Направленное движение внимания — как основная функция сознания
В этой статье мы не будем вдаваться в глобальные проблемы сильного искусственного интеллекта, но лишь продемонстрируем некоторые основы нашего подхода к его проектированию.
Рассмотрим, пожалуй, одну из самых известных иллюстраций к тому, как работает зрение, исследуя зрительные объекты

Мы видим, что зрительное внимание подвижно.
А что если, само движение внимания и есть ключ к его пониманию?
Мы выдвинули гипотезу о том, что сознание направляет движение внимания, и представили себе следующий образ алгоритма сознательного зрительного восприятия

Как мог бы работать такой алгоритм?
Важные понятия
Мы ввели определения двух понятий для нашего алгоритма: признак и обобщение.
Что такое признак, проще всего проиллюстрировать вышеприведенным изображением дамы с кошкой.
Возьмем какую-либо область изображения и посчитаем ее интегральные характеристики, например, размер области (в случае круга это будет ее диаметр), среднюю цветность, яркость, контрастность и фрактальную размерность.
Теперь в некотором направлении и на некотором расстоянии выберем другую область изображения и посчитаем ее интегральные характеристики.
Теперь посчитаем относительные изменения перехода из первой области во вторую, чтобы избавиться от абсолютных значений и не зависеть от изменений масштаба, поворота, сдвига, общей освещенности или тональности изображения. Обычные аффинные преобразования при этом так же позволяют избавиться от изменения перспективы плоскости изображения.
Такой переход мы и назовем признаком.

Далее, связывая такие признаки в цепочки мы будем получать обобщения признаков.
Вот такое, несколько вольное, но определение ключевых понятий предлагаемого подхода.
Я хочу, чтобы картинка ожила!
Хорошо, но пока здесь нет направленного движения внимания. Если мы случайным образом будем формировать такие цепочки из переходов, наша база данных будет безмерной и отличить в ней что-то полезное от хлама будет решительно невозможно.
Поэтому мы определяем еще несколько понятий.
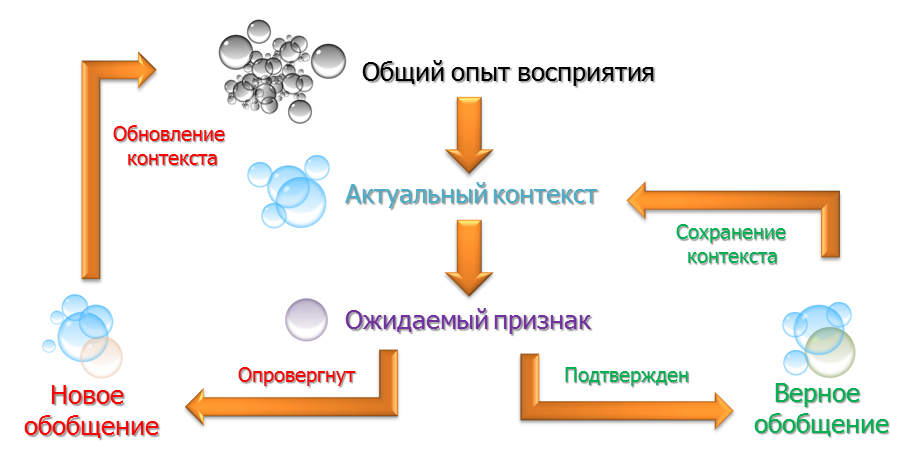
Ключевое понятие — это опыт. Совокупность ранжированных по значимости (частоте подтверждений) обобщений.
При этом, каждый раз в окрестности текущего направления внимания мы определяем актуальный контекст обобщений — тех, что бы уже подтверждены и все еще не опровергнуты.
Этот актуальный контекст обобщений так же ранжирован по вероятности наиболее ожидаемых признаков в потоке.
Центральным элементом алгоритма является текущий ожидаемый признак, который мы можем проверить. Переход из текущей области (фокуса внимания) в область задаваемую ожидаемым переходом направляет систему к расчету характеристик в определенной области и сравнению их с ожидаемыми.
Если признак подтверждается, мы получаем из актуального контекста следующий ожидаемый признак.
Если признак не подтверждается, мы формируем новое обобщение и убираем из актуального контекста обобщения, которые не подтвердились.
Что делать, если контекст пуст или полностью подтвержден и нет новых ожидаемых признаков?
Мы предполагаем, что естественное сознание в данной ситуации исследует окрестности того, что уже известно, но еще мало исследовано. То есть внимание переключается к тому, что регулярно оказывается в актуальном контексте, но уровень обобщения невысок (т.е. цепочки обобщений довольно коротки)
Ну теперь-то мы приехали?
Пока очень рано делать выводы о практической полезности предлагаемого подхода. Исследования только в самом начале.
Первые эксперименты показали, что реализация алгоритма «в лоб», без особых оптимизаций, на C#, в одном потоке на одном ядре генерирует порядка 50 тысяч обобщений в секунду, при этом на миллион сгенерированных обобщений повторяются хотя бы раз меньше 1%, а подтверждаются более одного раза около 0.2%
Довольно много вычислений выполняется «на всякий случай» и значительный объем базы занят еще неподтвержденными обобщения самых коротких цепочек из двух переходов (признаков).
В ближайших планах формирование аттракторов поведения системы (движения внимания ИИ) на обучающих выборках, изучение их параметров и публикация результатов.
