
В данном посте я хочу рассказать о простом алгоритме предложения на основании сделанных ранее выборов. Для этого, прежде всего, поставим две задачи:
- Выбрать случайное значение из массива
- Выбрать случайное значение из массива на основании веса значений
Наверняка многие заметят, что для решения первой задачи существуют готовые функции во многих ЯП. Однако, я буду
Для решения я буду использовать псевдокод, чем-то похожий на Javascript. Потому, мой метод random() будет возвращать значение от 0 до 1.
Итак, задача 1
Можно просто перебрать массив в каждой итерации получая случайным образом true/false, можно воспользоваться распространённым решением для Javascript вида
Math.floor(Math.random() * maxNumber), что, кстати, и является сокращённой версией решения, которое буду использовать я.Решение
Делим интервал чисел от 0 до 1 на равные
n отрезков и берём ближайшее предыдущее значение от random: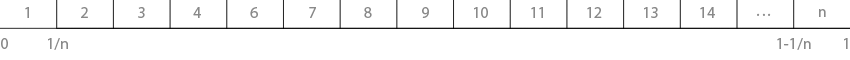
Практическая часть
Для простоты, возьмём массив из 150 элементов, содержащий только собственные индексы. То есть, числовой ряд от 0 до 150.
maxNumber = 150; // максимальный индекс или длина массива
elementPart = 100 / maxNumber / 100; // процентная доля значения в массиве, в данном случае это 0.66%
randomResult = random();
cursor = 0;
for (i = 0; i <= maxNumber; i++) {
cursor += elementPart;
if (cursor >= randomResult) {
result = i;
break;
}
}
Задача 2
Введём некоторые исходные данные:
items = [
{id: 1, score: 4},
{id: 2, score: 0},
{id: 3}
]
Где
score — некоторая величина (кол-во очков), изменяющая «вес» значения перед другими значениями. Очки можно начислять за выбор значения или за схожесть этого значения с выбранным однажды значением. Правила начисления очков ограничены только фантазией и конкретной ситуацией применения.Внимательный читатель успел заметить, что 0 очков не есть значение по умолчанию. Это сделано для того, чтобы можно было исключить значение из выборки, потому кол-во очков по умолчанию возьмём за 1. Для этого подкорректируем исходные данные:
for (i = 0; i < items.length; i++) {
item = items[i];
if (item.score === 0) {
item.remove(); // убираем значение из массива
continue;
}
if (item.score === null) {
item.score = 1; // если score отсутствует, ставим по умолчанию 1
}
}
Решение
Суть решения заключается в изменении отрезков значений в интервале от 0 до 1.
Пример:

Практическая часть
Добавляем рассчёт веса значения:
sumScores = 0;
for (i = 0; i < items.length; i++) { // считаем сумму всех очков
sumScores += items[i].score;
}
for (i = 0; i < items.length; i++) {
weight = items[i].score / sumScores;
items[i].weight = weight;
}
Здесь вес — это процентная доля от суммы очков всех элементов.
Вычисляем сумму весов и дарабатываем решение к задаче 1:
sumWeights = 0
for (i = 0; i < items.length; i++) { // считаем сумму всех весов
sumWeights += items[i].weight;
}
cursor = 0;
for (i = 0; i < items.length; i++) {
cursor += items[i].weight / sumWeights;
if (cursor >= randomResult) {
suggestedItem = items[i];
break;
}
}
Таким образом, получаем значение с id = 1 с большей вероятностью, чем с id = 3. Однако, в таком случае мы рано или поздно прийдём к тому, что предлагаться будут одни и те же значения (при условии роста кол-ва очков и если, конечно, искусственно не исключать их из выборки).
Такое решение вполне применимо к системам, где пользователю нужно предложить что-то наиболее похожее — просто составляем score нужных значений по своему вкусу (одинаковый цвет, одинаковый тип, может быть, один и тот же производитель) не забывая исключать выбранное значение выставляя score в 0.
Если нужно наборот, с наименьшей вероятностью показывать подобные товары (например, зачем человеку второй пылесос, если он его только что купил?) или предлагать попробовать что-то новое, не выбрасывая из выборки приобретённый товар (например, заказ еды или товары-расходники (аромат электронных сигарет, etc.)), тогда необходимо внести небольшие коррективы в рассчёт весов:
for (i = 0; i < items.length; i++) {
weight = 1 - items[i].score / sumScore;
if (items[i].score == sumScore) {
weight = 1;
}
items[i].weight = weight;
}
Где вес — инвертированное значение к процентной доле.
На случай, если у нас только один элемент в списке имеет ненулевой счёт проверяем и присваиваем 1 весу этого элемента.
Теперь, прибавляя к score очко каждый раз, как сделан выбор этого значения мы отодвигаем его дальше (при этом не исключая из выборки), предлагая альтернативные варианты пользователю.
Эти два подхода можно комбинировать: например, предлагаем пользователю производителя, товары которого он обычно приобретает, но при этом предлагаем товары которые он ещё не приобрёл.
Демо:
По теме
Почитать про многокритериальный выбор альтернатив и правила нечёткого выбора можно здесь.
