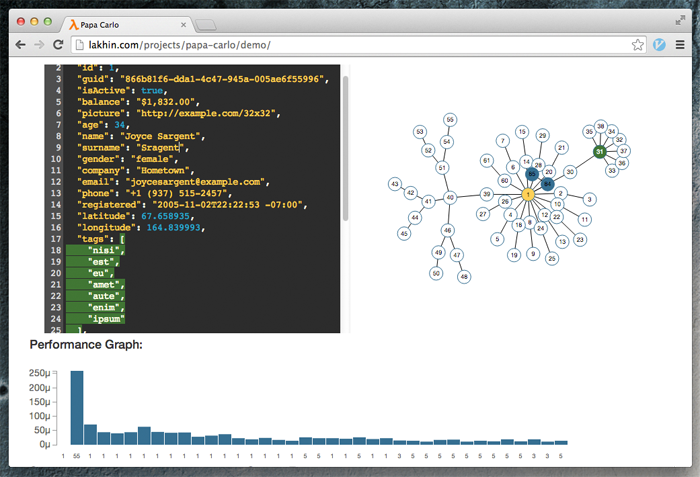
Уважаемые коллеги,
я сделал Демонстрационное веб-приложение, наглядно иллюстрирующее, что такое инкрементальный парсер, и как он работает. Посмотрите его, пожалуйста. Буду рад услышать ваши отзывы и критику.
А под катом я расскажу, о том, как работают современные IDE. И как проект, над которым я сейчас работаю, может помочь вывести индустрию разработки веб-редакторов на новый уровень.
Web IDE
В последнее время все больше набирают популярность IDE и редакторы кода, сделанные полностью на основе Веб технологий. Наверняка вам приходилось слышать о таких продуктах, как Cloud9, Koding, или о недавно вышедшем Atom от GitHub. А может быть даже и работать с ними.
Эти редакторы удобны тем, что предоставляют удаленный сервер разработки, и не требует специальных шагов для установки: вы просто открываете вкладку браузера, и получаете готовую к работе среду для программиста. Неплохое в общем-то решение для веб-разработчика, работающего с динамическими языками, такими как JavaScript, PHP, Ruby, Python.
Однако для языков со статической типизацией, например, для Java, C#, Objective-C, о конкурентноспособности веб-редакторов, по сравнению с такими гигантами рынка как IntelliJ Idea и Eclipse пока говорить не приходится. Ключевой особенностью последних является глубокое понимание синтаксиса и семантики исходных кодов, дающее нам такие инструменты, как code completion, jump to definition, рефакторинг, и подсветку ошибок. Это достаточно важно, особенно если мы работаем с большой базой кода.
Работа этих IDE основана на индексировании исходных кодов всего проекта: редактор использует специальные парсеры, называемые «инкрементальными парсерами/компиляторами», для непрерывного сканирования и поиска определений функций, переменных, мест, где они используются в коде.
Инкрементальный компилятор отличается от обычного компилятора целым рядом свойств:
- Непрерывное индексирование изменений. Обычный компилятор проходит весь код целиком, и заканчивает на этом свою работу. Если мы что-то поменяли в коде, то мы запускаем компилятор заново. Для IDE такой подход неприемлим, так как полная перекомпиляция исходных кодов после каждого введенного пользователем символа, будет создавать задержки на секунды, а то и минуты.
- Толерантность к синтаксическим ошибкам. В процессе набора программы, исходный код чаще находится в синтаксически некорректном состоянии. Тем не менее, IDE должна понимать остальные, корректные участки кода, например, чтобы функция code completion была доступна в любой момент.
- Связь между структурой Дерева разбора и текстом программы. Все узлы дерева разбора должны хранить в себе границы фрагментов кода, из которого они были получены. Например, чтобы при нажатии на имя функции в коде, IDE перебрасывала курсор на определение этой функции.
Разработка такого компилятора существенно отличается от техники разработки обычных компиляторов. К сожалению, на сегодняшний день в нашей индустрии практически отсутствуют инструменты для создания инкрементальных парсеров и компиляторов. Большинство существующих пишутся более-менее в ручную ценой больших трудозатрат и времени.
По этой причине я разработал библиотеку — Папа Карло — для построения инкрементальных парсеров. С помощью этой библиотеки можно создать инкрементальный парсер со всеми вышеперечисленными свойствами. Причем, API библиотеки внешне выглядит, как API обычных парсер-комбинаторов, с которыми привыкли работать большинство разработчиков компиляторов: вы просто описываете грамматику языка в PEG нотации.
Демонстрационный пример выше написан целиком с использованием библиотеки Папа Карло, и работает полностью на стороне клиента, в браузере. Данный подход можно было бы использовать для разработки плагинов для языков со статической типизацией, например, к существующим Web IDE. Или даже для редакторов кода вроде Sublime Text, превращая их тем самым в полноценные IDE.
Немного о том, что под капотом у этой демки
Сама библиотека Папа Карло написана на языке Scala, и скомпилирована в JavaScript с использованием компилятора ScalaJS. Таким образом, все вычисления производятся целиком на стороне клиента, в вашем браузере. С сервера отдается только статический контент: JS и HTML файлы.
Парсер запускается в веб-воркере(если они поддерживаются браузером). Это позволяет снять нагрузку с пользовательского интерфейса, а также осуществлять параллельные вычисления.
Все графики сделаны с помощью SVG и библиотеки d3.js. В качестве виджета редактора кода используется CodeMirror.
Друзья, если вам понравилось это Демо, пожалуйста, поддержите проект, поставьте ему звездочку на GitHub: https://github.com/Eliah-Lakhin/papa-carlo.
