Не так давно в boost-1.53 появился целый новый раздел — lockfree реализующий неблокирующие очереди и стек.
Я последние несколько лет работал с так называемыми неблокируюшими алгоритмами (lock-free data structures), мы их сами писали, сами тестировали, сами использовалии втайне ими гордились. Естественно, у нас немедленно встал вопрос, переходить ли с самодельных библиотек на boost, и если переходить, то когда?
Вот тогда у меня и возникла в первый раз идея применить к boost::lockfree кое-какие из методик которыми мы испытывали собственный код. К счастью, сам алгоритм нам тестировать не придется и можно сосредоточиться на измерении производительности.
Я постараюсь сделать статью интересной для всех. Тем кто еще не сталкивался с подобными задачами будет полезно посмотреть на то что такие алгоритмы способны, а главное, где и как их стоит или не стоит использовать. Для тех кто имеет опыт разработки неблокирующих очередей возможно будет интересно сравнить данные количественных измерений. Я сам по крайней мере таких публикаций еще не видел.
В современное программирование прочно вошло понятие многопоточности, однако работа с потоками невозможна без средств синхронизации, так появились mutex, semaphore, condition variable и их дальнейшие потомки. Однако первые стандартные функции были достаточно тяжелыми и медленными, более того, они были реализованы внутри ядра, то есть требовали контекстного переключения на каждый вызов. Время перключения слабо зависит от CPU, поэтому чем быстрее становились процессоры, тем больше относительного времени требовалось на синхронизацию потоков. Тогда появилась идея, что при минимальной аппаратной поддержке можно было бы создать структуры данных инвариантные при одновременной работе с несколькими потоками. Тем кто хотел бы об этом подробнее, рекомендую вот эту серию публикаций.
Основные алгоритмы были разработаны и положены в долгий ящик, их время тогда еще не пришло. Вторую жизнь они получили когда понятие времени обработки сообщения (latency) стало чуть ли не более важным чем привычная скорость CPU. О чем вообще речь?
Подробнее можно прочитать в изложении интервью Herb Sutter, он немного в другом контексте, но очень темпераментно обсуждает эту проблему. Интуитивно кажется что понятия быстродействия и latency идентичны — чем больше первое, тем меньше второе. При детальном рассмотрении оказывается, однако, что они независимы и даже антикоррелированы.
Какое это имеет отношение к неблокирующим структурам? Самое прямое, дело в том, что для latency любая попытка притормозить или остановить поток губительна. Усыпить поток легко, но разбудить его невозможно. Его может разбудитьласковым поцелуем только ядро операционной системы, а оно это делает строго по расписанию и с перерывами на обед. Попробуйте обьяснить кому нибудь, что ваша программа, которая обязалась по тех. заданию реагировать в течении 200 наносекунд, в данный момент заснула на 10 миллисекунд (типичное время для *nix систем) и ее лучше не беспокоить. На помощь приходят lock-free структуры данных, которые не требуют останавливать поток для синхронизации с другими потоками.
Вот об одной такой структуре и поговорим.
Я буду работать только с одной из структур — boost::lockfree::queue реализующей однонаправленную очередь с произвольным числом пишущих и читающих потоков. Эта структура существует в двух вариантах — аллоцирующем память по мере необходимости и имеющем бесконечную емкость, и вариант с фиксированным буфером. Строго говоря, они оба не являются неблокирующими, первый потому что системное выделение памяти не является lock-free, второй, потому что рано или поздно буфер переполнится и пишущие потоки будут вынуждены ждать неопределенное время пока не появится место для записи. Начнем с первого варианта, а ближе к концу я сравню с результатами для фиксированного буфера.
Добавлю еще что у меня 4-ядерная Linux Mint-15.
Возьмем код прямо отсюда и попробуем запустить, вот что получается:
То есть, если подходить к делу по простому, около 400 нс на сообщение, вполне удовлетворительно. Эта реализация передает int и запускает по 4 читающих и пишущих потока.
Давайте чуть-чуть модифицируем код, я хочу запускать произвольное число потоков и еще я люблю видеть статистику. Какое будет распределение если запустить тест 100 раз подряд?
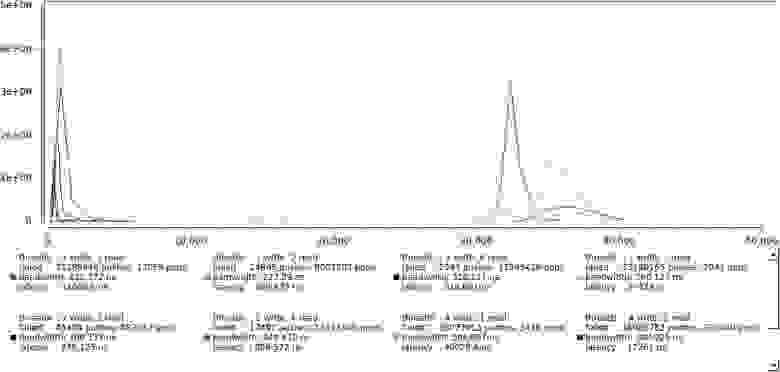
Вот, пожалуйста, выглядит вполне разумно. По оси X общее время исполнения в наносекундах деленное на число переданных сообщений, по оси Y — число таких событий.
А вот результат для разного числа писателей/читателей:
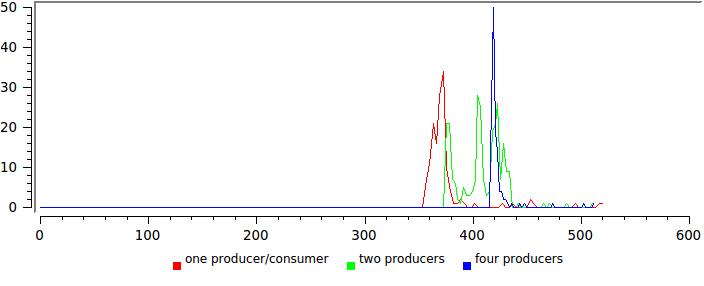
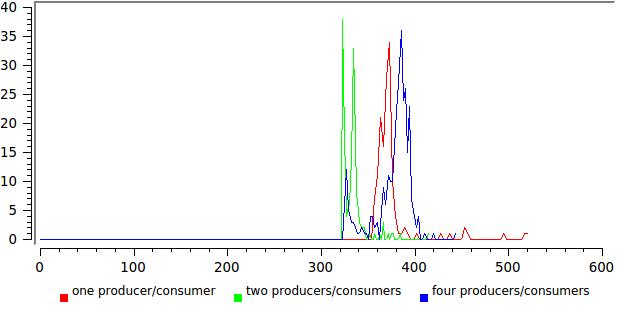
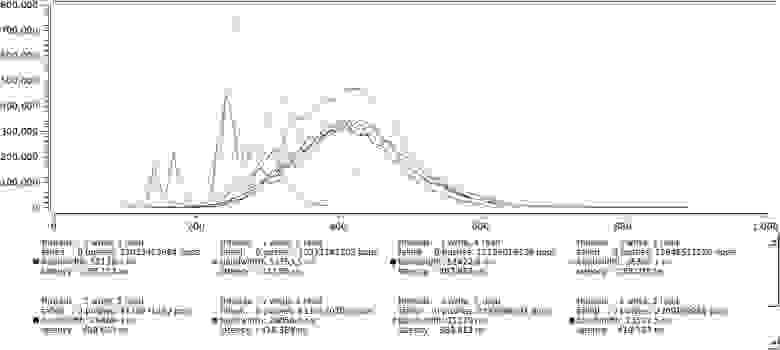
Здесь уже не все так радужно, любое уширение распределения говорит от том что что-то работает не оптимально. В данном случае примерно понятно что — читающие потоки в этом тесте никогда не отдают управление и когда их число приближается к числу ядер, системе просто приходится их приостанавливать.
Сделаем еще одно улучшение в тесте, вместо того чтобы передавать бесполезный int, пусть пишущий поток посылает текущее время с точностью до наносекунд. Тогда получатель сможет вычислить latency для каждого сообщения. Делаем, запускаем:
Мы теперь еще подсчитываем число неудачных попыток прочитать сообщение из очереди и записать в очередь (первое здесь конечно всегда будет равно нулю, это аллоцирующий вариант).
Однако это что еще такое? Задержка, которую мы интуитивно предполагали того же порядка — 200 нс, вдруг превышает 100 миллисекунд, в полмиллиона раз больше! Этого просто не может быть.
Но ведь мы теперь знаем задержку каждого сообщения, вот давйте и посмотрим как это выглядит в реальном времени, здесь приведены результаты нескольких идентичных запусков, чтобы было видно насколько случаен процесс:
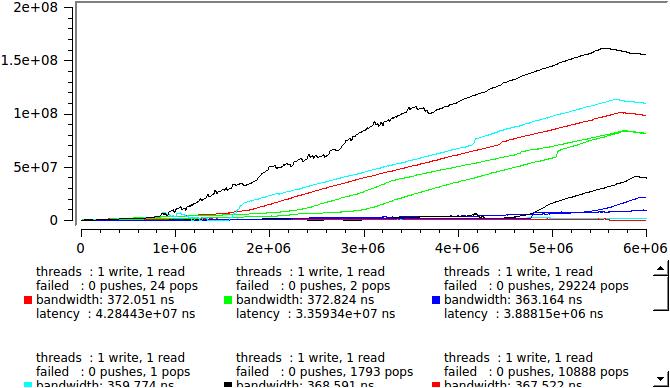
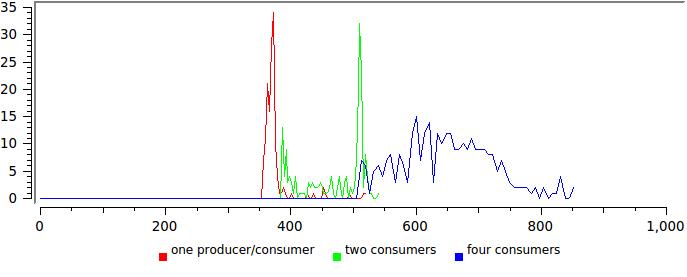
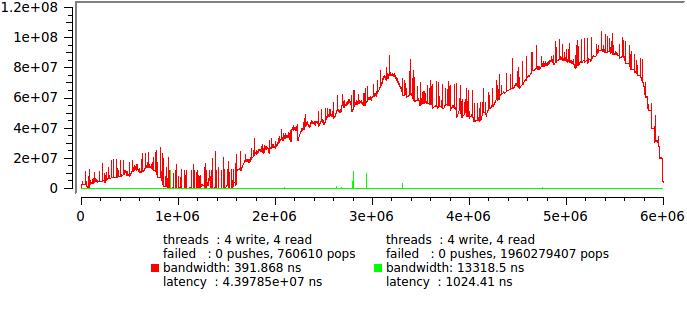
это если у нас пишет и читает по одному потоку, а если по четыре то вот:

Что же происходит? В какой то произвольный момент часть читающих потоков отправляется системой отдохнуть. Очередь начинает стремительно расти, сообщения сидят в ней и ждут обработки. Через некоторое время ситуация меняется, число пишущих потоков становится меньше чем читающих и очередь потихоньку рассасывается. Такие колебания происходят с периодом от миллисекунд до секунд и очередь работает в пакетном режиме — миллион сообщений записали, миллион прочли. При этом быстродействие остается очень высоким, но каждое отдельное сообщение может провести в очереди несколько миллисекунд.
Что будем делать? Прежде всего задумаемся, тест в таком виде явно неадекватен. У нас половина активных потоков занята только тем что вставляет сообщения в очередь, такого просто не может случиться на реальной системе, иными словами тест устроен так что генерирует траффик заведомо провосходящий мощность машины.
Придется ограничить входной траффик, достаточно вставить usleep(0) после каждой записи в очередь. На моей машине это дает задержку 50 мкс с хорошей точностью. Посмотрим:
Красная линия — исходный тест без задержки, зеленая — с задержкой.
Совсем другое дело, теперь можно и статистику посчитать.
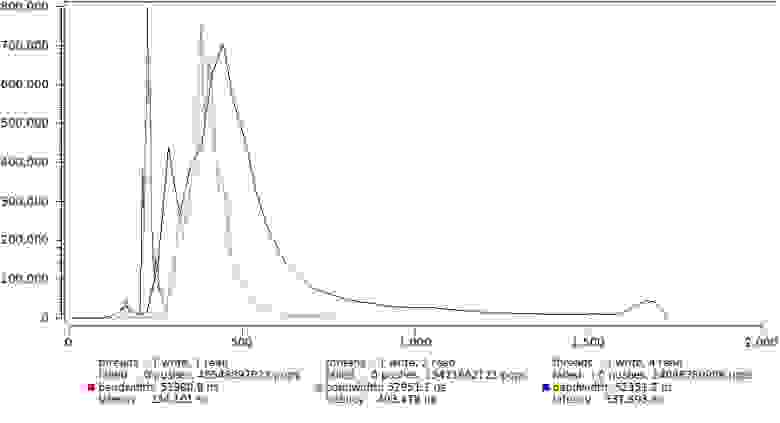
Вот результат для нескольких комбинаций числа пишущих и читающих потоков, для сохранения приемлемого масштаба по X, 1% самых больших отсчетов отброшен:

Обратите внимание что latency уверенно остается в пределах 300 нс и только хвост распределения вытягивается все дальше.
А вот результаты для одного и четырех пишуших потоков соответственно.
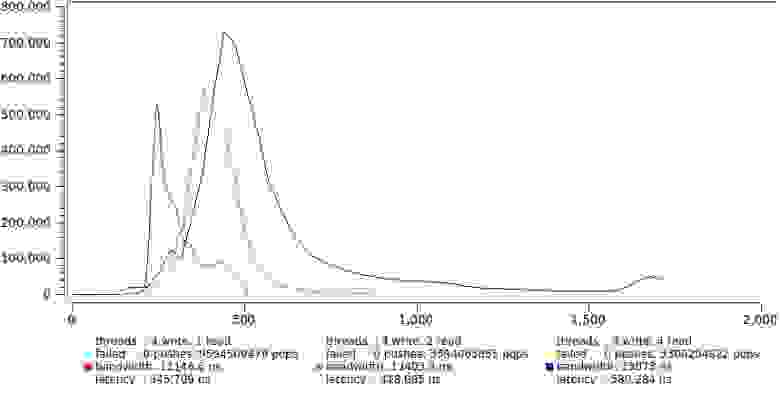
Здесь существенное увеличение задержки налицо, в основном за счет резкого роста хвоста. Опять мы видим что четыре (== CPU) потока которые непрерывно молотят вхолостую вырабатывая свой квант времени, что порождает большое количество неконтролируемых притормаживаний. Хотя средняя задержка уверенно остается в пределах 600 нс, для некоторых задач это уже на грани допустимого, например если у вас ТЗ четко оговаривающее что 99.9% сообщений должны быть доставлены за определенное время (у меня такое случалось).
Обратите также внимание, насколько выросло общее время исполнения, раз в 150. Это демонстрация утверждения кототое я делал в самом начале — минимальная latency и максимальное быстродействие одновременно не достигаются. Этакий своеобразный принцип неопределенности.
Вот собственно все что мы смогли вытащить из тестов, не так уж и мало. Мы с хорошей точностью померили задержку, показали что в ряде режимов средняя latency вырастает на много порядков или, точнее говоря, понятие среднего для нее теряет смысл.
Давайте напоследок рассмотрим последний вопрос.
fixed capacity — другой вариант boost::lockfree::queue построенный на внутреннем буфере жестко заданного размера. С одной стороны это позволяет избежать обращения к системному аллокатору, с другой, если буфер заполнится, пишущему потоку тоже придется ждать. Для некоторых типов задач это совершенно исключено.
Здесь будем работать по тому же методу. Сначала, наученные опытом, посмотрим динамику задержек:
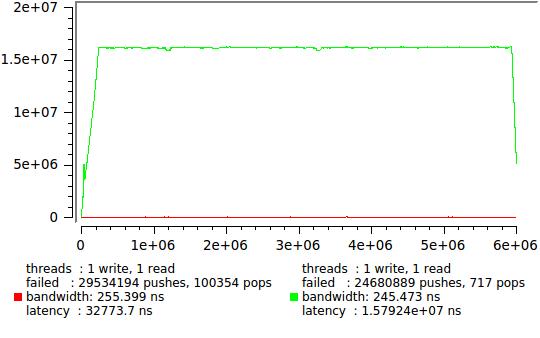
Красный график соответствыет используемому в примере из boost 128 байт, зеленый — максимально возможному 65534 байт.
Исскуственную задержку мы не вставляли, поэтому естественно что очередь работает в пакетном режиме, заполняется и освобождается большими порциями. Однако фиксированная емкость буфера вносит некий порядок и хорошо видно что среднее для задержки по крайней мере существует. Еще один неожиданныйдля любителей огромных буферов вывод в том, что размер буфера не влияет никак на общую скорость выполнения. То есть если вас устраивет latency в 32 мкс (что кстати вполне достаточно для многих приложений) можно использовать fixed_capacity lockfree::queue с крохотным использованием памяти получив впридачу замечательную скорость.
Но тем не менее, давайте оценим как этот вариант ведет себя в многопоточной программе:
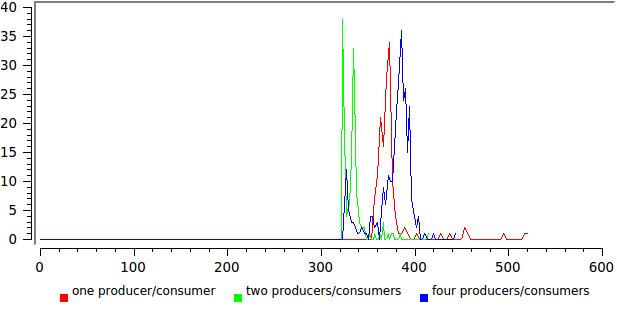
немного неожиданно было увидеть такое четкое разделение на две группы, там где скорость читателей превосходит скорость писателей мы получаем наши желанные сотни наносекунд, там где наоборот — скачком растет до 30-40 микросекунд, похоже это время переключения контекста на моей машине. Это результат для 128-байтового буфера, дле 64К выглядит очень похоже, только правая группа уползает далеко-далеко, на десятки миллисекунд.
Хорошо это или плохо? Зависит от задачи, с одной стороны мы можем уверенно гарантировать что задержка никогда не превысит 40 мкс при любых условиях, и это хорошо; с другой, если нам требуется гарантировать некоторую максимальную задержку меньше этого значения, то нам придется тяжело. Любое изменение баланса читателей/писателей, например из за незначительного изменения обработки сообщений, может привести к скачкообразному изменения задержки.
Вспомним, однако, что мы генерируем сообщения заведомо быстрее чем может обработать наша система (см. выше, в секции про динамически очереди) и попытаемся вставить правдоподобную задержку:
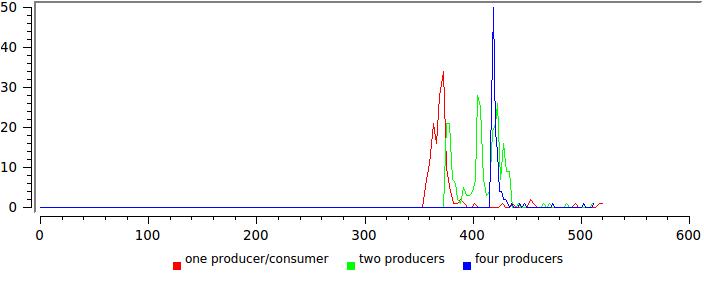
вот это уже совсем хорошо, две группы не слились полностью, однако правая приблизилась так, что максимальная latency не превышает 600 нс. Поверьте мне на слово, статистика для большого буфера — 64К, выглядит абсолютно так же, ни малейших различий.
Я надеюсь что те кто имеет опыт смогут извлечь что-то полезное сами из результатов тестов. Вот что думаю я сам:
Я последние несколько лет работал с так называемыми неблокируюшими алгоритмами (lock-free data structures), мы их сами писали, сами тестировали, сами использовали
Вот тогда у меня и возникла в первый раз идея применить к boost::lockfree кое-какие из методик которыми мы испытывали собственный код. К счастью, сам алгоритм нам тестировать не придется и можно сосредоточиться на измерении производительности.
Я постараюсь сделать статью интересной для всех. Тем кто еще не сталкивался с подобными задачами будет полезно посмотреть на то что такие алгоритмы способны, а главное, где и как их стоит или не стоит использовать. Для тех кто имеет опыт разработки неблокирующих очередей возможно будет интересно сравнить данные количественных измерений. Я сам по крайней мере таких публикаций еще не видел.
Вступление: что такое неблокирующие структуры данных и алгоритмы
В современное программирование прочно вошло понятие многопоточности, однако работа с потоками невозможна без средств синхронизации, так появились mutex, semaphore, condition variable и их дальнейшие потомки. Однако первые стандартные функции были достаточно тяжелыми и медленными, более того, они были реализованы внутри ядра, то есть требовали контекстного переключения на каждый вызов. Время перключения слабо зависит от CPU, поэтому чем быстрее становились процессоры, тем больше относительного времени требовалось на синхронизацию потоков. Тогда появилась идея, что при минимальной аппаратной поддержке можно было бы создать структуры данных инвариантные при одновременной работе с несколькими потоками. Тем кто хотел бы об этом подробнее, рекомендую вот эту серию публикаций.
Основные алгоритмы были разработаны и положены в долгий ящик, их время тогда еще не пришло. Вторую жизнь они получили когда понятие времени обработки сообщения (latency) стало чуть ли не более важным чем привычная скорость CPU. О чем вообще речь?
Вот простой пример:
Пусть у меня есть некий сервер который получает сообщения, обрабатывет и посылает ответ. Предположим что мне пришло 1 миллион сообщений и сервер справился с ними за 2 секунды, то есть по 2 мкс на транзакцию и меня это устраивает. Как раз это и называется быстродействием (bandwidth) и не является корректной мерой при обработке сообщений. Позже я с удивлением узнаю что каждый приславшинй мне сообщение клиент получил ответ не ранее чем через 1 секунду, что их не устраивает совершенно. В чем дело? Один из возможных сценариев: сервер быстро получает все сообщения и складывает их в буфер; потом обрабатывает их параллельно, тратя на каждое 1 секунду, но успевает обработать все вместе всего лишь за 2 секунды; и быстро посылает обратно. Это пример хорошей скорости системы в целом и в то же время неприемлемо большой latency.
Подробнее можно прочитать в изложении интервью Herb Sutter, он немного в другом контексте, но очень темпераментно обсуждает эту проблему. Интуитивно кажется что понятия быстродействия и latency идентичны — чем больше первое, тем меньше второе. При детальном рассмотрении оказывается, однако, что они независимы и даже антикоррелированы.
Какое это имеет отношение к неблокирующим структурам? Самое прямое, дело в том, что для latency любая попытка притормозить или остановить поток губительна. Усыпить поток легко, но разбудить его невозможно. Его может разбудить
Вот об одной такой структуре и поговорим.
Первый подход к помосту
Я буду работать только с одной из структур — boost::lockfree::queue реализующей однонаправленную очередь с произвольным числом пишущих и читающих потоков. Эта структура существует в двух вариантах — аллоцирующем память по мере необходимости и имеющем бесконечную емкость, и вариант с фиксированным буфером. Строго говоря, они оба не являются неблокирующими, первый потому что системное выделение памяти не является lock-free, второй, потому что рано или поздно буфер переполнится и пишущие потоки будут вынуждены ждать неопределенное время пока не появится место для записи. Начнем с первого варианта, а ближе к концу я сравню с результатами для фиксированного буфера.
Добавлю еще что у меня 4-ядерная Linux Mint-15.
Возьмем код прямо отсюда и попробуем запустить, вот что получается:
boost::lockfree::queue is lockfree produced 40000000 objects. consumed 40000000 objects. real 0m15.332s user 1m0.376s sys 0m0.064s
То есть, если подходить к делу по простому, около 400 нс на сообщение, вполне удовлетворительно. Эта реализация передает int и запускает по 4 читающих и пишущих потока.
Давайте чуть-чуть модифицируем код, я хочу запускать произвольное число потоков и еще я люблю видеть статистику. Какое будет распределение если запустить тест 100 раз подряд?
Вот, пожалуйста, выглядит вполне разумно. По оси X общее время исполнения в наносекундах деленное на число переданных сообщений, по оси Y — число таких событий.
А вот результат для разного числа писателей/читателей:
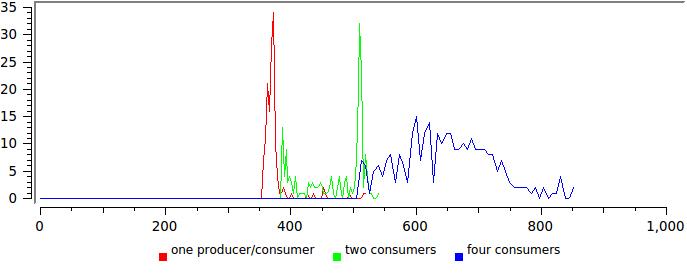
Здесь уже не все так радужно, любое уширение распределения говорит от том что что-то работает не оптимально. В данном случае примерно понятно что — читающие потоки в этом тесте никогда не отдают управление и когда их число приближается к числу ядер, системе просто приходится их приостанавливать.
Второй подход к помосту
Сделаем еще одно улучшение в тесте, вместо того чтобы передавать бесполезный int, пусть пишущий поток посылает текущее время с точностью до наносекунд. Тогда получатель сможет вычислить latency для каждого сообщения. Делаем, запускаем:
threads : 1 write, 1 read failed : 0 pushes, 3267 pops bandwidth: 177.864 ns latency : 1.03614e+08 ns
Мы теперь еще подсчитываем число неудачных попыток прочитать сообщение из очереди и записать в очередь (первое здесь конечно всегда будет равно нулю, это аллоцирующий вариант).
Однако это что еще такое? Задержка, которую мы интуитивно предполагали того же порядка — 200 нс, вдруг превышает 100 миллисекунд, в полмиллиона раз больше! Этого просто не может быть.
Но ведь мы теперь знаем задержку каждого сообщения, вот давйте и посмотрим как это выглядит в реальном времени, здесь приведены результаты нескольких идентичных запусков, чтобы было видно насколько случаен процесс:
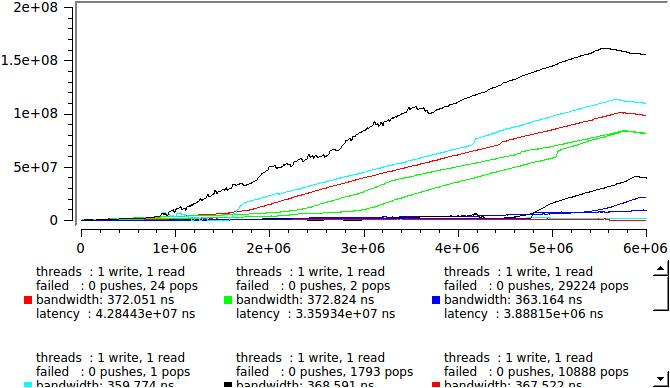
это если у нас пишет и читает по одному потоку, а если по четыре то вот:
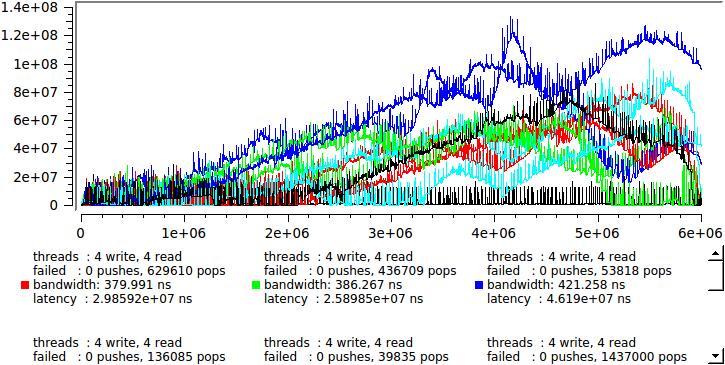
Что же происходит? В какой то произвольный момент часть читающих потоков отправляется системой отдохнуть. Очередь начинает стремительно расти, сообщения сидят в ней и ждут обработки. Через некоторое время ситуация меняется, число пишущих потоков становится меньше чем читающих и очередь потихоньку рассасывается. Такие колебания происходят с периодом от миллисекунд до секунд и очередь работает в пакетном режиме — миллион сообщений записали, миллион прочли. При этом быстродействие остается очень высоким, но каждое отдельное сообщение может провести в очереди несколько миллисекунд.
Что будем делать? Прежде всего задумаемся, тест в таком виде явно неадекватен. У нас половина активных потоков занята только тем что вставляет сообщения в очередь, такого просто не может случиться на реальной системе, иными словами тест устроен так что генерирует траффик заведомо провосходящий мощность машины.
Придется ограничить входной траффик, достаточно вставить usleep(0) после каждой записи в очередь. На моей машине это дает задержку 50 мкс с хорошей точностью. Посмотрим:
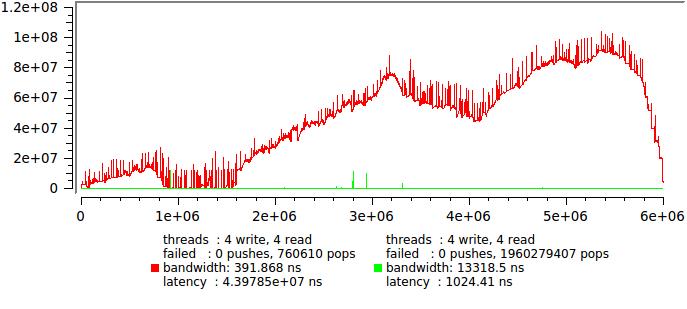
Красная линия — исходный тест без задержки, зеленая — с задержкой.
Совсем другое дело, теперь можно и статистику посчитать.
Вот результат для нескольких комбинаций числа пишущих и читающих потоков, для сохранения приемлемого масштаба по X, 1% самых больших отсчетов отброшен:
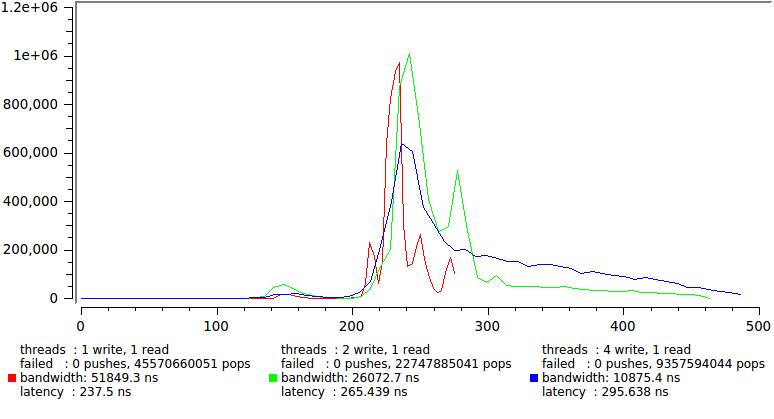
Обратите внимание что latency уверенно остается в пределах 300 нс и только хвост распределения вытягивается все дальше.
А вот результаты для одного и четырех пишуших потоков соответственно.
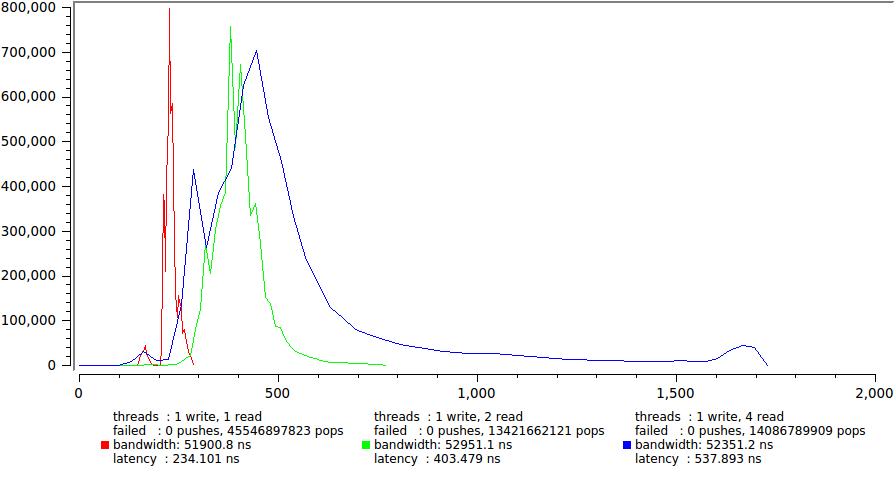
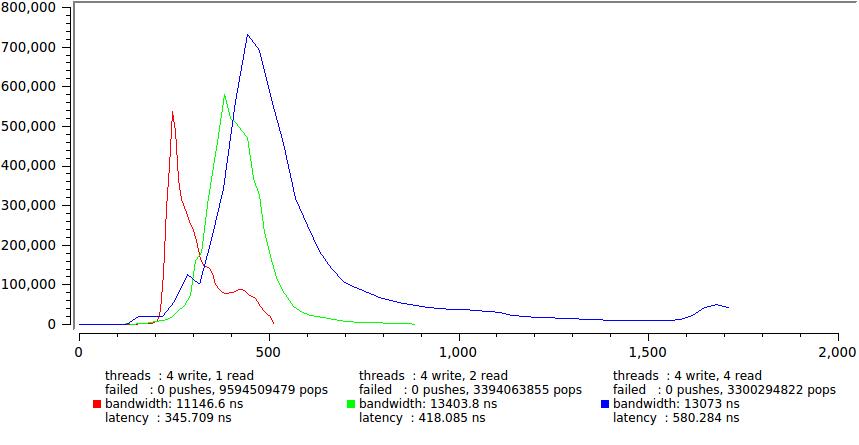
Здесь существенное увеличение задержки налицо, в основном за счет резкого роста хвоста. Опять мы видим что четыре (== CPU) потока которые непрерывно молотят вхолостую вырабатывая свой квант времени, что порождает большое количество неконтролируемых притормаживаний. Хотя средняя задержка уверенно остается в пределах 600 нс, для некоторых задач это уже на грани допустимого, например если у вас ТЗ четко оговаривающее что 99.9% сообщений должны быть доставлены за определенное время (у меня такое случалось).
Обратите также внимание, насколько выросло общее время исполнения, раз в 150. Это демонстрация утверждения кототое я делал в самом начале — минимальная latency и максимальное быстродействие одновременно не достигаются. Этакий своеобразный принцип неопределенности.
Вот собственно все что мы смогли вытащить из тестов, не так уж и мало. Мы с хорошей точностью померили задержку, показали что в ряде режимов средняя latency вырастает на много порядков или, точнее говоря, понятие среднего для нее теряет смысл.
Давайте напоследок рассмотрим последний вопрос.
А что насчет fixed capacity queue?
fixed capacity — другой вариант boost::lockfree::queue построенный на внутреннем буфере жестко заданного размера. С одной стороны это позволяет избежать обращения к системному аллокатору, с другой, если буфер заполнится, пишущему потоку тоже придется ждать. Для некоторых типов задач это совершенно исключено.
Здесь будем работать по тому же методу. Сначала, наученные опытом, посмотрим динамику задержек:

Красный график соответствыет используемому в примере из boost 128 байт, зеленый — максимально возможному 65534 байт.
Кстати
В документации сказано что максимальный размер — 65535 байт — не верьте, получите core dump
Исскуственную задержку мы не вставляли, поэтому естественно что очередь работает в пакетном режиме, заполняется и освобождается большими порциями. Однако фиксированная емкость буфера вносит некий порядок и хорошо видно что среднее для задержки по крайней мере существует. Еще один неожиданный
Но тем не менее, давайте оценим как этот вариант ведет себя в многопоточной программе:
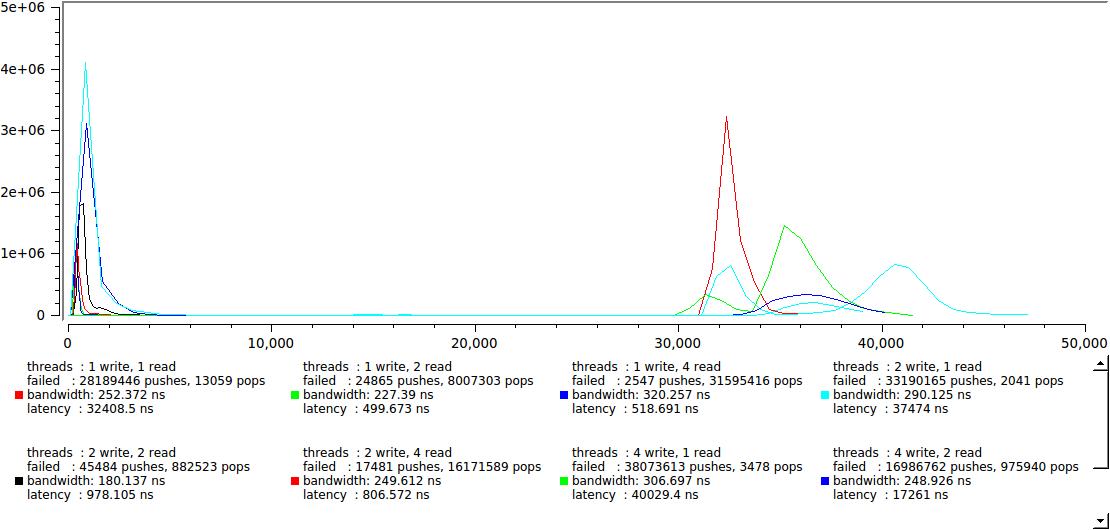
немного неожиданно было увидеть такое четкое разделение на две группы, там где скорость читателей превосходит скорость писателей мы получаем наши желанные сотни наносекунд, там где наоборот — скачком растет до 30-40 микросекунд, похоже это время переключения контекста на моей машине. Это результат для 128-байтового буфера, дле 64К выглядит очень похоже, только правая группа уползает далеко-далеко, на десятки миллисекунд.
Хорошо это или плохо? Зависит от задачи, с одной стороны мы можем уверенно гарантировать что задержка никогда не превысит 40 мкс при любых условиях, и это хорошо; с другой, если нам требуется гарантировать некоторую максимальную задержку меньше этого значения, то нам придется тяжело. Любое изменение баланса читателей/писателей, например из за незначительного изменения обработки сообщений, может привести к скачкообразному изменения задержки.
Вспомним, однако, что мы генерируем сообщения заведомо быстрее чем может обработать наша система (см. выше, в секции про динамически очереди) и попытаемся вставить правдоподобную задержку:
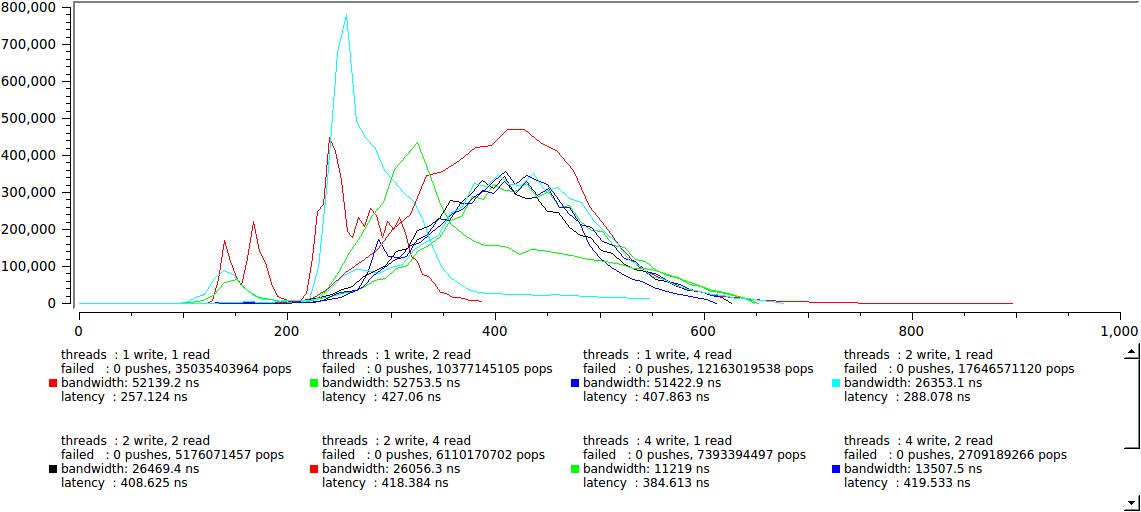
вот это уже совсем хорошо, две группы не слились полностью, однако правая приблизилась так, что максимальная latency не превышает 600 нс. Поверьте мне на слово, статистика для большого буфера — 64К, выглядит абсолютно так же, ни малейших различий.
Пора переходить к заключению
Я надеюсь что те кто имеет опыт смогут извлечь что-то полезное сами из результатов тестов. Вот что думаю я сам:
- Если вас интересует лишь быстродействие, все варианты примерно эквивалентны и дают среднее время порядка сотен наносекунд на сообщение. При этом fixed_capacity очередь является более легковесной, поскольку занимает фиксированный обьем памяти. Бывают однако приложения, логгер например, где критически важно как можно быстрее «освободить» читающий поток, в таком случае аллоцируюшая очередь подходит лучше, с другой стороны она может потреблять память неограниченно.
- Если требуется минимизация latency, времени обработки каждого сообщения в отдельности, ситуация осложняется. Для приложений где требуется не блокировать пишущий поток (логгеры) безусловно стоит выбрать аллоцирующий вариант. Для случая ограниченной памяти однозначно подходит fixed_capacity, размеры буфера придется подобрать исходя из статистики сигнала.
- В любом случае алгоритм неустойчив относительно интенсивности потока данных. При превышении некоторого критического порога задержка скачком возрастает на несколько порядков и очредь фактически (но не формально) становится блокирующей. Как правило требуется тонкая настройка чтобы заставить систему работать не сваливаясь в блокируюший режим.
- Полная развязка входного и выходного потоков возможна лишь в аллоцирующем варианте, достигается это, однако, за счет неконтролируемого потребления памяти и неконтролируемо большой задержки.
- Fixed_capacity позволяет добиться быстрой передачи данных одновременно ограничивая махимальную latency некоторым разумным пределом. Сама fixed_capacity очередь является по сути очень легковесной структурой. Главный минус — пишущие потоки блокируются если читаюшие не справляются или зависают по любой причине. Большие размеры буфера, на мой взгляд, нужны достаточно редко, они позволяют добиться переходной динамики, нечто приближающееся к аллоцируюшей очереди.
- Очень неприятным для меня сюрпризом оказалось то, какое большое негативное влияние оказывают непрерывно работаюшие вхолостую читающие потоки на динамику. Даже в случае когда общее число потоков <= CPU, добавление еще одного потребляющего 100% потока не улучшает, а ухудшает динамику. Похоже стратегия «больших серверов», когда каждому важному потоку присваевается отдельное ядро, работает далеко не всегда.
- В связи с этим, одна не упомянутая и до сих пор не решенная проблема — как эффективно использовать поток ожидающий какого либо события. Если его усыплять —
кармаlatency портится фатально, если использовать для других задач — возникает проблема быстрого переключения с задачи на задачу. Я думаю неплохим приближением к идеалу было бы дать возможность добавлять читающий поток в boost::io_service, так чтобы эффективно обслуживать хотя бы редкие события. Был бы рад услышать если у кого нибудь есть идеи.
Для тех кому надо - код
#include <boost/thread/thread.hpp>
#include <boost/lockfree/queue.hpp>
#include <time.h>
#include <atomic>
#include <iostream>
std::atomic<int> producer_count(0);
std::atomic<int> consumer_count(0);
std::atomic<unsigned long> push_fail_count(0);
std::atomic<unsigned long> pop_fail_count(0);
#if 1
boost::lockfree::queue<timespec, boost::lockfree::fixed_sized<true>> queue(65534);
#else
boost::lockfree::queue<timespec, boost::lockfree::fixed_sized<false>> queue(128);
#endif
unsigned stat_size=0, delay=0;
std::atomic<unsigned long>* stat=0;
std::atomic<int> idx(0);
void producer(unsigned iterations)
{
timespec t;
for (int i=0; i != iterations; ++i) {
++producer_count;
clock_gettime(CLOCK_MONOTONIC, &t);
while (!queue.push(t))
++push_fail_count;
if(delay) usleep(0);
}
}
boost::atomic<bool> done (false);
void consumer(unsigned iterations)
{
timespec t, v;
while (!done) {
while (queue.pop(t)) {
++consumer_count;
clock_gettime(CLOCK_MONOTONIC, &v);
unsigned i=idx++;
v.tv_sec-=t.tv_sec;
v.tv_nsec-=t.tv_nsec;
stat[i]=v.tv_sec*1000000000+v.tv_nsec;
}
++pop_fail_count;
}
while (queue.pop(t)) {
++consumer_count;
clock_gettime(CLOCK_MONOTONIC, &v);
unsigned i=idx++;
v.tv_sec-=t.tv_sec;
v.tv_nsec-=t.tv_nsec;
stat[i]=v.tv_sec*1000000000+v.tv_nsec;
}
}
int main(int argc, char* argv[])
{
boost::thread_group producer_threads, consumer_threads;
int indexed=0, quiet=0;
int producer_thread=1, consumer_thread=1;
int opt;
while((opt=getopt(argc,argv,"idqr:w:")) !=-1)
switch(opt) {
case 'r': consumer_thread=atol(optarg); break;
case 'w': producer_thread=atol(optarg); break;
case 'd': delay=1; break;
case 'i': indexed=1; break;
case 'q': quiet=1; break;
default : return 1;
}
int iterations=6000000/producer_thread/consumer_thread;
unsigned stat_size=iterations*producer_thread*consumer_thread;
stat=new std::atomic<unsigned long>[stat_size];
timespec st, fn;
clock_gettime(CLOCK_MONOTONIC, &st);
for (int i=0; i != producer_thread; ++i)
producer_threads.create_thread([=](){ producer(stat_size/producer_thread); });
for (int i=0; i != consumer_thread; ++i)
consumer_threads.create_thread([=]() { consumer(stat_size/consumer_thread); });
producer_threads.join_all();
done=true;
consumer_threads.join_all();
clock_gettime(CLOCK_MONOTONIC, &fn);
std::cerr << "threads : " << producer_thread <<" write, "
<< consumer_thread << " read" << std::endl;
std::cerr << "failed : " << push_fail_count << " pushes, "
<< pop_fail_count << " pops" << std::endl;
fn.tv_sec-=st.tv_sec;
fn.tv_nsec-=st.tv_nsec;
std::cerr << "bandwidth: " << (fn.tv_sec*1e9+fn.tv_nsec)/stat_size << " ns"<< std::endl;
double ct=0;
for(auto i=0; i < stat_size; ++i)
ct+=stat[i];
std::cerr << "latency : "<< ct/stat_size << " ns"<< std::endl;
if(!quiet) {
if(indexed) for(auto i=0; i < stat_size; ++i)
std::cout<<i<<" "<<stat[i]<<std::endl;
else for(auto i=0; i < stat_size; ++i)
std::cout<<stat[i]<<std::endl;
}
return 0;
}
