
Yacy — это децентрализованная поисковая машина, которая позволяет осуществлять поиск информации в интернете без локальной или глобальной цензуры или любых других ограничений.
Первое и единственное упоминание о нем на хабре было 29 ноября 2011.
Но с того времени многое изменилось, давайте посмотрим на него еще раз.
Основные возможности и преимущества Yacy:
— Децентрализованный поиск и хранение индекса — в сети DHT
— Три режима работы: 1) Глобальный поисковой индекс, 2) Групповой индекс, 3) Локальный индекс
— Отсутствие рекламы
— Отсутствие какой-либо цензуры (государственной, копирайтной)
— Огромное количество настроек
Основные недостатки:
— Время поиска (из-за децентрализованной природы, поиск непопулярного контента может занимать значительное время)
— Релевантность (алгоритм релевантности был переработан за эти три года, но все равно он отстает от поисковых гигантов)
Что изменилось за три года ?
— Поддержка русскоязычных поисковых запросов
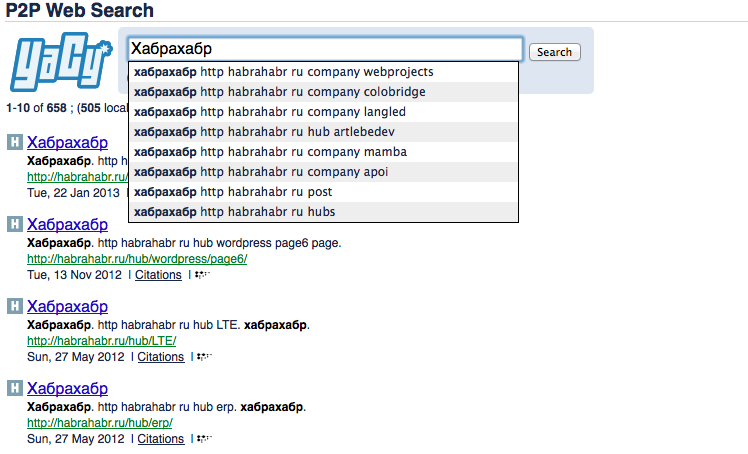
— Появились подсказки в во время ввода поискового запроса
— Опережающий поиск — пока вы печатаете yacy уже ищет пиров с данным контентом
— Улучшились алгоритмы поиска и выдачи — более релевантный результат
и миллионы других мелких изменений под капотом.
Как работает Yacy?
Индексирование
Индексирование может быть инициировано следующими путями:
1) Принудительное указание начала сканирования
2) Удаленный запрос от другого пира
3) Настройка проксирования всех запросов от браузера к Yacy с последующий индексацией того, что вы читаете
После составление базы индекса она сохраняется локально, рассылая в сеть информацию о том, что она у вас есть, и распределяется по DHT на соседних пиров.
Поиск
Во время процесса поиска Yacy сначала ищет результаты в локальном индексе, а затем в глобальном, связываясь по DHT c пирами, у которых есть сведения об индексе того или иного запроса/сайта.
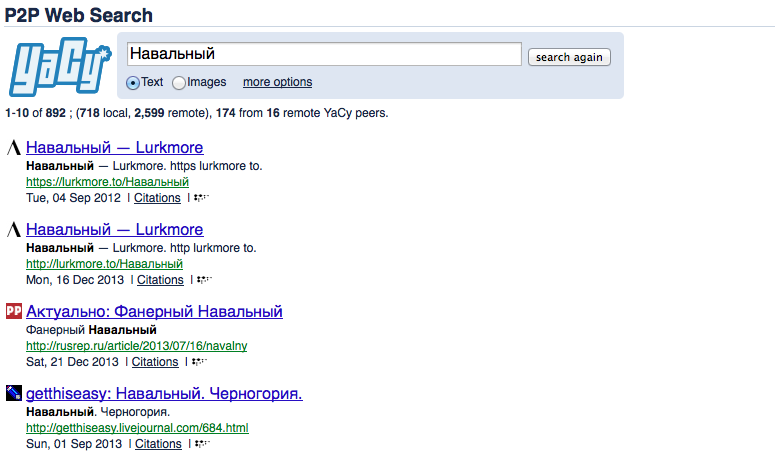
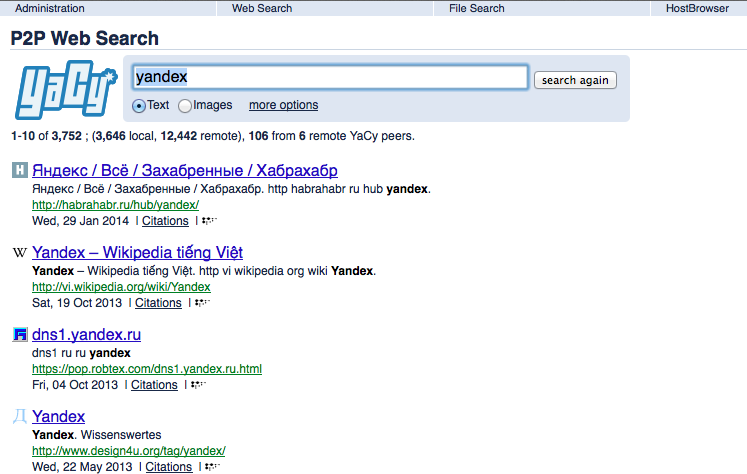
Результаты поиска от Yacy:

Официальный сайт проекта yacy.net/en
Windows yacy.net/release/yacy_v1.68_20140209_9000.exe
Linux yacy.net/release/yacy_v1.68_20140209_9000.tar.gz
OS X yacy.net/release/yacy_v1.68_20140209_9000.dmg
Тестовая поисковая страницы search.yacy.net (которая может упасть от большого трафика)
PS Последняя статья была три года назад, если хабр пользователям будет интересна тема децентрализованных поисковых систем, я готов сделать обзор всего функционала Yacy и рассмотреть подробно как она работает
Only registered users can participate in poll. Log in, please.
Хотите ли вы пользоваться децентрализованными поисковыми системами?
84.12% Да1865
15.88% Нет352
2217 users voted. 634 users abstained.
Only registered users can participate in poll. Log in, please.
А почему вы хотите/не хотите ими пользоваться?
48.84% Хочу, Они не сохраняют никакой обо мне информации1093
48.66% Хочу, Информация о том, что я искал не может быть передана никому1089
72.56% Хочу, Отсутствие цензуры1624
46.11% Хочу, Отсутствие рекламы1032
8.18% Не хочу, Сложность использования183
24.84% Не хочу, Малая база индекса сайтов556
11.44% Не хочу, Меня не волнует слежка256
22.83% Не хочу, Мне важна релевантность поиска в ущерб приватности511
2238 users voted. 640 users abstained.
Only registered users can participate in poll. Log in, please.
Хотите еще почитать про Yacy?
88.32% Да определенно2026
11.68% Нет меня это не интересует268
2294 users voted. 470 users abstained.
