Функциональность LINQ запросов в C# переписана на PHP. Изначально библиотека задумывалась как тренинг, так как подобные библиотеки уже существуют, но потом было решено её опубликовать для всех. Скопировать LINQ на PHP один в один невозможно, поскольку возможности языков C# и PHP очень разные. Отличительной возможностью предлагаемого решения является ориентация на итераторы, ленивые лямбда выражения и сигнатура LINQ методов, идентичная C# на сколько это возможно. Все стандартные LINQ методы, естественно, реализованы. Описание возможностей проекта с объяснением причин, почему именно такое решение было выбрано, под катом.
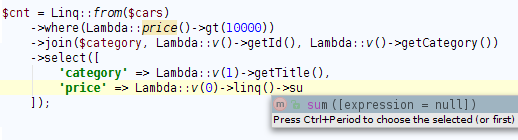
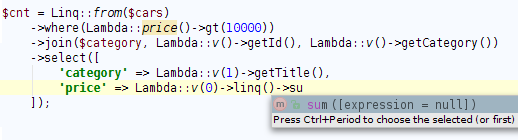
В C# поддержка такого синтаксиса встроена на уровне языка, хотя на самом деле это синтаксический сахар, который преобразуется к следующему виду
Здесь функции
Перед началом работы специально сильно не искал другие решения, чтобы писать под впечатлением от C#, а не от чужих реализаций. Первый вариант был написан за пару-тройку вечеров. Потом долго переносил все стандартные методы из MSDN, выпиливал лишнюю функциональность, приводя логику в соответствие с .NET. В начале года сравнил возможности в другими проектами, переработал код, опубликовал проект на github. При разработке основной упор делался на следующие моменты.
Вместо сложных циклов, копирования из массива в массив, библиотека работает с итераторами. До версии PHP 5.5, чтобы обработать итератор, надо было писать класс, реализующий интерфейс
При чтении данных из текущего итератора, данные начинают вытягиваться и обрабатываться из родительских итераторов. Накладные расходы на работу итераторов вроде бы минимальны. Реализовано более 15 итераторов для типичных задач по обработке последовательностей.
Если в качестве выражения в LINQ методах передавать анонимные функции, то это дает наибольшую скорость исполнения, красивую подсветку и возможность рефакторинга в IDE, но теряется информация о структуре выражения. Это не позволяет реконструировать выражение в другом языке программирования, допустим, SQL. В отличие от лямбда-выражений. Чтобы решить эту проблему, многие авторы в качестве «выражения» передают строку валидного PHP кода. Строка вычисляется с помощью eval для каждого элемента последовательности и есть вероятность, что она может быть переформатирована в другой язык, допустим, SQL. Некоторые придумывают свой формат строки, например
В предлагаемой библиотеке создан инструмент, позволяющий легко строить сложные выражения. Информация о структуре выражения при этом не теряется и может быть в последствии использована повторно. Основой служит класс
Поддерживаются приоритеты операций и скобки. Класс
Все LINQ методы взяты из стандартного .NET 4.5 и раскиданы по соответствующим интерфейсам (
Каждый LINQ метод создает объект класса
Весь код документирован, аннотирован, покрыт тестами и опубликован на github под лицензией BSD (modified). Это полностью рабочая библиотека.
Почему LINQ?
Новые технологии это всегда интересно. Почему они возникли, какие проблемы решают, как решают? Одной из таких фишек является LINQ (Language Integrated Query), SQL подобный язык запросов к последовательностям данных (массивы, ответы баз данных, коллекции). Например,var q = from c in db.Customers
where c.Activity == 1
select new { c.CompanyName, c.ItemID, c.ItemName };
В C# поддержка такого синтаксиса встроена на уровне языка, хотя на самом деле это синтаксический сахар, который преобразуется к следующему виду
var q = db.Customers.
Where((c) => c.Activity == 1).
Select((c) => { c.CompanyName, c.ItemID, c.ItemName });
Здесь функции
Where и Select определены над последовательностями данных, но логика обработки задана для отдельного элемента. Сделано в духе функционального программирования — все есть функция и результат вычисления функции зависит только от входных параметров. Требование к чистоте функций позволяет априори исключить ошибки из-за побочных эффектов. Есть и другие плюсы:- Так как порядок обработки не важен, то обработку над множеством можно делать параллельно.
- Вместо локального перебора LINQ запросы могут сворачиваться (в т.ч. частично) в обычные SQL запросы к базам данных. Запрос внешне остается тем же.
- Логика обработки отдельного элемента изолирована. Её можно повторно использовать для других коллекций или комбинировать с другими.
Почему нельзя скопировать?
Перечислим каких возможностей C# на первый взгляд не хватает для копирования библиотеки в PHP.- нестрогая типизация. Это скорее преимущество.
- нет перегрузки методов. Это следствие из предыдущего пункта. К примеру, если вам надо сравнить строки, массивы и объекты, то надо писать три разные функции с именами
cmpString,cmpArray,cmpLaptopили ставить if внутри одной большой. Оба решения плохи. В первом случае, информация о типе в имени «засоряет» код, где эти функции используются. Во втором случае, тяжело расширять функционал. - нет расширений классов. Вы не можете написать метод и вызывать его как будто это метод другого класса, то есть нельзя расширять IEnumerable<T>, просто подключая свой namespace. Зато в PHP есть магический метод __call, через который можно вызывать статические методы, реализованные в другом месте. Правда надо модифицировать желаемый класс, а это не всегда возможно. Так же стоит забыть про поддержку в IDE.
- нет генераторов с красивым return yield (php<5.5). С одной стороны это синтаксический сахар. Можно написать функцию, возвращающую
\Iterator, который поnext()будет вызывать анонимную функцию, которая будет вычислять значение следующего элемента и сохранять свое состояние в атрибутах класса. Но размер кода увеличится многократно, а его полезная доля упадет. В версии 5.5 появились генераторы, но надо еще долго ждать, пока эта версия станет популярной. - нет лямбда выражений. Это такие маленькие анонимные функции, функционал которых ограничен, но при этом сохраняется информация о структуре. Её можно использоваться для символьного вычисления функции от функций или для экспорта выражения в другой язык, допустим, SQL. В PHP можно написать анонимную функцию, но у вас не будет информации о её структуре и, соответственно, не будет экспорта в SQL.
- нет перегрузки операторов. Так же не получится красиво сымитировать лямбда выражения, записав что-то вроде
$f = (Exp::x()+1) * 2и перегрузив операции сложения и умножения для класса, возвращаемого методомExp::x(), наследника отClosure.
IEnumerator стало Iterator, IEnumerable стало IteratorAggregate), или то, что в PHP у массивов нет методов, но это все легко решается.Что делать? Что сделано
Перед началом работы специально сильно не искал другие решения, чтобы писать под впечатлением от C#, а не от чужих реализаций. Первый вариант был написан за пару-тройку вечеров. Потом долго переносил все стандартные методы из MSDN, выпиливал лишнюю функциональность, приводя логику в соответствие с .NET. В начале года сравнил возможности в другими проектами, переработал код, опубликовал проект на github. При разработке основной упор делался на следующие моменты.Итераторы есть всё и всё есть итераторы
Вместо сложных циклов, копирования из массива в массив, библиотека работает с итераторами. До версии PHP 5.5, чтобы обработать итератор, надо было писать класс, реализующий интерфейс
\Iterator, и передавать ему в конструктор обрабатываемый \Iterator как входной параметр.$data = new \ArrayIterator([1,2,3]);
$even = new \CallbackFilterIterator($data, function ($item) { return $item % 2 == 0; } );
При чтении данных из текущего итератора, данные начинают вытягиваться и обрабатываться из родительских итераторов. Накладные расходы на работу итераторов вроде бы минимальны. Реализовано более 15 итераторов для типичных задач по обработке последовательностей.
- CallbackFilterIterator — фильтрация элементов
- CallbackIterator — генерация бесконечной последовательности функцией
- DistinctIterator — выдача уникальных элементов
- ExceptIterator, IntersectIterator — вычитание, пересечение двух последовательностей
- GroupingIterator — группировка по ключу
- IndexIterator — упорядочение элементов по ключу
- JoinIterator, OuterJoinIterator — строгое, не строгое связываение двух последовательностей по ключу
- LimitIterator — выдача диапазона последовательности
- ProductIterator — cross-product нескольких итераторов
- ProjectionIterator — проекция элементов (ключей)
- ReverseIterator — инвертирование порядка
- SkipIterator — пропуск элементов пока верно условие
- TakeIterator — выдавача элементов пока верно условие
- LazyIterator — абстрактный класс. Итератор строится при первом чтении элемента
- VariableIterator — родительский итератор может поменяться после открытия итератора
Ленивые вычисления тоже работают
Если в качестве выражения в LINQ методах передавать анонимные функции, то это дает наибольшую скорость исполнения, красивую подсветку и возможность рефакторинга в IDE, но теряется информация о структуре выражения. Это не позволяет реконструировать выражение в другом языке программирования, допустим, SQL. В отличие от лямбда-выражений. Чтобы решить эту проблему, многие авторы в качестве «выражения» передают строку валидного PHP кода. Строка вычисляется с помощью eval для каждого элемента последовательности и есть вероятность, что она может быть переформатирована в другой язык, допустим, SQL. Некоторые придумывают свой формат строки, например
$x ==> $x*$x. В этом случае теряется подсветка кода и рефакторинг в IDE, исполнение долгое, код не кэшируется и не безопасно.В предлагаемой библиотеке создан инструмент, позволяющий легко строить сложные выражения. Информация о структуре выражения при этом не теряется и может быть в последствии использована повторно. Основой служит класс
ExpressionBuilder, который в потоковом режиме создает дерево вычисления и экспортирует его в обратную польскую (постфиксная) запись. Например, так$exp = new ExpressionBuilder();
$exp->add(1);
$exp->add('+',1);
$exp->add(2);
$exp->export(); // [1, 2, 2, '+']
Поддерживаются приоритеты операций и скобки. Класс
Expression пробегает по выгруженному массиву и, если встречает данные, то закидывает их в стек, а если встречает объект типа OperationInterface, то передает управление ему. Объект достает нужное количество аргументов из стека, вычисляет результат и закидывает его обратно в стек. По окончанию в стеке остается одно значение — результат. На более высоком уровне выражения строятся с помощью класса LambdaInstance и его декоратора Lambda. Примеры возможностей.- доступ к аргументам, константы
/* идентичные функции */ $f = Lambda::v(); $f = function ($x) { return $x; }; - математические операции, операции сравнения, логические операции
$f = Lambda::v()->add()->v()->mult(12)->gt(36); $f = function ($x) { return $x + $x*12 > 36; }; - скобки
$f = Lambda::v()->mult()->begin()->c(1)->add()->v()->end(); $f = function ($x) { return $x * (1 + $x); }; - строковые операции
$f = Lambda::v()->like('hallo%'); - генерация массива
$f = Lambda::complex([ 'a'=>1, 'b'=>Lambda::v() ]); $f = function ($x) { return [ 'a' => 1, 'b' => $x ]; }; - доступ к свойствам и методам объекта, элементам массива
$f = Lambda::v()->items('car'); $f = Lambda::v()->getCar(); $f = Lambda::car; $f = function ($x) { return $x->getCar(); }; - вызов глобальных функций
$f = Lambda::substr(Lambda::v(), 3, 1)->eq('a'); $f = function ($x) { return substr($x,3,1) == 'a'; }; - LINQ методы для значений
$f = Lambda::v()->linq()->where(Lambda::v()->gt(1)); $f = function (\Iterator $x) { return new CallbackFilterIterator($x, function ($x) { return $x > 1; }); };
(x)=>x+1 скорость вычисления Lambda в 15 раз медленнее прямого вызова функции, а сама структура требует для хранения в 3600 байт памяти против 800. Планируется провести анализ профайлером, чтобы разобраться как увеличить скорость и уменьшить память.Встречают по интерфейсу, а провожают по реализации
Все LINQ методы взяты из стандартного .NET 4.5 и раскиданы по соответствующим интерфейсам (
GenerationInterface, FilteringInterface, etc.) с описанием из MSDN. Получилось много файлов, но дополнительная нагрузка на разбор файлов не должна быть большой, особенно, если включено кэширование. Сигнатура методов осталась насколько это возможно неизмененной с учетом возможностей PHP. Интерфейс IEnumerable наследует все упомянутые интерфейсы и \IteratorAggregate. Класс Linq реализует интерфейсы IEnumerable для локального перебора. В дальнейшем можно сделать другую реализацию IEnumerable, которая будет собирать SQL запрос или будет фасадом к Doctrine. Реализованые следующие методы.- Aggregation — aggregate, average, min, max, sum, count
- Concatenation — concat, zip
- Element — elementAt, elementAtOrDefault, first, firstOrDefault, last, lastOrDefault, single, singleOrDefault
- Equality — isEqual
- Filtering — ofType, where
- Generation — from, range, repeat
- Grouping — groupBy
- Joining — product, join, joinOuter, groupJoin
- Partitioning — skip, skipWhile, take, takeWhile
- Projection — select, selectMany, cast
- Quantifier — all, any, contains
- Set — distinct, intersect, except, union
- Sorting — orderBy, orderByDescending, thenBy, thenByDescending, reverse, order
- Прочее — toArray, toList, each
array), функция (callable) или итератор (\Iterator, \IteratorAggregate). Аналогично в качестве выражения может быть передана строка (string), функция (callable), массив (array) или лямбда выражение (\LambdaInterface). Ниже несколько примеров, есть так же разнообразные юнит-тесты.// Grouping+Sorting+Filtering+array expression
$x = Linq::from($cars)->group(Lambda::v()->getCategory()->getId())->select([
'category' => Lambda::i()->keys(),
'best' => Lambda::v()->linq()
->where(Lambda::v()->isActive()->eq(true))
->orderBy(Lambda::v()->getPrice())
->last()
])
// Set + LambdaInterface expression
$x = Linq::from($cars)->distinct(Lambda::v()->getCategory()->getTitle());
// Set + string expression
$x = Linq::from($cars)->distinct('category.title');
// Generation+callable
$fibonacci = function () {
$position = 0;
$f2 = 0;
$f1 = 1;
return function () use (&$position, &$f2, &$f1) {
$position++;
if ($position == 1) {
return $f2;
} elseif ($position == 2) {
return $f1;
} else {
$f = $f1 + $f2;
$f2 = $f1;
$f1 = $f;
return $f;
}
}
}
$x = Linq::from($fibonacci)->take(10);
Функция, которая вернула функцию, которая вернула функцию, которая ...
Каждый LINQ метод создает объект класса
Linq, которому передается инициализирующая анонимная функция и ссылка на другие Linq объекты, итераторы которых являются входными данными для инициализирующей функции. Так как Linq реализует интерфейс \IteratorAggregate, то при запросе первого элемента итераторы автоматически инициализируются по цепочке вверх.Зачем все это?
Спасибо всем, кто дочитал до конца. Проект делался для тренировки мозгов и рук, поэтому любая содержательная критика приветствуется на 200%. Мне очень хотелось поделиться работой, которой в общем доволен. Если он кому-либо еще и реально пригодится, то вообще замечательно.Весь код документирован, аннотирован, покрыт тестами и опубликован на github под лицензией BSD (modified). Это полностью рабочая библиотека.
