Всем прикольно пообсуждать «всё новое хреновое», и последние пару лет мы увлечённо обсуждали и пробовали NoSQL/NewSQL на сервере и Angular/Knockout/Ember на клиенте. Но эти тренды, похоже, уже на излёте. Отличный момент, чтобы присесть и поразмыслить, что же дальше. Как сказал M. Andreessen, «software is eating the world». В то же время, mobile/web apps едят обычные приложения. Поэтому особенно интересно прикинуть, а куда же всё катится в мире мобильных и веб-приложений? Ведь они, получается, едят вообще всех. Я считаю, что следующей Большой Темой будет синхронизация данных, и вот почему.

В браузере, разработчики уже строят вполне полноценные «нормальные» MVC приложения. Сама MVC архитектура не нова (из 1970-х), но в веб пришла лишь 10 лет назад, вместе с Google Mail. Занятно, что изначально проект GMail воспринимался, как приблуда для гиков, но, как сказал тогда Larry Page, «normal users would look more like us in 10 years’ time». Что ж, это сработало, и GMail теперь используют все.
С приходом HTML5, у браузера уже есть своё хранилище данных (даже два), своя бизнес логика на JavaScript и своё постоянное соединение с сервером. Теперь, разработчики пытаются совместить лучшее из двух миров: доступность и моментальный отклик локальных приложений и постоянный «онлайн-режим» веб-приложений.

Основной источник дискомфорта — это запросы к серверу. Особенно это ощущается на мобильных устройствах. Ирония в том, что беспроводной интернет сбоит, когда он больше всего нужен — в дороге (в метро), на массовых мероприятиях и «в полях». Дома-то и на работе за столом он бесперебойно работает, спасибо огромное, только не сильно нужен. Да и то, в том же офисе Яндекса WiFi небезупречен — видимо, из-за концентрации гиков на метр площади. На конференциях типа FOSDEM, WiFi не работал никогда.
Можно подумать, что с LTE проблема исчезнет. Вряд ли. Мы видим, что пропускная способность, объём хранения, плотность чипов растут экспоненциально, а RTT (время отклика сервера) и частота CPU за последние 10 лет улучшились крайне мало — из-за физики. Для мобильных сетей, физика — это миллионы тонн бетона, арматуры и скальных пород, и свойства радио спектра, которые никуда не денутся. Спасает кэширование данных и фоновая синхронизация, тот же GMail и тут впереди всех. Dropbox тоже радует в этом отношении, а вот Evernote не очень — полно жалоб на сбои синхронизации и потерю данных.

Задумаемся. Всё больше данных и логики переезжает на клиента. WebStorage, CoreData, IndexedDB. Данных всё больше, места на клиенте всё больше, а пробежки до сервера легче не становятся. Скачать данные просто, закешировать ещё проще, а с синхронизацией начинается rocket science. Сбойнувшая мобила «сохраняет» на сервер пустые данные — упс, потерялись, пользователь недоволен. Данные изменены сразу на нескольких устройствах — упс, конфликт, пользователь скрежещет зубами. А сколько ещё будет таких упсов. Новые условия на клиенте уже напоминают условия в «больших» системах — множество единиц оборудования, множество реплик данных, всё везде постоянно ломается и это нормально. Похоже, на клиенте скоро потребуются инструменты из арсенала «больших мальчиков».
На сервере когда-то всё начиналось просто и логично — ничто не предвещало беды. Был один источник истины — БД (скажем, MySQL), был один сервер с логикой (скажем, PHP), а клиент получал плоские View и дёргал логику на сервере через HTTP GET запросы. С масштабированием логики все поначалу справлялись просто — через умножение stateless серверов. БД постепенно начала требовать репликации (master-slave), потом потребовалось защитить её кэшем (Memcache) и добавить pusher для отправки событий на клиента в реальном времени. Потом ситуация начала усложняться дальше. Где-то прикрутили Hadoop, где-то NoSQL, где-то graph database — хранилищ стало много. Также, всё обросло специализированными сервисами — аналитика, поиск, рассылки итд итп.

Всё это стремительное размножение специализированных систем также подняло проблему синхронизации данных. Как наиболее удачное решение для «зоопарка», много упоминают Apache Kafka. В такой архитектуре, разные срезы данных хранятся в разных системах, которые предпочитают обмениваться событиями через «шину». Действительно, при интеграции N систем можно написать либо O(N*N) переходников, либо одну общую очередь событий. При N=2..3 этот нюанс ещё мало заметен, а вот в LinkedIn, видимо, N велико.
А теперь два окурка одновременно. Представим количество реплик одних и тех же данных в системе — и на серверной, и на клиентской стороне. Скажем, MongoDB+Redis+Hadoop+WebStorage+CoreData. Как это всё грамотно синхронизировать?
Итак, какими же будут дальнейшие тренды? Точно никто не скажет, но можно прикинуть, на что обратить внимание. Ведь новые идеи появляются крайне медленно и крайне редко. Например, MongoDB использует master-slave репликацию через оплог, которая отличается от репликации MySQL через бинлог лишь инкрементными улучшениями и базируется на работах Leslie Lamport 1979-1984 годов про state machine replication.
NoSQL системы — Riak, Voldemort, Cassandra, CouchDB пытаются сделать заметный шаг вперёд и выжать что-то из eventual consistency, causal order, logical и vector clocks — эти подходы восходят к работам того же L.Lamport и C.Fidge конца восьмидесятых.
Супер-пупер технология одновременного редактирования Operational transformation из Google Wave и Docs впервые описана в 1989 C.A. Ellis и S.J. Gibbs и на сегодня морально устарела.
Свежего мало, но тоже попадается. Попытки NoSQL вендоров попробовать воду с CRDT структурами данных базируются на теории из конца 2000-х — очень нетипичный свежачок.
Итак, подумаем, что будет прорастать в новой среде. Новые тренды неизбежно будут определяться чем-то, уже достаточно широко известным в узких кругах. Я могу предложить трёх основных подозреваемых.
Первый и наиболее многообещающий тренд — это event-oriented и reactive архитектуры, а также event sourcing. В этих подходах, работа в системе идёт не только и не столько с самим текущим состоянием, но с операциями, его изменяющими, которые являются объектами «первой категории» — они обрабатываются, передаются и сохраняются отдельно от состояния. Kafka и общую шину событий я уже упоминал. Если подумать, то и логика работы клиент-сайда событийно-ориентированная. Добавляем сюда событийно-ориентированную бизнес-логику и начинает собираться интересный пазл.

Event-oriented подход, в частности, уменьшает зависимость от ACID транзакций. Главный аргумент за транзакции — «а если мы деньги считаем?» Ирония в том, что в собственно финансовой индустрии, где действительно считают большие деньги, до того, как был изобретён SQL с транзакциями, совершенно спокойно обходились без них долгие тысячи лет. Бухгалтерия со счетами и балансами, в том виде, в котором они оформились ещё в Средневековье, является классическим примером event sourcing: операции фиксируются, сводятся, и собираются в состояние. То же видим и древней системе расчётов Хавала. Никакого ACID, чистейший eventual consistency. Книжки пишут, например, про развитую финансовую систему Испанской империи, которая сто лет воевала в долг. Письма от столицы до окраинных провинций оборачивались за год. И ничего, товары доставлялись, армия воевала, балансы сводились. А вот мой деловой партнёр недавно три раза ходил в налоговую, потому что у них «компьютеры зависли».
Второй тренд, который может начать проклёвываться — это инфоцентричные архитектуры. Когда данные хранятся где угодно и свободно перетекают, имеет смысл реализовывать приложения не в логике место хранения-соединение, а всегда плясать от данных. Исторические примеры инфоцентричных сетей — USENET и BitTorrent; в первой, сообщения идентифицируются именем группы и собственным id, и свободно перетекают между серверами. Во второй, данные вообще идентифицируются по хэшу, а участники взаимовыгодно обмениваются данными между собой. Общий принцип: надёжно идентифицируем данные, потом выстраиваем под них и участников и топологию сети. Это особенно важно, когда участники ненадёжны и постоянно уходят и приходят, что очень актуально для мобильных клиентов.
Лет пять назад, был интересный обмен мнениями по поводу инфоцентричности интернета. Пионер TCP Van Jacobson отстаивал позицию, что существующие архитектуры достигли предела масштабирования и надо проектировать с нуля инфоцентричный интернет. Другая группа участников, откуда могу припомнить Ion Stoica, в целом придерживались позиции, что HTTP конечно устарел, но, подстроив под HTTP CDN-инфраструктуру, мы можем понимать URL, как просто идентификатор куска информации, а не путь сервер-файл. Поэтому, дуплет HTTP+CDN может быть инфоцентричным в необходимой степени для решения всех насущных проблем с распространением статики в HTTP. И, пожалуй, ребята были в основном правы.
Интересный вопрос — можно ли по аналогии впилить инфоцентричность для данных в веб-приложениях, не занимаясь редизайном архитектуры с нуля.
И третий интересный тренд, который я уже упоминал, как свежачок — это CRDT (Conflict-free Replicated Data Types). Их уже начали прикручивать в высоконагруженные NoSQL системы (точно знаю про Cassandra и Riak, но вроде кто-то ещё был). Основная идея CRDT в том, чтобы отказаться от линеаризации всех операций в системе (это подход, который используется в том же MySQL для репликации), и ограничиться наличием частичного порядка с хорошими свойствами (causal order). Соответственно, можно использовать только структуры данных и алгоритмы, которые не ломаются от лёгкого переупорядочения операций.
CRDT позволяет оптимистичную синхронизацию множества реплик, когда полная линеаризация всех операций в принципе невозможна. В литературе рассматриваются варианты, как реализовать в CRDT базовые структуры данных — Set, Map, counter, текст.
Это наиболее многообещающий подход, который позволяет шагнуть чуть дальше примитивного last-writer-wins, опасного потенциальной потерей данных при конкурентной записи. Основная сложность, конечно, в том, что разработчик должен понимать возможности CRDT, чтобы с ними работать. Что, в общем-то, верно для любой технологии. Плюс, далеко не все данные и алгоритмы можно разложить на CRDT-базис. А основная выгода — в возможности решить вопросы синхронизации зоопарка реплик и хранилищ данных, при конкурентном доступе на запись.
CRDT-движок в мобильном приложении позволит полноценно работать с данными даже в отсутствие постоянного соединения с интернетом, и лишь при появлении соединения синхронизироваться, без конфликтов и потери данных. В идеале, это может быть совершенно незаметно для пользователя. Этакий Dropbox/git для объектов. Да-да, Firebase, Meteor, Derby, Google Drive Realtime API — движуха идёт именно в этом направлении. Но бомбой, уровня MySQL или jQuery, это ещё не стало — значит, что-то ещё не готово.
Если, например, мысленно скрестить CRDT, information-centric и event-oriented, получим гипотетическую CRDT-шину, которая, в отличие от тех же CORBA/DCOM/RMI, позволит не столько обращаться к удалённым объектам, сколько работать с их локальными копиями. При этом, эти локальные копии будут не плоским «кэшем», а полноценными живыми репликами с возможностью записи, которые будут автоматически синхронизироваться.
Чем не архитектура для веб-приложений будущего?
А, что, собственно, происходит на клиенте?
В браузере, разработчики уже строят вполне полноценные «нормальные» MVC приложения. Сама MVC архитектура не нова (из 1970-х), но в веб пришла лишь 10 лет назад, вместе с Google Mail. Занятно, что изначально проект GMail воспринимался, как приблуда для гиков, но, как сказал тогда Larry Page, «normal users would look more like us in 10 years’ time». Что ж, это сработало, и GMail теперь используют все.
С приходом HTML5, у браузера уже есть своё хранилище данных (даже два), своя бизнес логика на JavaScript и своё постоянное соединение с сервером. Теперь, разработчики пытаются совместить лучшее из двух миров: доступность и моментальный отклик локальных приложений и постоянный «онлайн-режим» веб-приложений.

Основной источник дискомфорта — это запросы к серверу. Особенно это ощущается на мобильных устройствах. Ирония в том, что беспроводной интернет сбоит, когда он больше всего нужен — в дороге (в метро), на массовых мероприятиях и «в полях». Дома-то и на работе за столом он бесперебойно работает, спасибо огромное, только не сильно нужен. Да и то, в том же офисе Яндекса WiFi небезупречен — видимо, из-за концентрации гиков на метр площади. На конференциях типа FOSDEM, WiFi не работал никогда.
Можно подумать, что с LTE проблема исчезнет. Вряд ли. Мы видим, что пропускная способность, объём хранения, плотность чипов растут экспоненциально, а RTT (время отклика сервера) и частота CPU за последние 10 лет улучшились крайне мало — из-за физики. Для мобильных сетей, физика — это миллионы тонн бетона, арматуры и скальных пород, и свойства радио спектра, которые никуда не денутся. Спасает кэширование данных и фоновая синхронизация, тот же GMail и тут впереди всех. Dropbox тоже радует в этом отношении, а вот Evernote не очень — полно жалоб на сбои синхронизации и потерю данных.

Задумаемся. Всё больше данных и логики переезжает на клиента. WebStorage, CoreData, IndexedDB. Данных всё больше, места на клиенте всё больше, а пробежки до сервера легче не становятся. Скачать данные просто, закешировать ещё проще, а с синхронизацией начинается rocket science. Сбойнувшая мобила «сохраняет» на сервер пустые данные — упс, потерялись, пользователь недоволен. Данные изменены сразу на нескольких устройствах — упс, конфликт, пользователь скрежещет зубами. А сколько ещё будет таких упсов. Новые условия на клиенте уже напоминают условия в «больших» системах — множество единиц оборудования, множество реплик данных, всё везде постоянно ломается и это нормально. Похоже, на клиенте скоро потребуются инструменты из арсенала «больших мальчиков».
А что, собственно, происходит на сервере?
На сервере когда-то всё начиналось просто и логично — ничто не предвещало беды. Был один источник истины — БД (скажем, MySQL), был один сервер с логикой (скажем, PHP), а клиент получал плоские View и дёргал логику на сервере через HTTP GET запросы. С масштабированием логики все поначалу справлялись просто — через умножение stateless серверов. БД постепенно начала требовать репликации (master-slave), потом потребовалось защитить её кэшем (Memcache) и добавить pusher для отправки событий на клиента в реальном времени. Потом ситуация начала усложняться дальше. Где-то прикрутили Hadoop, где-то NoSQL, где-то graph database — хранилищ стало много. Также, всё обросло специализированными сервисами — аналитика, поиск, рассылки итд итп.
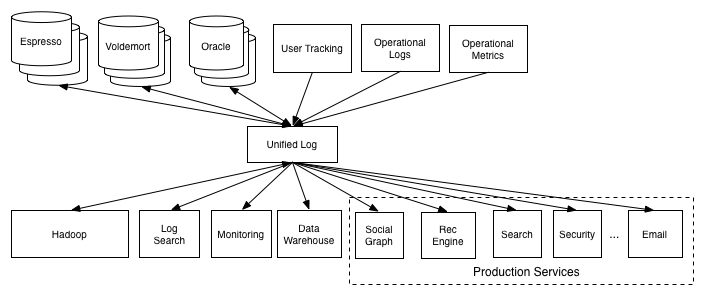
Всё это стремительное размножение специализированных систем также подняло проблему синхронизации данных. Как наиболее удачное решение для «зоопарка», много упоминают Apache Kafka. В такой архитектуре, разные срезы данных хранятся в разных системах, которые предпочитают обмениваться событиями через «шину». Действительно, при интеграции N систем можно написать либо O(N*N) переходников, либо одну общую очередь событий. При N=2..3 этот нюанс ещё мало заметен, а вот в LinkedIn, видимо, N велико.
А теперь два окурка одновременно. Представим количество реплик одних и тех же данных в системе — и на серверной, и на клиентской стороне. Скажем, MongoDB+Redis+Hadoop+WebStorage+CoreData. Как это всё грамотно синхронизировать?
И к чему это всё ведёт?
Итак, какими же будут дальнейшие тренды? Точно никто не скажет, но можно прикинуть, на что обратить внимание. Ведь новые идеи появляются крайне медленно и крайне редко. Например, MongoDB использует master-slave репликацию через оплог, которая отличается от репликации MySQL через бинлог лишь инкрементными улучшениями и базируется на работах Leslie Lamport 1979-1984 годов про state machine replication.
NoSQL системы — Riak, Voldemort, Cassandra, CouchDB пытаются сделать заметный шаг вперёд и выжать что-то из eventual consistency, causal order, logical и vector clocks — эти подходы восходят к работам того же L.Lamport и C.Fidge конца восьмидесятых.
Супер-пупер технология одновременного редактирования Operational transformation из Google Wave и Docs впервые описана в 1989 C.A. Ellis и S.J. Gibbs и на сегодня морально устарела.
Свежего мало, но тоже попадается. Попытки NoSQL вендоров попробовать воду с CRDT структурами данных базируются на теории из конца 2000-х — очень нетипичный свежачок.
Итак, подумаем, что будет прорастать в новой среде. Новые тренды неизбежно будут определяться чем-то, уже достаточно широко известным в узких кругах. Я могу предложить трёх основных подозреваемых.
«Общая шина» и event-oriented
Первый и наиболее многообещающий тренд — это event-oriented и reactive архитектуры, а также event sourcing. В этих подходах, работа в системе идёт не только и не столько с самим текущим состоянием, но с операциями, его изменяющими, которые являются объектами «первой категории» — они обрабатываются, передаются и сохраняются отдельно от состояния. Kafka и общую шину событий я уже упоминал. Если подумать, то и логика работы клиент-сайда событийно-ориентированная. Добавляем сюда событийно-ориентированную бизнес-логику и начинает собираться интересный пазл.

Event-oriented подход, в частности, уменьшает зависимость от ACID транзакций. Главный аргумент за транзакции — «а если мы деньги считаем?» Ирония в том, что в собственно финансовой индустрии, где действительно считают большие деньги, до того, как был изобретён SQL с транзакциями, совершенно спокойно обходились без них долгие тысячи лет. Бухгалтерия со счетами и балансами, в том виде, в котором они оформились ещё в Средневековье, является классическим примером event sourcing: операции фиксируются, сводятся, и собираются в состояние. То же видим и древней системе расчётов Хавала. Никакого ACID, чистейший eventual consistency. Книжки пишут, например, про развитую финансовую систему Испанской империи, которая сто лет воевала в долг. Письма от столицы до окраинных провинций оборачивались за год. И ничего, товары доставлялись, армия воевала, балансы сводились. А вот мой деловой партнёр недавно три раза ходил в налоговую, потому что у них «компьютеры зависли».
Information-centric architectures
Второй тренд, который может начать проклёвываться — это инфоцентричные архитектуры. Когда данные хранятся где угодно и свободно перетекают, имеет смысл реализовывать приложения не в логике место хранения-соединение, а всегда плясать от данных. Исторические примеры инфоцентричных сетей — USENET и BitTorrent; в первой, сообщения идентифицируются именем группы и собственным id, и свободно перетекают между серверами. Во второй, данные вообще идентифицируются по хэшу, а участники взаимовыгодно обмениваются данными между собой. Общий принцип: надёжно идентифицируем данные, потом выстраиваем под них и участников и топологию сети. Это особенно важно, когда участники ненадёжны и постоянно уходят и приходят, что очень актуально для мобильных клиентов.
Лет пять назад, был интересный обмен мнениями по поводу инфоцентричности интернета. Пионер TCP Van Jacobson отстаивал позицию, что существующие архитектуры достигли предела масштабирования и надо проектировать с нуля инфоцентричный интернет. Другая группа участников, откуда могу припомнить Ion Stoica, в целом придерживались позиции, что HTTP конечно устарел, но, подстроив под HTTP CDN-инфраструктуру, мы можем понимать URL, как просто идентификатор куска информации, а не путь сервер-файл. Поэтому, дуплет HTTP+CDN может быть инфоцентричным в необходимой степени для решения всех насущных проблем с распространением статики в HTTP. И, пожалуй, ребята были в основном правы.
Интересный вопрос — можно ли по аналогии впилить инфоцентричность для данных в веб-приложениях, не занимаясь редизайном архитектуры с нуля.
CRDT типы
И третий интересный тренд, который я уже упоминал, как свежачок — это CRDT (Conflict-free Replicated Data Types). Их уже начали прикручивать в высоконагруженные NoSQL системы (точно знаю про Cassandra и Riak, но вроде кто-то ещё был). Основная идея CRDT в том, чтобы отказаться от линеаризации всех операций в системе (это подход, который используется в том же MySQL для репликации), и ограничиться наличием частичного порядка с хорошими свойствами (causal order). Соответственно, можно использовать только структуры данных и алгоритмы, которые не ломаются от лёгкого переупорядочения операций.
CRDT позволяет оптимистичную синхронизацию множества реплик, когда полная линеаризация всех операций в принципе невозможна. В литературе рассматриваются варианты, как реализовать в CRDT базовые структуры данных — Set, Map, counter, текст.
Это наиболее многообещающий подход, который позволяет шагнуть чуть дальше примитивного last-writer-wins, опасного потенциальной потерей данных при конкурентной записи. Основная сложность, конечно, в том, что разработчик должен понимать возможности CRDT, чтобы с ними работать. Что, в общем-то, верно для любой технологии. Плюс, далеко не все данные и алгоритмы можно разложить на CRDT-базис. А основная выгода — в возможности решить вопросы синхронизации зоопарка реплик и хранилищ данных, при конкурентном доступе на запись.
CRDT-движок в мобильном приложении позволит полноценно работать с данными даже в отсутствие постоянного соединения с интернетом, и лишь при появлении соединения синхронизироваться, без конфликтов и потери данных. В идеале, это может быть совершенно незаметно для пользователя. Этакий Dropbox/git для объектов. Да-да, Firebase, Meteor, Derby, Google Drive Realtime API — движуха идёт именно в этом направлении. Но бомбой, уровня MySQL или jQuery, это ещё не стало — значит, что-то ещё не готово.
Если, например, мысленно скрестить CRDT, information-centric и event-oriented, получим гипотетическую CRDT-шину, которая, в отличие от тех же CORBA/DCOM/RMI, позволит не столько обращаться к удалённым объектам, сколько работать с их локальными копиями. При этом, эти локальные копии будут не плоским «кэшем», а полноценными живыми репликами с возможностью записи, которые будут автоматически синхронизироваться.
Чем не архитектура для веб-приложений будущего?
Only registered users can participate in poll. Log in, please.
Как веб-разработчику, нравится ли вам идея «Dropbox/git для объектов?»
22.14% это никому не нужно87
8.4% у нас это уже есть33
69.47% круто, где дают?273
393 users voted. 228 users abstained.
