры! Другими словами: технология, какой бы продвинутой она не была, должна служить архитектуре, выполняя определённые задачи в ее рамках. Эти задачи должны определятся архитектурой и требованиями к системе.
Подход Technology First, который можно часто встретить в окопах разработки ПО, очень привлекателен для руководства, плохо подкованного технически: «Если стартап Х использует Mongo, Bootstrap, ElasticSearch и/или Ruby, то и мне этот коктейль поможет, а если нет, то я всегда отмажусь перед инвесторами: мол, использовал все самые модные технологии и значит — не виноват!» К сожалению (для судьбы стартапа и к счастью для всех остальных), такой подход редко приводит к правильному решению конкретной проблемы.
Я же ратую за противоположный подход: Architecture First. Это означает, что проблема решается в первую очередь архитектурно, а технология является лишь способом реализации архитектуры. Соответственно, технология — только часть решения и только тогда, когда она приносит конкретную пользу в контексте данного решения.
Вот пример.
Долгие годы люди пытались решить все проблемы порталостроения при помощи реляционных СУБД, и долгие же годы все попытки масштабирования этих порталов венчались прахом, как только Schema (Схема БД) становилась достаточно сложной. В результате этой беды и появилось поколение наследников РСУБД — NoSQL СУБД (являются ли базы NoSQL чем-то принципиально новым или лишь реанимацией старых идей, в данном контексте не суть важно). Интересно другое: успех NoSQL СУБД основан на том, что они распознали главную проблему SQL СУБД, — а именно Joins, и попросту их не поддерживают. Но если построить архитектуру так, чтобы обойтись без Joins, то есть сознательно от них отказаться, то и старые добрые базы SQL масштабируются без особых проблем.
Архитектура — что это?
Прежде чем говорить о том, как найти правильную архитектуру, которая будет поддерживать такие стандартные требования как flexibility (гибкость), scalability (масштабируемость) и manageability (управляемость), нужно определиться: а что, собственно, является архитектурой? Тут мнения расходятся. Одни рассматривают архитектуру как очень абстрактный вид описаний требований к системе, эдакий requirement analysis; другие — как распределение классов по пакетам (packages). Большой выбор разнообразных определений понятия «архитектура программного обеспечения» можно найти на этой странице.
Я считаю наиболее удачным следующее:
Архитектурой (программного обеспечения) является структура системы, состоящая из компонентов, видимых свойств этих компонентов и отношений между ними.
Иными словами, архитектура занимается компонентами системы и коммуникацией между ними. Это определение основывается на понятии компонент, а что же такое компонент?
Компоненты — это составляющие нашей архитектурной мысли, которые мы определяем по различным признакам: в частности, я — по ответственности за какой-либо бизнес процесс или данные.
Отдельный компонент — совокупность сущностей (например классов/объектов), выполняющих общую задачу. Например, MessagingService — компонент, отвечающий за отправку сообщений и состоящий из нескольких классов (в том числе и самого MessagingService interface).
Размер компонента должен быть максимально маленьким, но достаточным, чтобы решить задачу (для Messaging — отправка и прием сообщений).
Возвращаясь к B2C порталам, отметим их общие, с точки зрения архитектуры, свойства:
- высокий коэффициент соотношения между читающими и пишущими операциями: количество читающих может быть в 9-10 раз выше, чем пишущих;
- четко отличаемые функционалы — например, внутренние сообщения (messaging) или профиль;
- посещаемость порталов подвержена пикам, которые создают множественное число от нормальной загрузки в зависимости от времени дня, недели или года;
- порталы постоянно и быстро меняются. Это касается и кода, и контента, и данных.
Общие архитектурные принципы
Одна из самых популярных архитектур для построения таких порталов — сервисно-ориентированная (SOA). В недалеком прошлом её реноме пострадало от популярности WebServices, архитектуры, с SOA имеющей мало общего, но которую часто с ней путают. SOA, будучи архитектурой гораздо старшей и более зрелой, чем WebServices, при правильном использовании предлагает решение многих проблем масштабирования.
С архитектурной точки зрения, компоненты в SOA — это сервисы и клиенты, причем каждый компонент может быть тем и другим одновременно. Внешне видимые свойства компонента — это интерфейсы, которые он публикует. Что касается отношений между компонентами, то их два вида:
- Прямая или синхронная коммуникация — вызов методов, то есть обращение клиента к сервису.
- Косвенная, или асинхронная коммуникация — оповещение об изменении состояния (event), которое компонент публикует «по секрету всему свету», не заботясь о том, есть ли у него конкретные слушатели.
Прямая коммуникация похожа на телефонный звонок в службу заказа такси или пиццы, косвенная сравнима с бегущей строкой на биржевом табло, которая появляется независимо от того, читает её кто-то или нет. Опрашиваемые методы, так же, как и прослушиваемые данные, являются интерфейсами с точки зрения архитектуры, то есть средствами коммуникации с компонентом.
Изоляция до мозга костей (до базы данных)
Один из основных и наиболее полезных принципов SOA: изоляция компонентов друг от друга. Помимо прочего, это означает, что каждый компонент является абсолютным хозяином своих данных. Никто не имеет права их изменять, не поставив, как минимум, хозяина в известность, а лучше — попросив его сделать модификацию самому.
Сервисно-ориентированная архитектура умеет много гитик, но основное её преимущество — в отсутствии глобальной модели данных. Интерфейсы каждого конкретного компонента — это всё, что о нём известно «снаружи». Внутренняя же его жизнь остаётся делом сугубо личным, никому не ведомым. У этого принципа есть не только сторонники — ведь провести сложное расследование при помощи одного (трехэтажного) SQL запроса так удобно! Да, это правда, связь между данными разных сервисов на уровне СУБД могла бы принести определенную пользу при расследовании, статистическом анализе и дата майнинге (data mining, глубинном, или интеллектуальном анализе данных). Но где сказано, что эти связи должны существовать в рабочей среде? Если кому-то нужны данные для анализа, никто не мешает регулярно переносить их из рабочей системы в аналитическую, и при этом создавать сколько угодно и какие угодно связи, а также переворачивать данные боком, вверх головой или как еще понравится. Но сама рабочая система не должна быть загрязнена этими «субпродуктами» — балластом, делающим из юркого, быстрого «Феррари» грузный и неповоротливый «Пассат».
Добровольный отказ от глобальной модели данных с точки зрения архитектуры системы означает следующее:
- Место модели данных занимает модель сервисов. Её можно было бы назвать Enterprise-моделью, если бы это слово не использовалось направо и налево, для чего придётся. Сервисная модель состоит из сервисов в системе, артефактов, которыми они управляют, и связей между этими артефактами.
- Каждый сервис и каждый компонент совершенно свободны в выборе их персистентности. Сервис, который управляет хорошо структурированными данными, может записывать их в базу данных SQL; сервис, занимающийся блобами (blobs), будь то картинки или большие тексты, может использовать более подходящие методы персистентности.
- Нагрузка на сервисы варьируется в пределах системы. В 2-tier (двухуровневой) системе, ориентированной на базы данных, рост нагрузки всегда ложится на всю систему целиком. В SOA же легко идентифицировать сервис, нагрузка на который выросла, что даёт возможность бороться с ней именно в этом месте, путем оптимизации или масштабирования.
Чтобы в полноте насладиться преимуществами SOA, сервисы должны быть грамотно «нарезаны». Большие, монстроподобные сервисы часто превращаются в «приложениe в приложении», и сами подвержены тем проблемам, которые мы собирались побороть. Слишком мелконарезанные сервисы приводят к переизбытку (overhead) коммуникации, которая убивает всё масштабирование в корне. Как же найти правильный размер сервиса?
Проще всего это сделать, придерживаясь двух следующих парадигм разработки ПО: Design by Responsibility и Layer Isolation. С помощью последнего можно определить основополагающие границы ответственности сервисов — что является сервисом (как business logic), а что нет (например, презентационная логика). Design by Responsibility помогает нарезать сервисы по вертикали, разбивая их по предметной или функциональной специализации (messaging, search и т.д.).
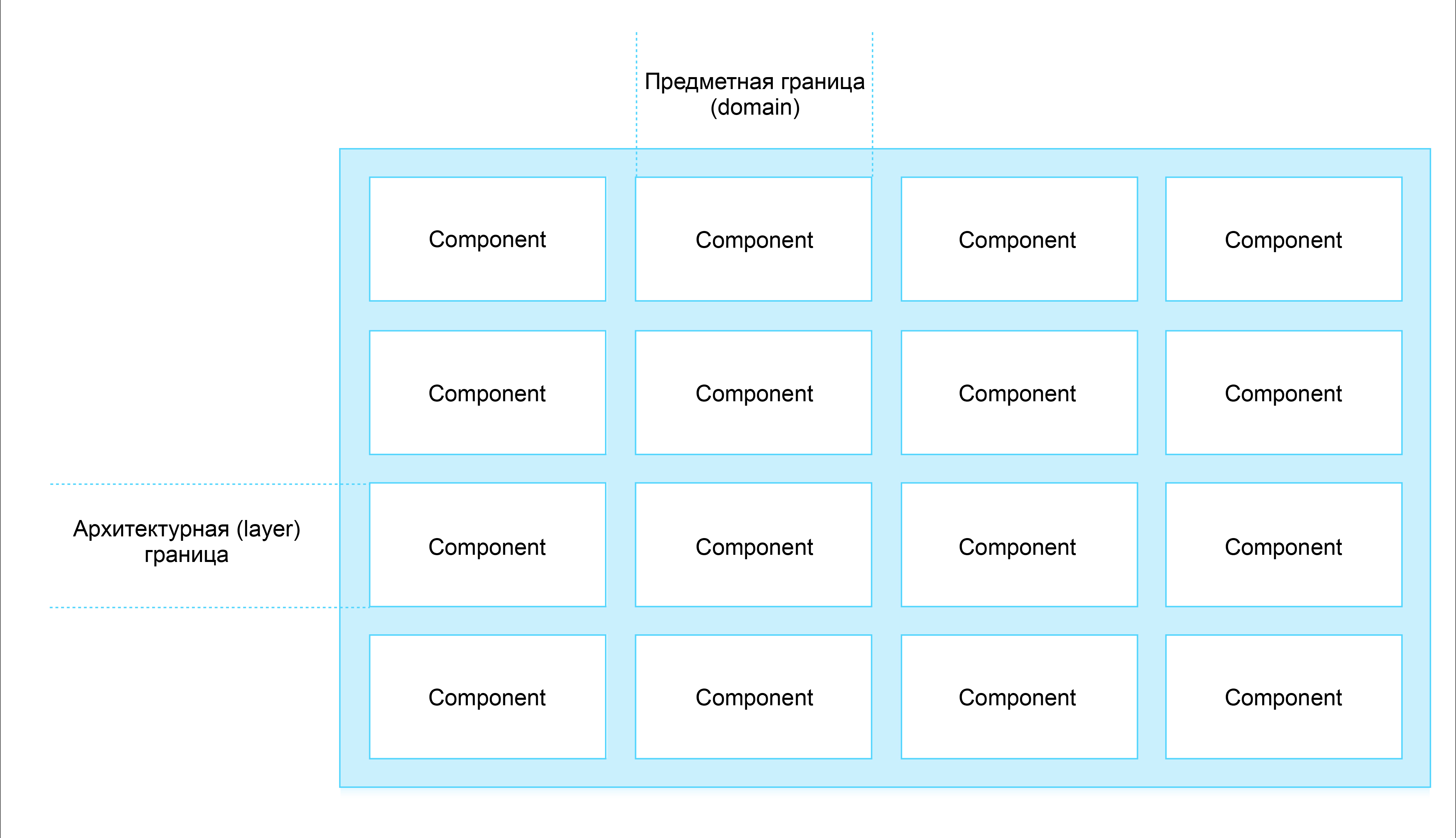
Схема 1: Правильная нарезка сервисов
После корректной идентификации сервисов нужно подумать о том, как они должны между собой «общаться».
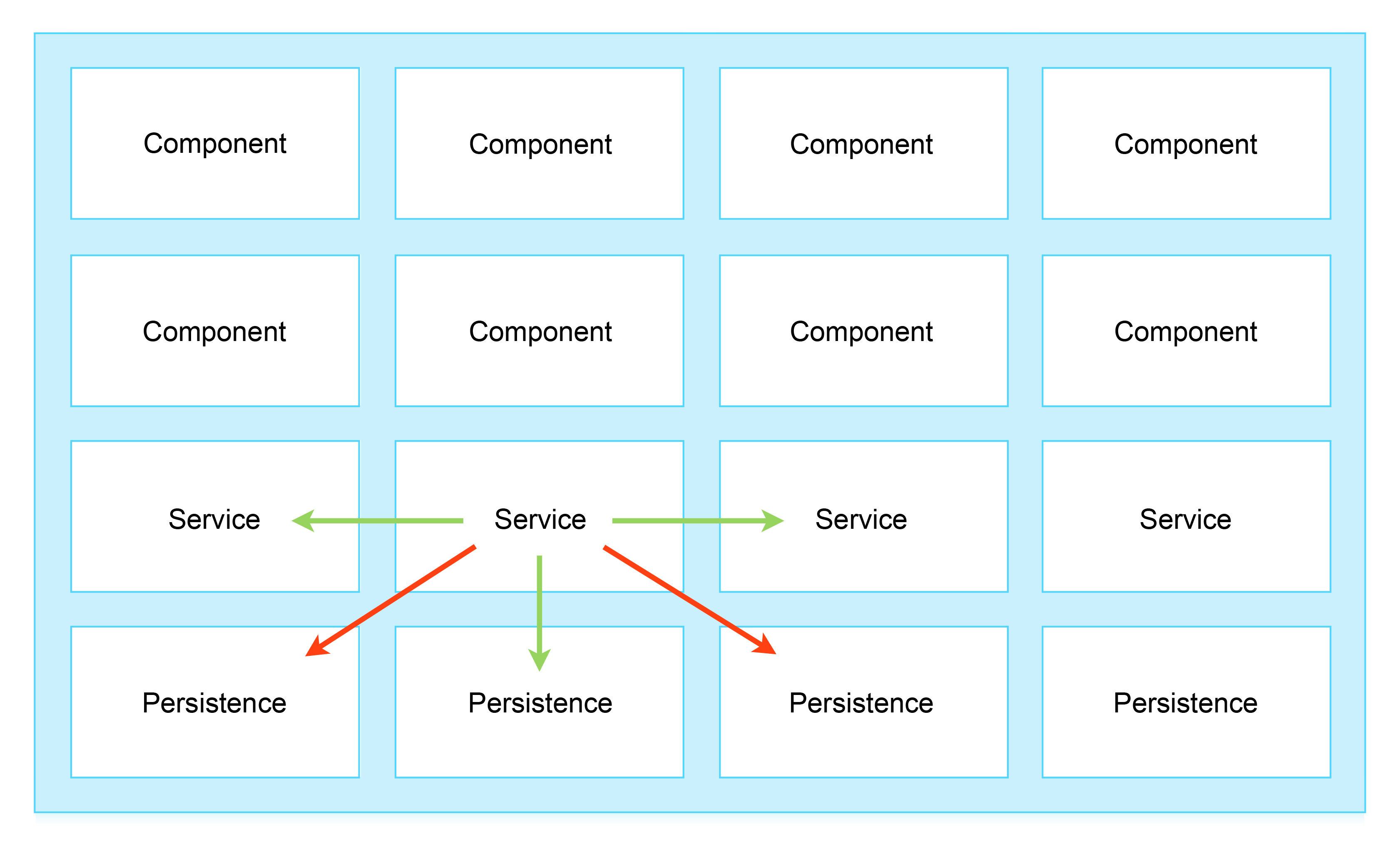
Схема 2: Разрешенные (зеленые) и запрещенные (красные) пути коммуникации
Как избежать глобальной модели данных?
Общепринятая модель слоев — вертикальная. Наверху находится презентационный слой, внизу — персистентный. Поэтому разработчики обычно начинают с персистентости и создают глобальную модель данных. На самом же деле, в SOA надо начинать с середины:
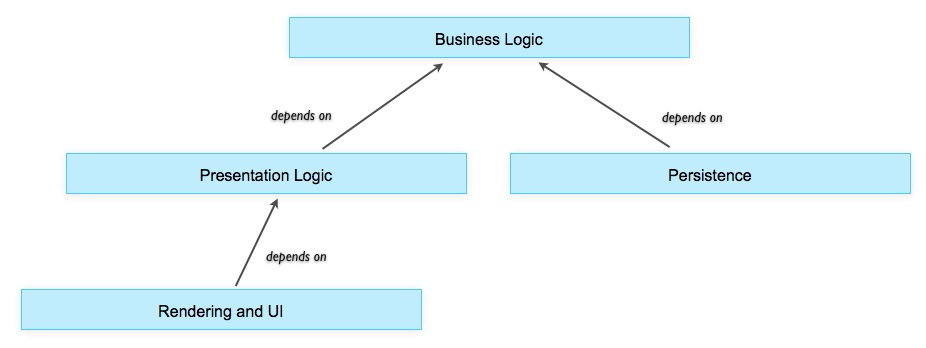
Схема 3: Зависимости между слоями
Таким образом, мы сможем создать настоящую сервисную модель, в которой каждая конкретная персистентность удовлетворяет потребности своего сервиса, и только его. Это приводит к строгой изоляции, необходимой для масштабирования:
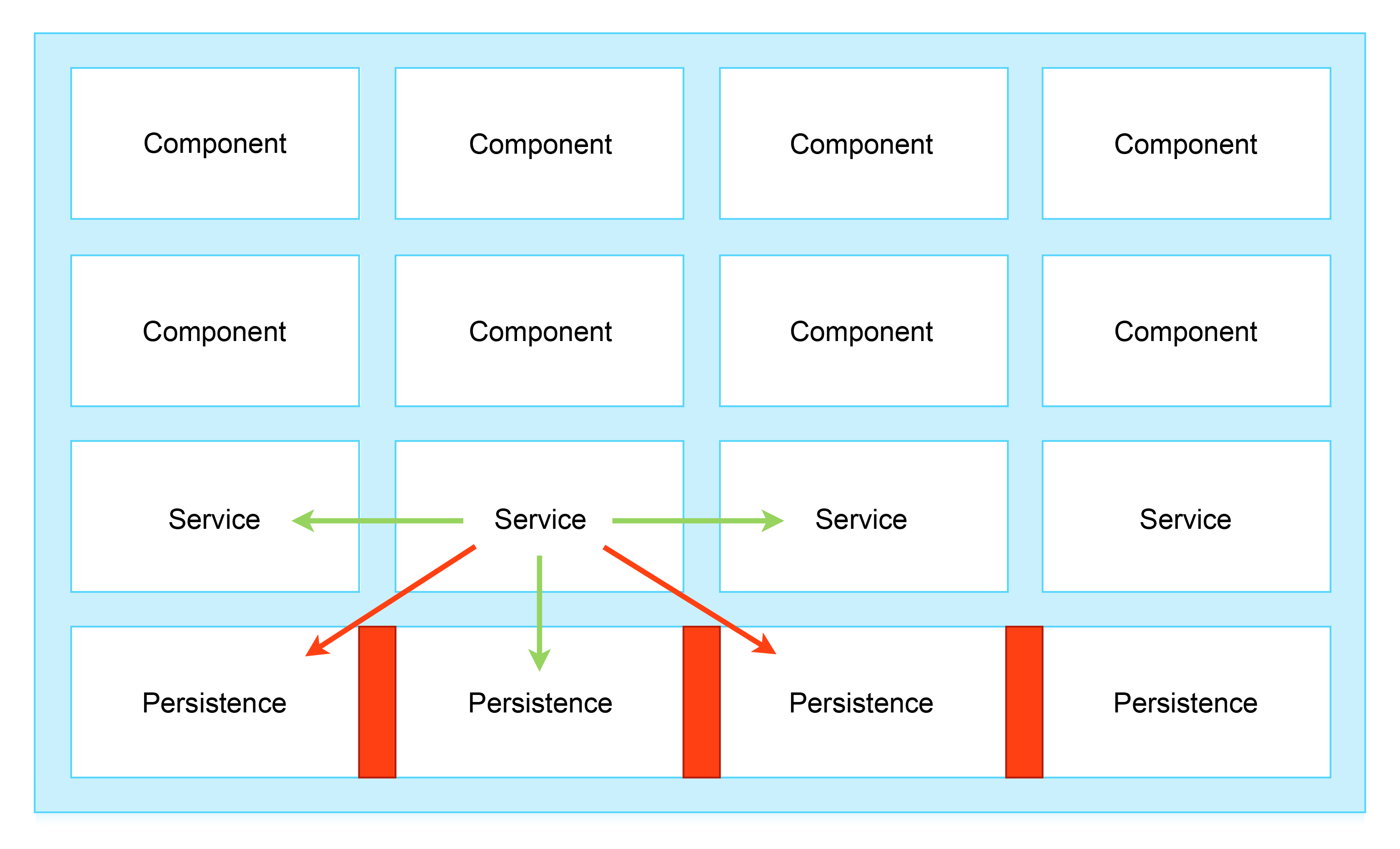
Схема 4: Изоляция персистентностей
Другая парадигма, следование которой абсолютно необходимо — это KISS (Keep it Simple, Stupid). Касательно архитектуры ПО, KISS означает, что лишь абсолютно необходимые компоненты должны быть частью нашей архитектуры. Всё, что не приносит непосредственной пользы, и к этому могут относиться модные технологии, должно быть исключено. Другими словами, лишь те технологии, которые оправдывают расходы на свою поддержку, заслуживают право входить в конечное решение.
В хорошей архитектуре много винтиков
Но вот, наконец, настал тот час, когда сервисы спроектированы и написаны, и пора бросаться грудью на амбразуру — то есть под реальную нагрузку реальных пользователей. До запуска мы часто не знаем, какую нагрузку выдержит тот или иной компонент. Конечно, хорошо иметь реалистичный нагрузочный тест. Проблема в том, что для написания хорошего теста нам нужно знать реальное поведение пользователей, а чтобы узнать реальное поведение пользователей, нам надо… запуститься.
Тем не менее, совсем не страшно заниматься тюнингом уже после запуска в рабочем режиме, ведь все мы хорошо помним, что такое преждевременная оптимизация (premature optimization). Важно мониторить (Привет MoSKito!) каждый компонент, чтобы вовремя распознавать «узкие места» и реагировать до полной перегрузки этого компонента. Зная такое «узкое место», у нас есть разные возможности реагирования. О двух из них, Кэшах и Маршрутизации, мы поговорим в следующих частях.
