
В предыдущей части мы детально рассмотрели «читерские» приёмы обхода «защит» (скрытие SSID, MAC-фильтрация) и защит (WPS) беспроводных сетей. И хотя работает это в половине случаев, а иногда и чаще — когда-то игры заканчиваются и приходится браться за тяжёлую артиллерию. Вот тут-то между вашей личной жизнью и взломщиком и оказывается самое слабое звено: пароль от WPA-сети.
В статье будет показан перехват рукопожатия клиент-точка доступа, перебор паролей как с помощью ЦП, так и ГП, а кроме этого — сводная статистика по скоростям на обычных одиночных системах, кластерах EC2 и данные по разным типам современных GPU. Почти все они подкреплены моими собственным опытом.
К концу статьи вы поймёте, почему ленивый 20-значный пароль из букв a-z на пару солнц более стоек, чем зубодробительный 8-значный, даже использующий все 256 значений диапазона.
Оглавление:
1) Матчасть
2) Kali. Скрытие SSID. MAC-фильтрация. WPS
3) WPA. OpenCL/CUDA. Статистика подбора
PMK, PTK, РПГ

Как всегда, начнём с теории. Строго говоря, она нам не нужна, чтобы подбирать пароли, и кому лень — могут пропустить этот раздел до практики. Однако, на мой взгляд, знать, как происходит проверка подлинности клиента и шифрование данных — очень полезно и объяснит все трудности, которые мы, как атакующий, испытываем при попытке взломать этот протокол. Более детальное описание понятным английским языком с разбором форматов всех пакетов авторизации можно найти здесь.
WPA и WPA2 (первый основан на черновике IEEE, второй — на финальной версии, но в нашем случае оба можно считать синонимами) используют довольно хитрую схему обмена ключами. Вернее, их необмена. Как мы помним по первой части, самое слабое место в любой защите — это передача ключей, даже зашифрованных — ведь хакер может перехватить эти значения и попытаться подобрать по ним изначальный ключ в offline-режиме, то есть никак более не общаясь с точкой доступа или клиентом. Разработчики WPA устранили всякий обмен и шифрованными, и открытыми паролями. Как это всё работает как раз и будет описано ниже.
Начнём с конца. Допустим, мы хотим передать зашифрованный пакет данных. Для этого нам нужны сами данные и ключ, по которому алгоритм вроде AES (а именно он используется в CCMP) преобразует их в
Самый простой способ — использовать в виде ключа сам пароль от беспроводной сети. Однако это чревато серьёзными проблемами:
- Слишком быстрые вычисления — если мы знаем начальные байты исходных данных (а почти всегда это так, ведь в начале идёт какой-нибудь стандартный заголовок), то простым перебором мы сможем попробовать дешифровать перехваченный пакет, подставляя разные пароли и смотря, что получилось на выходе — если он содержит похожий на корректный заголовок, то скорее всего мы нашли исходный пароль.
- Гарантия на всю жизнь — если каким-то образом мы узнали пароль, то сможем расшифровать всё, что передавалось ранее и будет передано позднее, пока администратор не сменит ключ сети. А как показывает практика, даже при смене роутера люди обычно ставят на него старый пароль, так что надеяться на их благоразумие не, гм, благоразумно.
- Отсутствие защиты от любопытного соседа — если мы можем авторизоваться в сети, то ничто не помешает нам читать пакеты других клиентов и даже произвольно подменять их, так как
тапки одни на всехпароль, используемый для шифрования наших данных, используется и для всех остальных клиентов в рамках этой сети
Это похоже на то, как если бы между нами и конечной целью стояло много-много дверей, каждая из которых ведёт внутрь. Двери — клиенты сети, «нутрь» — сама сеть. Если ко всем дверям подходит одинаковый ключ, то мы можем пройти через соседнюю дверь и посмотреть, что там происходит.
Вторую и третью проблемы легко устранить, добавив к ключу случайное значение, которое меняется каждый раз при запуске защищённого соединения и даже в процессе его работы. Первую — очень длинным ключом. Но тогда встаёт вопрос:
Для этого есть два стандартных решения: либо введение ограничений на число попыток входа, либо многократное шифрование, чтобы замедлить процесс получения конечной строки. Первый вариант не подходит, так как он годится для online-атак (обычно на формы входа на веб-сайты) и бесполезен, когда сам хэш уже «утёк». А вот второй — как раз наш случай.
Однако и тут есть проблема: если мы просто прогоняем некий алгоритм 10 000 раз на нашей исходной строке с паролем, то возможен вариант, когда хакер создаст словарь, предварительно прогнав этот же алгоритм на всех возможных комбинациях паролей, и затем всё, что ему останется — перехватить рукопожатие и посмотреть хэш в нём по таблице, которую он уже успел вычислить. Если в таблице такой хэш есть — значит, есть и исходная строка, из которой он был вычислен, и она ему известна. А затем ту же самую таблицу можно использовать для расшифровки других данных. Такая таблица называется радужной (rainbow table). Особую популярность техника получила при подборе паролей в украденных базах старых форумных и прочих движков на PHP.
Решается это добавлением «соли» — случайной или более-менее уникальной строки, которая даже при совпадении самих паролей сделает вычисленные хэши разными.
Посмотрим, как авторы стандарта WPA справились с этими задачами:

Схема выше отражает процессы, происходящие параллельно на обеих сторонах (клиенте и точке доступа), а не то, что передаётся по радиоканалу — это важно и об этом ниже. Ещё до начала вычислений и клиент, и ТД уже имеют следующие данные:
- Пароль сети, как он указан администратором — на схеме 12345678 (
ай-яй-яй, какой несознательный администратор) - Имя сети (SSID) — аналогично указан администратором — на схеме mynet
- MAC-адрес клиента — на схеме FF:EE:DD:...
- MAC-адрес точки доступа (BSSID) — на схеме 11:22:33:...
Всё начинается с того, что «короткий пароль» (от пользователя) преобразуется в более длинный ключ с добавлением
Строка, полученная выше, называется PMK (Pairwise Master Key — главный парный ключ). Она статичная, то есть нам не стоит шифровать данные с её помощью, ведь она, как и пароль, не меняется, если не меняется имя сети — а, значит, нет разницы шифрованием по PMK и по самому паролю (о проблемах этого было сказано в начале). Соответственно, точно так же, как и паролем, мы не должны «светить» и PMK.
Поэтому дальше нам нужно получить временный, очень длинный и очень уникальный ключ, который бы мы использовали конкретно для данного сеанса передачи данных. То есть временный ключ. То есть PTK (Pairwise Transient Key — кратковременный парный ключ). Для этого используется тот же алгоритм PBKDF, но передаются ему на вход 5 значений:
- PMK — уже вычислен на основе пароля и имени сети
- A-Nonce — это просто случайная строка, переданная точкой доступа на запрос клиента о подключении (самый первый пакет при авторизации)
- S-Nonce — ещё одна случайная строка, но переданная клиентом к ТД в следующем пакете
- BSSID точки доступа (MAC-адрес)
- MAC-адрес клиента
Итак, связав 5 значений в строку и прогнав их 4096 раз через SHA-1 мы получили 256-битный PTK. Именно он и будет использоваться для шифрования всех данных от клиента к ТД и обратно.
Последний этап — проверка на то, что клиент на самом деле обладает верным паролем к сети, из-за которого-то всё и затеяно. Вы ведь не забыли, что описанные манипуляции происходят на обеих сторонах независимо и без взаимодействия друг с другом, если не считать пересылки двух nonce? В этом случае, имея разные исходные данные стороны получат разные PTK и если, скажем, клиент зашифрует свой трафик и отправит точке доступа, то та не сможет его расшифровать из-за того, что её PTK отличается от ключа, которым был зашифрован поток у клиента. Разные «исходные данные» здесь — это, конечно, в первую очередь пароль от сети, так как исходит он от нестабильного элемента — человека, тогда как MAC-адреса, имя сети и прочее исходит от «железа», которое между собой обычно договаривается без проблем.
Для проверки переданного пакета данных к нему добавляется MIC — Message Integrity Code, или код целостности сообщения. В WPA для его вычисления используется HMAC-MD5 (разновидность всем известного MD5). К слову, все знакомы с CRC32 — это ещё один алгоритм для подобных целей, часто используется для проверки файлов в архиве. Полученный в результате код также называют хэш-суммой.
Идея в том, что подав на вход хэш-функции (MD5, CRC, SHA и других) любой поток данных произвольной длинны мы получим некую строку на выходе, которая будет уникальна для этого потока данных. Естественно, 100% уникальность невозможна — если выходная строка 4 байта, то при всём желании она не сможет вместить все возможные входные комбинации. Тем не менее, алгоритм создан так, что найти, какие ещё строки могут выдать точно такой же хэш, мы не можем (на самом деле для слабых алгоритмов вроде CRC это не так; они используются для проверки данных на случайное повреждение, а не умышленную фабрикацию).
Соответственно, представим, что нам нужно передать строку
12345 и при этом позволить принимающей стороне проверить, что в процессе передачи строка не изменилась. Для этого мы прибавим к ней её собственный хэш:input = 1 2 3 4 5
sha1(1 2 3 4 5) = 8cb2237d0679ca88db6464eac60da96345513964
output = 1 2 3 4 5 | 8c b2 23 7d 06 79 ca 88 db 64 64 ea c6 0d a9 63 45 51 39 64
При приёме устройство отрезает хэш от принятого сообщения (после "|"), вычисляет хэш-сумму для того, что было слева, и сравнивает обе части. Сошлись — значит, ничьи ловкие ручки к данным не прикасались.
… Но, конечно, всё не так просто. Легко заметить, что зная алгоритм вычисления хэш-суммы атакующий может поменять сообщение, вычислить его новую сумму и заменить старую на новую. Что делать?
Снова посмотрим на эту схему, на этот раз нас интересует последняя строка. MIC составляется из PTK и потока байтов самого сообщения. PTK — это как раз наша «соль» (как мы помним, PTK используется и для шифрования самого потока, и теперь ещё для вычисления его хэш-суммы, то есть MIC). Поток и PTK передаются в HMAC-MD5 и полученный хэш называется MIC. Он передаётся вместе с сообщением принимающей стороне, которая декодирует пакет, вычисляет его MIC и если этот MIC отличается от того, который был найден в самом пакете — считает, что кто-то влез в процесс передачи или просто была не лётная погода, и отбрасывает этот пакет.
А теперь внимание: как нам понять, что клиент обладает верным паролем к сети и, как следствие, вычислил верный PTK, без передачи этого самого PTK? Просто: попробовать зашифровать первое сообщение на одной стороне и посмотреть, смогут ли его расшифровать на другой. Если использовались одинаковые PTK — значит при расшифровке полученный MIC совпадёт с переданным. Если разные — MIC не сойдутся, как следствие, PTK были разные, как следствие, PMK были разные, и, как следствие, исходные пароли тоже были разные.
Напоследок для закрепления — упрощённая схема того, что, собственно, передаётся в открытом виде по радиоканалу при рукопожатии.
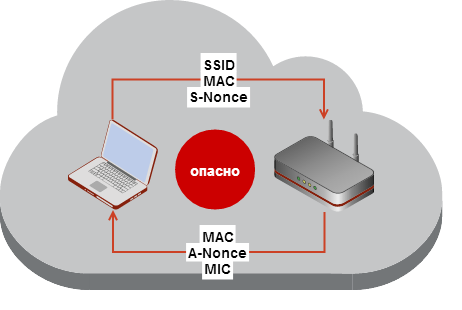
Как видим, из всех более-менее закрытых данных хитрые парни в IEEE обошлись передачей одного MIC, который к тому же передаётся уже зашифрованным с помощью PTK.

(Оригинальный арт.)
Что делать, Семёныч?
Надеюсь, мой краткий обзор пролил кое-какой свет на то, какую чёрную магию используют инструменты вроде aircrack-ng и hashcat при попытке определить пароль в рукопожатии. Как мы теперь знаем, им нужно раскрутить всю цепочку назад, имея на руках всего-навсего хэш-сумму одного из пакетов (MIC). А именно, сделать следующее:
- Первым делом вычислить главный ключ сети — PMK. Для этого берётся пароль и имя сети. Последнее берётся из перехваченных пакетов рукопожатия (об этом ниже), а первый можно брать из словаря по одному или перебирать всё доступное пространство ключей «в лоб»,
но только если вы джедай и обладаете особой уличной магией в виде пары GPU. - Дальше вычисляется PTK — хэш-сумма из полученного PMK (выше), MAC-адресов клиента и ТД и случайных nonce-строк от них же (берутся из перехваченных пакетов).
- Наконец, для пакета, переданного с MIC, вычисляется MIC на основании PTK, полученного выше, при этом переданный MIC игнорируется (так как он зависит от всего сообщения, в том числе самого MIC, то перед вычислениями это поле устанавливается в 0, иначе невозможно вычислить сумму, не зная MIC, для вычисления которого нужно знать эту сумму).
- Оба MIC сравниваются — если совпали — пароль найден (PTK верен > PMK верен > пароль верен), если нет — go to line 1
Таким образом, каждая итерация требует как минимум 8192 вычислений SHA-1, который в 3 раза медленнее MD5. Это очень затратный процесс. А что мы получим в итоге?
А в итоге — только исходный пароль и PTK того незадачливого клиента, аутентификацию которого мы перехватили. Это значит, что мы не сможем прочитать потоки других клиентов — у них другие PTK. Мы не сможем прочитать данные, которые этот клиент передал до того, как подключился — у него тоже был другой PTK. Мы даже не сможем прочитать то, что он передаст после того, как подключится в следующий раз — ведь PTK снова изменится!
Это очень важный вывод, который в четвёртой статье цикла нам будет очень кстати при перехвате пакетов в Wireshark. Там нам придётся не только получить пароль от сети, как описано в этой статье, но и перехватить рукопожатия всех клиентов, которых мы хотим прослушать (либо использовать ARP-спуфинг, но это атака на другом уровне). Та ещё работёнка.
Кстати, опыт с PTK — сын ошибок трудных в WEP, где для шифрования всех потоков клиентов всегда использовался одинаковый ключ.
К оружию!

С теорией всё, обещаю. Теперь только практика — отсюда и до обеда.
Итак, ещё раз: наша задача — перехватить первые 4 пакета, которыми обмениваются клиент и точка доступа (по 2 с каждой стороны) при установлении соединения. В сумме они называются рукопожатием (handshake). После них начинается уже шифрованная передача данных, из которой нам ничего не вытащить. Кстати, эти пакеты — часть протокола EAP (или EAPOL), и под таким именем они фигурируют в Wireshark (см. следующую статью цикла).
Перехватив их мы можем сохранить их к себе и затем провести offline-атаку — то есть попытаться подобрать оригинальный пароль к сети, поочерёдно пробуя разные пароли для генерации PMK > PTK > MIC и сравнивая последний с тем, который был передан на самом деле, как это было описано выше.
Перехват делается с помощью airodump-ng, с которой мы уже знакомы по второй части. С параметрами можете поиграть, о них писалось там же, но в общем случае вызов выглядит так:
airodump-ng mon0 -c 5 --bssid AP_BSSID -w caps
Перед этим вам нужно перевести свою карту в «хакерский режим» (monitor mode) и проделать все прочие манипуляции (смена MAC, txpower и т.д. — см. вторую часть).
В команде выше мы используем интерфейс под идентификатором
mon0 для сбора пакетов атакуемой сети на канале 5, которая имеет MAC, указанный после --bssid, сохраняя пакеты в файл caps-NN.cap (по умолчанию используется стандартный формат libpcap, который поддерживается очень многими библиотеками на всех ОС, в том числе и Wireshark). NN будет заменено на уникальное число, таким образом при повторных запусках airodump-ng с теми же параметрами старые файлы не будут перезаписаны, а будут иметь имена вида cap-01.cap и дальше.Допустим, что атакуемая нами сеть имеет BSSID
4F:B1:A4:05:5C:21 и находится на канале 11. Тогда делаем так:airodump-ng mon0 -c 11 --bssid 4F:B1:A4:05:5C:21 -w caps
После запуска откроется уже знакомое консольное окно с двумя таблицами. Оставим его висеть, пока кто-нибудь не подключится к нашей сети…
Но ведь мы можем ускорить этот процесс! Читатель помнит про то, что мы можем отключить имеющихся клиентов и заставить их передать данные аутентификации повторно — очень полезно для таких непоседливых хакеров, как мы. Уже знакомая aireplay-ng с радостью поможет нам:
aireplay-ng mon0 -0 5 -a 4F:B1:A4:05:5C:21 -c 5B:23:15:00:C8:57
5B:23:15:00:C8:57 — MAC-адрес клиента, который мы почерпнули из таблицы запущенного ранее airodump-ng.Если всё сделано правильно, aireplay-ng выведет 5 строк вида
Sending directed deauth, а в окне с airodump-ng мы должны наблюдать быстро увеличивающееся число «потерянных» пакетов (в графе Lost). Оно может пойти на тысячи.После этого наш дорогой клиент, если он был в радиусе действия нашего передатчика и если он был активный (иногда устройство остаётся подключенным к сети, но не использует её, и отключение не заставляет его переподключиться), тут же начнёт авторизацию заново и мы поймаем эти пакеты, о чём в правом верхнем углу airodump-ng победно сообщит надписью
[ WPA handshake: 4F:B1:A4:05:5C:21 ] (MAC-адрес сети, рукопожатие с которой было перехвачено).Если так и случилось — атака проведена успешно, airodump-ng можно закрывать, копировать полученный
caps-01.cap на флешку Зашифрованные.
Подбор пароля
Первая часть с перехватом рукопожатия обычно самая простая, особенно в сетях со множеством активных клиентов. Мы получили пакеты с MIC и прочими данными авторизации. Теперь нужно найти, какой же из наших ключей подойдёт к этому замку?
Подбор требует больших вычислительных мощностей и ради них можно арендовать EC2-кластер или даже собрать свою ATI-ферму. А можно просто прогнать пакеты через словарь самых распространённых паролей на обычном ЦП с надеждой, что пользователь ССЗБ. Последнее, кстати, очень может быть — на протестированных мной 11 сетях одна использовала пароль «12345678», вторая — «123456789», а пять других — пароли из 8 цифр, которые на средней системе взламываются за сутки. При этом из оставшихся 4 три были взломаны ещё за двое суток через WPS (см. вторую часть).
Не повторяйте таких ошибок.
Другой часто встречающийся вариант — номер телефона (только цифры). Особенно актуально для сетей фирм, магазинов, кафе. Обычно такой «пароль» висит прямо на входе в заведение. Сгенерировать все номера, если известен код, можно через
crunch 10 10 -t 063%%%%%%% (RaSta).aircrack-ng
Самый простой способ перебора. aircrack-ng использует только ЦП, зато отлично поддерживает многопоточность. Она перебирает значения по словарю для WPA-сетей (также умеет взламывать WEP).
Kali идёт с набором словарей в
/usr/share/wordlists/, но их при желании можно легко найти на просторах Интернета любого размера — от мегабайт до десятков гигабайт. Довольно хорошая компиляция — WPA-PSK Wordlist 3 Final, а также сгенерированный словарь из всех комбинаций 8-значных числовых паролей, который получается с помощью crunch 8 8 1234567890aircrack-ng -w /usr/share/wordlists/fasttrack.txt caps-01.cap
/usr/share/wordlists/fasttrack.txt (идёт в комплекте с Kali) — путь к словарному файлу с паролями, один пароль на строку. Строки короче 8 символов будут проигнорированы, так как это минимальная длина для WPA.На моём i7 3840QM 4x3.8 GHz aircrack-ng выжимает ~4700 паролей в секунду. Таким образом, мы можем подсчитать, сколько времени птребуется для полного перебора всех возможных комбинаций из 8 цифр:
(10^8) / (4700 * 3600) = 5,91 часов
Проверить скорость подбора без собственно подбора (бенчмарк) можно так:
aircrack-ng -S
# 4713 k/s
А так можно посмотреть, сколько при подборе будет использоваться ядер:
aircrack-ng -u
# No CPU detected: 8 (SSE2 available)
Итого, за 6 часов можно перебрать 10 миллионов паролей на high-end мобильном ЦП. Цифровой пароль такой длинны не стоит рассматривать в качестве серьёзной защиты, и даже не поэтому — применив ГП (GPU), который даёт в десятки и сотни раз большую скорость, такой пароль сломается за минуты. Об этом ниже.
Если атака прошла успешно, то есть aircrack-ng нашла пароль, то она завершит работу и на экране будет выведено радостное
KEY FOUND! [ ... ] — запишите его и используйте для входа в сеть. Также можно записать найденный пароль в файл через -l pass.txt, что полезно при запуске перебора в фоне как aircrack-ng ... -l pass.txt &Пояснения по формуле выше:
- 10^8 — 10 в степени 8, число возможных комбинаций; вычисляется как
число_возможных_символов ^ длина_строки. К примеру, для 6-значного пароля из латинских символов в нижнем регистре будет 266 = 308 915 776 комбинаций. К слову, это наглядно показывает, что длина пароля имеет куда большее значение, чем возможное число символов в нём: запомнить "this weirdo voodoo" куда проще, чем "0.o@&z%_" — тогда как комбинаций первого на 1025 больше (десять и 24 нуля). - 4700 — число сравнений паролей в секунду (скорость перебора)
- 3600 — приведение результата деления от паролей в секунду к паролям в час (60 секунд * 60 минут)
Ещё подсчёты для сравнения:
(26^8) / (4700 * 3600 * 24) = 514 суток для перебора 8-значного пароля с a-z
(10^10) / (4700 * 3600 * 24) = 24,6 суток для 10-значного цифрового пароля
(26^10) / (4700 * 3600 * 24 * 365) = 952 года для 10-значного пароля с a-z
(10^12) / (4700 * 3600 * 24 * 365) = 6,7 лет для 12-значного цифрового пароля
(10^14) / (4700 * 3600 * 24 * 365) = 674,6 лет для 14-значного цифрового пароля
Статистику для более длинных строк нет смысла вычислять, если речь идёт только о ЦП. Но перед тем, как делать выводы, подождите, пока мы не познакомимся с голиафами от ATI.
Мир сошёл с ума или GPGPU — «ГП общего назначения»

Времена, когда игры были тёплыми и ламповыми, а графические процессоры
Графические чипы по своим конструкционным особенностям кардинально отличаются от архитектуры ЦП. Если с ЦП мы говорим о 4, 8, 16 ядрах (не берём сервера), то в случае с ГП речь идёт о тысячах независимых ядер. При обработке графики нужно быстро выполнять операции над большими массивами — матрицами. И именно такие операции и нужны в криптографии. Поэтому ГП можно использовать для вычисления хэшей — или добычи криптовалют.
ГП можно собирать вместе в рамках одной системы, а системы — в кластеры, создавая «фермы». При колоссальном отрыве в производительности от обычных ЦП куда эффективнее собрать ферму из 10 систем с 4 ГП, чем из 10 систем с 4 ЦП.
Дать большую производительность могут только ASIC и FPGA — специальные устройства, которые можно программировать на выполнение определённых вычислений, но с ними надо возиться и писать отдельный софт, а ГП и SDK к ним существуют уже давно и начать писать под них сравнительно легко. Особенно привлекательно выглядят ATI-шные карточки, которые благодаря своей архитектуре на порядок превосходят карточки от nVidia конкретно для этих задач, и при этом значительно дешевле.
В контексте нашей задачи подбор паролей с использованием ГП могут делать две замечательные программы: hashcat и pyrit.
hashcat — закрытая, бесплатная утилита для молниеносного вычисления хэшей различных форм, используя различные алгоритмы (MD5, SHA, WPA и ещё пару десятков), с применением правил к словарным словам и даже с добавлением соли. На мой взгляд это лучшее, что существует на сегодня. Немного огорчает закрытость проекта, но автора можно понять — это большая работа.
hashcat состоит из трёх программ: hashcat (не использует ГП и по моим тестам по скорости сравнима с pyrit и немного медленнее aircrack-ng, которая вообще работает быстрее всех на ЦП); oclhashcat для OpenCL (SDK от ATI) и cudaHashcat (nVidia). Последние две идентичны в возможностях, но должны соответствовать производителю вашего ГП. Перед их работой нужно поставить драйвера и SDK, так как без них ядра ГП опознаны не будут.pyrit — открытый инструмент для подбора WPA-ключей на Python. В целом приятная программа, для своих целей подходит замечательно. Так же имеет версии для ЦП и обоих производителей ГП, однако работает только с WPA. В отличии от oclhashcat, pyrit использует и ЦП, и ГП, тогда как oclhashcat — только ГП. Автор последней объясняет это тем, что выигрыш минимален, а затрат по программированию много.
Установка драйверов
Итак, посмотрим, как нам задействовать этот инструментарий. Описанный ниже механизм был выявлен после многих часов борьбы с Kali, CUDA и исходниками Pyrit, поэтому надеюсь, что он сэкономит это время для вас. Всё было успешно протестировано на версии
Kali 1.0.7 x64 и версиях cuda_6.0.37_linux_64 и NVIDIA-Linux-x86_64-331.67. На ноутбуке используется Optimus (технология от nVidia для переключения между встроенным ГП от Intel). В документации Kali есть страница об установке драйверов nVidia — тоже может пригодиться.Изначально в Kali не установлены программы для работы с ГП, так как сегодня есть два соперничающих стандарта (OpenCL от AMD и CUDA от nVidia), и кроме того, CUDA использует закрытые драйверы, а не стандартный nouveau. Поэтому придётся устанавливать всё самим.
Для начала установим заголовки исходников ядра Linux:
apt-get install linux-headers-`uname -r`
Далее скачиваем драйвера для nVidia и SDK для CUDA. Ссылки на RUN-файлы возьмите с сайта nVidia и из раздела CUDA.
wget http://.../NVIDIA-Linux-x86_64-331.67.run
wget http://.../cuda_6.0.37_linux_64.run
Дальше нам нужно выйти из оконного менеджера (X). На самом деле эта загадочная фраза (в мануалах — shutdown the X server/session) обозначает буквально следующее:
shutdown 0
Это переведёт систему в maintenance/single user mode. Kali запросит пароль от root или нажатие Ctrl+D — последнее приведёт к повторному запуску GNOME, что нам совсем не нужно. Вводим пароль, который по умолчанию toor, и попадаем в консоль. Там выполняем:
modprobe -r nouveau
chmod +x *.run
./NVIDIA-Linux-x86_64-331.67.run
./cuda_6.0.37_linux_64.run
При этом при установке драйверов (предпоследняя команда):
- Выбираем No, когда установщик сообщает нам, что мы должны быть в runlevel 3 (перейти в него через telinit 3 у меня не получилось, так как он всё так же ругался, но на нормальной работе дальше это никак не отразилось)
- Выбираем No при вопросе об установке 32-битных версий (для 64-битных систем)
- Последний вопрос будет об установке закрытых драйверов nVidia в качестве системных (с заменой nouveau) — у меня они вешали X после перезагрузки и я решил с этим не возиться, поэтому ответил No
Для установщика CUDA отвечаем n, когда он захочет установить драйвера nVidia (второй вопрос после принятия лицензии) — этот момент мне не понятен, но устанавливая драйвера через него установка всегда заканчивается с
Installation failed, тогда как ставя, по идее, те же самые драйвера через скачанный ранее первый установщик всё проходит успешно.На все остальные вопросы установщика CUDA отвечаем y. Samples можно ставить, можно нет (занимают около 230 Мб).
Для проверки работоспособности поставленной CUDA можно запустить nvcc (находится в
/usr/local/cuda/bin) — если прошло без ошибок, значит всё работает.Если в процессе установки отключился интерфейс проводной сети (иногда бывает) — его можно поднять так:
ifconfig eth0 up
dhclient eth0
Наконец, если с установкой что-то не так и вы хотите вернуть старый драйвер, чтобы снова открыть GNOME — вначале загрузите обратно nouveau, а затем нажмите Ctrl+D.:
modprobe nouveau
Все манипуляции с драйверами рекомендую проводить после загрузки ОС в read only (см. вторую часть), так как повредив драйвер очень легко потом лишиться нормального рабочего стола и придётся обходиться консолью в поисках проблемы.
Установка cpyrit_cuda и oclhashcat
Теперь можно ставить собственно сами утилиты. hashcat ставится через
apt-get install -y oclhashcat (для обеих версий OpenCL/CUDA), а pyrit собирается из исходников (внимание: используйте последнюю версию в trunk, так как в текущей стабильной версии есть баг, из-за которого компиляция может не пройти на некоторых nVidia, как это было с моей картой).Установка pyrit (если у вас OpenCL — см. документацию на сайте проекта):
apt-get install -y libpcap-dev python-scapy
svn checkout http://pyrit.googlecode.com/svn/trunk/ psrc
cd psrc/pyrit
sudo python setup.py build
sudo python setup.py install
cd ../cpyrit_cuda
sudo python setup.py build
sudo python setup.py install
Сборка закончена. Посмотрим, нашёл ли pyrit наши карточки:
pyrit list_cores
В случае успеха будет выведено
#0 GPU ... — по одной строчке на каждое ядро, плюс по одной строке на каждое ядро ЦП (правда, на моей системе одно ядро процессора «съелось» ядром ГП — возможно, pyrit не поддерживает больше 8 потоков).Дальше мы можем запустить тест и через 10-20 секунд узнать примерную скорость перебора с использованием возможностей ГП:
pyrit benchmark
На моей системе и pyrit, и hashcat выдают 10 500 (ГП) + 4 000 (ЦП) паролей в секунду, что лишний раз подтверждает непригодность nVidia для подобных вычислений (у меня GeForce GTX 675MX). Аналогичная мобильная карточка от ATI выдаёт около 40 000 п/с.
Итак, запустим перебор на pyrit:
pyrit -r caps-01.cap -e MYNET -i /usr/share/wordlist/fasttrack.txt attack_passthrough
Параметры аналогичны параметрам aircrack-ng. Когда совпадение будет найдено pyrit завершит работу и ключ будет виден на экране.
Если при запуске pyrit и hashcat появляются предупреждения об ACPI — их можно игнорировать, если вычисления идут нормально. У меня их бывает по 10-15 штук.
Если мы хотим перебрать все цифровые пароли определённой длинны — это можно сделать двумя способами: на лету или сгенерировав словарь на диске. Для генерации словарей у Kali есть несколько утилит, одна из них — crunch:
crunch 8 10 0123456789 | pyrit -r caps.cap -e MYNET -i - attack_passthrough
-i - говорит pyrit читать пароли из stdin, а 8 10 — минимальный и максимальный длины генерируемых crunch слов, состоящих из символов 0123456789. Не имеет смысла генерировать словарь с сохранением на диск, так как файл будет в 112 Гб и их можно сэкономить, так как на скорости перебора генерация на лету никак не скажется.
Запуск hashcat
 Так как hashcat — более универсальная утилита, то синтаксис её параметров сложнее, и кроме того, она принимает на вход не стандартный файл libpcap (который мы ранее сохранили через airodump-ng), а собственный —
Так как hashcat — более универсальная утилита, то синтаксис её параметров сложнее, и кроме того, она принимает на вход не стандартный файл libpcap (который мы ранее сохранили через airodump-ng), а собственный — *.hccap.Процесс преобразования из .cap в .hccap описан в официальной вики. Делается это просто: сначала мы убираем из файла все пакеты, кроме рукопожатия, а затем преобразуем оставшиеся в .hccap: На сайте там же есть online-конвертер, принимающий файлы размером до 5 Мб — если вас вопрос приватности не очень волнует, то можно воспользоваться и им (делает он то же самое, что описано ниже).
wpaclean clean.cap caps-01.cap
aircrack-ng clean.cap -J hashcat
Получившийся в итоге
hashcat.hccap передаём в hashcat, oclhashcat или cudahashcat. Кстати, wpaclean (идёт вместе с Kali) иногда может вырезать не те пакеты, поэтому можно пользоваться скриптом с этого сайта. Если файл был обрезан не верно, то подобрать пароль становится невозможно (сообщений об ошибок не будет, просто aircrack, hashcat, pyrit и пр. будут рапортовать о том, что пароль не найден, даже если в вашем словаре настоящий пароль был).За подробностями по работе hashcat я отправлю вас в
oclhashcat -h и к её отличной документации. Ниже — несколько коротких примеров.Так можно запустить простой перебор по маске (здесь -m2500 обозначает подбор ключа в WPA-рукопожатии, -a3 задаёт режим подбора по маске, а ?d... — саму маску для генерации слов (
?d обозначает символы 0-9, а восемь ?d подряд обозначают 8 цифр одна за другой):oclhashcat -m2500 -a3 caps.hccap ?d?d?d?d?d?d?d?d
Аналогично, но перебор по словарю (-a0 можно не указывать):
oclhashcat -m2500 -a0 caps.hccap /usr/share/wordlists/fasttrack.txt
А так мы запускаем простой перебор подряд (-a3) паролей по хэшам в файле
~/hashes.txt, вычисленных по алгоритму sha1(пароль+соль) (-m110), причём пароли шестизначные и имеют форму [A-Z] [A-Z0-9] [A-Z0-9] [A-Z0-9] [A-Z0-9] [0-9]:oclhashcat -m110 -a3 -1?d?l ~/hashes.txt ?u?1?1?1?1?d
Наконец, так можно запустить тест на скорость:
oclhashcat -b
Найденные пароли будут отображаться на экране, а также записываться в файл
/usr/share/hashcat/hashcat.pot, либо для ГП-версий — в /usr/share/oclhashcat/hashcat.pot. Пока утилита работает, в терминале можно нажать на Enter для вывода текущего состояния (скорости, оставшемся % и прочего). Если нажать на q, то программа прервётся, сохранив состояние, и продолжить с того же самого места можно используя ту же самую командную строку с добавленным -s 1234, где число обозначает номер сессии (оно выводится в момент выхода из утилиты).
Amazon EC2
 Для интереса я прогнал подбор WPA-ключей на двух самых мощных кластерах от AWS: cc2.8xlarge (32 ядра ЦП) и g2.2xlarge (1 nVidia Tesla и 8 ядер ЦП):
Для интереса я прогнал подбор WPA-ключей на двух самых мощных кластерах от AWS: cc2.8xlarge (32 ядра ЦП) и g2.2xlarge (1 nVidia Tesla и 8 ядер ЦП):g2.2xlarge = 22000 k/s [pyrit+cuda]
cc2.8xlarge = 14000 k/s [aircrack-ng]
13500 k/s [pyrit]
Как видим, даже ультра дорогая карта от nVidia не справляется с задачей вычисления хэшей так, как средние ГП от ATI. На самом деле Tesla даёт даже меньшую скорость, чем обычные GTX. Оно и понятно — у неё совсем иное назначение. А вот почему ATI так хорошо в это дело вписались — интересный вопрос…
И, конечно, 32 серверных ядра не способны потягаться даже с Tesla.
Почему AMD настолько превосходит аналогичные решения nVidia? Дело в большем числе потоковых процессоров (ядер), как следствие, более быстрых операциях над целочисленными значениями (не числах с плавающей точкой, которые в криптографии не нужны) и в особенности — благодаря специальным инструкциям, которые можно использовать при шифровании (
BIT_SELECT и BFI_INT).Кто хочет попробовать сам — устанавливается aircrack-ng на EC2 с Debian или Ubuntu так:
sudo yum install gcc libnl-devel openssl-devel
wget http://download.aircrack-ng.org/aircrack-ng-1.2-beta3.tar.gz
tar xf aircrack-ng-1.2-beta3.tar.gz
cd aircrack-ng-1.2-beta3
sudo make install
Статистика
Вот теперь, посмотрев, как ЦП и ГП справляются с перебором паролей, можно делать выводы. Ниже — статистика по некоторым современным на сегодня (июнь 2014) видеокартам. Данные получены по нескольким моим системам, от товарища chem_ua и открытых источников (golubev.com, страницы oclhashcat и форума). Сравнить возможности разных карт относительно друг друга можно по обширной таблице в вики Litecoin и аналогичной у Bitcoin.
Цифры — ориентировочные, зависят от конфигурации системы, ОС, температуры/охлаждения и разгона. Если у вас есть свои данные — поделитесь в комментариях или лично, я добавлю их в таблицу. kh/s — число вычислений и сравнений паролей в секунду в тысячах (10 kh/s = 10 000 паролей в секунду).
nVidia 670 24 kh/s
nVidia 675MX 11 kh/s
nVidia 780M 42 kh/s
nVidia 580 47 kh/s
nVidia Tesla K20 85 kh/s
nVidia 750 Ti 55 kh/s
nVidia Titan Black 108 kh/s
AMD 280X 160 kh/s
AMD 290X 190 kh/s
AMD 295X*2 203*2 kh/s
AMD 5870 101 kh/s
AMD 5870 153 kh/s
AMD 6870 72 kh/s
AMD 6990 181 kh/s
AMD 7970 128 kh/s
AMD 7990 220 kh/s
Внимание: хотя цифры зашкаливают даже при сравнении low-cost ГП (к примеру, 5870 за $90) с результатами ЦП помните, что в отличии от последних графические процессоры, и в особенности от AMD, потребляют в десятки раз больше электроэнергии (к примеру, желательно иметь БП на 0,75-1 кВт для всего двух 290X). Так что перед покупкой такого «генератора» вначале посчитайте, во сколько обойдётся вам ежемесячный счёт на электричество, особенно если планируется их разгонять. Либо посмотрите на 750 Ti, для которой нужно всего 300 Вт.
Сухой остаток
Знакомство с вычислением хэшей с помощью ГП даёт нам понять,
Таким образом, озвученные выше цифры по времени на перебор для WPA выглядят так:
(26^8) / (1500000 * 3600) = 38,7 часов для перебора 8-значного пароля с a-z (было 514 суток)
(10^10) / (1500000 * 3600) = 2 часа для 10-значного цифрового пароля (было 25 суток)
(26^10) / (1500000 * 3600 * 24 * 365) = 3 года для 10-значного пароля с a-z (было 952 года)
(10^12) / (1500000 * 3600 * 24) = 7,7 дней для 12-значного цифрового пароля (было 7 лет)
(10^14) / (1500000 * 3600 * 24 * 365) = 2,1 года для 14-значного цифрового пароля (было 674 года)
Как видим, цифры изменились кардинально. Более того, если мы посмотрим на стойкость паролей с MD5 (который вычисляется в 61 000 раз быстрее, и это без rainbow-таблиц, которые, впрочем, бесполезны для длинных паролей из-за своего объёма):
(26^8) / (94000000000) = 2 секунды для перебора 8-значного пароля с a-z
(10^10) / (94000000000) = 100 миллисекунд для 10-значного цифрового пароля
(26^10) / (94000000000 * 60) = 25 минут для 10-значного пароля с a-z
(10^12) / (94000000000) = 10,6 секунд для 12-значного цифрового пароля
(10^14) / (94000000000 * 60) = 17,7 минут для 14-значного цифрового пароля
MD5 и SHA1 (который всего в три раза медленнее первого) до сих пор используются многими сайтами для хэширования паролей пользователей, часто без добавления соли, хотя и они ситуации сильно не меняют. Так как мы не можем поручиться за благонадёжность всех сайтов, где регистрируемся (особенно имея перед глазами пример крупного сайта — Adobe), то использовать цифровые пароли длиной менее 20 символов (см. ниже) или буквенные длиной менее 14 — по меньшей мере безрассудно. И дело даже не в добавлении скобочек и точек (которые некоторыми сайтами вообще запрещены в паролях по каким-то своим соображениям) — как видим, разница между 10-значным цифровым и буквенным паролями продлит стойкость последнего где-то на полчаса.
Так что же делать?
Как говорится, спасение отца русской демократии — дело рук самой демократии. Посмотрим, что получается, если мы добавим по 4 символа к длине пароля:
(26^10) / (1500000 * 3600 * 24 * 365) = 3 года для перебора 10-значного пароля с a-z
(26^12) / (1500000 * 3600 * 24 * 365) = 2 017 лет для перебора 12-значного пароля с a-z
(10^16) / (1500000 * 3600 * 24 * 365) = 211 лет для 16-значного цифрового пароля
(10^18) / (1500000 * 3600 * 24 * 365) = 21 140 лет для 18-значного цифрового пароля
И для MD5:
(26^12) / (94000000000 * 3600 * 24) = 11,6 дней для перебора 12-значного пароля с a-z
(10^16) / (94000000000 * 3600 * 24) = 1 день для 16-значного цифрового пароля
(10^18) / (94000000000 * 3600 * 24) = 123 дня для 18-значного цифрового пароля
(26^16) / (94000000000 * 3600 * 24 * 365) = 14 710 лет для перебора 16-значного пароля с a-z
(26^14) / (94000000000 * 3600 * 24 * 365) = 21,7 лет для перебора 14-значного пароля с a-z
(26^16) / (94000000000 * 3600 * 24 * 365) = 14 710 лет для перебора 16-значного пароля с a-z
(10^20) / (94000000000 * 3600 * 24 * 365) = 34 года для 20-значного цифрового пароля
(10^22) / (94000000000 * 3600 * 24 * 365) = 3 373 года для 22-значного цифрового пароля
Как видим, даже «быстрый» MD5 длиной от 16 буквенных символов ломать уже не имеет смысла. Тем более при отсутствии «словарных» слов такой длины — если только мы не говорим о
qwertyuiopasdfghjk.Данная идея — о важности длины пароля, а не его содержимого — не нова. Три года назад XKCD нарисовал свой исторический стрип:
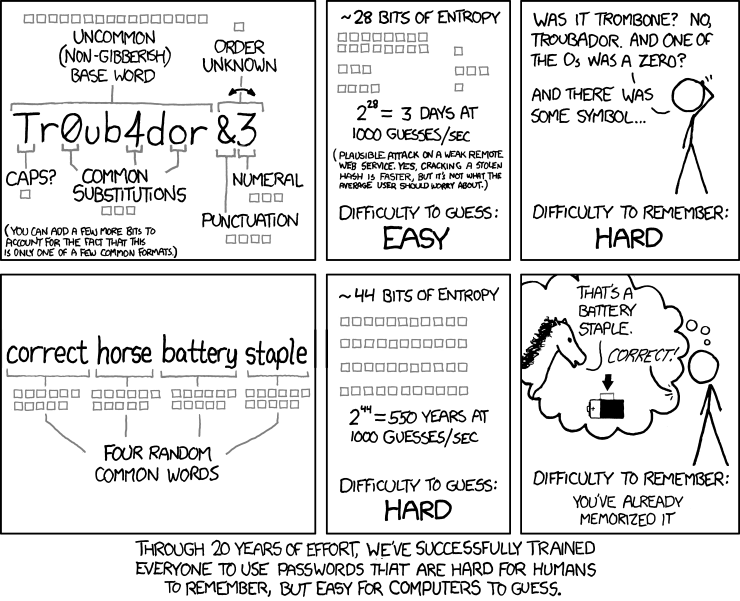
(«Спустя 20 лет постоянных усилий мы, наконец, преуспели в том, что научили людей придумывать сложные для запоминания пароли, которые легко подбираются компьютером.»)
А в апреле Стенфорд опубликовал новые требования к паролям, которые сводятся к тому, что на пароли длиной от 20 не накладываются требования к алфавиту (не обязательно наличие цифр, букв в верхнем регистре и так далее).
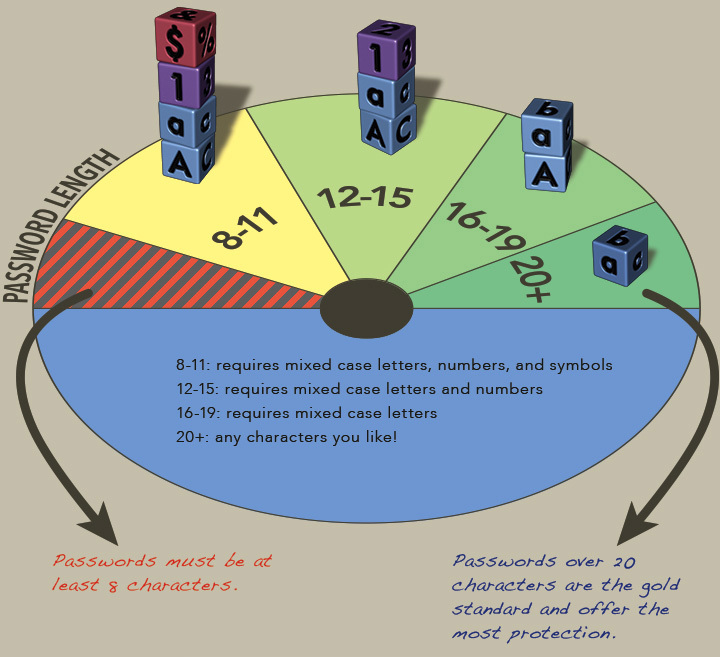
При всём этом печально выглядят требования таких организаций, как Альфа-Банк, где длина пароля ограничена 16 знаками без допуска большей части спецсимволов.
Подведём итог: чтобы не оставить злоумышленнику шансов подобрать пароль для WPA стоит придумать 12-значный буквенный пароль и если в ближайшие годы квантовый компьютер не станет доступен массам — бояться нечего. Ну, а для паролей к сайтам достаточно 16 символов и если они не хранят их в открытом виде — что бы вы не придумали, это так и останется тайной. До следующего пришествия компьютеров.
(Примечательным и неожиданным примером сайта, хранящем пароли в открытом виде, является форум ixbt.ru: «Пожалуйста, имейте в виду, что Ваш пароль не будет закодирован и может быть просмотрен администратором конференции. » — так что будьте бдительны!)
На этом экскурс в дебри вычислений закончен. В следующей, вероятно, последней статье цикла — о прослушивании трафика беспроводной сети после того, как вы туда проникли.
Понравилась ли вам статья? Был ли понятно изложен процесс рукопожатия? Были ли ошибки/неточности в описании (для знатоков)? Есть чем поделиться? Жду ваших комментариев, которые к тому же ускорят написание следующей части!
Оглавление:
1) Матчасть
2) Kali. Скрытие SSID. MAC-фильтрация. WPS
3) WPA. OpenCL/CUDA. Статистика подбора
