Если вам приходилось создавать интеграционные решения на Java, наверняка, вам знаком замечательный Java framework под названием Apache Camel. Он с лёгкостью осуществит связку между несколькими сервисами, импортирует данные из файлов, баз данных и прочих источников, оповестит вас о различных событиях в Jabber-клиент или по E-mail, станет основой для композитного приложения на базе большого числа других приложений.
В основе модели Apache Camel лежит понятие маршрутов (routes), которые можно конфигурировать как статически (например, в файле Spring-контекста), так и во время работы приложения. По маршрутам ходят караваны сообщений, попутно попадая в различные обработчики, конверторы, аггрегаторы и прочие трансформеры, что в конечном итоге позволяет обработать данные из множества различных источников в едином приложении и передать эти данные другим сервисам или сохранить в какое-либо хранилище.
В общем и целом Camel — вполне самодостаточный фреймворк. Используя его, зачастую, даже не приходится писать собственный код — достаточно лишь набрать правильный маршрут, который позволит решить поставленную задачу. Однако, всё же для построения собственной модели обработки данных, может потребоваться написание кода.
Так было и у нас. Мы используем Camel для реализации конвейеров по обработке множества сообщений из различных источников. Подобный подход позволяет, например, следить за состоянием сервисов, своевременно оповещая о проблемах, получать аггрегированные аналитические срезы, готовить данные для отправки в другие системы и прочее. Поток обрабатываемых и «перевариваемых» сообщений в систему может быть довольно большим (тысячи сообщений в минуту), поэтому мы стараемся использовать горизонтально масштабируемые решения там, где это возможно. Например, у нас есть система отслеживания состояний выполняемых тестов и мониторингов сервисов. Подобных тестов выполняется по миллиону ежедневно, а сообщений для контроля процесса их выполнения мы получаем в разы больше.
Чтобы «усвоить» подобный объём сообщений, необходимо чётко определить стратегию аггрегации — от большего параллелизма к меньшему. Помимо этого необходимо иметь хотя бы базовую горизонтальную масштабируемость и отказоустойчивость сервиса.
В качестве очереди сообщений мы используем ActiveMQ, в качестве оперативного хранилища — Hazelcast.
Для организации параллельной обработки организуется кластер из нескольких равноправных серверов. На каждом из них живёт брокер ActiveMQ, в очереди которого складываются сообщения, поступающие по HTTP-протоколу. HTTP-ручки находятся за балансировщиком, распределяющим сообщения по живым серверам.
Входную очередь сообщений на каждом сервере разбирает Camel-приложение, использующее кластер Hazelcast для хранения состояний, а также, при необходимости, синхронизации обработки. ActiveMQ также объеденены в кластер с использованием NetworkConnectors, и могут «делиться» сообщениями друг с другом.
В целом схема выглядит следующим образом:
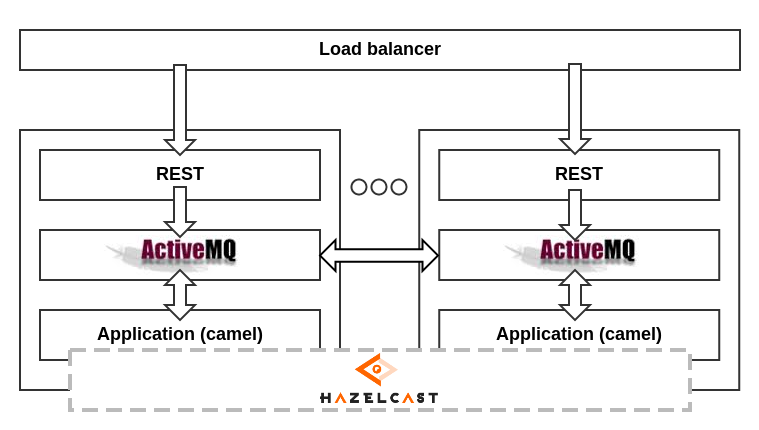
Как видно из схемы, выход из строя одного из компонентов системы не нарушает её работоспособность, с учётом равноправия элементов. К примеру, если выходит из строя обработчик сообщений на одном из серверов, ActiveMQ начинает отдавать сообщения из своих очередей другим. Если падает один из брокеров ActiveMQ, то обработчик «зацепляется» за соседний. Ну и наконец, если выходит из строя весь сервер, остальные сервера продолжают трудиться в поте лица, как ни в чём не бывало. Для повышения сохранности данных ноды Hazelcast хранят резервные копии данных своих соседей (копии осуществляются асинхронно, их число на каждой ноде настраивается дополнительно).
Данная схема также позволяет без особых затрат масштабировать сервис, добавляя дополнительные сервера, и тем самым увеличивая вычислительный ресурс.
При использовании аггрегации Apache Camel включает понятия "aggregation repository" и "correlation key". Первое — это репозиторий, где хранятся аггрегированные состояния (например, число упавших тестов за день). Второе — это ключ, используемый для распределения потока сообщений по состояниям. Другими словами correlation key — это ключ в репозитории аггрегации (например, текущая дата).
Для аггрегаторов в подобной схеме нам понадобилась реализация своего собственного репозитория аггрегации, умеющего хранить состояния в Hazelcast и синхронизировать обработку одинаковых ключей внутри кластера. К сожалению, в стандартной поставке Camel мы подобной возможности не обнаружили. Благо создать его оказалось совсем несложно — достаточно реализовать интерфейс AggregationRepository:
Чтобы воспользоваться подобным репозиторием, теперь нужно лишь подключить к проекту Hazelcast и объявить его в контексте, а затем добавить и набор репозиториев с указанием на инстанс Hazelcast. Важно помнить, что каждый аггрегатор должен иметь собственное пространство ключей, а поэтому ему необходимо передавать также имя репозитория. В настройках Hazelcast нужно прописать все сервера, которые входят в кластер.
Таким образом, мы получаем возможность использовать аггрегаторы в распределённой среде, не задумываясь о том на каком именно сервере произойдёт аггрегация.
Число состояний, хранящихся в кластере достаточно велико. Но не все из них нужны постоянно. К тому же, некоторые состояния (например, состояние тестов, которые давно не используются, а следовательно для них давно не было сообщений) вообще хранить не нужно. От подобных состояний хочется избавляться и дополнительно оповещать об этом прочие системы. Для этого необходимо с заданной периодичностью проверять состояния аггрегаторов на предмет устаревания и удалять их.
Простой способ это сделать — добавить периодическую задачу, например, с помощью Quartz. К тому же, Camel это сделать позволяет. Однако, необходимо помнить, что выполнение происходит в кластере со множеством равноправных серверов. И не очень хочется, чтобы периодические задачи Quartz срабатывали на всех одновременно. Во избежание этого, достаточно сделать синхронизацию опять же с помощью локов Hazelcast. Но как заставить Quartz инициализироваться только на одном сервере, вернее в какой момент производить синхронизацию?
Для инициализации Camel-контекста и всех остальных компонентов системы мы используем Spring, и чтобы заставить Quartz стартовать планировщик только на одном сервере из кластера, во-первых, необходимо отключить его автоматический запуск, явно объявив в контексте:
Во-вторых, нужно где-то произвести синхронизацию и запустить планировщик только если удалось захватить лок, а затем ожидать следующего момента его захвата (в случае, если предыдущий сервер, захвативший лок, вышел из строя или по какой-то причине его отпустил). Это в Spring можно реализовать несколькими вариантами, например, через ApplicationListener, который позволяет обработать события запуска контекста:
Получим следующую реализацию класса инициализации планировщика:
Таким образом, мы получим возможность использовать периодические задачи рекомендуемым в Camel способом и с учётом распределённой среды выполнения. Например, так:
Помимо простых способов аггрегации (например, подсчёта сумм), нам также часто было необходимо переключать состояния аггрегаторов в зависимости от поступающих сообщений, например, чтобы всегда помнить текущее состояние выполненного теста. Для реализации этой возможности хорошо подходят конечные автоматы. Представим, что у нас есть некоторое состояние теста. Например, TestPassedState. При получении сообщения TestFailed для данного теста мы должны переключить состояние аггрегатора в TestFailedState, а при получении TestPassed снова в TestPassedState. И так до бесконечности. На основе этих переходов можно делать некоторые выводы, например, если переход происходит TestPassed -> TestFailed, необходимо оповестить всех заинтересованных лиц о том, что тест сломался. А если происходит обратный переход, то, наоборот — рассказать им, что всё стало хорошо.
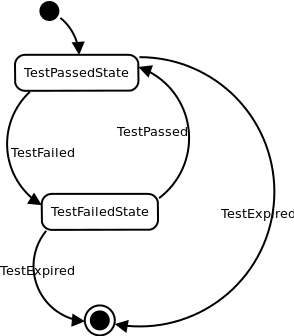
Подбирая варианты реализации подобной стратегии аггрегации, мы пришли к выводу, что необходима некая адаптированная к реалиям обработки сообщений модель конечных автоматов. Во-первых, сообщения поступающие на вход аггрегаторов — это некий набор объектов. Каждое событие имеет собственный тип, а следовательно легко ложится на классы в Java. Для описания типов событий мы используем xsd-схему, по которой с помощью xjc генерируем набор классов. Эти классы легко сериализуются и десериализуются в xml и json, с использованием jaxb. Состояния, хранящиеся в Hazelcast также представляются набором классов, сгенерированных по xsd. Таким образом, нам необходимо было найти реализацию конечных автоматов, позволяющую легко оперировать переходами между состояниями на основе типа сообщения и типа текущего состояния. И ещё хотелось, чтобы задавались эти переходы декларативно, а не императивно, как во множестве подобных библиотек. Легковесной реализации подобной функциональности мы не нашли, а поэтому решили написать свою собственную, учитывающую наши потребности и хорошо ложащуюся в основу обработки сообщений, приходящих по маршруту в Camel.
Небольшая библиотечка, реализующая наши потребности получила название Yatomata (от слов Yet Another auTomata) и доступна на github.
Было решено несколько упростить модель FSM — например, контекст задаётся объектом текущего состояния, сообщение также хранит некоторые данные. Однако, переходы при этом определяются только типами состояний и сообщений. Стейт-машина определяется для класса, который используется в качестве аггрегатора. Для этого класс помечается аннотацией @FSM. Для неё определено исходное состояние (start) и набор переходов, некоторые из которых останавливают аггрегацию (stop=true), автоматически отправляя накопленное состояние далее по маршруту.
Набор переходов декларируется аннотацией @Transitions и массивом аннотаций @Transit, в каждом из которых можно задать набор исходных состояний (from), конечное состояние (to), набор событий, по которым данный переход активируется (on), а также указать является ли это состояние окончанием работы машины (stop). Для обработки переходов предусмотрены аннотации @OnTransit, @BeforeTransit, а также @AfterTransit, которыми можно пометить публичные методы внутри класса. Эти методы будут вызваны в том случае, если найден соответствующий переход, удовлетворяющий его сигнатуре.
Работа со стейт-машиной осуществляется следующим образом:
Путём реализации интерфейса AggregationStrategy, мы создали FSMAggregationStrategy, объявление которого в контексте Spring происходит так:
Простейшая реализация стратегии аггрегации в случае использования этой стейт-машины может выглядеть следующим образом:
Перечисленные приёмы позволили нам реализовать несколько горизонтально масштабируемых сервисов различного назначения. Apache Camel показал себя с лучшей стороны и оправдал возложенные на него надежды. Декларативность сочетается в нём с высокой гибкостью, что в сумме обеспечивает отличное масштабирование интеграционных приложений с приложением минимума усилий на поддержку и добавление новой функциональности.
Введение
В основе модели Apache Camel лежит понятие маршрутов (routes), которые можно конфигурировать как статически (например, в файле Spring-контекста), так и во время работы приложения. По маршрутам ходят караваны сообщений, попутно попадая в различные обработчики, конверторы, аггрегаторы и прочие трансформеры, что в конечном итоге позволяет обработать данные из множества различных источников в едином приложении и передать эти данные другим сервисам или сохранить в какое-либо хранилище.
В общем и целом Camel — вполне самодостаточный фреймворк. Используя его, зачастую, даже не приходится писать собственный код — достаточно лишь набрать правильный маршрут, который позволит решить поставленную задачу. Однако, всё же для построения собственной модели обработки данных, может потребоваться написание кода.
Так было и у нас. Мы используем Camel для реализации конвейеров по обработке множества сообщений из различных источников. Подобный подход позволяет, например, следить за состоянием сервисов, своевременно оповещая о проблемах, получать аггрегированные аналитические срезы, готовить данные для отправки в другие системы и прочее. Поток обрабатываемых и «перевариваемых» сообщений в систему может быть довольно большим (тысячи сообщений в минуту), поэтому мы стараемся использовать горизонтально масштабируемые решения там, где это возможно. Например, у нас есть система отслеживания состояний выполняемых тестов и мониторингов сервисов. Подобных тестов выполняется по миллиону ежедневно, а сообщений для контроля процесса их выполнения мы получаем в разы больше.
Чтобы «усвоить» подобный объём сообщений, необходимо чётко определить стратегию аггрегации — от большего параллелизма к меньшему. Помимо этого необходимо иметь хотя бы базовую горизонтальную масштабируемость и отказоустойчивость сервиса.
В качестве очереди сообщений мы используем ActiveMQ, в качестве оперативного хранилища — Hazelcast.
Масштабирование
Для организации параллельной обработки организуется кластер из нескольких равноправных серверов. На каждом из них живёт брокер ActiveMQ, в очереди которого складываются сообщения, поступающие по HTTP-протоколу. HTTP-ручки находятся за балансировщиком, распределяющим сообщения по живым серверам.
Входную очередь сообщений на каждом сервере разбирает Camel-приложение, использующее кластер Hazelcast для хранения состояний, а также, при необходимости, синхронизации обработки. ActiveMQ также объеденены в кластер с использованием NetworkConnectors, и могут «делиться» сообщениями друг с другом.
В целом схема выглядит следующим образом:
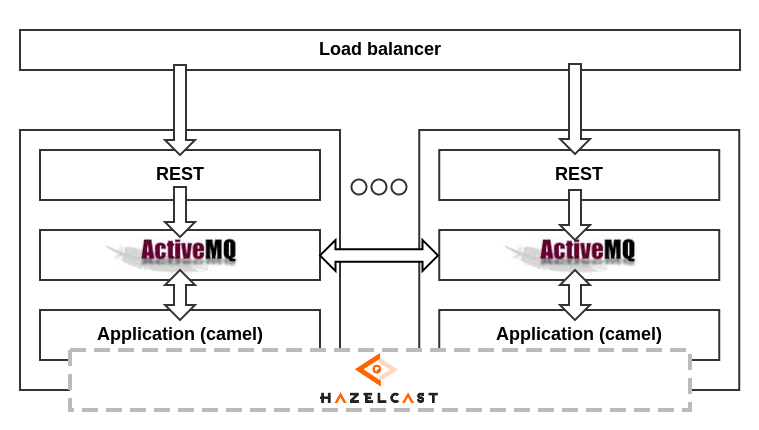
Как видно из схемы, выход из строя одного из компонентов системы не нарушает её работоспособность, с учётом равноправия элементов. К примеру, если выходит из строя обработчик сообщений на одном из серверов, ActiveMQ начинает отдавать сообщения из своих очередей другим. Если падает один из брокеров ActiveMQ, то обработчик «зацепляется» за соседний. Ну и наконец, если выходит из строя весь сервер, остальные сервера продолжают трудиться в поте лица, как ни в чём не бывало. Для повышения сохранности данных ноды Hazelcast хранят резервные копии данных своих соседей (копии осуществляются асинхронно, их число на каждой ноде настраивается дополнительно).
Данная схема также позволяет без особых затрат масштабировать сервис, добавляя дополнительные сервера, и тем самым увеличивая вычислительный ресурс.
Распределённые аггрегаторы
При использовании аггрегации Apache Camel включает понятия "aggregation repository" и "correlation key". Первое — это репозиторий, где хранятся аггрегированные состояния (например, число упавших тестов за день). Второе — это ключ, используемый для распределения потока сообщений по состояниям. Другими словами correlation key — это ключ в репозитории аггрегации (например, текущая дата).
Для аггрегаторов в подобной схеме нам понадобилась реализация своего собственного репозитория аггрегации, умеющего хранить состояния в Hazelcast и синхронизировать обработку одинаковых ключей внутри кластера. К сожалению, в стандартной поставке Camel мы подобной возможности не обнаружили. Благо создать его оказалось совсем несложно — достаточно реализовать интерфейс AggregationRepository:
Скрытый текст
public class HazelcastAggregatorRepository implements AggregationRepository {
private final Logger logger = LoggerFactory.getLogger(getClass());
// maximum time of waiting for the lock from hz
public static final long WAIT_FOR_LOCK_SEC = 20;
private final HazelcastInstance hazelcastInstance;
private final String repositoryName;
private IMap<String, DefaultExchangeHolder> map;
public HazelcastAggregatorRepository(HazelcastInstance hazelcastInstance, String repositoryName){
this.hazelcastInstance = hazelcastInstance;
this.repositoryName = repositoryName;
}
@Override
protected void doStart() throws Exception {
map = hazelcastInstance.getMap(repositoryName);
}
@Override
protected void doStop() throws Exception {
/* Nothing to do */
}
@Override
public Exchange add(CamelContext camelContext, String key, Exchange exchange) {
try {
DefaultExchangeHolder holder = DefaultExchangeHolder.marshal(exchange);
map.tryPut(key, holder, WAIT_FOR_LOCK_SEC, TimeUnit.SECONDS);
return toExchange(camelContext, holder);
} catch (Exception e) {
logger.error("Failed to add new exchange", e);
} finally {
map.unlock(key);
}
return null;
}
@Override
public Exchange get(CamelContext camelContext, String key) {
try {
map.tryLock(key, WAIT_FOR_LOCK_SEC, TimeUnit.SECONDS);
return toExchange(camelContext, map.get(key));
} catch (Exception e) {
logger.error("Failed to get the exchange", e);
}
return null;
}
@Override
public void remove(CamelContext camelContext, String key, Exchange exchange) {
try {
logger.debug("Removing '" + key + "' tryRemove...");
map.tryRemove(key, WAIT_FOR_LOCK_SEC, TimeUnit.SECONDS);
} catch (Exception e) {
logger.error("Failed to remove the exchange", e);
} finally {
map.unlock(key);
}
}
@Override
public void confirm(CamelContext camelContext, String exchangeId) {
/* Nothing to do */
}
@Override
public Set<String> getKeys() {
return Collections.unmodifiableSet(map.keySet());
}
private Exchange toExchange(CamelContext camelContext, DefaultExchangeHolder holder) {
Exchange exchange = null;
if (holder != null) {
exchange = new DefaultExchange(camelContext);
DefaultExchangeHolder.unmarshal(exchange, holder);
}
return exchange;
}
}
Чтобы воспользоваться подобным репозиторием, теперь нужно лишь подключить к проекту Hazelcast и объявить его в контексте, а затем добавить и набор репозиториев с указанием на инстанс Hazelcast. Важно помнить, что каждый аггрегатор должен иметь собственное пространство ключей, а поэтому ему необходимо передавать также имя репозитория. В настройках Hazelcast нужно прописать все сервера, которые входят в кластер.
Таким образом, мы получаем возможность использовать аггрегаторы в распределённой среде, не задумываясь о том на каком именно сервере произойдёт аггрегация.
Распределённые таймеры
Число состояний, хранящихся в кластере достаточно велико. Но не все из них нужны постоянно. К тому же, некоторые состояния (например, состояние тестов, которые давно не используются, а следовательно для них давно не было сообщений) вообще хранить не нужно. От подобных состояний хочется избавляться и дополнительно оповещать об этом прочие системы. Для этого необходимо с заданной периодичностью проверять состояния аггрегаторов на предмет устаревания и удалять их.
Простой способ это сделать — добавить периодическую задачу, например, с помощью Quartz. К тому же, Camel это сделать позволяет. Однако, необходимо помнить, что выполнение происходит в кластере со множеством равноправных серверов. И не очень хочется, чтобы периодические задачи Quartz срабатывали на всех одновременно. Во избежание этого, достаточно сделать синхронизацию опять же с помощью локов Hazelcast. Но как заставить Quartz инициализироваться только на одном сервере, вернее в какой момент производить синхронизацию?
Для инициализации Camel-контекста и всех остальных компонентов системы мы используем Spring, и чтобы заставить Quartz стартовать планировщик только на одном сервере из кластера, во-первых, необходимо отключить его автоматический запуск, явно объявив в контексте:
<bean id="quartz" class="org.apache.camel.component.quartz.QuartzComponent">
<property name="autoStartScheduler" value="false"/>
</bean>
Во-вторых, нужно где-то произвести синхронизацию и запустить планировщик только если удалось захватить лок, а затем ожидать следующего момента его захвата (в случае, если предыдущий сервер, захвативший лок, вышел из строя или по какой-то причине его отпустил). Это в Spring можно реализовать несколькими вариантами, например, через ApplicationListener, который позволяет обработать события запуска контекста:
<bean class="com.my.hazelcast.HazelcastQuartzSchedulerStartupListener">
<property name="hazelcastInstance" ref="hazelcastInstance"/>
<property name="quartzComponent" ref="quartz"/>
</bean>
Получим следующую реализацию класса инициализации планировщика:
Скрытый текст
public class HazelcastQuartzSchedulerStartupListener implements ShutdownPrepared, ApplicationListener {
public static final String DEFAULT_QUARTZ_LOCK = "defaultQuartzLock";
protected volatile boolean initialized = false;
Logger log = LoggerFactory.getLogger(getClass());
Lock lock;
protected volatile boolean initialized = false;
protected String lockName;
protected HazelcastInstance hazelcastInstance;
protected QuartzComponent quartzComponent;
public HazelcastQuartzSchedulerStartupListener() {
super();
log.info("HazelcastQuartzSchedulerStartupListener created");
}
public void setLockName(final String lockName) {
this.lockName = lockName;
}
public synchronized Lock getLock() {
if (lock == null) {
lock = hazelcastInstance.getLock(lockName != null ? lockName : DEFAULT_QUARTZ_LOCK);
}
return lock;
}
@Override
public void prepareShutdown(boolean forced) {
unlock();
}
@Required
public void setQuartzComponent(QuartzComponent quartzComponent) {
this.quartzComponent = quartzComponent;
}
@Required
public void setHazelcastInstance(HazelcastInstance hazelcastInstance) {
this.hazelcastInstance = hazelcastInstance;
}
@Override
public synchronized void onApplicationEvent(ApplicationEvent event) {
if (initialized) {
return;
}
try {
while (true) {
try {
getLock().lock();
log.warn("This node is now the master Quartz!");
try {
quartzComponent.startScheduler();
} catch (Exception e) {
unlock();
throw new RuntimeException(e);
}
return;
} catch (OperationTimeoutException e) {
log.warn("This node is not the master Quartz and failed to wait for the lock!");
}
}
} catch (Exception e) {
log.error("Error while trying to wait for the lock from Hazelcast!", e);
}
}
private synchronized void unlock() {
try {
getLock().unlock();
} catch (IllegalStateException e) {
log.warn("Exception while trying to unlock quartz lock: Hazelcast instance is already inactive!");
} catch (Exception e) {
log.warn("Exception during the unlock of the master Quartz!", e);
}
}
}
Таким образом, мы получим возможность использовать периодические задачи рекомендуемым в Camel способом и с учётом распределённой среды выполнения. Например, так:
<route id="quartz-route">
<from uri="quartz://quartz-test/test?cron=*+*+*+*+*+?"/>
<log message="Quartz each second message caught ${in.body.class}!"/>
<to uri="direct:queue:done-quartz"/>
</route>
Finite state machine
Помимо простых способов аггрегации (например, подсчёта сумм), нам также часто было необходимо переключать состояния аггрегаторов в зависимости от поступающих сообщений, например, чтобы всегда помнить текущее состояние выполненного теста. Для реализации этой возможности хорошо подходят конечные автоматы. Представим, что у нас есть некоторое состояние теста. Например, TestPassedState. При получении сообщения TestFailed для данного теста мы должны переключить состояние аггрегатора в TestFailedState, а при получении TestPassed снова в TestPassedState. И так до бесконечности. На основе этих переходов можно делать некоторые выводы, например, если переход происходит TestPassed -> TestFailed, необходимо оповестить всех заинтересованных лиц о том, что тест сломался. А если происходит обратный переход, то, наоборот — рассказать им, что всё стало хорошо.
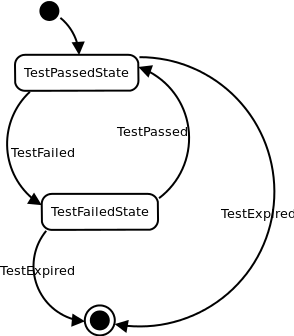
Подбирая варианты реализации подобной стратегии аггрегации, мы пришли к выводу, что необходима некая адаптированная к реалиям обработки сообщений модель конечных автоматов. Во-первых, сообщения поступающие на вход аггрегаторов — это некий набор объектов. Каждое событие имеет собственный тип, а следовательно легко ложится на классы в Java. Для описания типов событий мы используем xsd-схему, по которой с помощью xjc генерируем набор классов. Эти классы легко сериализуются и десериализуются в xml и json, с использованием jaxb. Состояния, хранящиеся в Hazelcast также представляются набором классов, сгенерированных по xsd. Таким образом, нам необходимо было найти реализацию конечных автоматов, позволяющую легко оперировать переходами между состояниями на основе типа сообщения и типа текущего состояния. И ещё хотелось, чтобы задавались эти переходы декларативно, а не императивно, как во множестве подобных библиотек. Легковесной реализации подобной функциональности мы не нашли, а поэтому решили написать свою собственную, учитывающую наши потребности и хорошо ложащуюся в основу обработки сообщений, приходящих по маршруту в Camel.
Небольшая библиотечка, реализующая наши потребности получила название Yatomata (от слов Yet Another auTomata) и доступна на github.
Было решено несколько упростить модель FSM — например, контекст задаётся объектом текущего состояния, сообщение также хранит некоторые данные. Однако, переходы при этом определяются только типами состояний и сообщений. Стейт-машина определяется для класса, который используется в качестве аггрегатора. Для этого класс помечается аннотацией @FSM. Для неё определено исходное состояние (start) и набор переходов, некоторые из которых останавливают аггрегацию (stop=true), автоматически отправляя накопленное состояние далее по маршруту.
Набор переходов декларируется аннотацией @Transitions и массивом аннотаций @Transit, в каждом из которых можно задать набор исходных состояний (from), конечное состояние (to), набор событий, по которым данный переход активируется (on), а также указать является ли это состояние окончанием работы машины (stop). Для обработки переходов предусмотрены аннотации @OnTransit, @BeforeTransit, а также @AfterTransit, которыми можно пометить публичные методы внутри класса. Эти методы будут вызваны в том случае, если найден соответствующий переход, удовлетворяющий его сигнатуре.
@FSM(start = Undefined.class)
@Transitions({
@Transit(on = TestPassed.class, to = TestPassedState.class),
@Transit(on = TestFailed.class, to = TestFailedState.class),
@Transit(stop = true, on = TestExpired.class),
})
public class TestStateFSM {
@OnTransit
public void onTestFailed(State oldState, TestFailedState newState, TestFailed event){}
@OnTransit
public void onTestPassed(State oldState, TestPassedState newState, TestPassed event){}
}
Работа со стейт-машиной осуществляется следующим образом:
Yatomata<TestStateFSM> fsm = new FSMBuilder(TestStateFSM.class).build();
fsm.getCurrentState(); // returns instance of Undefined
fsm.isStopped(); // returns false
fsm.getFSM(); // returns instance of TestStateFSM
fsm.fire(new TestPassed()); // returns instance of TestPassedState
fsm.fire(new TestFailed()); // returns instance of TestFailedState
fsm.fire(new TestExpired()); // returns instance of TestFailedState
fsm.isStopped(); // returns true
Путём реализации интерфейса AggregationStrategy, мы создали FSMAggregationStrategy, объявление которого в контексте Spring происходит так:
<bean id="runnableAggregator" class="com.my.FSMAggregationStrategy">
<constructor-arg value="com.my.TestStateFSM"/>
</bean>
Простейшая реализация стратегии аггрегации в случае использования этой стейт-машины может выглядеть следующим образом:
Скрытый текст
public class FSMAggregationStrategy<T> implements AggregationStrategy {
private final Yatomata<T> fsmEngine;
public FSMAggregationStrategy(Class fsmClass) {
this.fsmEngine = new FSMBuilder(fsmClass).build();
}
@Override
public Exchange aggregate(Exchange state, Exchange message) {
Object result = state == null ? null : state.getIn().getBody();
try {
Object event = message.getIn().getBody();
Object fsm = fsmEngine.getFSM();
result = fsmEngine.fire(event);
} catch (Exception e) {
logger.error(fsm + " error", e);
}
if (result != null) {
message.getIn().setBody(result);
}
return message;
}
public boolean isCompleted() {
return fsmEngine.isCompleted();
}
}
Выводы
Перечисленные приёмы позволили нам реализовать несколько горизонтально масштабируемых сервисов различного назначения. Apache Camel показал себя с лучшей стороны и оправдал возложенные на него надежды. Декларативность сочетается в нём с высокой гибкостью, что в сумме обеспечивает отличное масштабирование интеграционных приложений с приложением минимума усилий на поддержку и добавление новой функциональности.
