
В этой статье речь пойдет о довольно необычном проекте. Однажды меня посетило желание написать свой интерпретатор какого-нибудь скриптового языка и исполняющую машину для него. Просто для того, чтобы посмотреть, как оно внутри работает. Такая цель звучит не очень благородно и я отложил затею в долгий ящик, т.к. мне хотелось более полезной формулировки.
Как-то раз, один мой знакомый посетовал, что нужно написать скрипт автоматизации на WSH, но ни VBScript, ни Javascript он не знает. Тут «благородная» формулировка возникла сама собой… нужно помочь товарищу. В результате был написан компилятор и исполняющая машина, позволяющая исполнять скрипты для Windows Script Host, не прибегая к VBScript и JS. Под катом — краткая предыстория проекта и его внутреннее устройство и сам язык программирования.
Краткая предыстория
Господа, я раскрою вам страшную тайну. Я знаю, что признаться в таком грехе — очень стыдно, но тем не менее, признаюсь. Я — один-эсник. Да-да-да, я пишу большие и малые решения с помощью желтого фреймворка и совесть меня не мучает))).
Помимо 1С я знаю и другие языки, но я молодой, могу себе позволить. Мой знакомый, которого я упомянул во введении — наоборот — военный отставник, хороший инженер-электронщик, переучился в программисты, когда вышел на гражданку. Для грамотного технаря такая переквалификация — несложное дело, платят в сфере 1С неплохо, а хорошим спецам — так и вовсе хорошо. Однако, с возрастом все труднее становится гнаться за новыми технологиями, все сложнее следить за стремительно меняющимся миром IT. Когда состоялся упомянутый разговор, он сказал что-то вроде: «Да это долго, новый язык учить, вот если бы такой скрипт на 1С можно было написать, но чтоб в консоли выполнялся…» Тогда-то я и вспомнил свою старую идею с написанием интерпретатора, которая теперь из чисто исследовательской получала вполне прикладную направленность — выполнение скриптов, работающих с инфраструктурой WSH, но на языке 1С.
Немного о языке программирования
Про язык 1С говорят, что это Visual Basic, переведенный промтом. Это действительно так. По духу язык очень близок к VB — в нем нестрогая типизация, нет ООП, лямбда-выражений и замыканий. В нем «словесный», а не «сишный» синтаксис. Кроме того, поскольку все ключевые слова имеют английские аналоги, то код 1С, написанный в английских терминах отличить с первого взгляда от VB почти невозможно. Разве что символ комментария — две косые черты, а не апостроф, как в бейсике.
Язык различает процедуры и функции, имеет классические циклы «For» и «While», а также итераторный цикл «For Each … In». Обращение к свойствам и методам объектов выполняется «через точку», обращение к массивам — в квадратных скобках. Каждый оператор завершается точкой с запятой.
Что такое «стековая машина» и как она работает
Насколько мне известно, стековые машины являются наиболее распространенными. Например, виртуальные машины .NET CLR и JVM являются стековыми. На хабре даже есть отдельная статья про это дело. Тем не менее, чтобы не гонять читателя по ссылкам, думаю, что стоит описать принцип их работы и здесь. Стековая машина выполняет все операции над данными, которые организованы в виде стека. Каждая операция извлекает из стека нужное ей количество операндов, выполняет над ними действия и кладет результат обратно в стек. Такой подход позволяет создать легковесный байт-код с минимумом команд. Кроме того, он еще и довольно шустро работает.
Байт-код — это набор команд, которые будет выполнять машина.
Каждая инструкция представляет собой однобайтовый код операции от 0 до 255, за которым следуют такие параметры, как регистры или адреса памяти (википедия).
В нашей машине команда будет иметь фиксированную длину и состоять из двух чисел — кода операции и аргумента операции. Каждая команда подразумевает набор действий над данными в стеке.
Например, псевдокод операции сложения «1+2» может выглядеть следующим образом:
Push 1
Push 2
AddПервые две команды кладут в стек слагаемые, третья команда выполняет сложение и кладет результат в стек. В таком случае, операция присваивания «A = 1 + 2» может выглядеть так:
Push 1 ; поместить в стек "1"
Push 2 ; поместить в стек "2"
Add ; извлечь из стека "1" и "2", сложить и поместить результат в стек.
LoadVar A ; извлечь значение из стека и записать в переменную "А"Видно, что команды Push и LoadVar имеют аргумент, команда Add в аргументе не нуждается.
Преимущество стековых вычислений в том, что операции выполняются в порядке их следования, не нужно обращать внимание на приоритеты операций. Что написано, то и выполняется. Перед выполнением операции ее операнды заталкиваются в стек. Такой способ описания выражений получил название "обратной польской записи"
Задача написания стековой машины сводится к «изобретению» необходимого набора команд, которые эта машина будет понимать.
Устройство компилятора
Задача компилятора — преобразовать код на заданном языке в байт-код машины, которая будет его выполнять. Классический компилятор имеет 3 компонента:
- Лексический анализатор (парсер)
- Синтаксический анализатор
- Генератор кода
Лексический анализатор разбивает хаотичный поток входящих символов на лексемы. Он выделяет из исходного текста слова, числа, строковые константы, знаки операций и превращает их в атомарные сущности, с которыми далее удобно работать.
Синтаксический анализатор проверяет, что набор лексем, которые дал ему лексический анализатор является осмысленным, что перед нами программа, а не бессмысленный набор букв.
Анализатор строит абстрактное синтаксическое дерево (AST), которое затем подается на вход генератора кода.
Генератор кода создает байт-код, обходя узлы синтаксического дерева.
Я начал писать компилятор по такой же трехзвенной схеме, но потом мне это показалось излишне правильным и в рамках данной задачи — ненужным. Поэтому, я отказался от AST и объединил синтаксический анализ с генерацией кода.
Компилятор в цикле запрашивает у парсера очередную лексему и, глядя на нее, генерирует код. Попутно проверяет, что лексема является разрешенной в данном контексте. AST в этой схеме оказывается лишним.
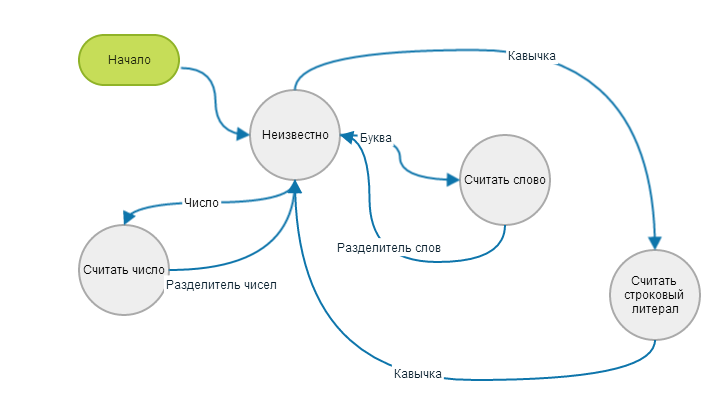
Конечный автомат
Парсер и компилятор удобнее реализовать в виде конечного автомата. При извлечении очередного символа делается вывод о том, в какой режим нужно переключиться, чтобы этот символ интерпретировать. Например, если на входе появилась буква, то переключаемся в режим считывания слова, если появилось число, то считываем в режиме числа и т.д. Каждое состояние определяет набор допустимых для себя входных символов. После извлечения лексемы, автомат переходит в предыдущее состояние. С генерацией кода — аналогично. Появился на входе IF, значит переключаемся в режим генерации условия, а по окончании — возвращаемся в предыдущее состояние.
Устройство виртуальной машины
Контексты видимости
Все переменные и методы всегда принадлежат к какому-либо контексту. Существует глобальный контекст, контекст модуля и локальный контекст внутри метода. Получается стек доступных (видимых) имен, к которому можно обращаться при выполнении. С этим стеком идет активная работа в момент компиляции и выполнения.Более того, если развить идею и предположить, что можно создавать экземпляры контекстов, то естественным образом возникает модульность. Если у нас есть некий модуль, как набор методов и переменных, то мы имеем контекст, в котором весь код этого модуля работает. Теперь, если мы создадим два экземпляра одного и того же модуля, то фактически мы создадим два экземпляра одного класса. Каждый из них будет видеть свой собственный контекст и иметь собственное состояние.
Документация 1С этого прямо не говорит, но наблюдаемое поведение позволяет сделать вывод, что выполнение модулей в исполняющей среде 1С работает именно таким образом. Исполняющая среда работает не с экземплярами объектов, а с контекстами, которые «присоединяются» к виртуальной машине по мере необходимости.
Память
Условная «память» машины представляет собой список подключенных к ней контекстов. Каждый контекст имеет свой номер и состояние (конкретные значения переменных). Команды чтения/записи переменных имеют аргумент в виде номера ячейки в таблице контекстов. Каждая запись в таблице описывает номер контекста и номер переменной в этом контексте, над которой выполняется действие.| Индекс | Номер контекста | Номер переменной |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 2 | 1 | 3 |
Например, если поступила команда PushVar 1, то в таблице по индексу 1 выбирается запись, в которой сказано — взять из контекста 0 переменную номер 1.
Переменные — это простой массив, который каждый подключенный контекст сообщает машине. Машина пишет и читает данные из этого массива, изменяя таким образом состояние подключенных контекстов. При этом неважно, что за контекст подключен — экземпляр какого-то класса или глобальный контекст. Машина умеет менять переменные, а что за переменные — не имеет значения.
Стек вызовов
Выполнение кода организовано с помощью так называемых «кадров», каждый из которых представляет собой набор локальных переменных и указатель на текущую инструкцию. При вызове какого-либо метода текущий кадр помещается в стек. Таким образом сохраняется состояние машины на момент вызова.
Затем формируется новый кадр с пустым массивом локальных переменных и номером инструкции, равным началу вызываемого метода. Этот новый кадр становится текущим и цикл выполнения команд продолжается уже с него.
По достижении команды Return текущий кадр уничтожается (вместе со значениями локальных переменных, которые вышли из области видимости), из стека вызовов извлекается сохраненный кадр с предыдущим состоянием и цикл исполнения команд продолжается с точки вызова.
Фрагмент псевдокода с вызовом метода.
0: Push 1
1: Push 2
2: Add
3: Return
4: Nop
5: Nop
6: Call 0
7: LoadVar
Предположим, что текущая инструкция имеет номер 6. Это вызов по адресу 0. Локальные переменные и номер текущей инструкции сохраняются в стеке вызовов. Далее, управление передается по адресу 0, а затем возвращается на адрес 6, где происходит переход далее, на очередную инструкцию.
Реализация команд
Все реализации команд представляют собой методы класса MachineInstance, а указатели на эти методы размещены в массиве кодов операций. При извлечении очередной команды, по ее номеру из массива извлекается указатель на реализацию и эта реализация выполняется. Попутно выполняется обработка исключений.
Основной цикл выполнения команд
private void ExecuteCode()
{
while (true)
{
try
{
MainCommandLoop();
break;
}
catch (RuntimeException exc)
{
if (_exceptionsStack.Count == 0)
throw;
var handler = _exceptionsStack.Pop();
SetFrame(handler.handlerFrame);
_currentFrame.InstructionPointer = handler.handlerAddress;
_lastException = exc;
}
}
}
private void MainCommandLoop()
{
try
{
while (_currentFrame.InstructionPointer >= 0
&& _currentFrame.InstructionPointer < _module.Code.Length)
{
var command = _module.Code[_currentFrame.InstructionPointer];
_commands[(int)command.Code](command.Argument);
}
}
catch (RuntimeException)
{
throw;
}
catch (Exception exc)
{
throw new ExternalSystemException(exc);
}
}
Устройство исполняемого модуля
В данной машине использована команда с одним числовым аргументом. Каждая команда определяется кодом операции и аргументом, трактовка которого зависит от самой команды. На этом принципе построена вся система команд и структура исполняемого модуля.
Для начала рассмотрим, из чего состоит исходный модуль в 1С.
Он имеет 3 явно выраженные секции:
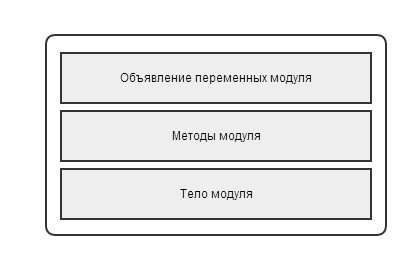
- В секции переменных объявляются все переменные уровня модуля, т.е. те, которые видны везде внутри модуля.
- Методы модуля — это собственно процедуры и функции с кодом
- Тело модуля, это код, который выполняется при загрузке модуля. Исполнение начинается именно с него.
Поскольку тело модуля — это по сути метод без имени, то можно сказать, что есть всего два вида разнотипных конструкций — объявление переменных и исполняемый код.
Константы
Очевидно, что все операции выполняются над некоторыми значениями. Значения, в свою очередь, представлены переменными и константами. К константам относятся литералы чисел, строк, дат, ключевые слова
Истина, Ложь и Неопределено. Для того чтобы сложить 2 и 2 любой вычислительной машине требуется объяснить, что такое «2» и где ее взять. Для этой цели в скомпилированный модуль включается описание всех констант, используемых в коде. Если в коде написано "
А = "Привет"", значит это слово «Привет» должно лежать в списке констант.Переменные
Имена переменных важны только в момент компиляции, чтобы разрешать области видимости. Во время исполнения имена переменных не нужны. Чтобы выделить память под массив переменных достаточно знать только их количество. При работе машины создается массив переменных, обращение к которому идет по номеру. В скомпилированном модуле указывается только количество переменных.
С переменными, однако, есть небольшое усложнение. Дело в том, что помимо переменных модуля существуют еще и глобальные переменные, объявленные где-то извне модуля. Как упоминалось выше — существует стек видимых имен, а компилятор, встречая некоторое имя, ищет его в стеке объявленных имен. Теоретически можно подключить несколько независимых библиотек со своими свойствами и функциями, которые будут видны клиентскому скрипту.
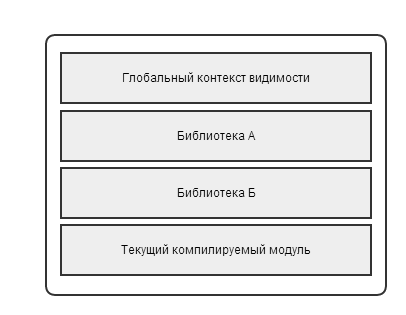
Если в коде используется переменная, то машина должна знать какому контексту она принадлежит. Поскольку у команды всего один числовой аргумент, то определять контекст, в котором эта переменная объявлена необходимо с помощью одного аргумента. С этой целью в модуль введена таблица переменных. каждая запись в таблице содержит номер контекста и номер переменной внутри контекста. Аргумент команды трактуется, как номер записи в таблице переменных (см. раздел «Память»).
Операции работы с переменными на стеке
private void PushVar(int arg)
{
var vm = _module.VariableRefs[arg];
var scope = _scopes[vm.ContextIndex];
_operationStack.Push(scope.Variables[vm.CodeIndex]);
NextInstruction();
}
private void LoadVar(int arg)
{
var vm = _module.VariableRefs[arg];
var scope = _scopes[vm.ContextIndex];
scope.Variables[vm.CodeIndex].Value = BreakVariableLink(_operationStack.Pop());
NextInstruction();
}
Методы
Методы разделяются на процедуры и функции. Последние могут возвращать значения. По умолчанию параметры в методы передаются по ссылке. Для передачи по значению параметр метода должен быть обозначен ключевым словом «Знач» (аналог ByVal в Бейсике).
В скомпилированном модуле содержится информация о параметрах метода, их обязательности, наличии возвращаемых значений и т.п. Каждый метод имеет свой номер. Кроме того, для каждого метода указывается количество локальных переменных этого метода.
Методы, как и переменные могут быть внешними, по отношению к модулю (т.е. объявленными где-то глобально). Обращение к методам организовано так же, как и в переменных — через таблицу соответствия, определяющую контекст, в котором находится вызываемый метод.
Конечная структура модуля
Объединим все вышесказанное и получим следующую структуру скомпилированного модуля:

После компиляции модуль представляет собой структуру, которая включает в себя:
- Количество переменных уровня модуля
- Перечень констант
- Перечень сигнатур методов
- Байт-код модуля
- Карту переменных
- Карту методов
- Номер метода, являющегося точкой входа в модуль (тело модуля)
Работа со значениями
Язык 1С не имеет строгой типизации. Переменная получает тип в момент присваивания ей значения. Любое значение имеет по сути универсальный тип VARIANT. При выполнении операций универсальное значение приводится с нужному типу. Например при арифметических действиях выполняется приведение к числу, а при булевых операциях — к булевым значениям.
Существуют следующие базовые типы значений:
- Неопределено
- Строка
- Число
- Дата
- Булево
- Объект
- Тип
Последний — это примитивный тип для работы с типами (аналог
System.Type в .NET)Универсальное значение представлено интерфейсом
IValue:interface IValue : IComparable<IValue>, IEquatable<IValue>
{
DataType DataType { get; }
TypeDescriptor SystemType { get; }
double AsNumber();
DateTime AsDate();
bool AsBoolean();
string AsString();
TypeDescriptor AsType();
IRuntimeContextInstance AsObject();
}
Интерфейс позволяет выяснить действительный тип значения, а также выполнить приведение к базовым типам. Такое приведение необходимо, например, для выполнения арифметических операций. Класс, реализующий конкретный тип значения сам пробует выполнить приведение своего значения к каждому из базовых типов.
При вычислении выражения тип конечного результата определяется по типу первого операнда. Так, выражение
"12345" + 10 должно выдать строковый результат. При выполнении сложения второй аргумент будет приведен к строке и выполнена конкатенация.Напротив, операция
10 + "12345" выполнит попытку приведения строки «12345» к числу. Если это приведение будет невозможным — возникает исключение «ошибка приведения к типу Число».В приведенных примерах у класса, реализующего тип «Число» вызывается метод AsString(), а у класса, реализующего тип «Строка» — метод AsNumber().
Операция сложения
private void Add(int arg)
{
var op2 = _operationStack.Pop();
var op1 = _operationStack.Pop();
var type1 = op1.DataType;
if (type1 == DataType.String)
{
var result = op1.AsString() + op2.AsString();
_operationStack.Push(ValueFactory.Create(result));
}
else if (type1 == DataType.Date && op2.DataType == DataType.Number)
{
var date = op1.AsDate();
var result = date.AddSeconds(op2.AsNumber());
_operationStack.Push(ValueFactory.Create(result));
}
else
{ // все к числовому типу.
var result = op1.AsNumber() + op2.AsNumber();
_operationStack.Push(ValueFactory.Create(result));
}
NextInstruction();
}
Доступ к свойствам и методам объектов
Каждый объект может иметь свойства и методы, к которым можно обратиться «через точку». Обращение выполняется по имени. Механика обращения по имени представлена специальным интерфейсом, который позволяет выяснять наличие у объекта нужных членов и обращение к ним.
interface IRuntimeContextInstance
{
bool IsIndexed { get; }
IValue GetIndexedValue(IValue index);
void SetIndexedValue(IValue index, IValue val);
int FindProperty(string name);
bool IsPropReadable(int propNum);
bool IsPropWritable(int propNum);
IValue GetPropValue(int propNum);
void SetPropValue(int propNum, IValue newVal);
int FindMethod(string name);
MethodInfo GetMethodInfo(int methodNumber);
void CallAsProcedure(int methodNumber, IValue[] arguments);
void CallAsFunction(int methodNumber, IValue[] arguments, out IValue retValue);
}
При обращении к свойству или методу у объекта запрашивается номер этого свойства/метода. Далее по этому номеру выполняется запрос о доступности чтения и записи свойства, количеству параметров метода, наличию возвращаемого значения и т.д. После выяснения этой информации выполняется вызов.
Для свойств это установка или чтение значения. Для методов — вызов как процедуры или вызов как функции. В последнем случае возвращенное значение кладется в стек виртуальной машины.
Работа с объектами как с контекстами и наоборот
Выше я упомянул о модульности и о создании объектов, как экземпляров контекстов. Давайте рассмотрим подробнее, что имелось в виду и как организовано обращение к объектам «через точку».
Представьте, что у нас есть некая библиотека функций. Мы можем вызывать функции из этой библиотеки и наслаждаться результатом. А теперь представьте, что библиотека — это экземпляр класса, с набором публичных методов и свойств. Этот экземпляр незаметно «встроен» в нашу область видимости так, что мы вызываем методы экземпляра напрямую, как если бы это были глобальные функции.
Если экземпляр класса "
MathLibrary" подключить в стек областей видимости, то функции Sin, Cos и Sqrt можно вызывать прямым обращением. Они будут видны, как обычные методы, объявленные где-то на уровне библиотек.А = Sin(X);
// Функция Sin является методом класса, который подключен к стеку областей видимости, поэтому она видна в текущей области видимости.
А теперь сделаем обратную операцию. Если мы написали какой-то скрипт, то он сам по себе является контекстом. Он предоставляет область видимости в которой работает код. А что, если мы создадим экземпляр этого скрипта и запишем его в переменную? Получится, что наш скрипт является классом, со своими свойствами и методами и с ним можно работать, как с объектом. На этом принципе построена возможность подключать (импортировать) внешние файлы скриптов, и работать с ними, как с объектами — создавать экземпляры, вызывать методы и т.п.
При этом когда скрипт А вызывает скрипт Б, то скрипт Б подключается в память машины, как контекст и исполнение кода Б идет, как если бы Б был единственным скриптом. При возврате из модуля Б он отсоединяется и выполнение снова переходит к скрипту А.
Примеры байт-кода
Ниже приведены примеры того, как организовано исполнение некоторых операций в байт-коде.
Сложение и присваивание
А = 1;
Б = 2;
В = А + Б;.constants
0 :type: Number, val: 1
1 :type: Number, val: 2
.code
0 :(PushConst 0) ; помещение константы 0 в стек
1 :(LoadLoc 0) ; запись из стека в локальную переменную 0
2 :(PushConst 1) ; помещение константы 1 в стек
3 :(LoadLoc 1) ; запись из стека в локальную переменную 1
4 :(PushLoc 0) ; помещение в стек переменной 0
5 :(PushLoc 1) ; помещение в стек переменной 1
6 :(Add 0) ; сложение и помещение результата в стек
7 :(LoadLoc 2) ; запись из стека в локальную переменную 2
Цикл с предусловием (While)
А = 1;
Пока А < 5 Цикл
А = А + 1;
КонецЦикла;.constants
0 :type: Number, val: 1
1 :type: Number, val: 5
.code
0 :(PushConst 0)
1 :(LoadLoc 0) ; запись начального значения в А
2 :(PushLoc 0) ; начало цикла (условие цикла)
3 :(PushConst 1)
4 :(Less 0) ; сравнение на "Меньше" с константой №1 (равной 5)
5 :(JmpFalse 11) ; если результат сравнения - Ложь, то переход в конец цикла (адрес 11)
6 :(PushLoc 0) ; выполнение А = А + 1
7 :(PushConst 0)
8 :(Add 0)
9 :(LoadLoc 0)
10 :(Jmp 2) ; переход в начало цикла на очередную итерацию
11 :(Nop 0) ; конец цикла
Условие
Если 1 > 2 Тогда
Б = 1;
Иначе
Б = 0;
КонецЕсли;.constants
0 :type: Number, val: 1
1 :type: Number, val: 2
2 :type: Number, val: 0
.code
0 :(PushConst 0)
1 :(PushConst 1)
2 :(Greater 0) ; вычисление условия "Больше"
3 :(JmpFalse 7) ; если результат условия - Ложь переход на "Иначе"
4 :(PushConst 0) ; тело блока Если
5 :(LoadLoc 0)
6 :(Jmp 9) ; конец блока Если, переход в конец условия
7 :(PushConst 2) ; тело блока Иначе
8 :(LoadLoc 0)
9 :(Nop 0); конец условия
Вызов метода
Сообщить("Привет");.constants
0 :type: String, val: Привет
.code
0 :(PushConst 0) ; запись константы в стек
1 :(ArgNum 1) ; запись в стек количества аргументов
2 :(CallProc 1) ; вызов метода, который указан в таблице методов за номером 1
.procmap
0 :(1,2)
1 :(0,4) ; процедура 1 расположена в контексте 0 и имеет там номер 4.
Что там было про WSH?
Инфраструктура скриптов WSH представлена рядом COM объектов. К этим объектам можно обращаться из скриптовых языков, обращаясь к их членам по имени, с помощью IDispatch. Ничего не напоминает?
Достаточно сделать небольшую обертку над IDispatch, которая позволит машине работать с этими COM-объектами через упомянутый интерфейс IRuntimeContextInstance.
На рисунке представлено окно тестового приложения, которое я использовал для отладки скриптов. В нем выполнен скрипт, перечисляющий метки дисков с помощью объекта Scripting.FileSystemObject
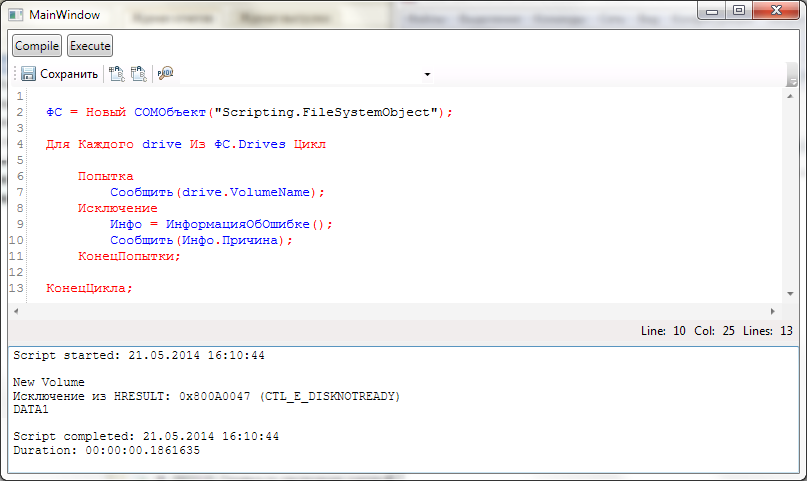
Конечно, на данный момент полностью все возможности WSH не реализованы и абсолютно полноценной заменой этот движок быть не может. Например, отсутствует возможность создания объектов WSH на удаленных машинах, а если покопать глубже, то и еще найдется много всего. Тем не менее, для большинства локальных задач, как мне кажется, этот движок вполне подойдет.
Исходники и прочее
Весь проект состоит из двух приложений и dll с движком машины.
Приложение TestApp — это вспомогательный GUI-based инструмент, в котором можно пробовать работу движка, писать тестовые скрипты и запускать их выполнение.
Консольное приложение oscript это основной инструмент работы в командной строке.
Поддерживаемые команды oscript показывает сам, если его запустить без параметров.
Есть также мысль сделать объединение скриптов и исполняющего приложения в один модуль, чтобы получался самостоятельный exe-файл. Но до этого пока руки не дошли.
Исходные коды доступны на bitbucket. Там же, коротенькое wiki о доступных языковых средствах.
Кому интересно посмотреть, как работает, но не хочется собирать из исходников — setup.exe
Короткое заключение
В рамках проекта разработан интерпретатор сценариев на языке 1С, включающий в себя стековую виртуальную машину, исполняющую сценарий и транслятор языка 1С в байт-код виртуальной машины.
Производительность получилась примерно сравнимой с оригиналом. Если учесть, что это любительский проект, сделанный «на коленке», то результат, полагаю, можно считать неплохим. Каких-то серьезных исследований по скорости я не проводил. Ради интереса можно посравнивать скорость математики и больших чисел, но это уже немного отдельная тема.
Надеюсь, данный опус был вам интересен. Форкайте проект, критикуйте, мне будет приятно. Удачи.
P.S. В комментариях к статье про 1С обязательно должно быть сообщение «Как можно писать операторы на русском языке?» :)
