К сожалению довольно сложно найти хорошие материалы по web-components на русском языке, поэтому мы с filipovskii_off решили перевести эту небольшую статью от Rob Dodson.
Эх… Markdown… Отличная штука! Я, честно говоря, не писал бы этот пост, если бы не Markdown. Много раз я пытался начать блог, но каждый раз находил процесс написания слишком ограниченным, как в GUI так и в HTML режиме WordPress. Markdown всё изменил для меня. По-моему, нам давно пора сделать его полноценной частью инструментария разработчика.
Сегодня я покажу вам, как создать тег Markdown с помощью Polymer, Web Components фреймворка от Google.
Если хотите следить за ходом создания тега, хватайте код с Github.
Обо всём по порядку, для начала загружаем последнюю версию Polymer. Для этого я предпочитаю использовать bower, что и вам советую. Об этом пока не так много говорят, но думаю bower будет также важен для web components, как npm и папка node_modules для Node.js. Если разработчики имеют представление о местонахождении и версии зависимости, они способны избавить пользователя от лишней работы. Отложим этот разговор на другой раз. А пока просто запустим:
чтобы создать файл bower.json.
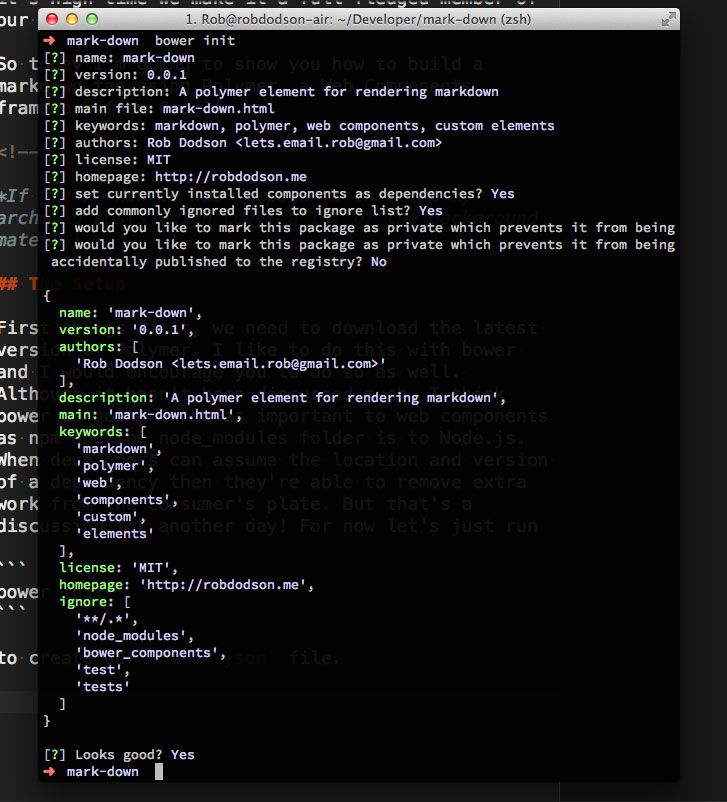
Нам также понадобятся Polymer и Markdown, так что
И наконец, сделаем тестовую страницу для нашего элемента. Я предполагаю, что сам элемент будет лежать в папке, которая называется (креативно) elements, импортируем его оттуда:
Начнём с базового каркаса в файле elements/mark-down.html.
Разберём по шагам:
Эта строка указывает, что мы хотим, чтобы Polymer определил новый элемент с именем тега mark-down.
Это наш шаблон, из него Polymer сделает Shadow DOM. Вся Markdown разметка, которую мы пишем внутри тега <mark-down>, будет распаршена и попадёт туда.
Наконец вызываем конструктор Polymer и передаём имя нашего элемента. Таким образом, новый тэг становится доступен и мы можем начать
У каждого пользовательского элемента есть метод createdCallback, работающий в качестве конструктора. Polymer укорачивает имя метода до created, но идея та же. Мы используем callback created, чтобы взять innerHTML из нашего тега и конвертировать в Markdown. Чтобы определить поведение нашего элемента, мы передаем прототип вторым аргументом в конструктор Polymer.
Первым мы возьмем содержимое тега <mark-down> и избавимся от ненужных пробелов. Для этого мы используем функцию trim, позаимствованную из Markdown element Райана Седдона(eng.).
Затем мы конвертируем содержимое в Markdown с помощью метода toHTML из библиотеки Markdown. Полученную разметку поместим в див с Id #markdown из нашего шаблона.
Вы наверняка заметили забавное использование $ и, возможно, подумали, что я мудрю с jQuery. На самом деле Polymer создает ассоциативный массив, включающий все элементы у которых есть id. Этот массив сохранен в переменной $, так что используя идентификаторы, Вы легко сможете добраться до любого элемента используя this.$.someId. Документация Polymer называет это Автоматический поиск нодов. (eng.)Но разве использование идентификаторов не анти-паттерн?Хотя в обычной структуре документа не допускается повторение Id, Shadow DOM начинает все с чистого листа и дает каждому элементу свою песочницу для идентификаторов. Это значит, мы можем использовать Id #markdown в нашем элементе и не переживать о том, что в родительском документе может быть элемент с таким же идентификатором. Весьма элегантно!
Теперь нам осталось скормить нашему элементу немного разметки markdown и посмотреть что получится.

Проще простого!
Можно сделать еще много чего интересного, например использовать contenteditable, что позволит нам переключаться между исходником и результатом. Код есть на Github, не стесняйтесь экспериментировать.
Эх… Markdown… Отличная штука! Я, честно говоря, не писал бы этот пост, если бы не Markdown. Много раз я пытался начать блог, но каждый раз находил процесс написания слишком ограниченным, как в GUI так и в HTML режиме WordPress. Markdown всё изменил для меня. По-моему, нам давно пора сделать его полноценной частью инструментария разработчика.
Сегодня я покажу вам, как создать тег Markdown с помощью Polymer, Web Components фреймворка от Google.
Github
Если хотите следить за ходом создания тега, хватайте код с Github.
Подготовка
Обо всём по порядку, для начала загружаем последнюю версию Polymer. Для этого я предпочитаю использовать bower, что и вам советую. Об этом пока не так много говорят, но думаю bower будет также важен для web components, как npm и папка node_modules для Node.js. Если разработчики имеют представление о местонахождении и версии зависимости, они способны избавить пользователя от лишней работы. Отложим этот разговор на другой раз. А пока просто запустим:
bower init
чтобы создать файл bower.json.
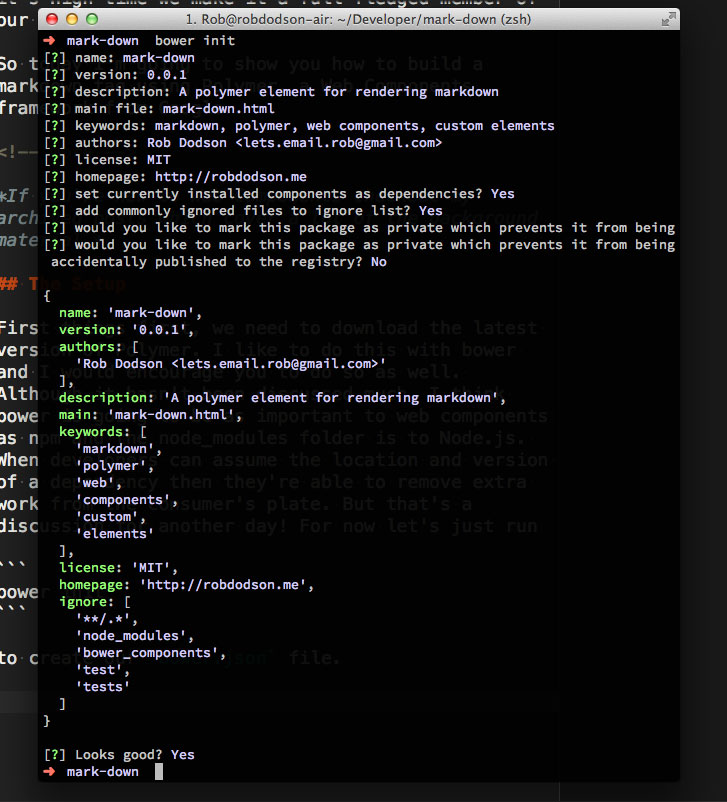
Нам также понадобятся Polymer и Markdown, так что
bower install polymer markdown --saveИ наконец, сделаем тестовую страницу для нашего элемента. Я предполагаю, что сам элемент будет лежать в папке, которая называется (креативно) elements, импортируем его оттуда:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Markdown Polymer Element</title>
<!-- Include our Markdown lib -->
<script src="./bower_components/markdown/lib/markdown.js"></script>
<!-- Include Polymer awesomesauce -->
<script src="./bower_components/polymer/polymer.min.js"></script>
<!-- Import our polymer elements -->
<link rel="import" href="./elements/mark-down.html">
</head>
<body>
<!-- Test our awesome new tag -->
<mark-down></mark-down>
</body>
</html>
Элемент
Начнём с базового каркаса в файле elements/mark-down.html.
<polymer-element name="mark-down">
<template>
<div id="markdown"></div>
</template>
<script>
Polymer("mark-down");
</script>
</polymer-element>
Разберём по шагам:
<polymer-element name="mark-down">
Эта строка указывает, что мы хотим, чтобы Polymer определил новый элемент с именем тега mark-down.
<template>
<div id="markdown"></div>
</template>
Это наш шаблон, из него Polymer сделает Shadow DOM. Вся Markdown разметка, которую мы пишем внутри тега <mark-down>, будет распаршена и попадёт туда.
<script>
Polymer("mark-down");
</script>
Наконец вызываем конструктор Polymer и передаём имя нашего элемента. Таким образом, новый тэг становится доступен и мы можем начать
Markdown
У каждого пользовательского элемента есть метод createdCallback, работающий в качестве конструктора. Polymer укорачивает имя метода до created, но идея та же. Мы используем callback created, чтобы взять innerHTML из нашего тега и конвертировать в Markdown. Чтобы определить поведение нашего элемента, мы передаем прототип вторым аргументом в конструктор Polymer.
Polymer("mark-down", {
created: function() {
var content = this.trim(this.innerHTML);
var parsed = markdown.toHTML(content);
this.$.markdown.innerHTML = parsed;
},
// Remove excess white space
trim: function() { ... }
});
Первым мы возьмем содержимое тега <mark-down> и избавимся от ненужных пробелов. Для этого мы используем функцию trim, позаимствованную из Markdown element Райана Седдона(eng.).
created: function() {
var content = this.trim(this.innerHTML);
...
},
Затем мы конвертируем содержимое в Markdown с помощью метода toHTML из библиотеки Markdown. Полученную разметку поместим в див с Id #markdown из нашего шаблона.
created: function() {
...
var parsed = markdown.toHTML(content);
this.$.markdown.innerHTML = parsed;
}
Поиск нодов
Вы наверняка заметили забавное использование $ и, возможно, подумали, что я мудрю с jQuery. На самом деле Polymer создает ассоциативный массив, включающий все элементы у которых есть id. Этот массив сохранен в переменной $, так что используя идентификаторы, Вы легко сможете добраться до любого элемента используя this.$.someId. Документация Polymer называет это Автоматический поиск нодов. (eng.)Но разве использование идентификаторов не анти-паттерн?Хотя в обычной структуре документа не допускается повторение Id, Shadow DOM начинает все с чистого листа и дает каждому элементу свою песочницу для идентификаторов. Это значит, мы можем использовать Id #markdown в нашем элементе и не переживать о том, что в родительском документе может быть элемент с таким же идентификатором. Весьма элегантно!
Тестируем
Теперь нам осталось скормить нашему элементу немного разметки markdown и посмотреть что получится.
<mark-down>
# This is a heading
## This is a subheading
Here is **more** _Markdown!_
`This is some codez`
This [is a link](http://robdodson.me)
</mark-down>

Проще простого!
Моар!
Можно сделать еще много чего интересного, например использовать contenteditable, что позволит нам переключаться между исходником и результатом. Код есть на Github, не стесняйтесь экспериментировать.
