Google использует своего «паука» FeedFetcher для кэширования любого контента в Google Spreadsheet, вставленного через формулу =image(«link»).
Например, если в одну из клеток таблицы вставить формулу
Однако если добавлять случайный параметр к URL картинки, FeedFetcher будет скачивать её каждый раз заново. Скажем, для примера, на сайте жертвы есть PDF-файл размером в 10 МБ. Вставка подобного списка в таблицу приведет к тому, что паук Google скачает один и тот же файл 1000 раз!
Все это может привести к исчерпанию лимита трафика у некоторых владельцев сайтов. Кто угодно, используя лишь браузер с одной открытой вкладкой, может запустить массированную HTTP GET FLOOD-атаку на любой веб-сервер.
Атакующему даже необязательно иметь быстрый канал. Поскольку в формуле используется ссылка на PDF-файл (т.е. не на картинку, которую можно было бы отобразить в таблице), в ответ от сервера Google атакующий получает только N/A. Это позволяет довольно просто многократно усилить атаку [Аналог DNS и NTP Amplification – прим. переводчика], что представляет серьезную угрозу.

С использованием одного ноутбука с несколькими открытыми вкладками, просто копируя-вставляя списки ссылок на файлы по 10 МБ, паук Google может скачивать этот файл со скоростью более 700 Мбит/c. В моем случае, это продолжалось в течение 30-45 минут, до тех пор, пока я не вырубил сервер. Если я все правильно подсчитал, за 45 минут ушло примерно 240GB трафика.
Я удивился, когда увидел объем исходящего трафика. Еще немного, и я думаю, исходящий трафик достиг бы 1 Гбит/с, а входящий 50-100 Мбит/с. Я могу только представить, что произойдет, если несколько атакующих будут использовать этот метод. Паук Google использует не один IP-адрес, и хотя User-Agent всегда один и тот же, редактировать конфиг веб-сервера может быть слишком поздно, если атака застанет жертву врасплох. Благодаря простоте использования, атака легко может продолжаться часами.
Когда обнаружился этот баг, я стал гуглить инциденты с его использованием, и нашел два:
• Статья, где блогер описывает, как случайно атаковал сам себя и получил огромный счет за трафик. [Перевод на хабре – прим. переводчика].
• Другая статья описывает похожую атаку с помощью Google Spreadsheet, но сначала, автор предлагает спарсить ссылки на все файлы сайта и запустить атаку по этому списку с использованием нескольких аккаунтов.
Я нахожу несколько странным, что никто не догадался попробовать добавить к запросу случайный параметр. Даже если на сайте всего один файл, добавление случайного параметра позволяет сделать тысячи запросов к этому сайту. На самом деле, это немного пугает. Простая вставка нескольких ссылок в открытую вкладку браузера не должна приводить к такому.
Вчера я отправил описание этого бага в Google и получил ответ, что это не уязвимость, и не проходит по программе Bug Bounty. Возможно, они заранее знали о нём, и действительно не считают это багом?
Тем не менее, я надеюсь, они пофиксят эту проблему. Просто немного раздражает, что любой может заставить паука Google доставить столько проблем. Простой фикс заключается в том, чтобы скачивать файлы пропуская дополнительные параметры в URL [На мой взгляд, это очень плохой фикс. Возможно, стоит ограничить пропускную способность или лимитировать количество запросов и трафик в единицу времени и при этом не скачивать файлы больше определенного размера – прим. переводчика].
Например, если в одну из клеток таблицы вставить формулу
=image("http://example.com/image.jpg")Однако если добавлять случайный параметр к URL картинки, FeedFetcher будет скачивать её каждый раз заново. Скажем, для примера, на сайте жертвы есть PDF-файл размером в 10 МБ. Вставка подобного списка в таблицу приведет к тому, что паук Google скачает один и тот же файл 1000 раз!
=image("http://targetname/file.pdf?r=1")
=image("http://targetname/file.pdf?r=2")
=image("http://targetname/file.pdf?r=3")
=image("http://targetname/file.pdf?r=4")
...
=image("http://targetname/file.pdf?r=1000")Все это может привести к исчерпанию лимита трафика у некоторых владельцев сайтов. Кто угодно, используя лишь браузер с одной открытой вкладкой, может запустить массированную HTTP GET FLOOD-атаку на любой веб-сервер.
Атакующему даже необязательно иметь быстрый канал. Поскольку в формуле используется ссылка на PDF-файл (т.е. не на картинку, которую можно было бы отобразить в таблице), в ответ от сервера Google атакующий получает только N/A. Это позволяет довольно просто многократно усилить атаку [Аналог DNS и NTP Amplification – прим. переводчика], что представляет серьезную угрозу.
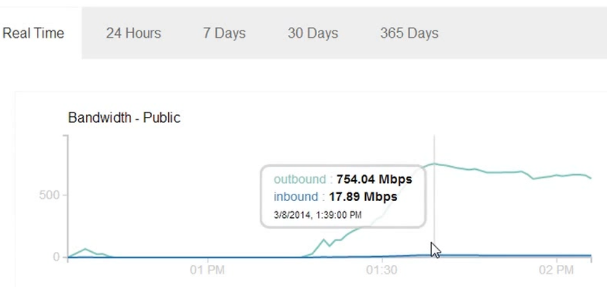
С использованием одного ноутбука с несколькими открытыми вкладками, просто копируя-вставляя списки ссылок на файлы по 10 МБ, паук Google может скачивать этот файл со скоростью более 700 Мбит/c. В моем случае, это продолжалось в течение 30-45 минут, до тех пор, пока я не вырубил сервер. Если я все правильно подсчитал, за 45 минут ушло примерно 240GB трафика.
Я удивился, когда увидел объем исходящего трафика. Еще немного, и я думаю, исходящий трафик достиг бы 1 Гбит/с, а входящий 50-100 Мбит/с. Я могу только представить, что произойдет, если несколько атакующих будут использовать этот метод. Паук Google использует не один IP-адрес, и хотя User-Agent всегда один и тот же, редактировать конфиг веб-сервера может быть слишком поздно, если атака застанет жертву врасплох. Благодаря простоте использования, атака легко может продолжаться часами.
Когда обнаружился этот баг, я стал гуглить инциденты с его использованием, и нашел два:
• Статья, где блогер описывает, как случайно атаковал сам себя и получил огромный счет за трафик. [Перевод на хабре – прим. переводчика].
• Другая статья описывает похожую атаку с помощью Google Spreadsheet, но сначала, автор предлагает спарсить ссылки на все файлы сайта и запустить атаку по этому списку с использованием нескольких аккаунтов.
Я нахожу несколько странным, что никто не догадался попробовать добавить к запросу случайный параметр. Даже если на сайте всего один файл, добавление случайного параметра позволяет сделать тысячи запросов к этому сайту. На самом деле, это немного пугает. Простая вставка нескольких ссылок в открытую вкладку браузера не должна приводить к такому.
Вчера я отправил описание этого бага в Google и получил ответ, что это не уязвимость, и не проходит по программе Bug Bounty. Возможно, они заранее знали о нём, и действительно не считают это багом?
Тем не менее, я надеюсь, они пофиксят эту проблему. Просто немного раздражает, что любой может заставить паука Google доставить столько проблем. Простой фикс заключается в том, чтобы скачивать файлы пропуская дополнительные параметры в URL [На мой взгляд, это очень плохой фикс. Возможно, стоит ограничить пропускную способность или лимитировать количество запросов и трафик в единицу времени и при этом не скачивать файлы больше определенного размера – прим. переводчика].
