В предыдущих частях (тут и тут) мы говорили об основных архитектурных принципах построения масштабируемых порталов. Сегодня продолжим разговор об оптимизации правильно построенного портала. Итак, стратегии масштабирования.
Кэши — хорошая штука, чтобы усилить ударную силу отдельно взятого компонента или сервиса. Но каждой оптимизации когда-то приходит конец. Это — самый поздний момент, когда стоит задуматься, как поддерживать несколько экземпляров (instances) своих сервисов, другими словами — как масштабировать свою архитектуру. Разные типы узлов по-разному поддаются масштабированию. Общее правило при этом таково: чем ближе компонент к пользователю — тем легче его масштабировать.
Производительность — не единственная причина для работы над масштабированием. Доступность (availability) системы в большой степени тоже зависит от того, можем ли мы запускать несколько экземпляров каждого компонента параллельно, и, благодаря этому, быть в состоянии перенести потерю любой части системы. Верх совершенства масштабирования — уметь администрировать систему эластично, то есть подстраивать использование ресурсов под траффик.
Масштабировать презентационный уровень обычно легко. Это уровень, к которому относятся веб-приложения, бегающие в веб-сервере или сервлет-контейнере (например, tomcat или jetty), и отвечающие за генерацию markup, то есть HTML, XML или JSON.
Можно просто добавлять и убирать новые сервера по необходимости — до тех пор, пока одиночный веб-сервер:
Посложнее масштабировать уровень приложения (application tier) — тот уровень, где бегают сервисы. Но прежде чем перейти к уровню приложения, давайте посмотрим на уровень позади него — базы данных.
Печальная правда о масштабировании через базу заключается в том, что оно не работает. И хотя время от времени представители различных производителей баз данных пытаются снова убедить нас в том, что вот в этот раз они точно могут масштабироваться — в самый ответственный момент они нас покинут. Маленький disclaimer: я не говорю, что не надо делать кластеры баз данных или репликации а-ля master/slave. Есть много причин для использования кластеров и реплик, но производительность в их число не входит.
Вот главная причина того, что приложения так плохо масштабируются через базы данных: основная задача базы данных — лишь надежное сохранение данных (ACID и всё такое). Чтение данных им даётся гораздо тяжелее (прежде чем кричать «как же» и «почему же», подумайте: зачем нужно такое количество индексаторов типа lucene/solar/elastic search?). Раз мы не можем масштабировать через базу, нам надо масштабировать через application tier. Есть много причин, почему это прекрасно работает, назову две:
Существуют разные стратегии для масштабирования сервисов.
Для начала необходимо определить, что такое состояние сервиса (state). Состояние одного экземпляра сервиса — это та информация, которая известна только ему и которая, соответственно, отличает его от других экземпляров.
Экземпляр сервиса — это, как правило, JavaVM, в которой бегает одна копия этого сервиса. Информация, которая определяет его состояние — это обычно данные, попадающие в кэш. Если у сервиса нет вообще никаких собственных данных, он — stateless (не имеющий состояния). Для того, чтобы уменьшить нагрузку на какой-либо сервис, можно запустить несколько экземпляров этого сервиса. Стратегии распределения траффика на эти инстанции, в общем-то, и есть стратегии масштабирования.
Самая простая стратегия — Round-Robin. При этом каждый клиент «разговаривает» с каждым экземпляром сервиса, которые используются по-очереди, то есть друг за другом, по кругу. Эта стратегия работает хорошо до тех пор, пока сервисы не имеют состояния (stateless) и выполняют простые задачи, например, посылают мейлы через внешний интерфейс.
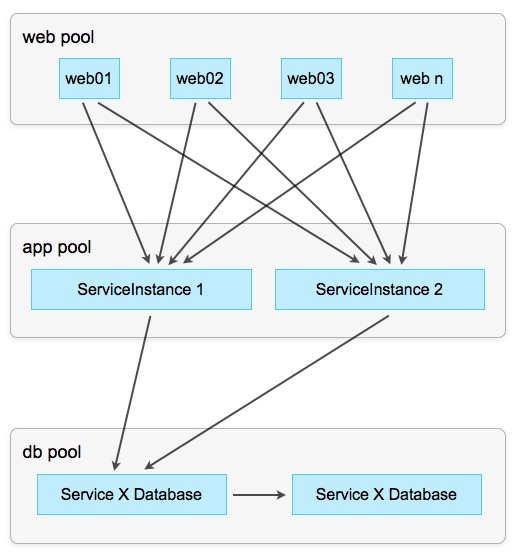
Схема 5: Распределяем обращения к сервисам по принципу Round-Robin
Когда у экземпляров сервисов есть состояния, они должны быть синхронизированы между собой, например, путем анонсирования изменений в состоянии через EventChannel или другой вариант Publish/Subscriber:
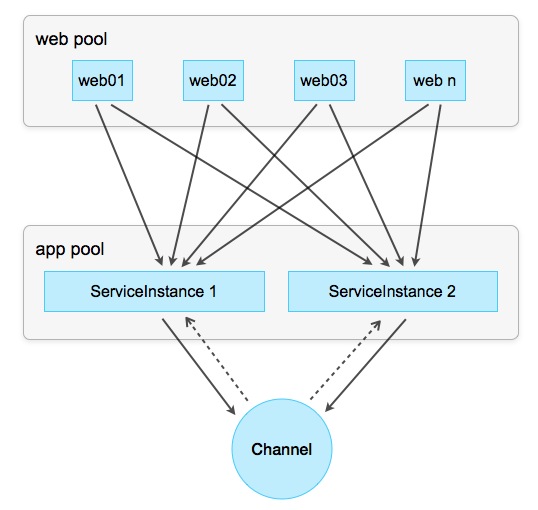
Схема 6: Round-Robin с синхронизацией состояния
При этом каждый экземпляр сообщает другим экземплярам обо всех изменениях, которые он вносит в каждый сохраняемый объект. В свою очередь, остальные экземпляры повторяют эту же операцию локально, изменяя своё частное состояние (state), и тем самым поддерживая состояние сервиса консистентным (согласованным) по всем экземплярам.
Эта стратегия неплохо работает при небольшом траффике. Однако с его увеличением возникают проблемы с возможностью одновременного изменения одного и того же объекта несколькими экземплярами.
Для борьбы с этим используется маршрутизация. При этом маршрутизация означает, что экземпляр сервиса выбирается в зависимости от контекста. Контекстом может быть клиент, операция или данные. Маршрутизация по данным, шардинг (sharding), — самый мощный инструмент маршрутизации: под ним подразумевается алгоритм маршрутизации, который выбирает целевой экземпляр сервиса на основании параметров операции (то есть данных).
В идеале, у нас есть однозначный параметр, например UserId, который можно легко перевести в числовую форму и провести деление с остатком. Разделяя на количество рабочих экземпляров, остаток указывает на целевой экземпляр запроса: все запросы с остатком 0 идут на первый экземпляр, с остатком 1 — на второй, и т.д.
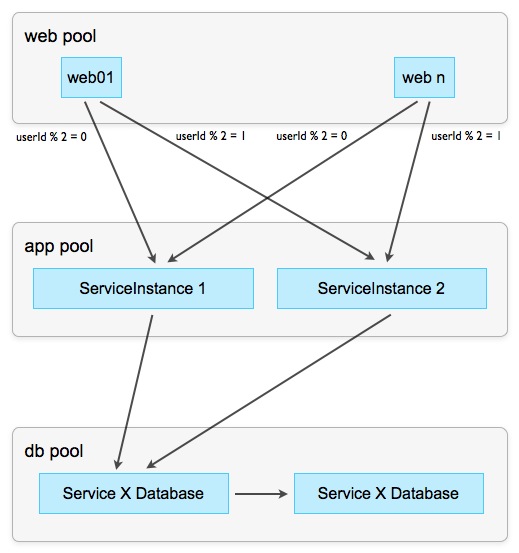
Схема 7: Шардинг (sharding) по остатку
У этой стратегии есть полезный побочный эффект: за счёт того, что все запросы по данным одного и того же пользователя попадают всегда на тот же экземпляр, данные фрагментируются. Это означает меньшие кэши, по желанию — фрагментированные базы данных (то есть, каждому экземпляру или их группе — своя база) и прочие оптимизационные вкусняшки
При наличие соответствующего middleware можно шагнуть на шаг дальше и комбинировать различные стратегии. Например, можно сгруппировать несколько экземпляров в группы, по которым распределять запросы шардингом, а внутри групп использовать Round-Robin для эластичности. Количество таких комбинированных стратегий слишком велико (ещё один пример), чтобы описать их все в одном посте, и зависит от конкретной проблемы.
Не всегда и не любые данные можно сегментировать, особенно когда одна операция изменяет одновременно два набора данных в разных контекстах. Классический пример — доставка сообщения от пользователя А к пользователю Б, при котором одновременно изменяются оба ящика (mailbox). Невозможно найти алгоритм распределения данных по экземплярам (шардинг), который гарантирует нахождение ящиков пользователя А и Б в одном экземпляре сервиса. Нои на старуху бывает проруха и для этой ситуации есть решения. Самое простое: имплицитно разделить сервис (в идеале — через middleware) так, чтобы клиент об этом ничего не знал. Например:
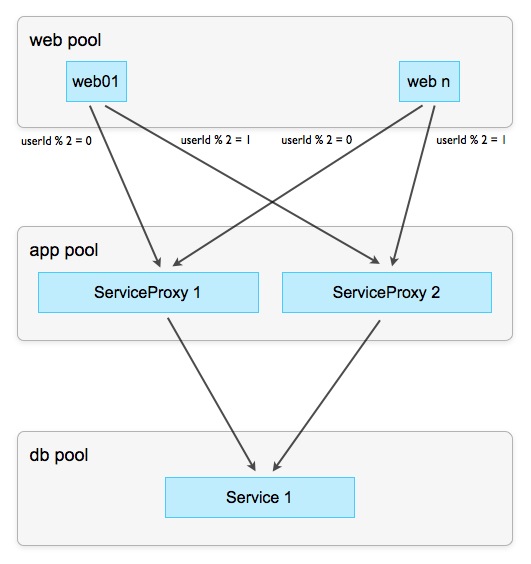
Схема 8: Прокси-сервисы
Задача экземпляров прокси-сервисов — обработать и ответить на читающие запросы, не доводя их до мастер-сервиса. Так как у нас гораздо больше читающих, чем пишущих операций (вспомним начальную установку), избавив от них мастер-сервис, мы значительно облегчим ему жизнь. Читающие операции обычно проходят в контексте одного (активного) пользователя и, значит, могут быть «расшардены», как описывалось выше. Оставшиеся пишущие операции проходят через прокси к мастеру, но, благодаря тому, что основная часть нагрузки осталась на прокси, уже доставляют значительно меньше геморроя.
В рамках этой серии (тут, тут и, собственно, тут) мы говорили о том, как найти правильную архитектуру и при помощи каких инструментов её масштабировать. Надеюсь, я убедил читателя, что время, потраченное на поиск и следование архитектурным парадигмам — инвестиция, многократно окупающаяся в тяжёлые моменты. Slave-Proxies, маршрутизация по Round-Robin или ноль-кэши — не то, о чем мы думаем в первую очередь, начиная работать над новым порталом. Да и не надо встраивать их «на всякий случай» — важно знать, как ими пользоваться и иметь архитектуру, которая позволяет использование подобных инструментов.
Далеко не каждый портал должен масштабироваться, но те, которые должны, обязаны уметь это делать быстро. Полагаться при этом исключительно на технологии (NoSQL и т.д.) означает отдать руль в чужие руки, и если выбор технологии окажется неправильным, собирать осколки своей системы веничком.
Если же с самого начала выбрать правильную архитектуру, найти свои принципы и парадигмы и придерживаться их, то ответ на возникающие сложности и вызовы всегда можно будет найти.
Удачи!
Потенциал локальной оптимизации очень ограничен.
Кэши — хорошая штука, чтобы усилить ударную силу отдельно взятого компонента или сервиса. Но каждой оптимизации когда-то приходит конец. Это — самый поздний момент, когда стоит задуматься, как поддерживать несколько экземпляров (instances) своих сервисов, другими словами — как масштабировать свою архитектуру. Разные типы узлов по-разному поддаются масштабированию. Общее правило при этом таково: чем ближе компонент к пользователю — тем легче его масштабировать.
Производительность — не единственная причина для работы над масштабированием. Доступность (availability) системы в большой степени тоже зависит от того, можем ли мы запускать несколько экземпляров каждого компонента параллельно, и, благодаря этому, быть в состоянии перенести потерю любой части системы. Верх совершенства масштабирования — уметь администрировать систему эластично, то есть подстраивать использование ресурсов под траффик.
Масштабировать презентационный уровень обычно легко. Это уровень, к которому относятся веб-приложения, бегающие в веб-сервере или сервлет-контейнере (например, tomcat или jetty), и отвечающие за генерацию markup, то есть HTML, XML или JSON.
Можно просто добавлять и убирать новые сервера по необходимости — до тех пор, пока одиночный веб-сервер:
- не имеет состояния (stateless), или
- его состояние восстановимо — например, потому, что оно целиком состоит из кэшей, или
- их (кэшей) состояние относится к конкретным пользователям и есть гарантия, что один и тот же пользователь будет всегда попадать на один и тот же сервер (session stickiness).
Посложнее масштабировать уровень приложения (application tier) — тот уровень, где бегают сервисы. Но прежде чем перейти к уровню приложения, давайте посмотрим на уровень позади него — базы данных.
Печальная правда о масштабировании через базу заключается в том, что оно не работает. И хотя время от времени представители различных производителей баз данных пытаются снова убедить нас в том, что вот в этот раз они точно могут масштабироваться — в самый ответственный момент они нас покинут. Маленький disclaimer: я не говорю, что не надо делать кластеры баз данных или репликации а-ля master/slave. Есть много причин для использования кластеров и реплик, но производительность в их число не входит.
Вот главная причина того, что приложения так плохо масштабируются через базы данных: основная задача базы данных — лишь надежное сохранение данных (ACID и всё такое). Чтение данных им даётся гораздо тяжелее (прежде чем кричать «как же» и «почему же», подумайте: зачем нужно такое количество индексаторов типа lucene/solar/elastic search?). Раз мы не можем масштабировать через базу, нам надо масштабировать через application tier. Есть много причин, почему это прекрасно работает, назову две:
- В этом уровне собрана большая часть трактата «Знание о приложении и его данных». Мы можем масштабировать, зная, что и как делает приложение и как им пользуются
- Здесь можно работать с помощью инструментов языков программирования, которые гораздо мощнее, чем инструменты, предоставляемые нам уровнем баз данных
Существуют разные стратегии для масштабирования сервисов.
Стратегии масштабирования.
Для начала необходимо определить, что такое состояние сервиса (state). Состояние одного экземпляра сервиса — это та информация, которая известна только ему и которая, соответственно, отличает его от других экземпляров.
Экземпляр сервиса — это, как правило, JavaVM, в которой бегает одна копия этого сервиса. Информация, которая определяет его состояние — это обычно данные, попадающие в кэш. Если у сервиса нет вообще никаких собственных данных, он — stateless (не имеющий состояния). Для того, чтобы уменьшить нагрузку на какой-либо сервис, можно запустить несколько экземпляров этого сервиса. Стратегии распределения траффика на эти инстанции, в общем-то, и есть стратегии масштабирования.
Самая простая стратегия — Round-Robin. При этом каждый клиент «разговаривает» с каждым экземпляром сервиса, которые используются по-очереди, то есть друг за другом, по кругу. Эта стратегия работает хорошо до тех пор, пока сервисы не имеют состояния (stateless) и выполняют простые задачи, например, посылают мейлы через внешний интерфейс.
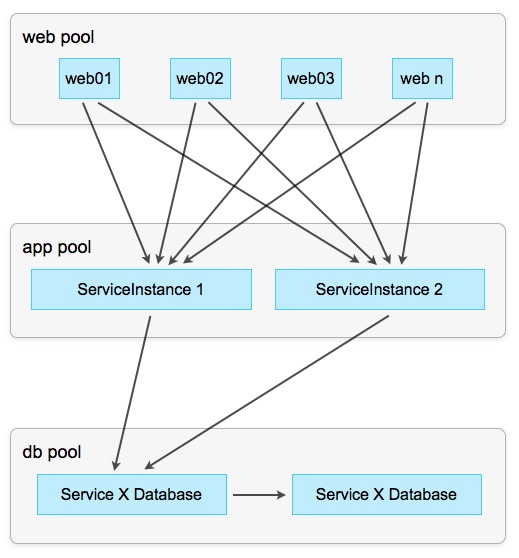
Схема 5: Распределяем обращения к сервисам по принципу Round-Robin
Когда у экземпляров сервисов есть состояния, они должны быть синхронизированы между собой, например, путем анонсирования изменений в состоянии через EventChannel или другой вариант Publish/Subscriber:

Схема 6: Round-Robin с синхронизацией состояния
При этом каждый экземпляр сообщает другим экземплярам обо всех изменениях, которые он вносит в каждый сохраняемый объект. В свою очередь, остальные экземпляры повторяют эту же операцию локально, изменяя своё частное состояние (state), и тем самым поддерживая состояние сервиса консистентным (согласованным) по всем экземплярам.
Эта стратегия неплохо работает при небольшом траффике. Однако с его увеличением возникают проблемы с возможностью одновременного изменения одного и того же объекта несколькими экземплярами.
Для борьбы с этим используется маршрутизация. При этом маршрутизация означает, что экземпляр сервиса выбирается в зависимости от контекста. Контекстом может быть клиент, операция или данные. Маршрутизация по данным, шардинг (sharding), — самый мощный инструмент маршрутизации: под ним подразумевается алгоритм маршрутизации, который выбирает целевой экземпляр сервиса на основании параметров операции (то есть данных).
В идеале, у нас есть однозначный параметр, например UserId, который можно легко перевести в числовую форму и провести деление с остатком. Разделяя на количество рабочих экземпляров, остаток указывает на целевой экземпляр запроса: все запросы с остатком 0 идут на первый экземпляр, с остатком 1 — на второй, и т.д.
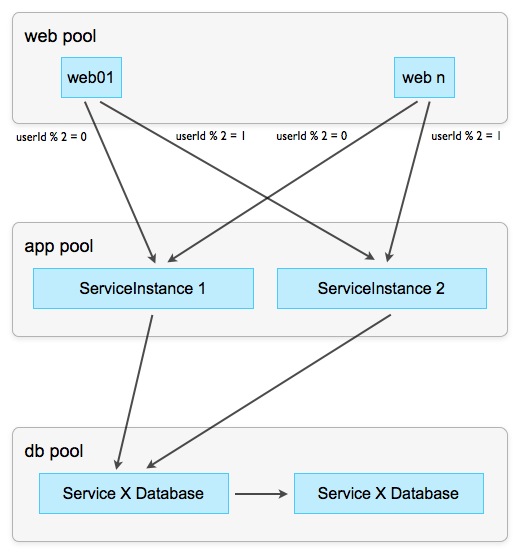
Схема 7: Шардинг (sharding) по остатку
У этой стратегии есть полезный побочный эффект: за счёт того, что все запросы по данным одного и того же пользователя попадают всегда на тот же экземпляр, данные фрагментируются. Это означает меньшие кэши, по желанию — фрагментированные базы данных (то есть, каждому экземпляру или их группе — своя база) и прочие оптимизационные вкусняшки
При наличие соответствующего middleware можно шагнуть на шаг дальше и комбинировать различные стратегии. Например, можно сгруппировать несколько экземпляров в группы, по которым распределять запросы шардингом, а внутри групп использовать Round-Robin для эластичности. Количество таких комбинированных стратегий слишком велико (ещё один пример), чтобы описать их все в одном посте, и зависит от конкретной проблемы.
Не всегда и не любые данные можно сегментировать, особенно когда одна операция изменяет одновременно два набора данных в разных контекстах. Классический пример — доставка сообщения от пользователя А к пользователю Б, при котором одновременно изменяются оба ящика (mailbox). Невозможно найти алгоритм распределения данных по экземплярам (шардинг), который гарантирует нахождение ящиков пользователя А и Б в одном экземпляре сервиса. Но
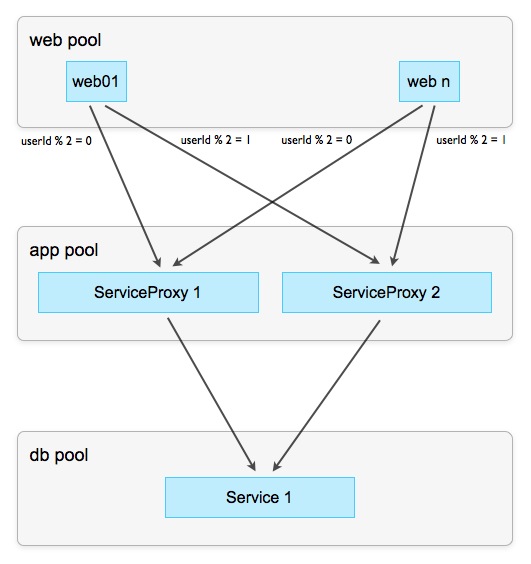
Схема 8: Прокси-сервисы
Задача экземпляров прокси-сервисов — обработать и ответить на читающие запросы, не доводя их до мастер-сервиса. Так как у нас гораздо больше читающих, чем пишущих операций (вспомним начальную установку), избавив от них мастер-сервис, мы значительно облегчим ему жизнь. Читающие операции обычно проходят в контексте одного (активного) пользователя и, значит, могут быть «расшардены», как описывалось выше. Оставшиеся пишущие операции проходят через прокси к мастеру, но, благодаря тому, что основная часть нагрузки осталась на прокси, уже доставляют значительно меньше геморроя.
Эпилог
В рамках этой серии (тут, тут и, собственно, тут) мы говорили о том, как найти правильную архитектуру и при помощи каких инструментов её масштабировать. Надеюсь, я убедил читателя, что время, потраченное на поиск и следование архитектурным парадигмам — инвестиция, многократно окупающаяся в тяжёлые моменты. Slave-Proxies, маршрутизация по Round-Robin или ноль-кэши — не то, о чем мы думаем в первую очередь, начиная работать над новым порталом. Да и не надо встраивать их «на всякий случай» — важно знать, как ими пользоваться и иметь архитектуру, которая позволяет использование подобных инструментов.
Далеко не каждый портал должен масштабироваться, но те, которые должны, обязаны уметь это делать быстро. Полагаться при этом исключительно на технологии (NoSQL и т.д.) означает отдать руль в чужие руки, и если выбор технологии окажется неправильным, собирать осколки своей системы веничком.
Если же с самого начала выбрать правильную архитектуру, найти свои принципы и парадигмы и придерживаться их, то ответ на возникающие сложности и вызовы всегда можно будет найти.
Удачи!
