Дополнение от 23.01.14. Эта статья была написана 30-го декабря минувшего года. Выдача с тех пор изменилась, однако по большому счету приведенная информация актуальна. За прошедшее время появились еще кое-какие данные, однако их, с одной стороны, слишком много для того, чтобы расширить эту статью — и слишком мало для новой с другой. Если пост вызовет интерес сообщества, вполне вероятно, что после накопления информации будет продолжение, связанное с характерными особенностями не упомянутых тут факторов.
Предупреждение. Нижеследующее не следует воспринимать как точную информацию — это только догадка, подтвержденная эмпирически.
Предупреждение 2. Возможно, эта информация — новость только в моем «болоте», но поиск по сети не дал результатов, сколько-нибудь похожих на эти выводы.
Все, более-менее имеющие отношение к интернету, знают, какой хай поднялся, когда Яндекс заявил, что отказывается от ссылочного в НГ.
С одной стороны, жить станет легче — без поискового мусора мир будет немного чище, с другой — непонятно, как это реализуют и по кому это ударит (ну, кроме копирайтеров-оптимизаторов и прочей братии, конечно, но и фиг бы с ними).
Поскольку я занимаюсь, помимо прочего, и рекламой в Сети, я начал с напряжением поглядывать на позиции сайтов моих клиентов, а заодно и конкурентов. Результаты выдачи к праздникам становились все страньше и страньше. Очевидно, нессылочные факторы потихоньку усиливались — и потому выдача по некоторым запросам стала довольно необычной.
Я попытался понять логику алгоритма и, похоже, это частично удалось. Хотя, если мои предположения верны, многих, зависящих от продаж через сеть, прямо скажем, ждут тяжелые времена.
Да и пользователям будет не легче.
Тем, кто торопится: краткое резюме есть в конце статьи.
Остальным же предлагаю полностью проследить ход мысли и поправить ошибки, которые я, возможно, допустил.
Меня заинтересовал запрос «ремонт остекления», с которым связаны услуги некоторых фирм, с которыми я сотрудничаю.
Результаты по нему через анонимный заход такие:

Надо сказать, данные вызвали удивление. Поясняю. Обратите внимание на характер сайтов в выдаче. На первые 12 мест приходится 9 штук лоджий-балконов. При «старом режиме» за данный запрос как правило дрались крупные компании, занимающиеся корпоративными заказами типа ремонта остекления фасада здания. Так уж сложилось, что запрос этот был релевантен именно для b2b, и основная процентовка пользователей, судя по практике, была именно из этой области. Для частников этот запрос был не слишком характерен. Они обычно формулировали свой запрос более четко — ведь у них был конкретный балкон, а не «остекление»
Статистика запросов в директе такова (тут от анонимности пришлось отказаться — нужен логин):

Как вы можете видеть, у большинства фигурирует просто «остекление» как объект. Впрочем, когда я вглядывался в результаты, меня посетила…
Обратите внимание: слово «остекление» может восприниматься в русском языке двояко. С одной стороны, это слово может обозначать объект. «Остекление» на профессиональном жаргоне строителей — это остекление всего здания в совокупности. С другой стороны, словосочетание «ремонт остекления» может восприниматься как незавершенная фраза.
А ведь задача поисковика — найти то, что хочет пользователь! Большинство уточнивших запрос захотело именно балконы/лоджии. Может, именно поэтому эта тематика вылезла наверх? Возможно ли, чтобы при поиске происходило «скрытое» уточнение запроса аналогичное строке подсказки популярных запросов?
То бишь, возможен ли такой механизм: яндекс достраивает запрос «в уме» и исходя из ожиданий строит выдачу?
Следовало проверить. Для этого мне понадобился такой же «неоконченный» запрос.
Пусть это будет «купить шампанское». Директ сообщил следующее:

Обратите внимание — запросы от конечных потребителей задают тон — разбитые по маркам, однако желающие одного и того же. Но значительная часть (хотя и не большинство!) пользователей интересуется оптом.
Что у нас в поиске? А вот что:

4 и 12 места взял опт, несмотря на то, что большинству пользователей, судя по запросам, он малоинтересен, однако число уточняющих запросов велико.
Бинго?..
Однако тут же нашелся контраргумент: запрос «ремонт механизма».
Директ:

Выдача:

Отношение диванов к авто в первой дюжине выдаче: пять к пяти.
Если подсчитать ту мебельную тематику в директе, что не влезла в скриншот, диванов будет, конечно, побольше, это останется второй по популярности тематикой, однако на соотношение один к одному это все равно не тянет!
Почему?
Предположения следующие:
1) Начинают работать те факторы «юзабилити», ПФ и прочие, о которых так долго говорили большевики, то есть Яндекс. Ярко выраженная направленность на работу через сеть «мебельных» сайтов бросается в глаза. Точно так же в запросе «ядовитая железа» в Яндексе лидирует энциклопедия по WoW, а вовсе не справочники по биологии!
2) Неоднородность «автомобильных» и «технических» запросов относительно мебельных. Там все хотят диван, а тут то камаз, то руль, то передача.
3) Предположение, возможно, слишком наглое, но существует и такая вероятность, причем большая: страницы, отвечающие на «автомобильные» запросы — не обязательно коммерческие. Более того, зачастую это информационные материалы — случается, правда, что размещены они на сайтах коммерческих, но выдающих себя за информационные. В то же время выдача по мебели носит ярко выраженный коммерческий характер. Случайность? Возможно, что это действует «юзабилити» (что это значит с точки зрения Яндекса — загадка), которое у коммерческих сайтов повыше, чем у информационных. Но возможно, что и нет. Я не смог составить точного мнения по этому вопросу — пока набрана слишком малая статистика.
Дальнейшие проверки различных запросов более-менее привели теорию к единому виду. Итак…
1) Топ выдачи Яндекса формируется с учетом того, что искали вместе с этими словами (запросом, то бишь) ранее. Позиции и количество представленных тематик в топе выдачи коррелируют с данной характеристикой, хотя точную зависимость установить невозможно — работают и иные факторы.
2) Одним из этих факторов, возможно (?), является коммерческая/информационная направленность сайта — возможно, в пользу первой, однако информации для однозначного вывода пока недостаточно.
3) Популярность тематики кроет логику — по запросу «ядовитая железа» энциклопедия по вовке выше словарей и энциклопедий IRL-ых. Кроме того, популярность тематики важнее популярности запроса — «ядовитая железа смертеплета» запрос непопулярный, судя по директу.
4) У вышеперечисленного есть как плюсы, так и минусы с точки зрения ищущего и владельца сайта. Минусов ИМХО больше.
Плюсы:
С точки зрения владельца:
Часть аудитории, проходившая мимо из-за неточного запроса, придет к нему.
С точки зрения пользователя:
Неполный или неоднозначный запрос имеет неплохой шанс дать нужную инфу
Минусы:
С точки зрения пользователя:
При неоднозначном запросе, как, например «ремонт остекления», где «остекление» может рассматриваться и как отдельное слово и начало словосочетания, он имеет шансы получить инфу, интересную не ему, а большинству, причем весьма условному большинству, рассчитанному неверно, на основе уточняющих запросов тех, для кого это начало выражения (а настоящему большинству и уточнять в голову не придет, для них это законченная фраза!).
Для владельца сайта:
Если речь в описанном выше случае идет о низкочастотниках, за счет которых компания только и живет (как многие в сфере b2b), это может очень серьезно ударить по потоку клиентов из Инета. Получается двойная конкуренция — как с сайтами релевантной тематики, так и нерелевантной, притом на заведомо неравных условиях: войти в тройку или семерку — большая разница. При «старом режиме» этот риск компенсировался ссылочным (работало правильное словоупотребление на ссылающихся сайтах), но в его отсутствии получается настоящее вавилонское смешение, с очень малыми шансами добраться до своих пользователей.
Убьет ли это Яндекс? Нет. Сделает ли его лучше? Тоже нет.
Я надеюсь, что изложенные в этой попытке исследования нессылочных факторов ранжирования Яндекса сведения были если и не полезны, то увлекательны (наивно, да?).
Введение
Предупреждение. Нижеследующее не следует воспринимать как точную информацию — это только догадка, подтвержденная эмпирически.
Предупреждение 2. Возможно, эта информация — новость только в моем «болоте», но поиск по сети не дал результатов, сколько-нибудь похожих на эти выводы.
Все, более-менее имеющие отношение к интернету, знают, какой хай поднялся, когда Яндекс заявил, что отказывается от ссылочного в НГ.
С одной стороны, жить станет легче — без поискового мусора мир будет немного чище, с другой — непонятно, как это реализуют и по кому это ударит (ну, кроме копирайтеров-оптимизаторов и прочей братии, конечно, но и фиг бы с ними).
Поскольку я занимаюсь, помимо прочего, и рекламой в Сети, я начал с напряжением поглядывать на позиции сайтов моих клиентов, а заодно и конкурентов. Результаты выдачи к праздникам становились все страньше и страньше. Очевидно, нессылочные факторы потихоньку усиливались — и потому выдача по некоторым запросам стала довольно необычной.
Я попытался понять логику алгоритма и, похоже, это частично удалось. Хотя, если мои предположения верны, многих, зависящих от продаж через сеть, прямо скажем, ждут тяжелые времена.
Да и пользователям будет не легче.
Тем, кто торопится: краткое резюме есть в конце статьи.
Остальным же предлагаю полностью проследить ход мысли и поправить ошибки, которые я, возможно, допустил.
Постановка задачи
Меня заинтересовал запрос «ремонт остекления», с которым связаны услуги некоторых фирм, с которыми я сотрудничаю.
Результаты по нему через анонимный заход такие:
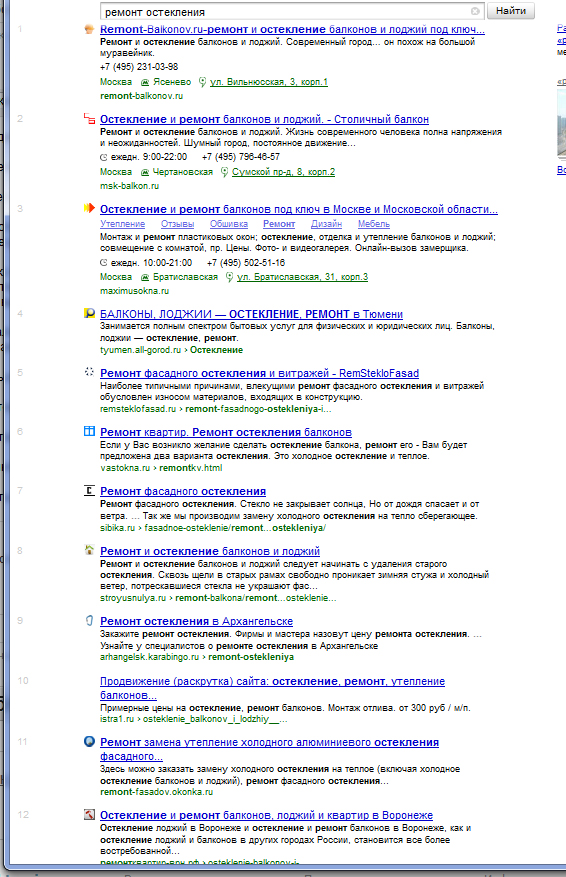
Надо сказать, данные вызвали удивление. Поясняю. Обратите внимание на характер сайтов в выдаче. На первые 12 мест приходится 9 штук лоджий-балконов. При «старом режиме» за данный запрос как правило дрались крупные компании, занимающиеся корпоративными заказами типа ремонта остекления фасада здания. Так уж сложилось, что запрос этот был релевантен именно для b2b, и основная процентовка пользователей, судя по практике, была именно из этой области. Для частников этот запрос был не слишком характерен. Они обычно формулировали свой запрос более четко — ведь у них был конкретный балкон, а не «остекление»
Статистика запросов в директе такова (тут от анонимности пришлось отказаться — нужен логин):
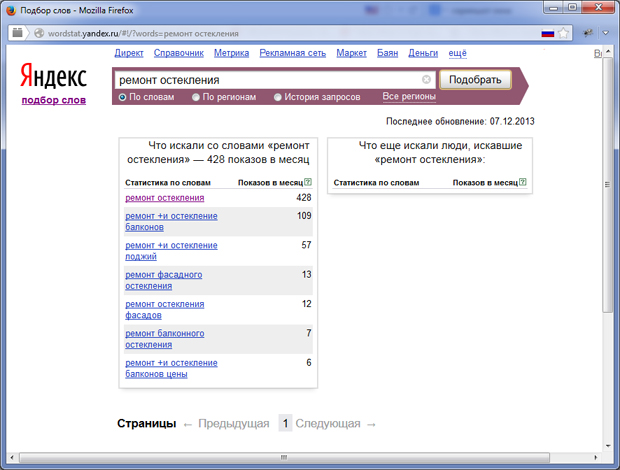
Как вы можете видеть, у большинства фигурирует просто «остекление» как объект. Впрочем, когда я вглядывался в результаты, меня посетила…
Догадка
Обратите внимание: слово «остекление» может восприниматься в русском языке двояко. С одной стороны, это слово может обозначать объект. «Остекление» на профессиональном жаргоне строителей — это остекление всего здания в совокупности. С другой стороны, словосочетание «ремонт остекления» может восприниматься как незавершенная фраза.
А ведь задача поисковика — найти то, что хочет пользователь! Большинство уточнивших запрос захотело именно балконы/лоджии. Может, именно поэтому эта тематика вылезла наверх? Возможно ли, чтобы при поиске происходило «скрытое» уточнение запроса аналогичное строке подсказки популярных запросов?
То бишь, возможен ли такой механизм: яндекс достраивает запрос «в уме» и исходя из ожиданий строит выдачу?
Следовало проверить. Для этого мне понадобился такой же «неоконченный» запрос.
Проверка
Пусть это будет «купить шампанское». Директ сообщил следующее:

Обратите внимание — запросы от конечных потребителей задают тон — разбитые по маркам, однако желающие одного и того же. Но значительная часть (хотя и не большинство!) пользователей интересуется оптом.
Что у нас в поиске? А вот что:

4 и 12 места взял опт, несмотря на то, что большинству пользователей, судя по запросам, он малоинтересен, однако число уточняющих запросов велико.
Бинго?..
Облом
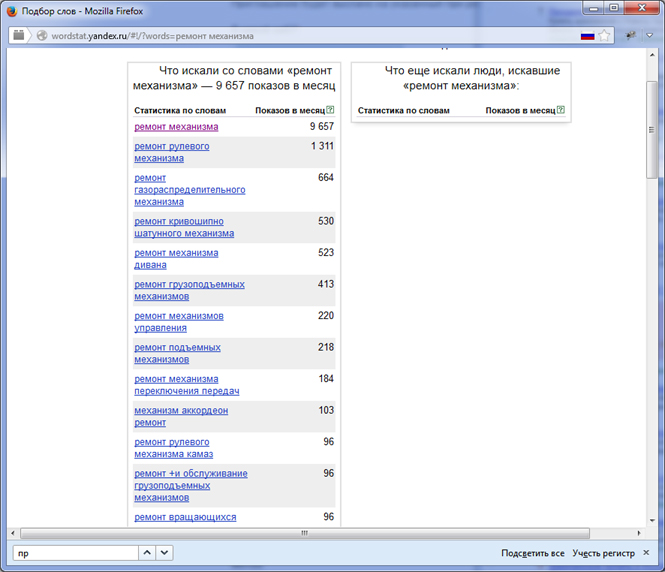
Однако тут же нашелся контраргумент: запрос «ремонт механизма».
Директ:
Выдача:
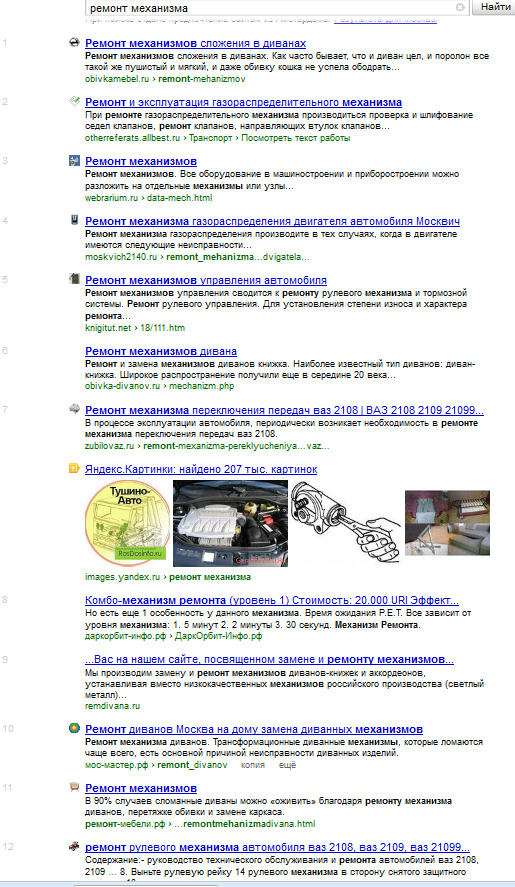
Отношение диванов к авто в первой дюжине выдаче: пять к пяти.
Если подсчитать ту мебельную тематику в директе, что не влезла в скриншот, диванов будет, конечно, побольше, это останется второй по популярности тематикой, однако на соотношение один к одному это все равно не тянет!
Почему?
Уточнение гипотезы
Предположения следующие:
1) Начинают работать те факторы «юзабилити», ПФ и прочие, о которых так долго говорили большевики, то есть Яндекс. Ярко выраженная направленность на работу через сеть «мебельных» сайтов бросается в глаза. Точно так же в запросе «ядовитая железа» в Яндексе лидирует энциклопедия по WoW, а вовсе не справочники по биологии!
2) Неоднородность «автомобильных» и «технических» запросов относительно мебельных. Там все хотят диван, а тут то камаз, то руль, то передача.
3) Предположение, возможно, слишком наглое, но существует и такая вероятность, причем большая: страницы, отвечающие на «автомобильные» запросы — не обязательно коммерческие. Более того, зачастую это информационные материалы — случается, правда, что размещены они на сайтах коммерческих, но выдающих себя за информационные. В то же время выдача по мебели носит ярко выраженный коммерческий характер. Случайность? Возможно, что это действует «юзабилити» (что это значит с точки зрения Яндекса — загадка), которое у коммерческих сайтов повыше, чем у информационных. Но возможно, что и нет. Я не смог составить точного мнения по этому вопросу — пока набрана слишком малая статистика.
Дальнейшие проверки различных запросов более-менее привели теорию к единому виду. Итак…
Выводы:
1) Топ выдачи Яндекса формируется с учетом того, что искали вместе с этими словами (запросом, то бишь) ранее. Позиции и количество представленных тематик в топе выдачи коррелируют с данной характеристикой, хотя точную зависимость установить невозможно — работают и иные факторы.
2) Одним из этих факторов, возможно (?), является коммерческая/информационная направленность сайта — возможно, в пользу первой, однако информации для однозначного вывода пока недостаточно.
3) Популярность тематики кроет логику — по запросу «ядовитая железа» энциклопедия по вовке выше словарей и энциклопедий IRL-ых. Кроме того, популярность тематики важнее популярности запроса — «ядовитая железа смертеплета» запрос непопулярный, судя по директу.
4) У вышеперечисленного есть как плюсы, так и минусы с точки зрения ищущего и владельца сайта. Минусов ИМХО больше.
Плюсы:
С точки зрения владельца:
Часть аудитории, проходившая мимо из-за неточного запроса, придет к нему.
С точки зрения пользователя:
Неполный или неоднозначный запрос имеет неплохой шанс дать нужную инфу
Минусы:
С точки зрения пользователя:
При неоднозначном запросе, как, например «ремонт остекления», где «остекление» может рассматриваться и как отдельное слово и начало словосочетания, он имеет шансы получить инфу, интересную не ему, а большинству, причем весьма условному большинству, рассчитанному неверно, на основе уточняющих запросов тех, для кого это начало выражения (а настоящему большинству и уточнять в голову не придет, для них это законченная фраза!).
Для владельца сайта:
Если речь в описанном выше случае идет о низкочастотниках, за счет которых компания только и живет (как многие в сфере b2b), это может очень серьезно ударить по потоку клиентов из Инета. Получается двойная конкуренция — как с сайтами релевантной тематики, так и нерелевантной, притом на заведомо неравных условиях: войти в тройку или семерку — большая разница. При «старом режиме» этот риск компенсировался ссылочным (работало правильное словоупотребление на ссылающихся сайтах), но в его отсутствии получается настоящее вавилонское смешение, с очень малыми шансами добраться до своих пользователей.
Заключение
Убьет ли это Яндекс? Нет. Сделает ли его лучше? Тоже нет.
Я надеюсь, что изложенные в этой попытке исследования нессылочных факторов ранжирования Яндекса сведения были если и не полезны, то увлекательны (наивно, да?).
