 Когда-то я вылез из песочницы с совочком в руке и постом о неблокирующих очередях и передаче данных между потоками. Тот пост был не столько об алгоритмах и их реализации, сколько об измерении быстродействия. Тогда же мне в комментариях задали совершенно резонный вопрос об обычных, блокирующих алгоритмах передачи — насколько они медленнее и вообще как выбрать оптимальный алгоритм под конкретную задачу.
Когда-то я вылез из песочницы с совочком в руке и постом о неблокирующих очередях и передаче данных между потоками. Тот пост был не столько об алгоритмах и их реализации, сколько об измерении быстродействия. Тогда же мне в комментариях задали совершенно резонный вопрос об обычных, блокирующих алгоритмах передачи — насколько они медленнее и вообще как выбрать оптимальный алгоритм под конкретную задачу.Я конечно обещал и с энтузиазмом принялся за дело, даже получил забавные результаты, однако… какой-то изюминки не хватало, выходило скучно и плоско. В результате мой внутренний перфекционист обьединился с моим нескрываемым прокрастинатором и вдвоем они меня одолели, пост надолго осел в черновиках и даже совесть уже не вздрагивала при виде забытого заголовка.
Однако все меняется, появляются новые технологии, старые исчезают в архивах, и я вдруг решил что пришло время отдавать долги и сдерживать обещания. В качестве наказания мне пришлось все переписать с нуля, если скупой платит дважды, то ленивый дважды переделывает, так мне и надо.
Да, за КДПВ извиняюсь — оно конечно совсем из другой предметной области, но для иллюстрации взаимодействия между потоками подходит тем не менее идеально.
Так что же разбудило Герцена?
Подтолкнулo меня к действию знакомство с
языком D
— чрезвычайно концептуально красивым языком, унаследовавшим и мощно двинувшим вперед идиомы C++ и при этом сохранившим эффективные низкоуровневые инструменты, вплоть до указателей. Возможно из-за этого на мой взгляд в стандартной библиотеке D есть некоторая раздвоенность — большинство функционала можно вызвать или из коробки, простым и легким способом, или через приближенный к нативному интерфейс, зато полностью используя ресурсы и возможности системы. Если C++ перекрывает непрерывным спектром весь диапазон, то в D обычно хорошо заметно такое разделение. Посмотрите сами: нужно измерить интервал времени, есть замечательный модуль std.datetime, однако квант измерения — 100 нс, что мне совершенно недостаточно, пожалуйста — есть не менее замечательный модуль — core.time. Не устраивает облегченный до предела яваподобный std.concurrency.spawn — можете использовать весь букет из core.thread. И так практически везде, за исключением одного, но чрезвычайно важного места — разделения данных между потоками. Да, да, все локальные для данного потока переменные размещаются в thread local storage и никакими силами нельзя заставить другой поток увидеть их адрес. А для обмена данными предусмотрены встроенные очереди, надо признать очень удобные — полиморфные, с возможностью внеочередной посылки важных сообщений и чрезвычайно приятным интерфейсом. Посылать данные через них можно естественно или by value, или неизменяемые (immutable) ссылки. Я, когда об этом прочитал первый раз, просто подпрыгнул от возмущения — «Да как же рука ваша поганая поднялась...» — а потом задумался, припомнил свои проекты за последние годы и признал — да, весь обмен между потоками проходит по такой схеме, а то что не проходит — явная ошибка дизайна.не надо продолжать аналогию, я вовсе не хотел сказать что он страшно далек от народа
И тем не менее вопрос повис в воздухе — насколько эффективны очереди в D? Если нет, то это сводит на нет всю прочую эффективность языка, этакое встроенное бутылочное горлышко. Вот так я проснулся и снова взялся за измерения.
Что же конкретно мы будем мерить?
Вопрос на самом деле непростой, я об этом писал и в прошлый раз и пожалуй повторюсь. Обычный «наивный» подход, когда посылают N сообщений, замеряют общее время и делят на N не работает. Давайте разберемся, мы меряем производительность очереди, так? Следовательно можно считать что в процессе измерения скорость генератора сообщений и приемника сообщений стремится к бесконечности, при разумном предположении что внутри очереди данные не копируются, оказывается выгодным поместить как можно больше данных в очередь, потом выполнить однократную передачу некоторого внутреннего указателя и все, данные уже там. При этом среднее время на сообщение будет падать как 1/N (на самом деле ограничено снизу временем вставки/удаления, которое может составлять единицы наносекунд) тогда как время доставки каждого сообщения в теории остается постоянным, и даже растет как O(N) на практике.
Вместо этого я использую противоположный подход — каждое сообщение посылается, замеряется время и только потом посылается следующее (latency). Как следствие, результаты представляются в виде гистограмм, по оси X — время, по оси Y — число пакетов доставленных за это время. Наиболее интересны численно два параметра — медианное среднее время распределения и процент сообщений не уложившихся в некоторый (произвольный) верхний предел.
Строго говоря, такой подход тоже не вполне адекватен, тем не менее он гораздо точнее описывает требования к быстродействию. Я немножко позанимаюсь самокритикой в заключении, пока только скажу что полное описание включало бы генерацию всех возможных видов трафика и анализ его статистическими методами, получилась бы полноценная научная работа из области теории QA, или скорее меня бы настиг очередной приступ прокрастинации.
Еще один момент, упоминаю об этом потому что прошлый раз были долгие дебаты, генератор сообщений может вставлять их в очередь сколь угодно быстро, но при условии что получатель в среднем успевает их извлекать и обрабатывать, иначе все измерение просто лишено смысла. Если ваш принимающий поток не успевает обрабатывать поток данных, надо сделать код быстрее, распараллелить обработку, изменить протокол сообщений, но в любом случае сама очередь здесь не причем. Вроде бы мысль простая, однако прошлый раз пришлось повторять несколько раз в комментариях. Флуктуации скорости, когда вдруг в очереди оказывается много сообщений, вполне возможны и даже неизбежны, это как раз один из факторов который хорошо спроектированный алгоритм должен сглаживать, но это возможно только если максимальная скорость приема больше средней скорости посылки.
Начнем-с
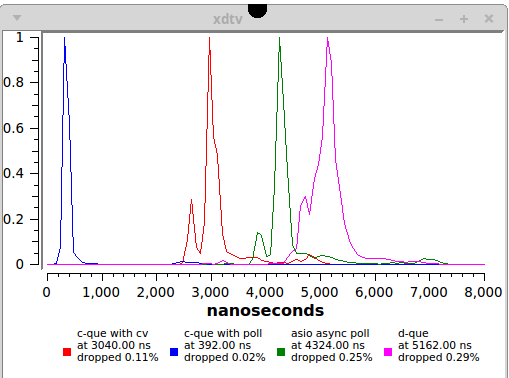
Это что? А это собственно результат, все мои труды уложились в одну картинку, зато я сейчас буду долго обьяснять что и зачем здесь нарисовано.
Розовый. Стандартный механизм D
5 микросекунд, это много или мало? Практически во всех случаях это мало (то есть это очень хорошо). Для подавляющего большинства реальных проектов это более чем достаточное быстродействие, более того, еще не так давно такое время передачи можно было получить только при помощи специального железа и/или очень специального софта. Здесь же мы имеем инструмент из стандартной библиотеки, со множеством других вкусных плюшек и достаточно быстрый для всех практических нужд. Оценка — отлично. Но однако не великолепно, потому что этой реализации присущи некоторые недостатки не связанные с быстродействием, я расскажу об этом в ругательной части.
Еще раз с удовольствием убеждаемся что главная магия программирования — в отсутствии какой-либо магии. Если залезть под капот (разумеется я не мог не заглянуть), увидим что код совершенно обычный — односвязные списки защищенные мьютексами. Я даже не стану здесь его приводить потому что в смысле реализации очереди он ничего нового нам не скажет. Зато те немногие кому действительно нужны более быстрые алгоритмы, включая неблокирующие, могут легко написать свой собственный вариант убрав все удобные но замедляющие плюшки. Зато свой код я приведу, просто чтобы показать насколько D все таки лаконичный и выразительный язык.
код для иллюстрации
import std.stdio, std.concurrency, std.datetime, core.thread;
void main()
{
immutable int N=1000000;
auto tid=spawn(&f, N);
foreach(i; 0..N) {
tid.send(thisTid, MonoTime.currTime.ticks);
// wait for receiver to handle message
receiveOnly!int();
}
}
void f(int n)
{
foreach(i; 0..n) {
auto m=receiveOnly!(Tid,long)();
writeln(MonoTime.currTime.ticks-m[1]);
// ask for the next message
m[0].send(0);
}
}
Синий. Лютый и неприкрытый C++.
400 наносекунд! Бинго! Побоку все неблокирующие и прочие хитрые алгоритмы! Или все таки нет?
Нет конечно, это грубая провокация, дело в том что в этом варианте читающий поток никогда не засыпает, продолжает в цикле непрерывно проверять очередь на пришедшие сообщения. Такой вариант работает пока вашим CPU просто нечем больше заняться, как только только появляются конкурирующие процессы, особенно если они так же безалаберно относятся к разделяемым ресурсам, все начинает непредсказуемо проскальзывать. Да, есть вариант с принудительным назначением одного из ядер для обслуживания этого потока, однако архитектурно это очень плохое решение, я вернусь к этому попозже. Есть места где это оправданно или даже необходимо, однако если вы в таком месте работаете, вы наверняка уже все сами знаете, для вас этот пост совершенно лишний.
Однако мы получили важную информацию — на современных системах скорость транзакций определяется вовсе не скоростью мьютексов или копирования данных, главный фактор — wake up time для потока после вынужденной или добровольной паузы. Отсюда мораль — если вы не хотите или не можете себе позволить dedicated CPU для обработки сообщений из очереди, подумайте дважды прежде чем использовать быстрые и сложные но неудобные в использовании решения, потери на подстраивание под них архитектуры приложения почти стопроцентно перевесят тот незначительный выигрыш, который вносит сам алгоритм во время транзакции. И, да, здесь я имею ввиду
boost::lockfree
это образцовый пример реализации неблокирующей очереди, однако тип сообщения обязан иметь тривиальные деструктор и оператор присваивания, условие настолько жестокое для C++ что я собственно так ни разу и не довел код до конечного продукта.
Так что же можно сделать оставаясь в рамках разумного?
Красный. Разумный и взвешенный C++.
Если кому-то пришел на ум usleep() и ему подобные — забудьте, вы гарантированно увеличиваете время отклика до минимум 40 микросекунд, это лучшее что современное ядро может гарантировать. Немногим лучше yield(), он, хотя и неплохо работает на малых загрузках, имеет тенденцию делиться процессорным временем с кем попало.
Это все из-за котиков разумеется
Выход один и он очевиден — использовать std::condition_variable, благо что мьютексы для синхронизации у нас уже используются и изменения в коде будут минимальными. В таком варианте получатель засыпает на переменной если очередь пуста, а генератор сообщений посылает сигнал если подозревает что партнер может спать. В этом случае ядро имеет все возможности для оптимизации и мы получаем результат, 3 микросекунды. Это уже можно сказать что ого, мы наступаем буквально на пятки всяким хитрым реализациям, при этом базовый код крайне прост и его можно адаптировать под все случаи жизни. Никакой полиморфизм здесь конечно и не ночевал как в D, зато и получилось почти в два раза быстрее. Без шуток, это вполне реальный конкурент неблокирующим алгоритмам.Опыт показывает, что на каждом сервере имеется хотя бы один процесс отрисовывающий в данный момент котиков, и он не отдаст CPU никому пока все котики в инете не будут тщательно отрисованы и залайканы
Зеленый. Мастштабируемость, масштабируемость.
А это архитектурное решение которое я долго искал и вынашивал, хотя результат выглядит крайне просто. Часто спрашивают, сколько максимально сообщений в секунду можно передать через очередь и тому подобные вещи, забывая что противоположная ситуация случается не менее часто — пусть у нас имеется некоторое количество потоков, которые занимаются своим делом и время от времени должны посылать сообщения, не слишком часто, но важных. Мы не хотим на каждый такой поток вешать отдельного слушателя, который все равно будет по большей части спать, значит придется создать один общий центр обработки, который будет опрашивать все очереди и обслуживать сообщения по мере поступления. Но поскольку у нас сегодня не вечер длинного кода, а вечер коротких концептуальных фрагментов, я предлагаю использовать boost::asio, в качестве огромного бонуса этот же поток может обслуживать еще и сокеты и таймеры. Здесь, кстати, можно было бы легко обойтись вообще без очереди, захватывая данные прямо в передаваемой функции, очередь служит скорее как агрегатор и буфер для данных, ну и для смысловой связки с предыдущими примерами.
И что же мы получаем? 4.3 микросекунды на процессе из только одного генератора, совсем даже неплохо. Надо учитывать что результат неизбежно ухудшится в системе где много потоков одновременно пишут сообщения, однако масштабируемость практически ничем неограничена и это многого стоит.
Еще раз хочу подчеркнуть в чем философский смысл этого фрагмента — мы пересылаем в другой поток не просто данные, а данные плюс функтор, который сам знает как с ними работать, что-то вроде межпоточной виртуальности. Это настолько общая концепция, что могла бы наверное претендовать на звание отдельного design pattern.
На этом экспериментальная часть заканчивается, если нужен код всех тестов то вот он. Осторожно, это не готовая библиотека, так что бездумно копировать не советую, однако может служить вполне годным тьюториалом для разработки своего кода. Дополнения и улучшения приветствуются.
Разные рассуждения, по делу и не очень.
Зачем вообще нужны очереди сообщений? Как нас учит пример D, это самый кошерный паттерн для проектирования многопоточных систем, за которыми будущее, значит будущее и за очередями тоже. Но все ли очереди одинаковы? Какие есть варианты и в чем различия? Вот об этом и поговорим.
Во первых нужно различать потоки данных и потоки сообщений. С потоками данных все сравнительно просто, каждый переданный фрагмент не несет смысловой нагрузки и границы между фрагментами достаточно произвольны. Расходы на копирование сравнимы или превосходят ресурсы потребляемые собственно очередью и рецепт в этом случае крайне простой — увеличивайте внутренний буфер насколько можно, получите просто невероятную скорость. Квант данных, большой файл например, можно считать одним сообщением, настолько большим что оно чисто технически не может быть передано за один раз. Ну и все, больше об этом сказать наверное и нечего. А вот в потоке сообщений каждый следующий фрагмент несет законченную порцию информации и должен вызвать немедленную реакцию, о них-то мы сегодня и говорим.
Еще бывает полезно проанализировать архитектуру с точки зрения связности, что с чем соединяется. Простейший тип -«труба», соединяет два потока, писателя и читателя, его главное назначение — обеспечить развязку входного и выходного потоков, в идеале ни один из них не должен знать о проблемах другого. Второй атомарный тип очереди — «воронка», куда произвольное количество потоков могут писать, но только один читает. Это наверное наиболее востребованный случай, простейший пример — логгер. И вообще-то это все, обратный случай, когда один поток пишет и несколько читают, реализуется с помощью пучка «труб» и поэтому не является атомарным, а если вам вдруг понадобилась очередь куда кто угодно может писать и кто угодно из нее читать то я очень посоветовал бы пересмотреть свое отношение к жизни вообще и к проектирования многопоточных систем в частности.
Возвращаясь к развязке входного и выходного потоков, отсюда неизбежно следует вывод что идеальная очередь должна быть безразмерной, то есть при необходимости вмещать в себя бесконечно много сообщений. Простой пример: пусть крайне важный и ответственный поток хочет записать коротенькое сообщение в лог и вернуться к своим крайне важным делам. Однако лог у нас построен на основе очереди с буфером фиксированного размера, и вот только что кто-то скинул туда «Войну и мир» в полном объеме. Что делать? Блокировать вызывающий поток такая низкоприоритетная задача как логгер не должна, возвращать ошибку или исключение — крайне нежелательно с архитектурной точки зрения (мы перекладываем ответственность на вызывающую функцию, мы обязуем ее отслеживать все возможные исходы, мы крайне усложняем вызывающий код и вероятность ошибки, а взамен не получаем ничего — что делать-то все равно не ясно). И вообще, к чему были все эти разговоры о неблокирующих очередях, если оно вот прямо тут на наших глазах заблокированное лежит?. Именно поэтому я уже упоминал что стандартные очереди D не являются универсальным решением для межпоточного взаимодействия, более того, неблокирующий boost::lockfree::queue в одном из вариантов тоже использует фиксированный буфер и не является на самом деле неблокирующей очередью, хотя и использует неблокирующий алгоритм.
К счастью, оперативная память нынче — один из самых дешевых ресурсов, поэтому видимо самой оптимальной среди универсальных будет адаптивная стратегия — память при необходимости выделяется из кучи (большими кусками
Ну и последнее — статистическая природа трафика. Про отличие передачи данных и передачи сообщений я уже говорил, но сообщения тоже могут иметь разное по времени распределение. Как ни странно, наиболее легкий случай если данные приходят максимально быстро (но не быстрее чем мы их успеваем из очереди вынимать), но при этом равномерно. При этом максимально эффективно работают различные ускорители, от спинлоков до встроенных в систему средств. Сложнее случай когда в потоке сообщений происходят мощные всплески, которые гарантированно превосходят скорость обработки. В этом режиме очередь должна эффективно накапливать приходящие сообщения, выделяя при необходимости память и не допуская при этом значительного замедления.
Именно тут я смухлевал
Однако самый возможно тяжелый режим — когда сообщения приходят очень редко, но требуют немедленной реакции. За такое время может произойти что угодно, включая выпадение в своп. Если при нормальном распределении интервалов такие события случаются редко и попадают в те доли процента которые мы отбросили в тестах, то в этом случае эффективность может упасть на порядки. в тестах, сообщения посылаются строго по одному и я никак не исследовал ни поведение очередей D при блокировке на записи, ни поведение C очередей при необходимости аллоцировать память. Еще я никак не исследовал взаимное влияние и борьбу за ресурсы нескольких потоков, особенно когда их становится больше чем физических CPU. По обьему это легко тянет на отдельный пост.
Неполный список граблей в ассортименте.
- Соблюдайте баланс записи и чтения: если читающий поток не справляется, никакой алгоритм вас не спасет. Делайте что хотите чтобы его ускорить, только очередь в этом не вините.
- Кумулятивное замедление: бывает что для некоторых реализаций скорость очереди зависит от числа сообщений в ней, тогда случайный всплеск активности может замедлить очередь настолько, что она не освободится до следующего всплеска, примерно как затор на дороге. Такую неустойчивость довольно сложно смоделировать при тестировании.
- Синдром ночного сторожа: иногда сообщения приходят очень редко, раз в час или даже раз в день, с точки зрения ОС это все равно вечность. Если сторож на посту сидит и ждет сигнала тревоги, а сигнала ни разу не было за всю его жизнь, чем он будет занят в критический момент? С таким спонтанным засыпанием трудно бороться.
- Учитывайте хвост распределения: в приведенных тестах 2-3 сообщения на 1000 обрабатывались аномально долго, это общая черта для всех ОС общего назначения. Если вам вдруг надо еще понизить это число, придется крепко потрудиться.
- Не рассчитывайте на выделенные CPU: это мощный ускоряющий фактор, но абсолютно не масштабируемый. В отличие от памяти, CPU — дорогой ресурс. Даже если в вашей системе 100500 ядер, обязательно найдется 100500+1 разработчиков желающих себе одно в личное пользование.Тот самый ПМ который год назад сам предлагал зарезервировать ядро на ускорение очередей теперь заглянет в душу честными голубыми глазами и скажет — «Ко мне тут ребята из фронтенда приходили, у них на главной странице логотип компании некрасивыми рывками перерисовывается. Просят выделить им одно из ядер, ты же понимаешь — это серьезно и всем видно, даже заказчик на днях внимание обратил. А твой сервер и так вроде работает, да и все равно его никто не видит». Если такое случится, рекомендую глубоко вдохнуть и медленно досчитать до десяти, иначе разрушения и жертвы неизбежны.
- есть много чего еще: но я забыл что именно
Заканчивать принято на оптимистичной ноте: за многопоточностью не то чтобы будущее, скорее настоящее. А за мощными, гибкими и универсальными механизмами обмена сообщениями — будущее, но они еще толком не написаны, видимо нас ждут.
Всем успехов.
