
«Если человек умер, он об этом не знает, только другим тяжело. То же самое, когда он тупой...»
И то же самое, когда он безграмотный.
К сожалению, невозможно заставить всех людей выучить правила и начать писать без ошибок. Это факт, с которым нужно смириться — ошибки в интернете есть и будут.
А что, если подойти к этой проблеме с другой стороны? Как было бы здорово иметь такой браузер, который при открытии страницы проверял бы текст и исправлял все ошибки. Или хотя бы часть. Ведь, по правде говоря, ошибки воспринимаются по-разному: забытая запятая скорее всего останется незамеченной, в то время как какие-нибудь «извени» или «правельно» вызывают кратковременное бешенство.
Что будет, если перед чтением страницы пропустить ее через фильтр и исправить орфографию, наподобие того как adblock режет рекламу?
Наверняка такие идеи приходили не только мне, но поиски меня ни к чему не привели. Поэтому я решил сам провести такой эксперимент и хочу рассказать о результатах.
Забегая вперед, скажу, что результаты получились интересные, но проблему грамотности я таким образом решить не смог.
Тогда зачем эта статья, если ничего не получилось?
Отрицательный результат — тоже результат. Эту статью я пишу по двум причинам:
Во-первых, чтобы следующий человек, которому придет эта идея в голову, не изобретал все с нуля, а мог опереться на мои результаты.
А во-вторых, вдруг найдется человек, который сможет развить эту идею дальше.
Реализация
Реализация проста — я написал букмарклет (wiki). Загружаем страницу, нажимаем на букмарклет — запускается js-скрипт, который проверяет орфографию и исправляет ошибки.
Для проверки орфографии я использовал прекрасный сервис — Яндекс.Спеллер — api.yandex.ru/speller (Условия использования сервиса «API Яндекс.Спеллер» — legal.yandex.ru/speller_api ).
Замена выполняется на первое предложенное сервисом слово.
Имеется ограничение — запрос не должен превышать 10000 символов. Учитывая то, что 1 русская буква — это 6 символов в URL-encoded виде (буква «а» — это %D0%B0), то получается существенное ограничение. Весь текст приходится разбивать на несколько фрагментов. Для средней страницы какого-нибудь форума приходится выполнять десяток-другой запросов.
Для тех, кто хочет испытать скрипт на себе, исходный код — ссылка на bitbucket.
То же самое, но в одну строчку:
javascript:(function(){function main(){var text=document.body.innerHTML;text=text.replace(/<.*?>/g," "),text=text.replace(/[^а-яА-ЯёЁ]/g," "),text=text.replace(/\s+/g," ");var fragments=splitByLimit(text,1e4);for(var i=0,len=fragments.length;i<len;i++)checkAndReplace(fragments[i])}function splitByLimit(text,limit){var fragments=[],words=text.split(" "),fragment=[],fragmentLen=0;for(var i=0;i<words.length;i++){var word=words[i];fragmentLen+word.length*6>limit&&(fragments.push(fragment.join(" ")),fragment=[],fragmentLen=0),fragment.push(word),fragmentLen+=word.length*6+3,i==words.length-1&&fragments.push(fragment.join(" "))}return fragments}function checkAndReplace(text){var xhr=new XMLHttpRequest;xhr.onreadystatechange=function(){this.readyState==4&&(xhr.status==200?(data=JSON.parse(xhr.responseText),replaceWords(data)):console.log(xhr.status))},xhr.open("GET","http://speller.yandex.net/services/spellservice.json/checkText?options=7&text="+text,!0),xhr.send()}function replaceWords(data){if(!data)return;var body=document.body.innerHTML;for(var i=0,len=data.length;i<len;i++){var subst=data[i];if(subst.s.length!==0&&subst.word.length>4){var replacement='<span style="background-color: #cfc">'+subst.s[0]+" </span>";replacement+='<span style="background-color:#fcc"><span>'+subst.word.split("").join("</span><span>")+"</span></span>";var regexp=new RegExp(subst.word);body=body.replace(regexp,replacement)}}document.body.innerHTML=body}main()})();
Чтобы попробовать, нужно создать закладку в браузере и в поле URL вписать этот код.
Результаты
Первые впечатления — изумительно! Исправляет все ошибки. На удивление — исправляет даже географические названия, имена, названия компаний.
Вот несколько примеров.
Красным выделены исходные слова, зеленым — на что заменилось.
Пример 1:

Пример 2:
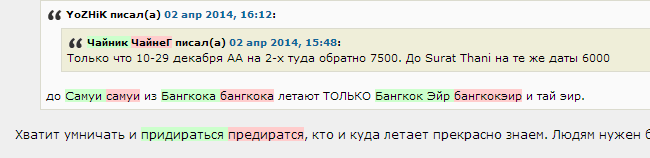
Пример 3:

Но, к сожалению, не все так радужно. Есть и обратная сторона — ложные срабатывания. Кажется, их даже побольше, чем исправленных ошибок. Особенно это заметно на тематических сайтах с переизбытком всяких терминов и сленга (как Хабр, например).
Пример 4:
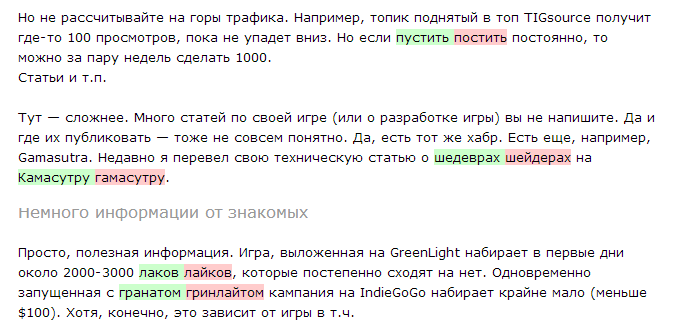
Пример 5:

Этот факт огорчает и сводит на нет все плюсы от использования скрипта.
Но все же надеюсь, что кому-то мои эксперименты оказались полезными.
