Ранее мы увидели как организована виртуальная память процесса. Теперь рассмотрим механизмы, благодаря которым ядро управляет памятью. Обратимся к нашей программе:
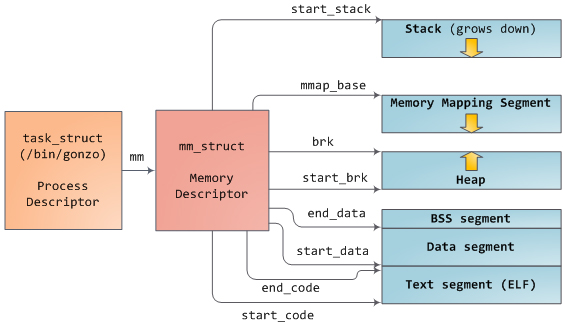
В Linux, процессы реализованы в виде struct-объекта task_struct, который по сути является дескриптором процесса. В поле mm объекта task_struct содержится указатель на т.н. «дескриптор памяти процесса» — struct-объект mm_struct — который содержит исчерпывающую информацию об использовании памяти данным процессом. В дескрипторе памяти процесса хранится информация о начальном и конечном адресе сегментов процесса, как показано на рисунке вверху, число page-фреймов (физических страниц в оперативной памяти), используемых процессом (это RSS или т.н. «резидентный набор страниц»), количество виртуальной памяти, выделенной процессу, и другая мелочь. Дескриптор памяти процесса также указывает на местонахождение дескрипторов VMA (virtual memory area или «область виртуальной памяти») и набора page-таблиц для процесса. Последние две структуры данных — это своего рода «рабочие лошадки», т.к. они задействуются при большинстве операций управления памятью. Области виртуальной памяти для нашей программы указаны на рисунке:
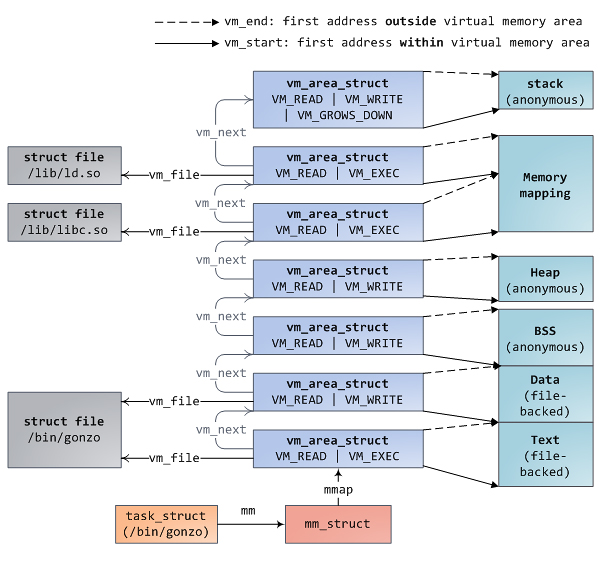
Область виртуальной памяти (VMA) представляет собой непрерывный диапазон виртуальных адресов; области никогда не перекрывают друг друга. Экземпляр struct-объекта vm_area_struct исчерпывающе описывает одну VMA, включая начальный и конечный виртуальный адрес области, флаги, определяющие права и другие особенности доступа к области, поле vm_file с информацией о файле, отображенном в данную область (если таковой файл имеется). Область виртуальной памяти, которая не сопоставлена ни с каким файлом, называется анонимной. Каждому из сегментов программы на вышеприведенном рисунке (куча, стек и т.д.) соответствует своя VMA; исключение в этом отношении состовляет только т.н. «сегмент для мэппирования» (memory mapping segment). Данное положение вещей не является каким-то требованием или чем-то предопределенным, но в случае с платформой x86 это в большинстве случаев именно так. Области виртуальной памяти все равно какому сегменту соответствовать.
Набор VMA для данного процесса описан сразу двумя способами. Во-первых, в дескрипторе памяти процесса (struct-объект mm_struct) имеется указатель mmap на связный список дескрипторов VMA (порядок дескрипторов в списке соответствует порядку следования VMA в виртуальном адресном пространстве). Во-вторых, все в том же дескрипторе памяти имеется указатель mm_rb на структуру, которая представляет собой red-black tree. RB-дерево позволяет ядру быстро устанавливать факт нахождения некоторого виртуального адреса в пределах той или иной виртуальной области. Если посмотреть содержимое файла /proc/pid_of_process/maps в файловой системе proc, то это будет не что иное как информация, полученная ядром в результате «прохода» по связному списку дескрипторов VMA.
В Windows, блок EPROCESS – это, грубо говоря, что-то среднее между структурами task_struct и mm_struct. Аналогом дескриптора области виртуальной памяти является Virtual Address Descriptor или VAD. Информация о VAD дескрипторах храниться в AVL-дереве. Знаете, что самое смешное при сравнении Windows и Linux? Это то, что отличий как раз не так уж и много.
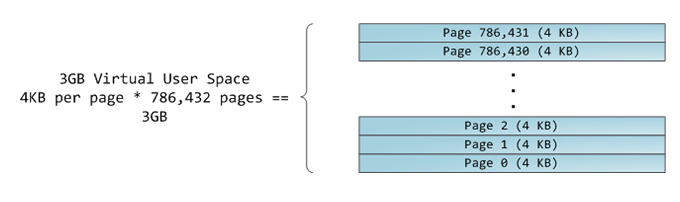
4-гигабайтное виртуальное адресное пространство представляется в виде последовательности страниц. 32-битные x86 процессоры поддерживают размер страниц равный 4 КБ, 2 МБ и 4 МБ. Linux и Windows используют 4-килобайтные страницы для user space-части виртуального адресного пространства. Байты 0-4095 попадают в страницу # 0, байты 4096-8191 попадают в страницу # 1 и т.д. Размер области VMA должен быть кратным размеру страницы. Вот так выглядит 3-гигабайтное user space пространство, организованное с помощью 4-килобайтных страниц:
Процессор консультируется с page-таблицами для того, чтобы осуществить преобразование виртуального адреса в физический. У каждого процесса есть свой набор таких page-таблиц; как только происходит переключение процесса (context switch), меняются и page-таблицы для user space-части виртуального адресного пространства. В Linux, указатель на page-таблицы процесса хранится в поле pgd дескриптора памяти процесса. Каждой виртуальной странице соответствует одна запись в page-таблице, и, в случае с классическим x86-пейджингом, это простая 4-байтовая запись, показанная на следующем рисунке:

В ядре Linux есть функции, которые позволяют взвести или обнулить любой флаг в page table записи. Флаг «P» говорит о том, находится ли страница в оперативной памяти или нет. Когда данный флаг установлен в 0, доступ к соответствующей странице вызовет page fault. Нужно учесть, что если данный флаг установлен в 0, то ядро может как угодно использовать оставшиеся биты в page table записи. Флаг «R/W» означает «запись/чтение»; если флаг не установлен, то к странице возможен доступ только на чтение. Флаг «U/S» означает «пользователь/супервайзер»; если флаг не установлен, только код выполняющийся с уровнем привилегий 0 (т.е. ядро) может обратиться к данной странице. Таким образом, данные флаги используются для того, чтобы реализовать концепцию адресного пространства доступного только на запись и пространства, которое доступно только для ядра.
Флаги «D» и «A» означают «dirty» и «accessed». «Dirty-страница» – эта та, в которую была недавно проведена запись, а «accessed»-страница – это страница, к которой было осуществлено обращение (чтение или запись). Оба флага являются «липкими», процессор может их установить, но не будет обнулять – делать это должно ядро. Наконец, page table запись хранит начальный физический адрес страницы в памяти; адрес всегда будет кратным 4 КБ. Это казалось бы безобидное поле является причиной многих проблем, т.к. оно фактически ограничивает размер адресуемой физической памяти 4 гигабайтами. Другие поля page table записи рассмотрим как-нибудь в другой раз, так же как и механизм Physical Address Extension.
Защита памяти осуществляется на постраничной основе, поскольку страница – это самый маленький «кусочек» памяти, для которого можно выставить флаги «U/S» и «R/W». Стоит однако учитывать, что теоретически, две разные виртуальные страницы, имеющие отличающийся набор флагов, могут соответствовать одной и той же физической странице. Заметьте, в формате page table записи не предусмотрены флаги, связанные с запретом на выполнение кода. Иными словами, классический x86-пейджинг никак не препятствует выполнению кода в стеке. Именно поэтому возможно эксплуатирование уязвимостей, в основе которых переполнение буфера в стеке (неисполняемые стеки все равно подвержены уязвимостям; в таком случае используется техника return-to-libc и другие приемы). Отсутсвие no-execute флага также свидетельствует о другом важном аспекте: флаги доступа, содержащиеся в дескрипторе VMA, не всегда имеют прямые соответствия в системе защиты, реализуемой процессором, и соответствуют этой системе лишь в большей или меньшей степени. Образно говоря, ядро делает все, что в его силах, но в конечном счете архитектура процессора накладывает свои ограничения на то, что возможно реализовать.
Конечно же виртуальная память сама по себе ничего не хранит. Виртуальное адресное пространство — это просто абстракция, но оно определенным образом поставлено в соответствие физической памяти. То, как работает адресная шина процессора, вообще говоря, вещь достаточно нетривиальная, но мы сейчас можем от этого абстрагироваться. Будем считать, что процессор работает с диапазоном последовательных адресов от нуля до максимально доступного в системе адреса (в зависимости от количества оперативной памяти) и может при необходимости обратиться к любому байту в этом диапазоне. Физическое адресное пространство рассматривается процессором как последовательность физических страниц (их еще называют page-фреймами). Процессору мало дела до page-фреймов, а вот для ядра они очень важны, т.к. page-фрейм – единица учета и управления физической памятью, которое и осуществляется ядром. 32-битные версии Linux и Windows используют 4-килобайтные page-фреймы; вот пример машины с 2 ГБ оперативной памяти:

Ядро Linux ведет учет каждому page-фрейму с помощью специального дескриптора и нескольких флагов. Взятые вместе, эти дескрипторы описывают всю оперативную память компьютера; в каждый момент времени известно точное состояние любого page-фрейма. В основе управления физической памятью лежит алгоритм Buddy memory allocation. Таким образом, page-фрейм считается свободным, если он доступен для выделения с точки зрения Buddy-алгоритма. Выделенный под использование page-фрейм может быть «анонимным» (в таком случае он содержит данные программы) или он может находиться в т.н. «страничном кэше» (page cache) и хранить порцию данных из некоторого файла или блочного устройства. Существуют и другие, более экзотичные варианты использования page-фреймов, но давайте не будем их сейчас трогать. В Windows также имеется аналогичная структура для учета page-фреймов, и называется она — база данных Page Frame Number.
А теперь, давайте соберем воедино все эти концепции – области виртуальной памяти (VMA), page table-записи и page-фреймы – и посмотрим как это все вместе работает. Далее идет пример кучи в user space области программы:
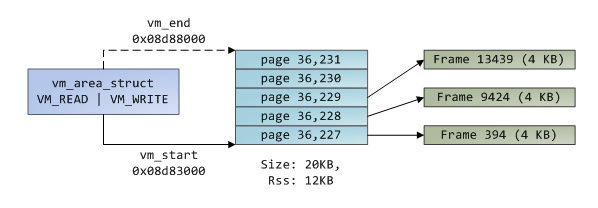
Прямоугольники с голубым фоном обозначают виртуальные страницы, находящиеся в пределах VMA. Стрелки обозначают page table-записи, с помощью которых виртуальные страницы «мэппируются» в page-фремы (физические страницы). У некоторых виртуальных страниц нет стрелок; это означает, что в соответствующих им page table записях флаг присутствия установлен в 0. Причиной тому может быть то, что данные виртуальные страницы возможно не разу еще не использовались или же потому, что соответствующие им физические страницы были выгружены в своп. В любом случае, попытка доступа к этим страницам приведет к page fault, даже несмотря на то, что виртуальные страницы находятся в пределах некоторой VMA. Может показаться странным, что существует подобного рода разночтение – страницы в пределах VMA и тем не менее доступ к ним является невалидным – но так действительно часто происходит.
VMA представляет собой своего рода «контракт» между программой и ядром. Вы просите ядро выполнить какое-нибудь действие (например, выделить память или замэппировать файл), ядро говорит «без проблем» и создает новую или обновляет существующую VMA. Но ядро при этом не спешит выполнять сами эти действия; вместо этого оно отложит непосредственное выполнение запрошенного действия до того момента, пока не случится page fault. Получается, что ядро – это этакий «ленивый обманщик», и это является основополагающим принципом управления виртуальной памятью. Данный принцип применяется в большинстве ситуаций – некоторые из них могут быть вполне знакомыми, некоторые — неожиданными, но общее правило таково, что VMA лишь фиксирует, то о чем было договорено, в то время как page table-записи отражают то, что непосредственно было сделано ленивым ядром. Эти две структуры вместе учавствуют в управлении памятью программы; обе структуры играют определенную роль при обработке page fault, высвобождении памяти, выгрузке страниц в своп и т.д. Рассмотрим простой случай выделения памяти:
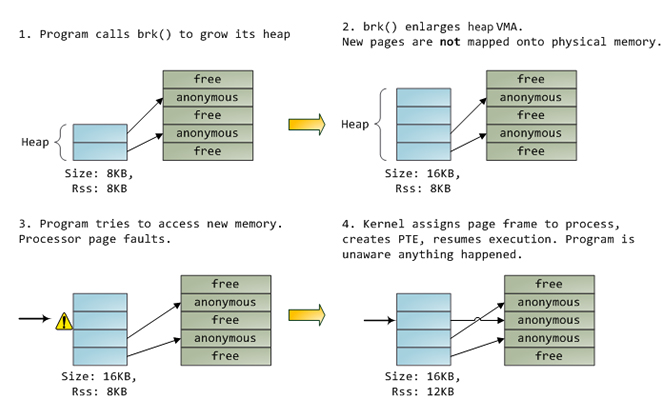
Когда программа запрашивает выделение дополнительной памяти посредством системного вызова brk(), ядро просто напросто обновляет информацию в дескрипторе VMA и на этом считает свою задачу выполненной. В данный момент времени не происходит ни выделение новых page-фреймов, ни размещение их в оперативной памяти. Однако, как только программа попытается обратиться к виртуальной странице, процессор отловит page fault и будет вызван обработчик do_page_fault(). Данная функция осуществит поиск VMA, в пределах которой находится адрес, обращение к которому вызвало page fault. Если такая VMA существует, то дальше прозводится проверка на соответствие между правами доступа к VMA и типом производимого доступа (доступ на чтение или запись). Если же подходящей VMA нет, тогда нет и «контракта», который предусматривал бы возможность обращения к памяти. В последнем случае, процессу посылается сигнал Segmentation Fault, и он завершается.
Допустим, VMA все-таки нашлась. Дальнейшая обработка page fault такая – ядро смотрит на содержимое page table записи и тип VMA. В нашем примере, page table запись свидетельствует о том, что страницы в памяти нет. Более того, наша запись совершенно пустая (состоит из одних нулей), и в Linux это означает, что соответствующая виртуальная страница вообще еще ни разу не была замэппирована. Поскольку мы имеем дело с «анонимной» VMA, то все дальнейшие действия будут связаны только с оперативной памятью, и для обработки данной ситуации вызывается функция do_anonymous_page(). Данная функция производит выделение page-фрейма и мэппирует в него виртуальную страницу путем внесения нужных данных в page table запись.
Дело могли обстоять и иначе. Page table запись для выгруженной в своп страницы, к примеру, имеет флаг присутствия установленный в 0, но остальная часть записи непустая. Остальные биты хранят информацию о нахождении страницы в свопе. Функция do_swap_page() считывает содержимое этой страницы с диска и загружает страницу в оперативную память. Подобного рода page fault называют major fault.
На этом завершим первую часть нашего экскурса в то, как ядро управляет памятью. В следующей статье мы усложним картину, дополнив её работой с файлами — таким образом получим более полное представление об основных концепциях управления памятью, включая и некоторые аспекты производительности.
Материал подготовлен сотрудниками компании Smart-Soft. Перевод статьи How the Kernel Manages Your Memory by Gustavo Duarte
smart-soft.ru
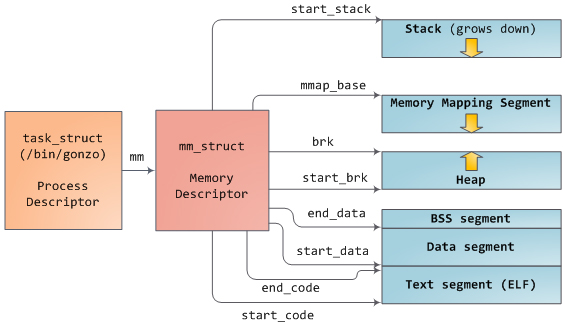
В Linux, процессы реализованы в виде struct-объекта task_struct, который по сути является дескриптором процесса. В поле mm объекта task_struct содержится указатель на т.н. «дескриптор памяти процесса» — struct-объект mm_struct — который содержит исчерпывающую информацию об использовании памяти данным процессом. В дескрипторе памяти процесса хранится информация о начальном и конечном адресе сегментов процесса, как показано на рисунке вверху, число page-фреймов (физических страниц в оперативной памяти), используемых процессом (это RSS или т.н. «резидентный набор страниц»), количество виртуальной памяти, выделенной процессу, и другая мелочь. Дескриптор памяти процесса также указывает на местонахождение дескрипторов VMA (virtual memory area или «область виртуальной памяти») и набора page-таблиц для процесса. Последние две структуры данных — это своего рода «рабочие лошадки», т.к. они задействуются при большинстве операций управления памятью. Области виртуальной памяти для нашей программы указаны на рисунке:

Область виртуальной памяти (VMA) представляет собой непрерывный диапазон виртуальных адресов; области никогда не перекрывают друг друга. Экземпляр struct-объекта vm_area_struct исчерпывающе описывает одну VMA, включая начальный и конечный виртуальный адрес области, флаги, определяющие права и другие особенности доступа к области, поле vm_file с информацией о файле, отображенном в данную область (если таковой файл имеется). Область виртуальной памяти, которая не сопоставлена ни с каким файлом, называется анонимной. Каждому из сегментов программы на вышеприведенном рисунке (куча, стек и т.д.) соответствует своя VMA; исключение в этом отношении состовляет только т.н. «сегмент для мэппирования» (memory mapping segment). Данное положение вещей не является каким-то требованием или чем-то предопределенным, но в случае с платформой x86 это в большинстве случаев именно так. Области виртуальной памяти все равно какому сегменту соответствовать.
Набор VMA для данного процесса описан сразу двумя способами. Во-первых, в дескрипторе памяти процесса (struct-объект mm_struct) имеется указатель mmap на связный список дескрипторов VMA (порядок дескрипторов в списке соответствует порядку следования VMA в виртуальном адресном пространстве). Во-вторых, все в том же дескрипторе памяти имеется указатель mm_rb на структуру, которая представляет собой red-black tree. RB-дерево позволяет ядру быстро устанавливать факт нахождения некоторого виртуального адреса в пределах той или иной виртуальной области. Если посмотреть содержимое файла /proc/pid_of_process/maps в файловой системе proc, то это будет не что иное как информация, полученная ядром в результате «прохода» по связному списку дескрипторов VMA.
В Windows, блок EPROCESS – это, грубо говоря, что-то среднее между структурами task_struct и mm_struct. Аналогом дескриптора области виртуальной памяти является Virtual Address Descriptor или VAD. Информация о VAD дескрипторах храниться в AVL-дереве. Знаете, что самое смешное при сравнении Windows и Linux? Это то, что отличий как раз не так уж и много.
4-гигабайтное виртуальное адресное пространство представляется в виде последовательности страниц. 32-битные x86 процессоры поддерживают размер страниц равный 4 КБ, 2 МБ и 4 МБ. Linux и Windows используют 4-килобайтные страницы для user space-части виртуального адресного пространства. Байты 0-4095 попадают в страницу # 0, байты 4096-8191 попадают в страницу # 1 и т.д. Размер области VMA должен быть кратным размеру страницы. Вот так выглядит 3-гигабайтное user space пространство, организованное с помощью 4-килобайтных страниц:

Процессор консультируется с page-таблицами для того, чтобы осуществить преобразование виртуального адреса в физический. У каждого процесса есть свой набор таких page-таблиц; как только происходит переключение процесса (context switch), меняются и page-таблицы для user space-части виртуального адресного пространства. В Linux, указатель на page-таблицы процесса хранится в поле pgd дескриптора памяти процесса. Каждой виртуальной странице соответствует одна запись в page-таблице, и, в случае с классическим x86-пейджингом, это простая 4-байтовая запись, показанная на следующем рисунке:

В ядре Linux есть функции, которые позволяют взвести или обнулить любой флаг в page table записи. Флаг «P» говорит о том, находится ли страница в оперативной памяти или нет. Когда данный флаг установлен в 0, доступ к соответствующей странице вызовет page fault. Нужно учесть, что если данный флаг установлен в 0, то ядро может как угодно использовать оставшиеся биты в page table записи. Флаг «R/W» означает «запись/чтение»; если флаг не установлен, то к странице возможен доступ только на чтение. Флаг «U/S» означает «пользователь/супервайзер»; если флаг не установлен, только код выполняющийся с уровнем привилегий 0 (т.е. ядро) может обратиться к данной странице. Таким образом, данные флаги используются для того, чтобы реализовать концепцию адресного пространства доступного только на запись и пространства, которое доступно только для ядра.
Флаги «D» и «A» означают «dirty» и «accessed». «Dirty-страница» – эта та, в которую была недавно проведена запись, а «accessed»-страница – это страница, к которой было осуществлено обращение (чтение или запись). Оба флага являются «липкими», процессор может их установить, но не будет обнулять – делать это должно ядро. Наконец, page table запись хранит начальный физический адрес страницы в памяти; адрес всегда будет кратным 4 КБ. Это казалось бы безобидное поле является причиной многих проблем, т.к. оно фактически ограничивает размер адресуемой физической памяти 4 гигабайтами. Другие поля page table записи рассмотрим как-нибудь в другой раз, так же как и механизм Physical Address Extension.
Защита памяти осуществляется на постраничной основе, поскольку страница – это самый маленький «кусочек» памяти, для которого можно выставить флаги «U/S» и «R/W». Стоит однако учитывать, что теоретически, две разные виртуальные страницы, имеющие отличающийся набор флагов, могут соответствовать одной и той же физической странице. Заметьте, в формате page table записи не предусмотрены флаги, связанные с запретом на выполнение кода. Иными словами, классический x86-пейджинг никак не препятствует выполнению кода в стеке. Именно поэтому возможно эксплуатирование уязвимостей, в основе которых переполнение буфера в стеке (неисполняемые стеки все равно подвержены уязвимостям; в таком случае используется техника return-to-libc и другие приемы). Отсутсвие no-execute флага также свидетельствует о другом важном аспекте: флаги доступа, содержащиеся в дескрипторе VMA, не всегда имеют прямые соответствия в системе защиты, реализуемой процессором, и соответствуют этой системе лишь в большей или меньшей степени. Образно говоря, ядро делает все, что в его силах, но в конечном счете архитектура процессора накладывает свои ограничения на то, что возможно реализовать.
Конечно же виртуальная память сама по себе ничего не хранит. Виртуальное адресное пространство — это просто абстракция, но оно определенным образом поставлено в соответствие физической памяти. То, как работает адресная шина процессора, вообще говоря, вещь достаточно нетривиальная, но мы сейчас можем от этого абстрагироваться. Будем считать, что процессор работает с диапазоном последовательных адресов от нуля до максимально доступного в системе адреса (в зависимости от количества оперативной памяти) и может при необходимости обратиться к любому байту в этом диапазоне. Физическое адресное пространство рассматривается процессором как последовательность физических страниц (их еще называют page-фреймами). Процессору мало дела до page-фреймов, а вот для ядра они очень важны, т.к. page-фрейм – единица учета и управления физической памятью, которое и осуществляется ядром. 32-битные версии Linux и Windows используют 4-килобайтные page-фреймы; вот пример машины с 2 ГБ оперативной памяти:

Ядро Linux ведет учет каждому page-фрейму с помощью специального дескриптора и нескольких флагов. Взятые вместе, эти дескрипторы описывают всю оперативную память компьютера; в каждый момент времени известно точное состояние любого page-фрейма. В основе управления физической памятью лежит алгоритм Buddy memory allocation. Таким образом, page-фрейм считается свободным, если он доступен для выделения с точки зрения Buddy-алгоритма. Выделенный под использование page-фрейм может быть «анонимным» (в таком случае он содержит данные программы) или он может находиться в т.н. «страничном кэше» (page cache) и хранить порцию данных из некоторого файла или блочного устройства. Существуют и другие, более экзотичные варианты использования page-фреймов, но давайте не будем их сейчас трогать. В Windows также имеется аналогичная структура для учета page-фреймов, и называется она — база данных Page Frame Number.
А теперь, давайте соберем воедино все эти концепции – области виртуальной памяти (VMA), page table-записи и page-фреймы – и посмотрим как это все вместе работает. Далее идет пример кучи в user space области программы:

Прямоугольники с голубым фоном обозначают виртуальные страницы, находящиеся в пределах VMA. Стрелки обозначают page table-записи, с помощью которых виртуальные страницы «мэппируются» в page-фремы (физические страницы). У некоторых виртуальных страниц нет стрелок; это означает, что в соответствующих им page table записях флаг присутствия установлен в 0. Причиной тому может быть то, что данные виртуальные страницы возможно не разу еще не использовались или же потому, что соответствующие им физические страницы были выгружены в своп. В любом случае, попытка доступа к этим страницам приведет к page fault, даже несмотря на то, что виртуальные страницы находятся в пределах некоторой VMA. Может показаться странным, что существует подобного рода разночтение – страницы в пределах VMA и тем не менее доступ к ним является невалидным – но так действительно часто происходит.
VMA представляет собой своего рода «контракт» между программой и ядром. Вы просите ядро выполнить какое-нибудь действие (например, выделить память или замэппировать файл), ядро говорит «без проблем» и создает новую или обновляет существующую VMA. Но ядро при этом не спешит выполнять сами эти действия; вместо этого оно отложит непосредственное выполнение запрошенного действия до того момента, пока не случится page fault. Получается, что ядро – это этакий «ленивый обманщик», и это является основополагающим принципом управления виртуальной памятью. Данный принцип применяется в большинстве ситуаций – некоторые из них могут быть вполне знакомыми, некоторые — неожиданными, но общее правило таково, что VMA лишь фиксирует, то о чем было договорено, в то время как page table-записи отражают то, что непосредственно было сделано ленивым ядром. Эти две структуры вместе учавствуют в управлении памятью программы; обе структуры играют определенную роль при обработке page fault, высвобождении памяти, выгрузке страниц в своп и т.д. Рассмотрим простой случай выделения памяти:

Когда программа запрашивает выделение дополнительной памяти посредством системного вызова brk(), ядро просто напросто обновляет информацию в дескрипторе VMA и на этом считает свою задачу выполненной. В данный момент времени не происходит ни выделение новых page-фреймов, ни размещение их в оперативной памяти. Однако, как только программа попытается обратиться к виртуальной странице, процессор отловит page fault и будет вызван обработчик do_page_fault(). Данная функция осуществит поиск VMA, в пределах которой находится адрес, обращение к которому вызвало page fault. Если такая VMA существует, то дальше прозводится проверка на соответствие между правами доступа к VMA и типом производимого доступа (доступ на чтение или запись). Если же подходящей VMA нет, тогда нет и «контракта», который предусматривал бы возможность обращения к памяти. В последнем случае, процессу посылается сигнал Segmentation Fault, и он завершается.
Допустим, VMA все-таки нашлась. Дальнейшая обработка page fault такая – ядро смотрит на содержимое page table записи и тип VMA. В нашем примере, page table запись свидетельствует о том, что страницы в памяти нет. Более того, наша запись совершенно пустая (состоит из одних нулей), и в Linux это означает, что соответствующая виртуальная страница вообще еще ни разу не была замэппирована. Поскольку мы имеем дело с «анонимной» VMA, то все дальнейшие действия будут связаны только с оперативной памятью, и для обработки данной ситуации вызывается функция do_anonymous_page(). Данная функция производит выделение page-фрейма и мэппирует в него виртуальную страницу путем внесения нужных данных в page table запись.
Дело могли обстоять и иначе. Page table запись для выгруженной в своп страницы, к примеру, имеет флаг присутствия установленный в 0, но остальная часть записи непустая. Остальные биты хранят информацию о нахождении страницы в свопе. Функция do_swap_page() считывает содержимое этой страницы с диска и загружает страницу в оперативную память. Подобного рода page fault называют major fault.
На этом завершим первую часть нашего экскурса в то, как ядро управляет памятью. В следующей статье мы усложним картину, дополнив её работой с файлами — таким образом получим более полное представление об основных концепциях управления памятью, включая и некоторые аспекты производительности.
Материал подготовлен сотрудниками компании Smart-Soft. Перевод статьи How the Kernel Manages Your Memory by Gustavo Duarte
smart-soft.ru
