Привет Хабр! Пару месяцев назад я захотел провести тестирование производительности некоторых сетевых фреймворков, c целью понять насколько большая разбежка между ними. Надо ли использовать Node.js там, где хотелось бы Python с Gevent или нужен Ruby с его EventMachine.
Я хочу обратить ваше внимание на то, что эти материалы не являются руководством к выбору фреймворка и могут содержать спорные моменты. Я вообще не собирался публиковать результаты этого исследования, но когда они попадались мне на глаза я ловил себя на мысли, что это может быть кому-нибудь полезно. Теперь я начну забрасывать вас графиками.
Первый тест я провёл на самом дешёвом VPS DigitalOcean (1 Core, 512Mb RAM, 20Gb SSD). Для тестирование производительности использовалась утилита httperf. Что бы произвести необходимую нагрузку были задействованы VPS такой же конфигурации, в количестве 5 штук. Для одновременного запуска теста на всех клиентах я использовал утилиту autobench со следующими параметрами:
Это тест начинает выполнение с 50 соединений в секунду (10 запросов через одно соединение) и с шагом в 10 соединений в секунду достигает 600. Каждый тест устанавливает всего 6000 соединений и все запросы, которые не были обработаны в течение 5 секунд, считаются ошибкой.
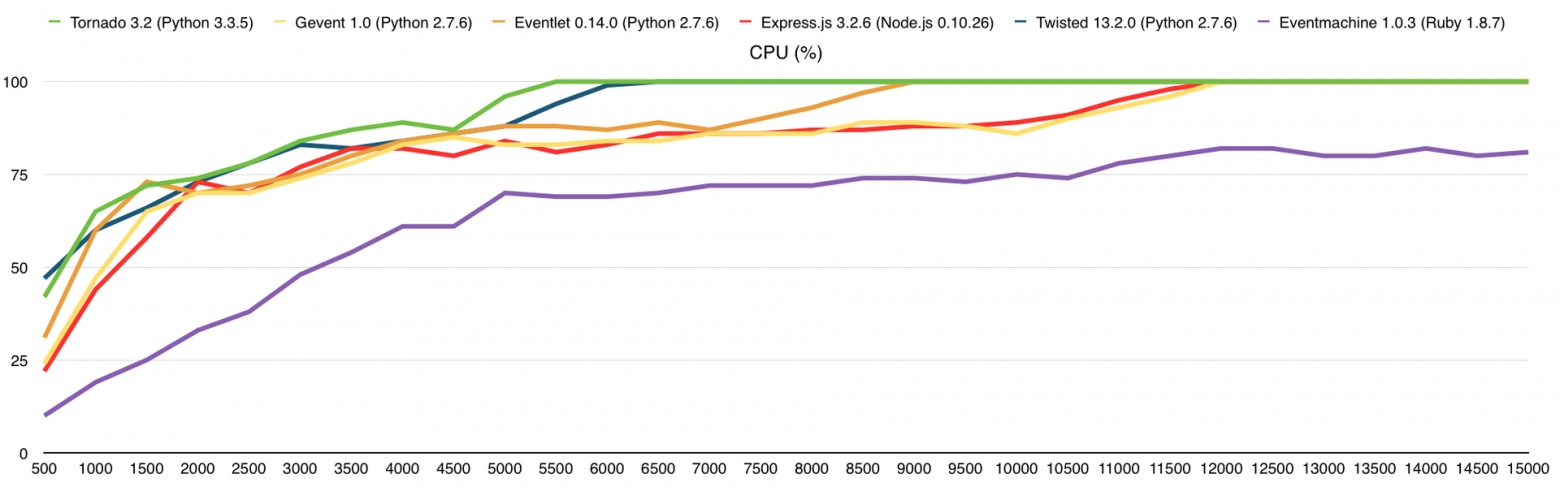
Все HTTP серверы делают одно и то же, а именно возвращают строку «I am a stupid HTTP server!» на каждый запрос. Результаты получились следующими (по оси Х – количество запросов в секунду):


Как только мы достигаем 100% использования CPU, потребление оперативной памяти начинает расти, количество ответов падает, время ответа на каждый запрос растёт и начинают появляться ошибки. Как я писал выше, каждый запрос, который не получил ответ в течение 5 секунд, считается ошибкой и здесь именно это и происходит, это можно проследить на графике «Время ответа».
Результаты (в скобках количество обработанных запросов без ошибок):
Я никогда не бываю доволен своей работой полностью, поэтому уже через пару часов я решил, что тестировать производительность на VPS не самый лучший выбор. Между фреймворками разница в производительности понятна и какие-то выводы сделать можно, но узнать сколько клиентов мы в состоянии обслужить на одном ядре настоящего процессора мы не можем. Одно дело делить с кем-то неизвестные ресурсы и совсем другое когда все ресурсы известны и в нашем распоряжении.
Для следующего теста я арендовал выделенный сервер у Hetzner (EX40) с процессором «Intel Core i7-4770 Quad-Core Haswell» и 32 GB DDR3 RAM.
На этот раз я создал 10 VPS, которые будут создавать необходимую нагрузку и запустил autobench со следующими параметрами:
Это тест начинает выполнение с 50 соединений в секунду (10 запросов через одно соединение) и с шагом в 50 соединений в секунду достигает 1500. Каждый тест устанавливает всего 15000 соединений и все запросы, которые не были обработаны в течение 5 секунд, считаются ошибкой.
Исходный код серверов тот же, что и в первом тесте. Запущена одна копия сервера, которая использует только 1 ядро. В этот тест я добавил фреймворки Twisted 13.2 и Eventmachine 1.0.3. Потребление памяти я удалил из результатов теста потому что разница, по современным меркам, ничтожна. Не буду тянуть кота за хвост, вот результаты:
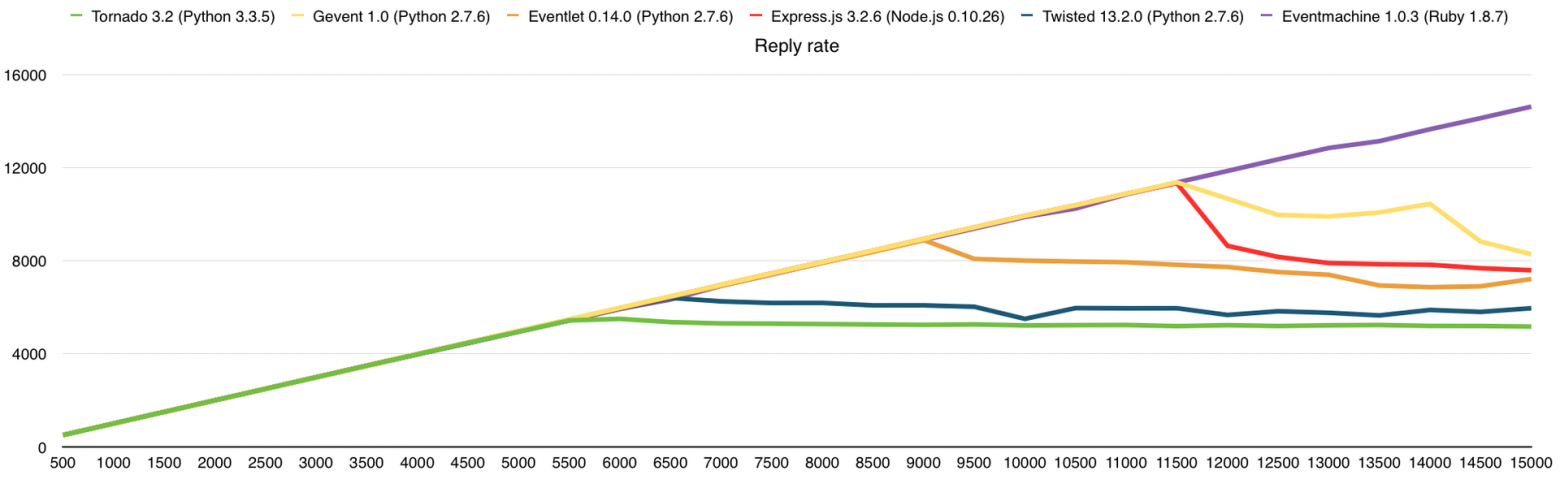
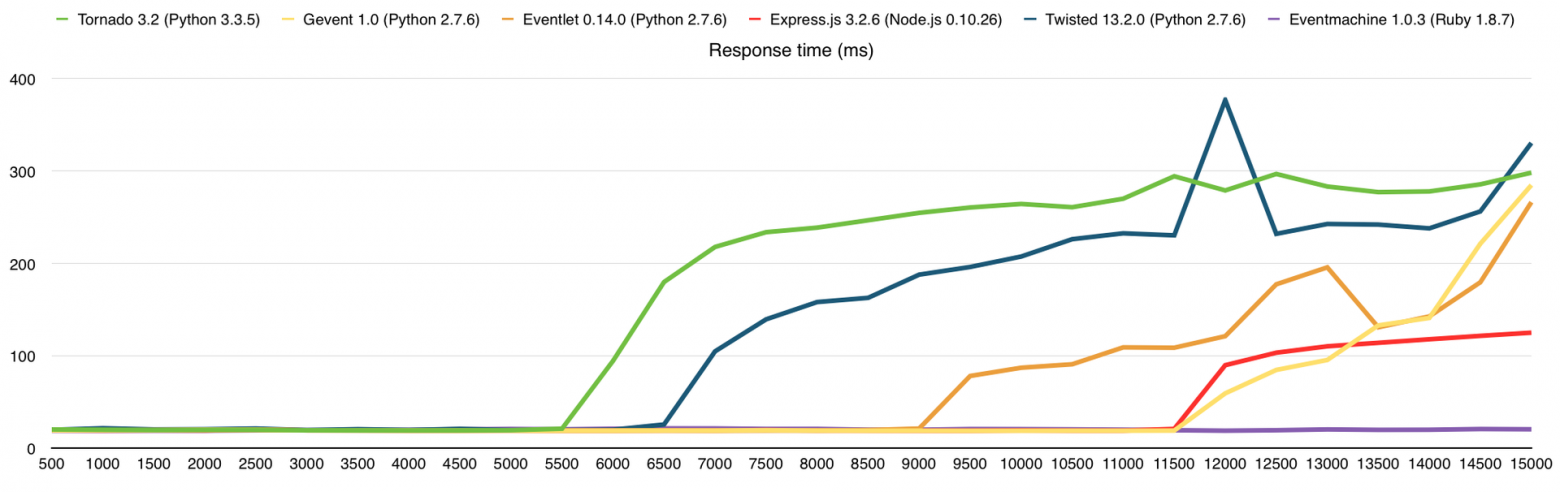
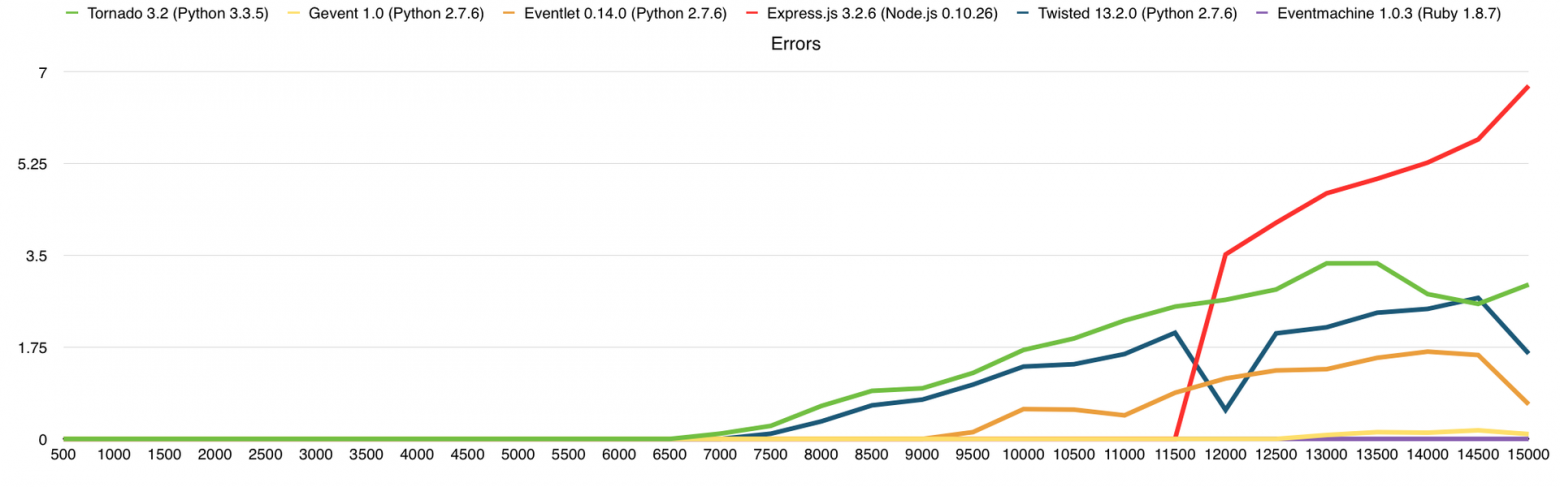
Тут, как и прежде, упёрлись в CPU, чего и следовало ожидать. В среднем, производительность здесь выше в 3 раза, чем на VPS DigitalOcean (1 Core, 512Mb), из чего можно сделать соответствующие выводы о количестве выделенных нам ресурсов.
Результаты (в скобках количество обработанных запросов без ошибок):
Eventmachine меня удивил своей производительностью и ушёл далеко от конкурентов, из-за чего мне пришлось увеличить нагрузку до 25000 запросов в секунду специально для него. Результат на графиках:
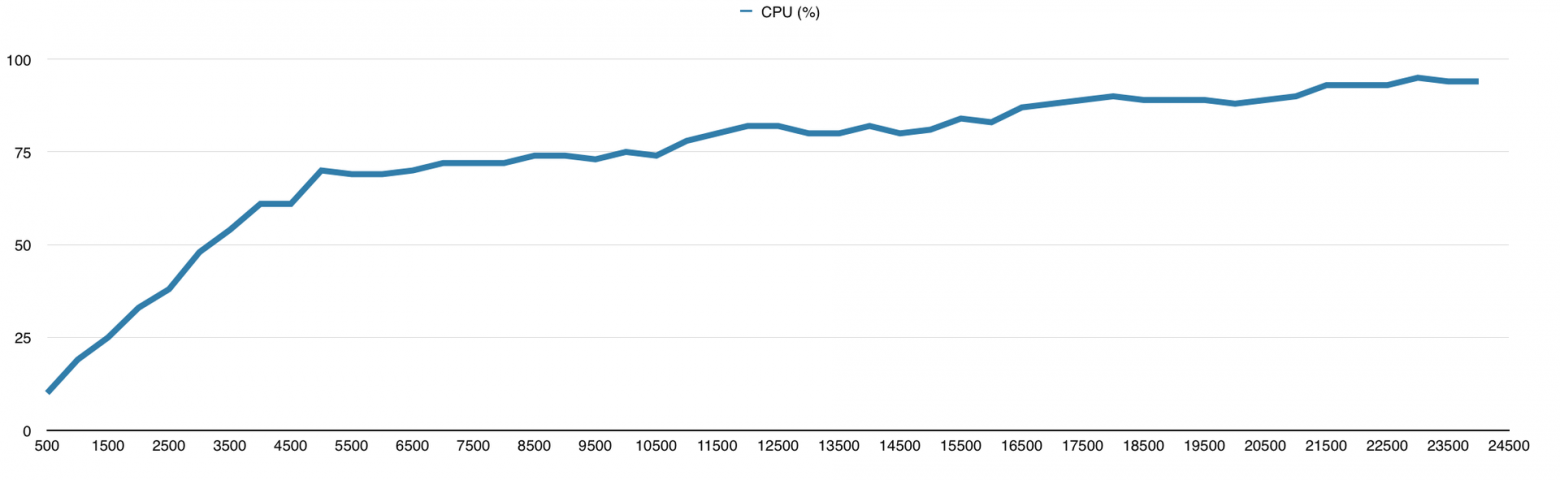
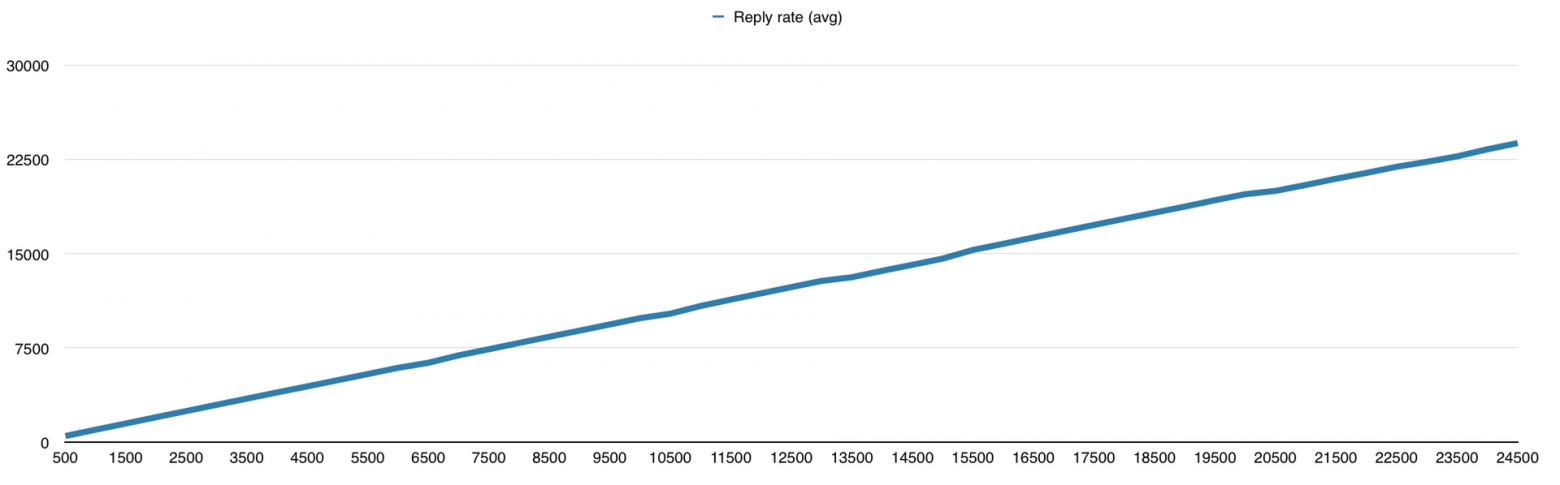
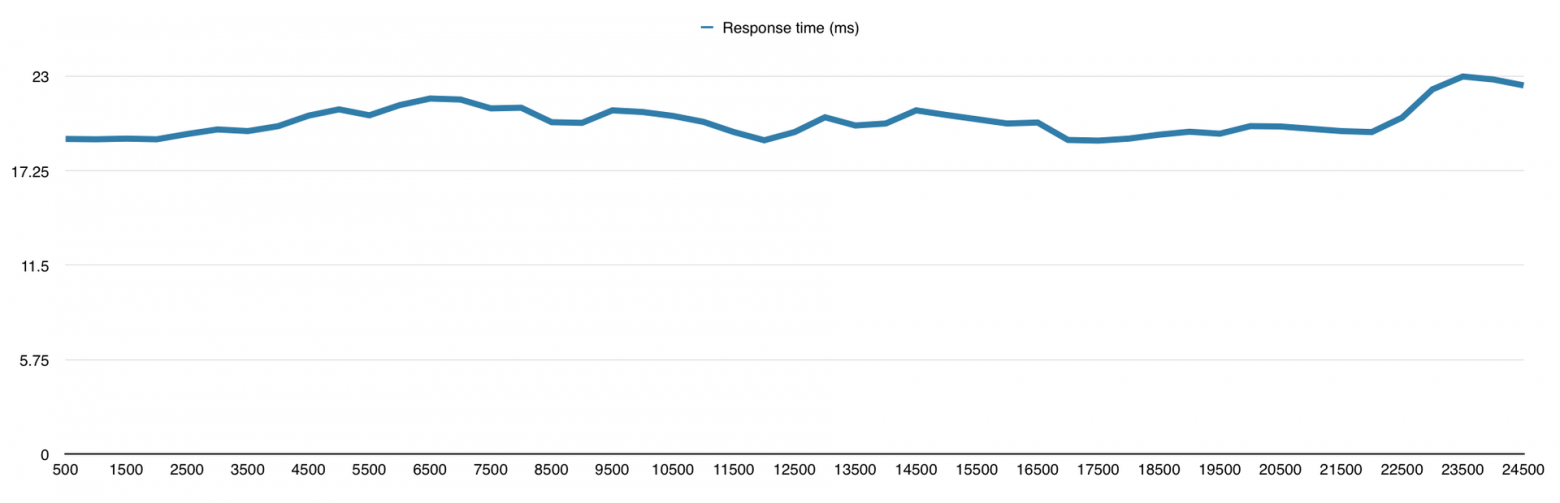

У меня есть подозрения, что и 30 000 запросов он бы смог обработать, но мне надо было двигаться дальше, поэтому я не смог в этом убедиться. Вообще я к этому моменту уже знал, что буду использовать Python для своего проекта, так что фреймворки на других языках мне нужны были просто для сравнения.
Как я писал выше, я не бываю доволен своей работой полностью, поэтому я лёг спать с чувством выполненного долга, а проснулся с мыслью «нужно больше тестов!». Отдавать строку текста на каждый запрос это конечно хорошо, но это не единственная функция веб-сервера, значит будем раздавать файлы.
Для этого теста я использовал 10 VPS, что бы создать необходимую нагрузку. Экспериментальным путём я выяснил, что на 1 VPS DigitalOcean, в среднем, выделен канал 100Mbps. Сервер у меня был с каналом 1Gbps и мне надо было его полностью нагрузить. Файлами для раздачи послужили изображения с интернет-магазина в количестве 10 000 штук, разных размеров. Для создания нагрузки я использовал утилиту siege со следующими параметрами:
В filelist.txt хранится список файлов, устанавливается 55 соединений и через них мы начинаем долбить сервер запросами в течение 1-й минуты. Файлы при этом выбираются случайным образом из списка fileslist.txt. Опредёленно стоит учесть, что тест этот запускается на 10 машинах одновременно, а значит мы устанавливаем не 55, а 550 одновременных соединений. Более того, эту опцию я постоянно менял от 5 до 55 с шагом в 5, увеличивая тем самым нагрузку на сервер, и устанавливая от 50 до 550 одновременных соединений.
Вот что получаем (по оси Х – количество одновременных соединений):
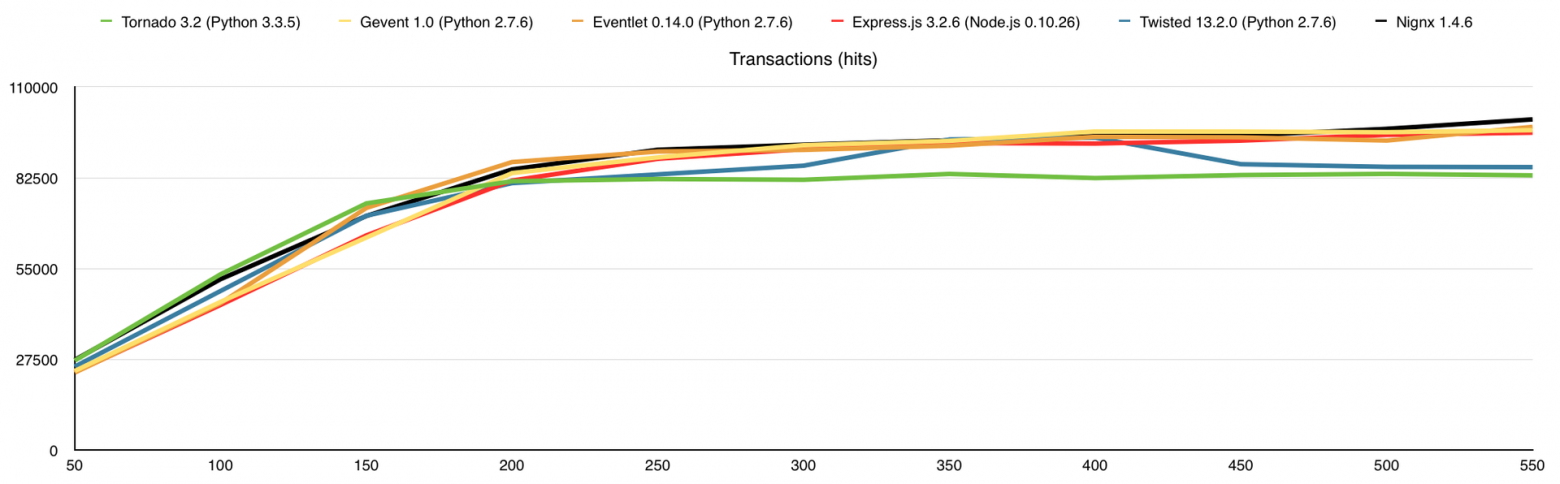
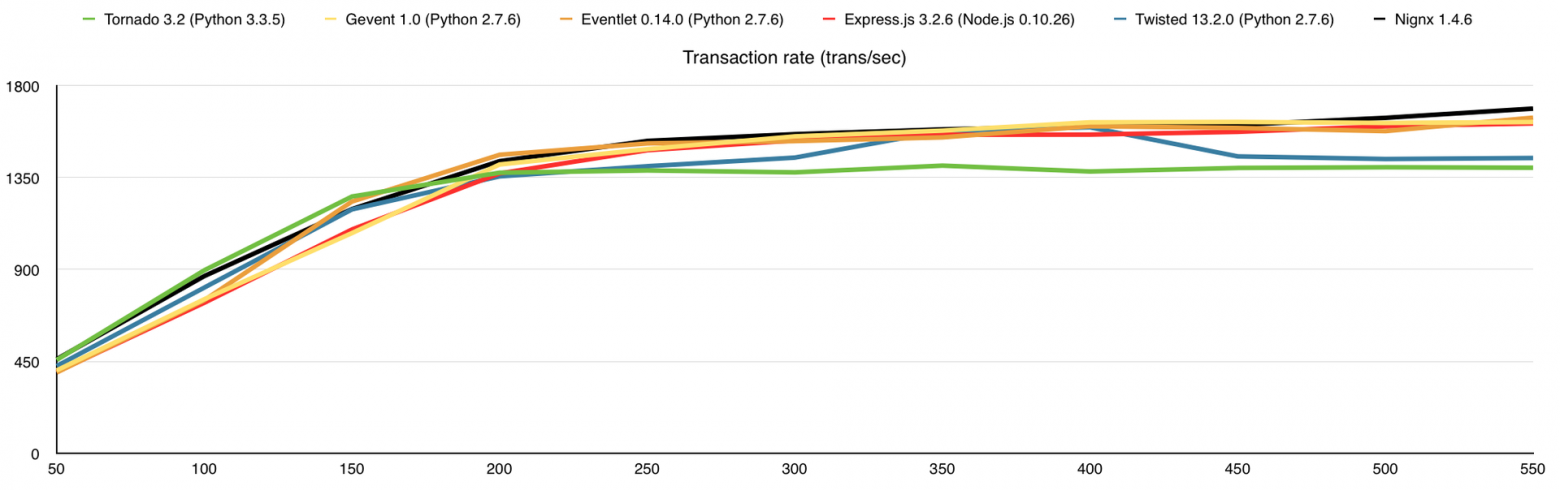
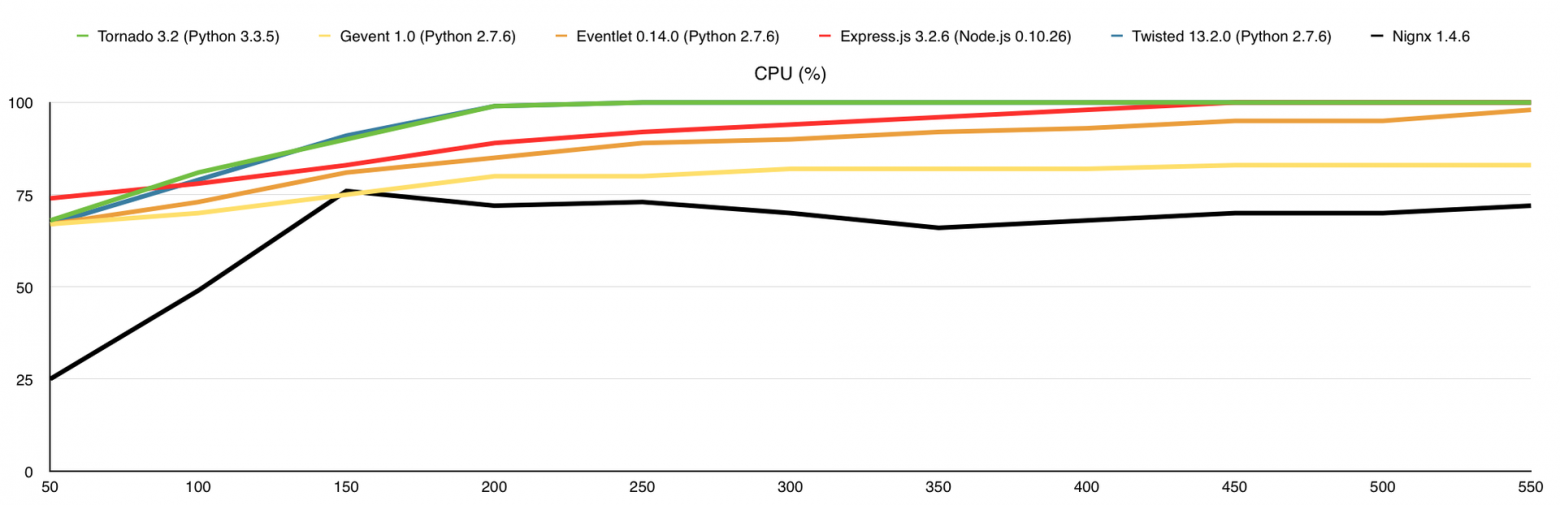
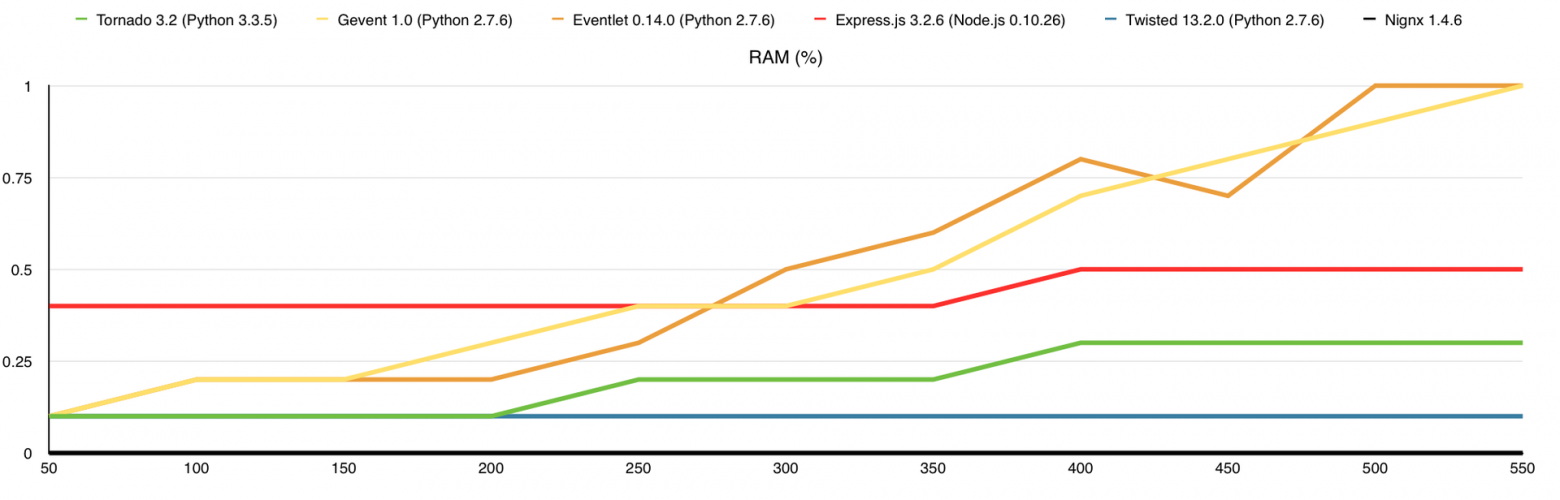
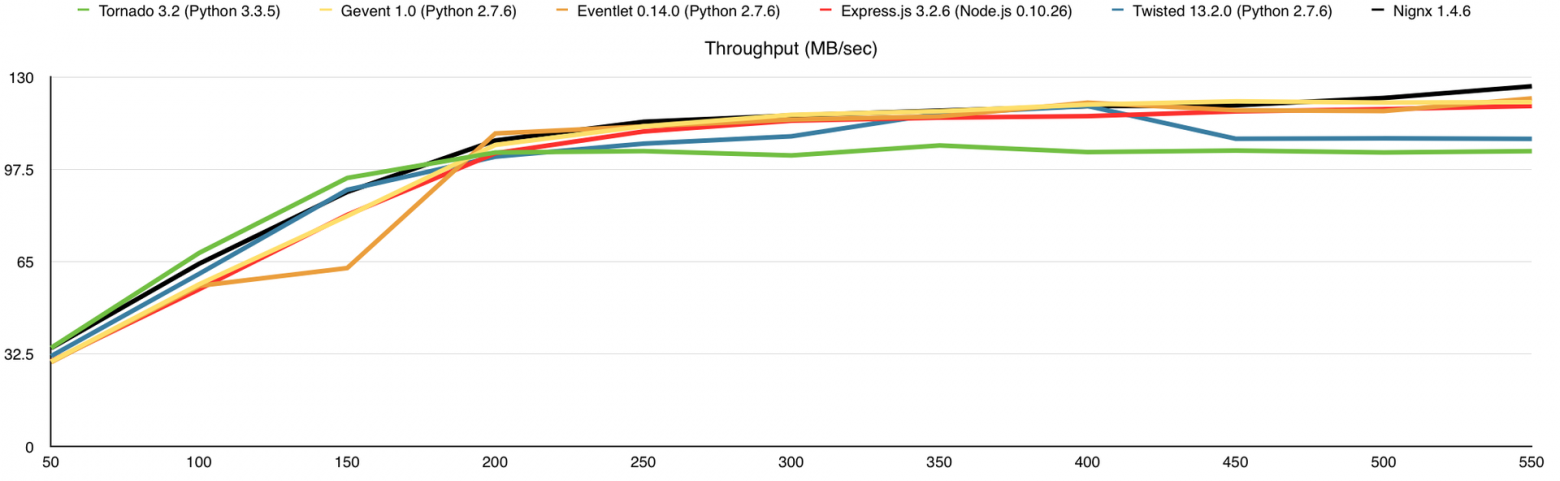
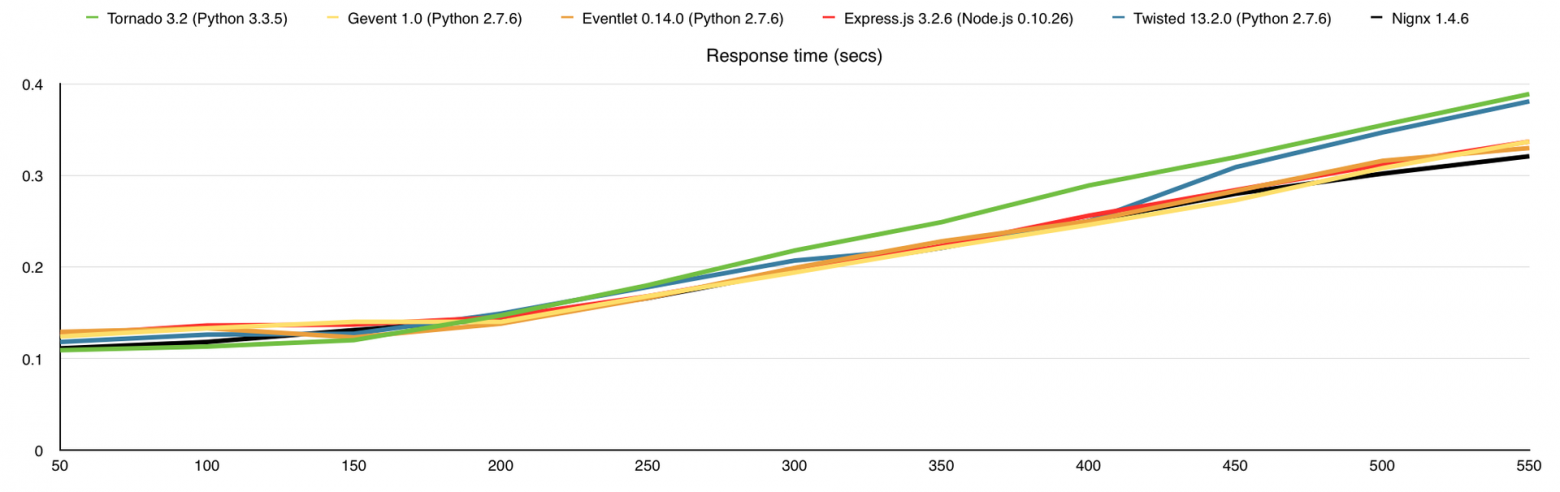
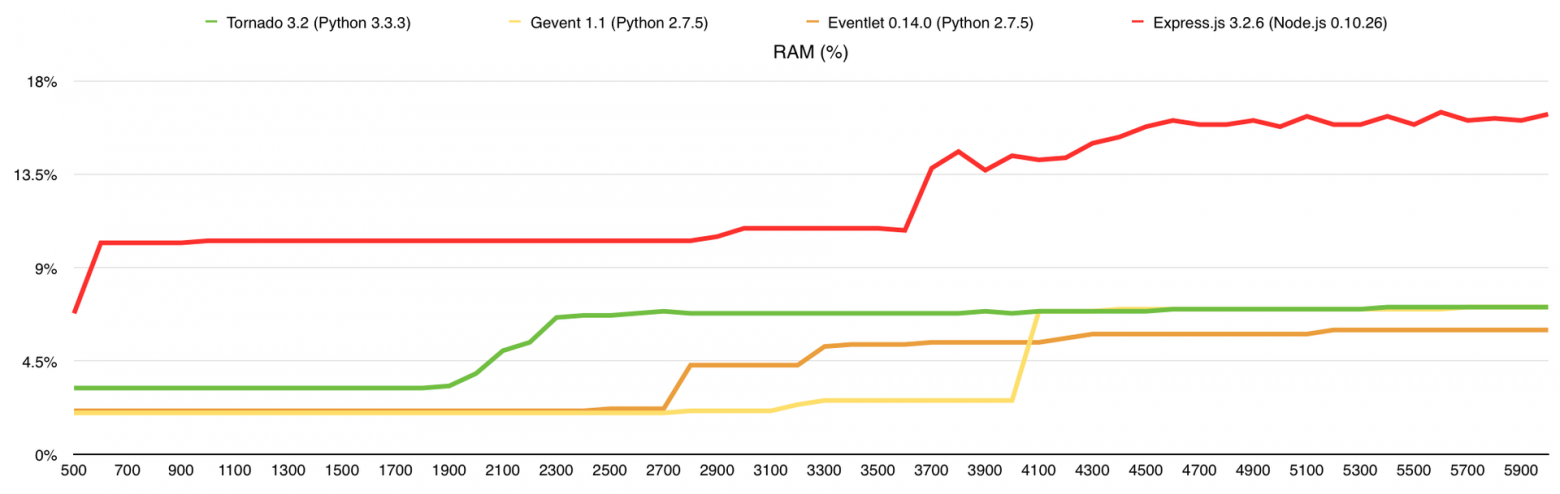
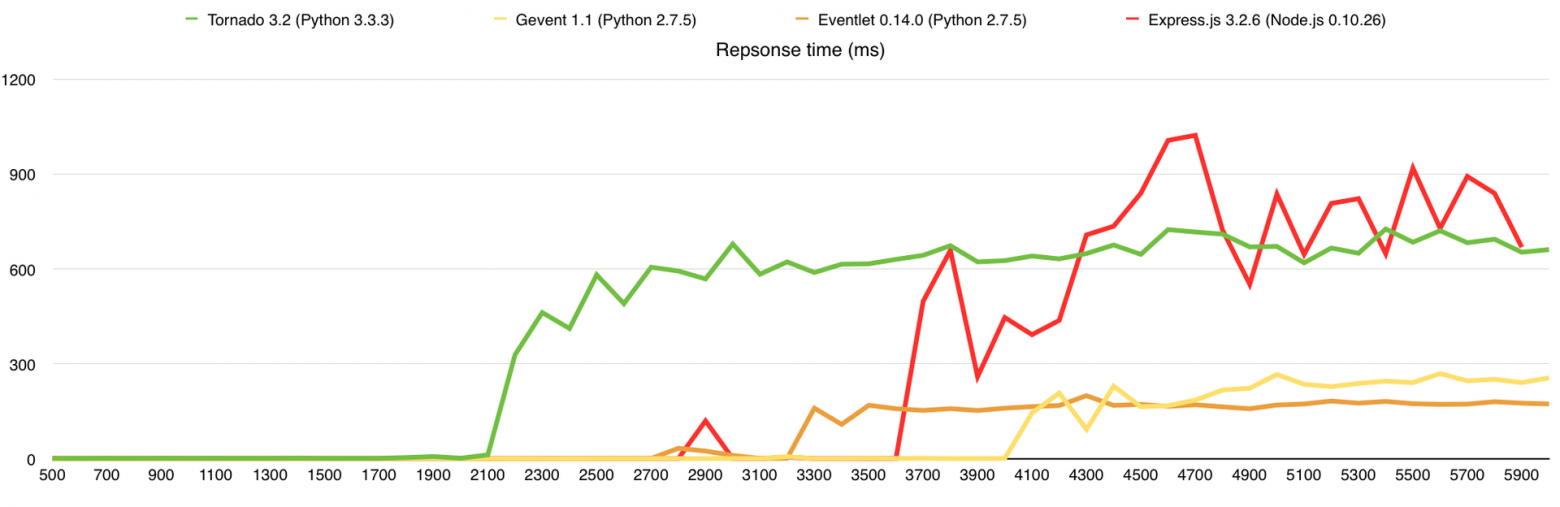
В этом тесте я добавил потребление оперативной памяти, а также веб-сервер nginx для сравнения. Здесь узким местом является канал связи, причём 1-го ядра достаточно для того, что бы весь этот канал в 1Gbps загрузить.
Результаты (в скобках количество обработанных запросов без ошибок):
На этом можно было завершать статью, но я хотел использовать MongoDB GridFS в своём проекте, поэтому решил посмотреть, как изменится производительность с её использованием. Данный тест аналогичен 3-му, за исключением того, что все изображения в количестве 10 000 штук я залил в MongoDB и переписал веб-серверы так, что бы они раздавали файлы из базы. Итак, что мы получаем:
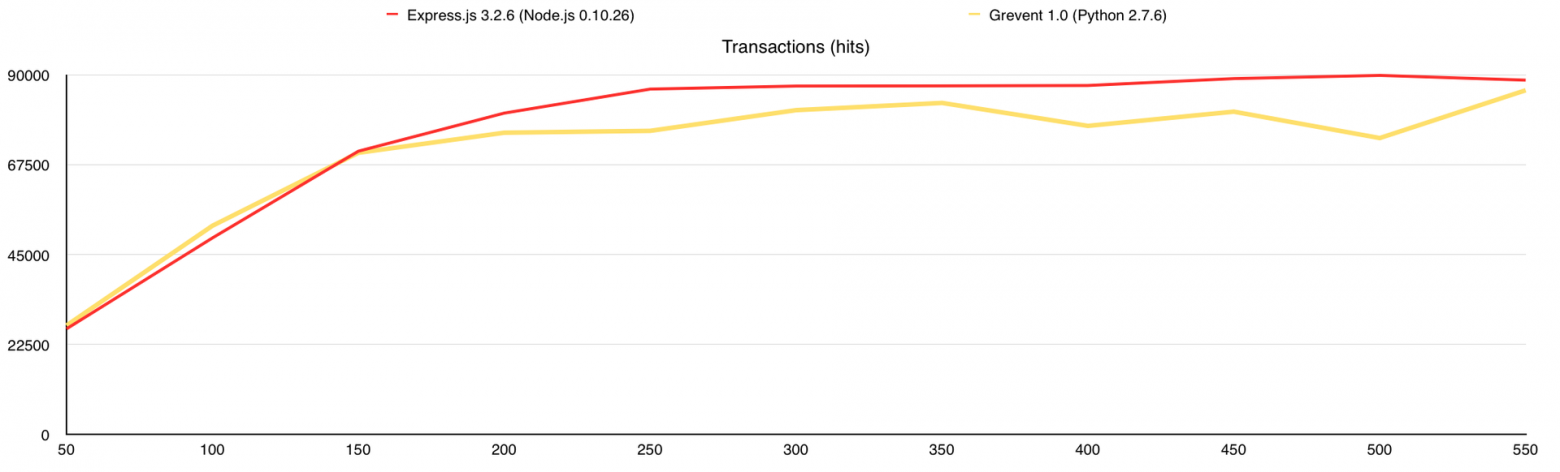
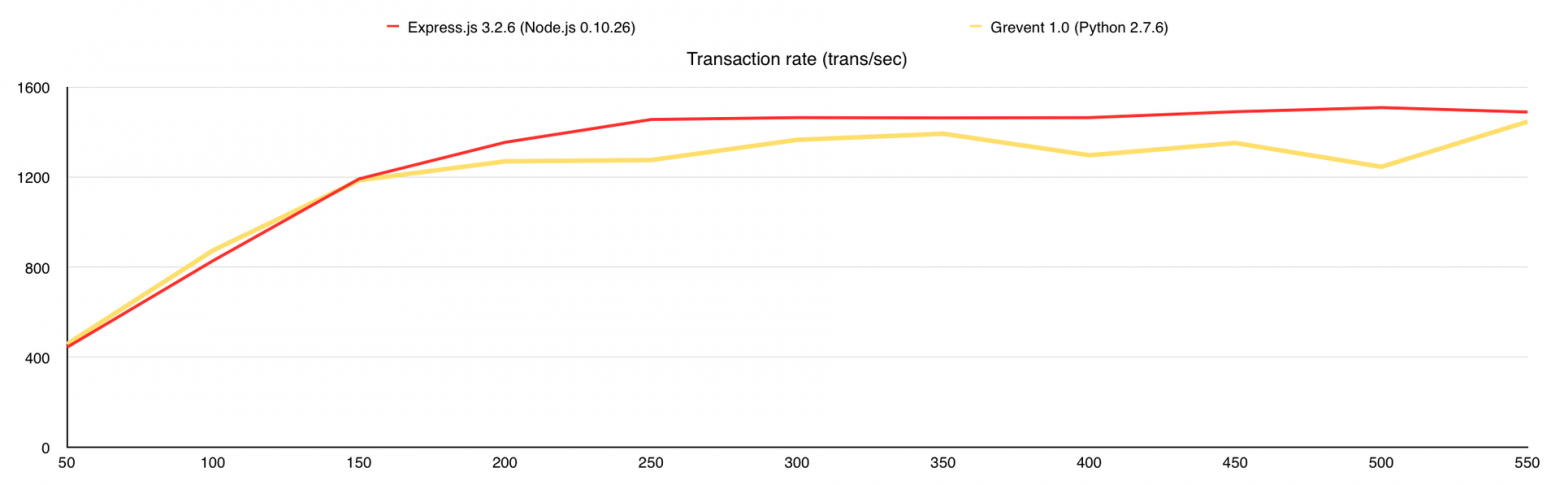
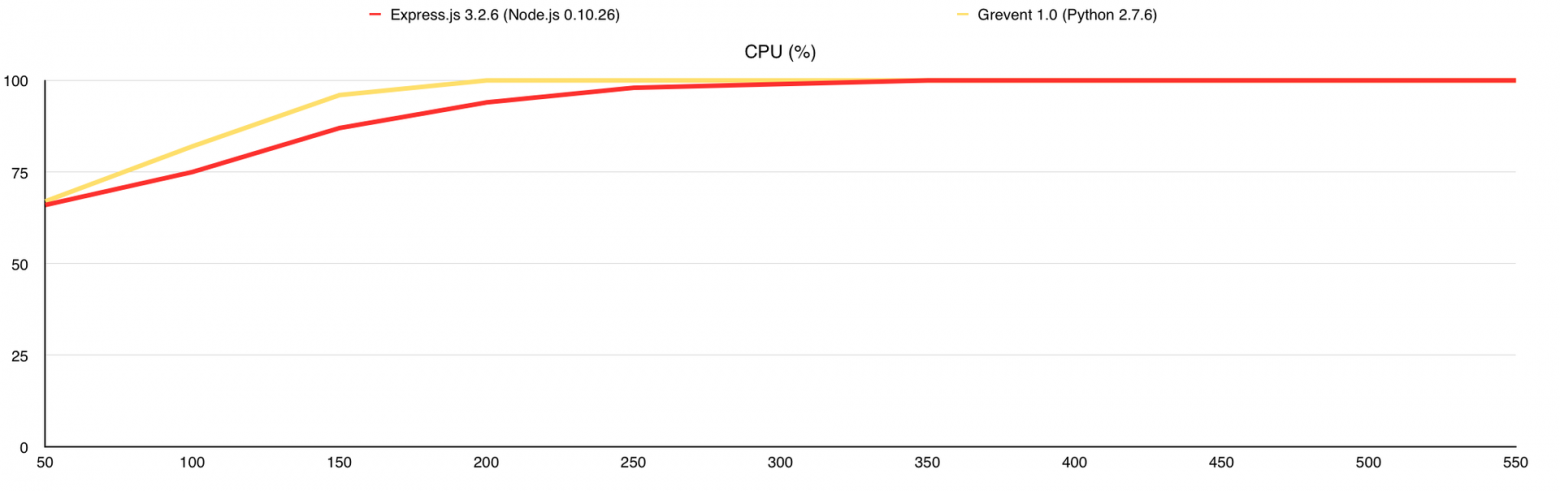

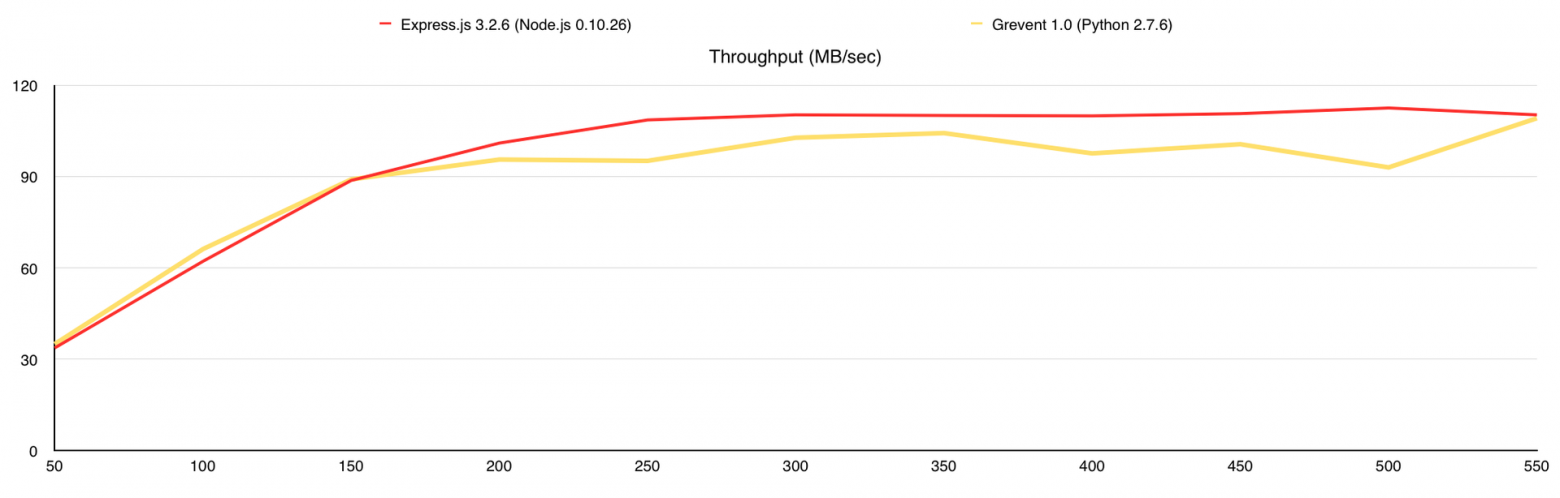
Во время теста у Gevent были ответы с ошибками, поэтому я добавил график «Количество ошибок». В целом GridFS вполне можно использовать, но стоит учитывать, что сама база создаёт немалую нагрузку на CPU, а у меня было 7 свободных ядер в её распоряжении, когда с файловой системой все гораздо проще.
Результаты (в скобках количество обработанных запросов без ошибок):
Если серьёзно, все зависит от условий, при которых будет работать ваш проект. Можно провести огромное число тестов, но когда сервис будет написан, все скорее всего будет совсем по другому. Например, при увеличении числа картинок с 10 000 до 1 000 000 узким местом уже становится производительность жёсткого диска, а не канал связи.
Если вы решите провести собственное тестирование или более подробно изучить моё, то этот список вам должен помочь.
Полные отчёты с индивидуальными графиками и цифрами можно скачать по этим ссылкам:
В своих тестах я использовал:
В тестах принимали участие:
Всем спасибо за внимание.
Подписывайтесь на меня в Twitter, я рассказываю о работе в стартапе, своих ошибках и правильных решениях, о python и всём, что касается веб-разработки.
P.S. Я ищу разработчиков в компанию, подробности у меня в профиле.
Я хочу обратить ваше внимание на то, что эти материалы не являются руководством к выбору фреймворка и могут содержать спорные моменты. Я вообще не собирался публиковать результаты этого исследования, но когда они попадались мне на глаза я ловил себя на мысли, что это может быть кому-нибудь полезно. Теперь я начну забрасывать вас графиками.
1. Text / Httperf / VPS 1 CPU, 512Mb RAM
Первый тест я провёл на самом дешёвом VPS DigitalOcean (1 Core, 512Mb RAM, 20Gb SSD). Для тестирование производительности использовалась утилита httperf. Что бы произвести необходимую нагрузку были задействованы VPS такой же конфигурации, в количестве 5 штук. Для одновременного запуска теста на всех клиентах я использовал утилиту autobench со следующими параметрами:
autobench_admin --single_host --host1 example.com --port1 8080 --uri1 / --low_rate 50 --high_rate 600 --rate_step 10 --num_call 10 --num_conn 6000 --timeout 5 --clients XX.XX.XX.XX:4600,XX.XX.XX.XX:4600,XX.XX.XX.XX:4600,XX.XX.XX.XX:4600,XX.XX.XX.XX:4600 --file bench.tsvЭто тест начинает выполнение с 50 соединений в секунду (10 запросов через одно соединение) и с шагом в 10 соединений в секунду достигает 600. Каждый тест устанавливает всего 6000 соединений и все запросы, которые не были обработаны в течение 5 секунд, считаются ошибкой.
Все HTTP серверы делают одно и то же, а именно возвращают строку «I am a stupid HTTP server!» на каждый запрос. Результаты получились следующими (по оси Х – количество запросов в секунду):
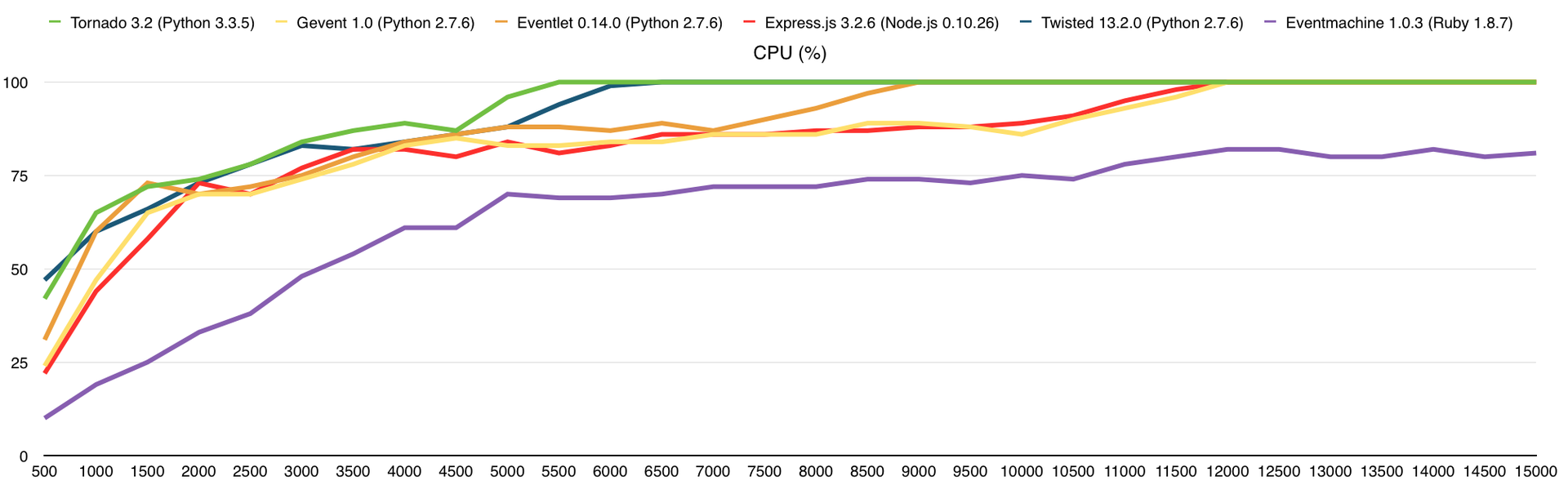
Нагрузка на процессор

Потребление оперативной памяти (в % от 512Mb)

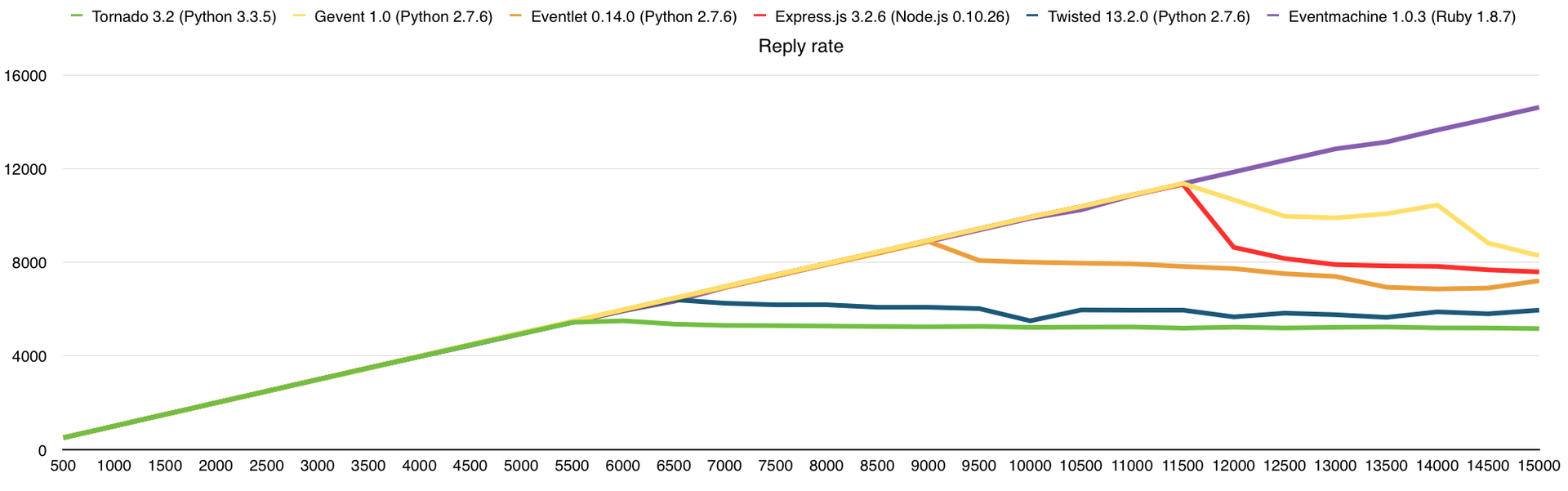
Количество ответов

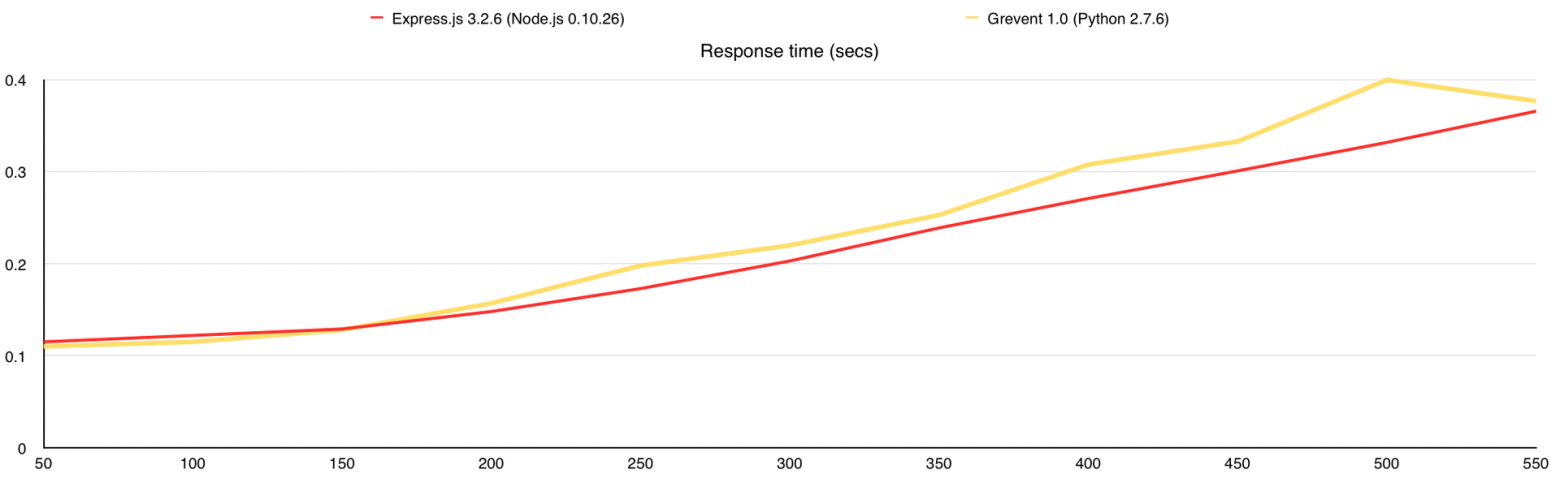
Время ответа (в миллисекундах)

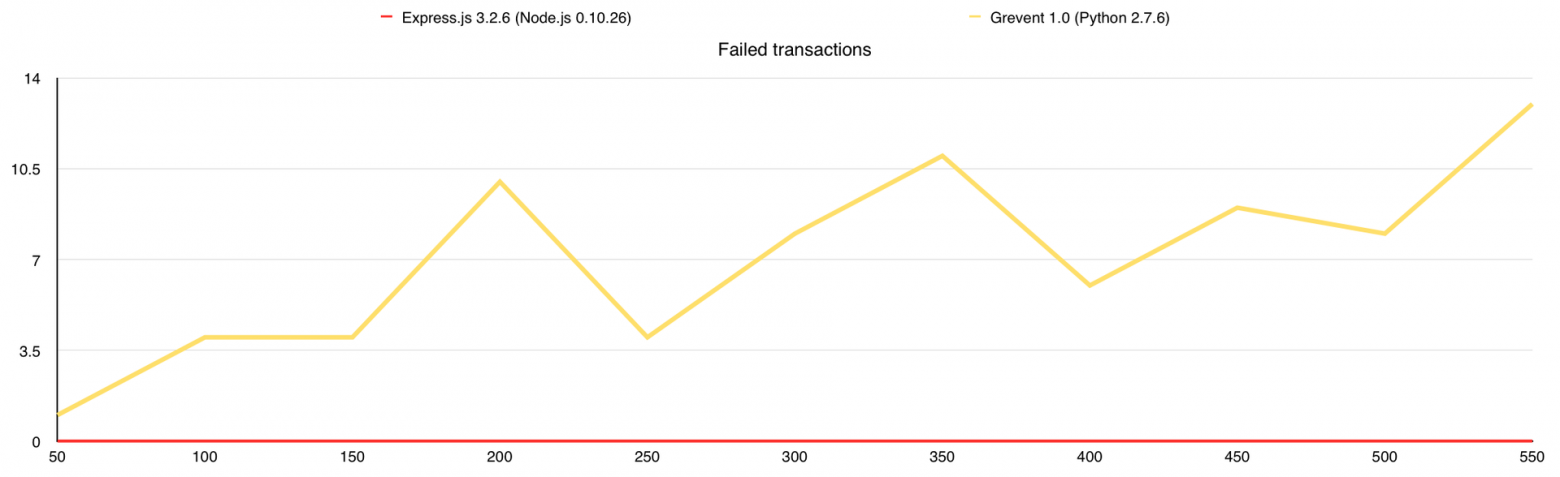
Количество ошибок

Как только мы достигаем 100% использования CPU, потребление оперативной памяти начинает расти, количество ответов падает, время ответа на каждый запрос растёт и начинают появляться ошибки. Как я писал выше, каждый запрос, который не получил ответ в течение 5 секунд, считается ошибкой и здесь именно это и происходит, это можно проследить на графике «Время ответа».
Результаты (в скобках количество обработанных запросов без ошибок):
- Gevent (4700)
- Express.js (3600)
- Eventlet (3200)
- Tornado (2200)
Я никогда не бываю доволен своей работой полностью, поэтому уже через пару часов я решил, что тестировать производительность на VPS не самый лучший выбор. Между фреймворками разница в производительности понятна и какие-то выводы сделать можно, но узнать сколько клиентов мы в состоянии обслужить на одном ядре настоящего процессора мы не можем. Одно дело делить с кем-то неизвестные ресурсы и совсем другое когда все ресурсы известны и в нашем распоряжении.
2. Text / Httperf / Intel Core i7-4770 Quad-Core Haswell, 32 GB DDR3 RAM
Для следующего теста я арендовал выделенный сервер у Hetzner (EX40) с процессором «Intel Core i7-4770 Quad-Core Haswell» и 32 GB DDR3 RAM.
На этот раз я создал 10 VPS, которые будут создавать необходимую нагрузку и запустил autobench со следующими параметрами:
autobench_admin --single_host --host1 example.com --port1 8080 --uri1 / --low_rate 50 --high_rate 1500 --rate_step 50 --num_call 10 --num_conn 15000 --timeout 5 --clients XX.XX.XX.XX:4600,XX.XX.XX.XX:4600,XX.XX.XX.XX:4600,XX.XX.XX.XX:4600,XX.XX.XX.XX:4600 ... --file bench.tsvЭто тест начинает выполнение с 50 соединений в секунду (10 запросов через одно соединение) и с шагом в 50 соединений в секунду достигает 1500. Каждый тест устанавливает всего 15000 соединений и все запросы, которые не были обработаны в течение 5 секунд, считаются ошибкой.
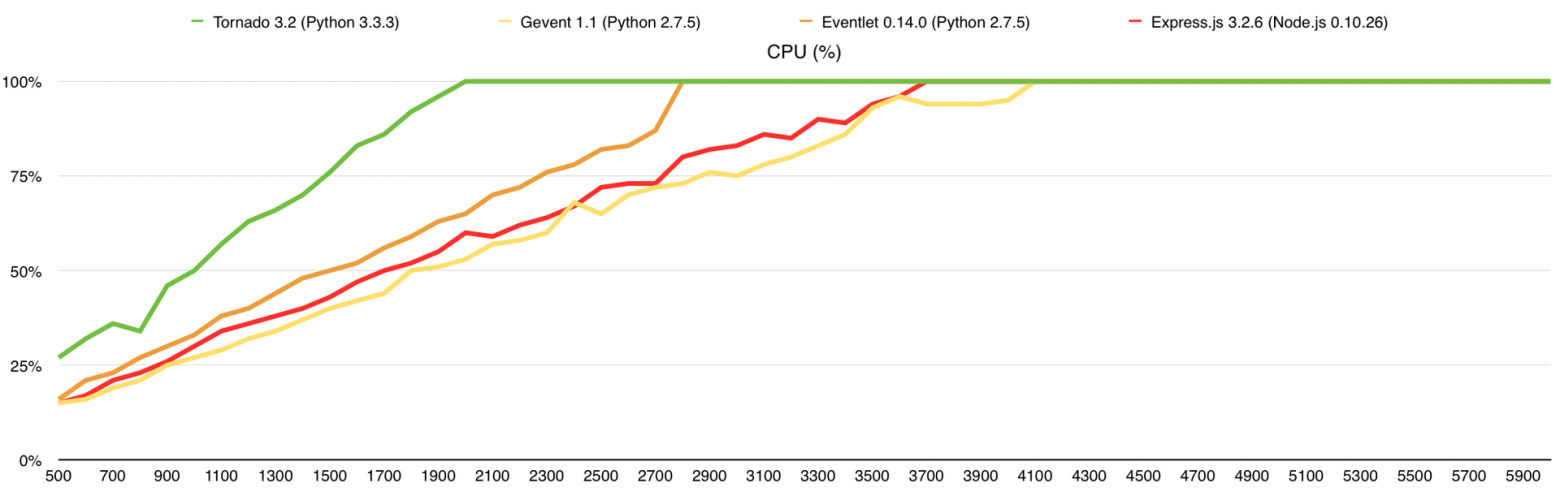
Исходный код серверов тот же, что и в первом тесте. Запущена одна копия сервера, которая использует только 1 ядро. В этот тест я добавил фреймворки Twisted 13.2 и Eventmachine 1.0.3. Потребление памяти я удалил из результатов теста потому что разница, по современным меркам, ничтожна. Не буду тянуть кота за хвост, вот результаты:
Нагрузка на процессор
Количество ответов
Время ответа (в миллисекундах)
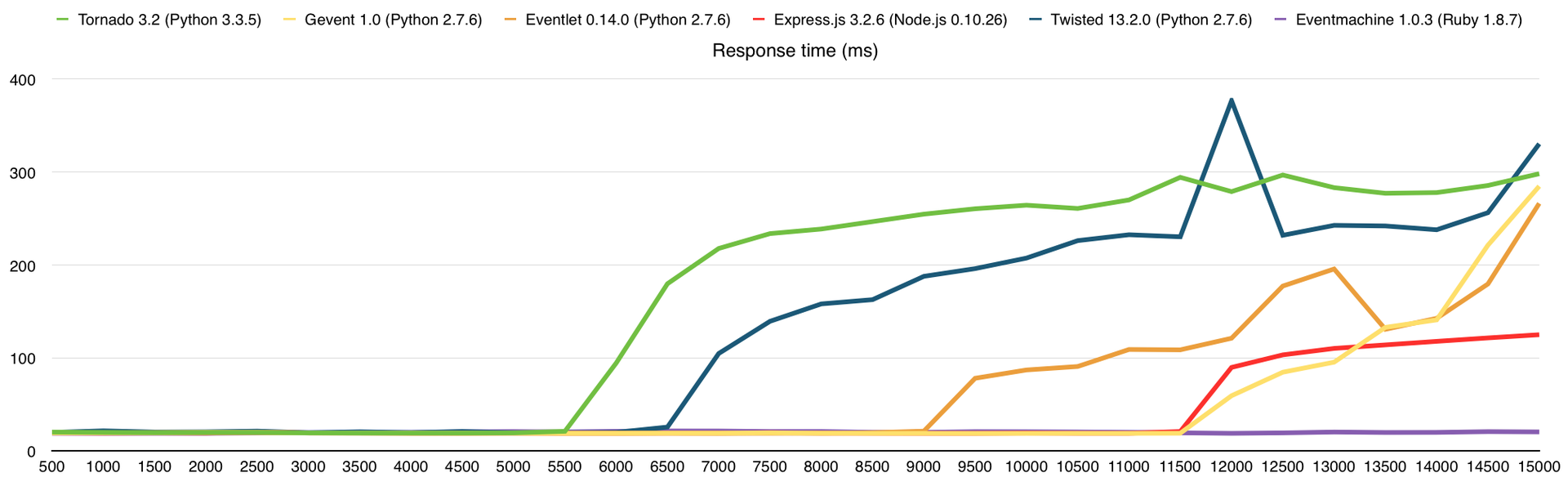
Количество ошибок

Тут, как и прежде, упёрлись в CPU, чего и следовало ожидать. В среднем, производительность здесь выше в 3 раза, чем на VPS DigitalOcean (1 Core, 512Mb), из чего можно сделать соответствующие выводы о количестве выделенных нам ресурсов.
Результаты (в скобках количество обработанных запросов без ошибок):
- Eventmachine (подробности ниже)
- Gevent (12500)
- Express.js (11500)
- Eventlet (9000)
- Twisted (7000)
- Tornado (6500)
Eventmachine
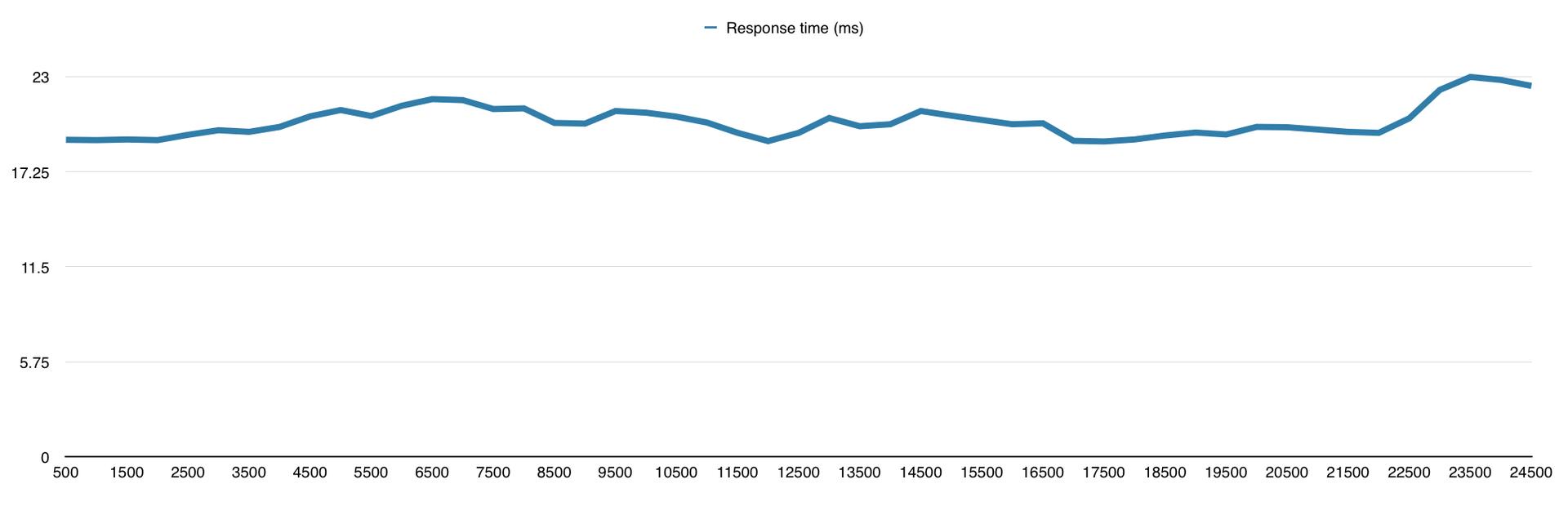
Eventmachine меня удивил своей производительностью и ушёл далеко от конкурентов, из-за чего мне пришлось увеличить нагрузку до 25000 запросов в секунду специально для него. Результат на графиках:
Нагрузка на процессор
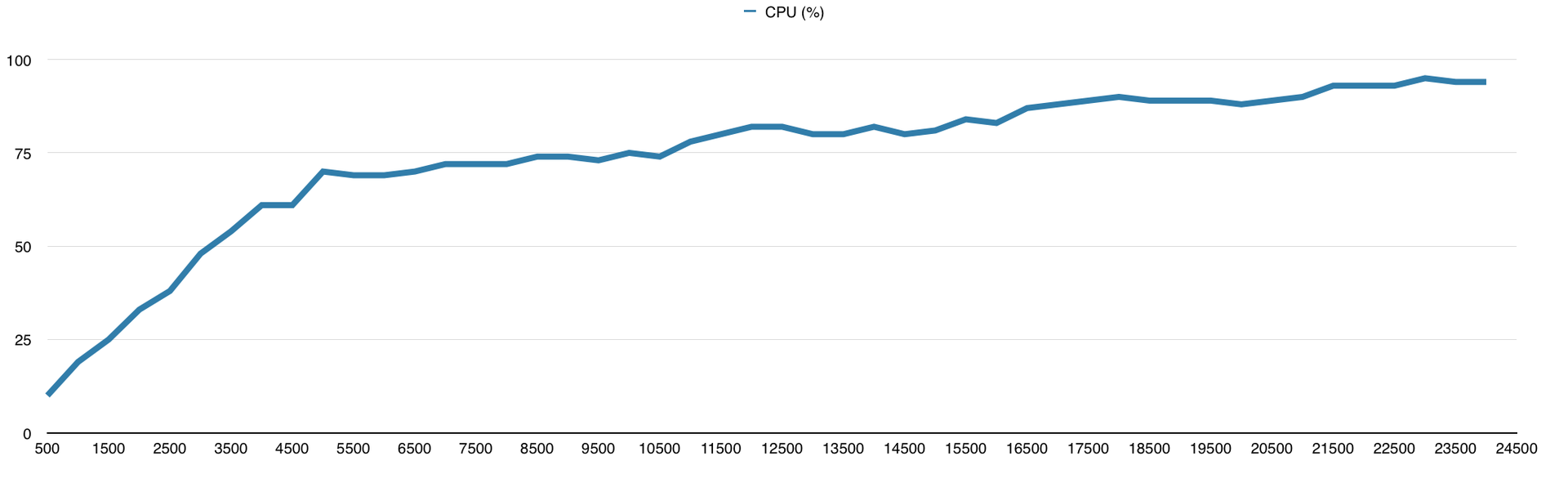
Количество ответов

Время ответа (в миллисекундах)
Количество ошибок
У меня есть подозрения, что и 30 000 запросов он бы смог обработать, но мне надо было двигаться дальше, поэтому я не смог в этом убедиться. Вообще я к этому моменту уже знал, что буду использовать Python для своего проекта, так что фреймворки на других языках мне нужны были просто для сравнения.
3. Files / Siege / Intel Core i7-4770 Quad-Core Haswell, 32 GB DDR3 RAM
Как я писал выше, я не бываю доволен своей работой полностью, поэтому я лёг спать с чувством выполненного долга, а проснулся с мыслью «нужно больше тестов!». Отдавать строку текста на каждый запрос это конечно хорошо, но это не единственная функция веб-сервера, значит будем раздавать файлы.
Для этого теста я использовал 10 VPS, что бы создать необходимую нагрузку. Экспериментальным путём я выяснил, что на 1 VPS DigitalOcean, в среднем, выделен канал 100Mbps. Сервер у меня был с каналом 1Gbps и мне надо было его полностью нагрузить. Файлами для раздачи послужили изображения с интернет-магазина в количестве 10 000 штук, разных размеров. Для создания нагрузки я использовал утилиту siege со следующими параметрами:
siege -i -f fileslist.txt -c 55 -b -t1MВ filelist.txt хранится список файлов, устанавливается 55 соединений и через них мы начинаем долбить сервер запросами в течение 1-й минуты. Файлы при этом выбираются случайным образом из списка fileslist.txt. Опредёленно стоит учесть, что тест этот запускается на 10 машинах одновременно, а значит мы устанавливаем не 55, а 550 одновременных соединений. Более того, эту опцию я постоянно менял от 5 до 55 с шагом в 5, увеличивая тем самым нагрузку на сервер, и устанавливая от 50 до 550 одновременных соединений.
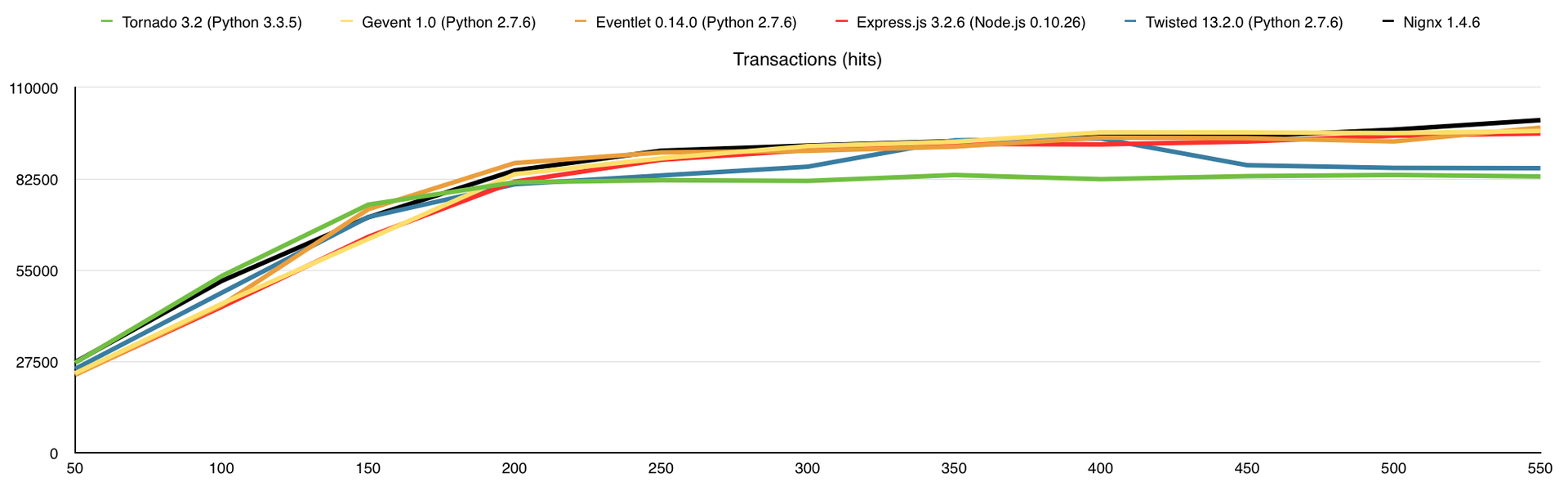
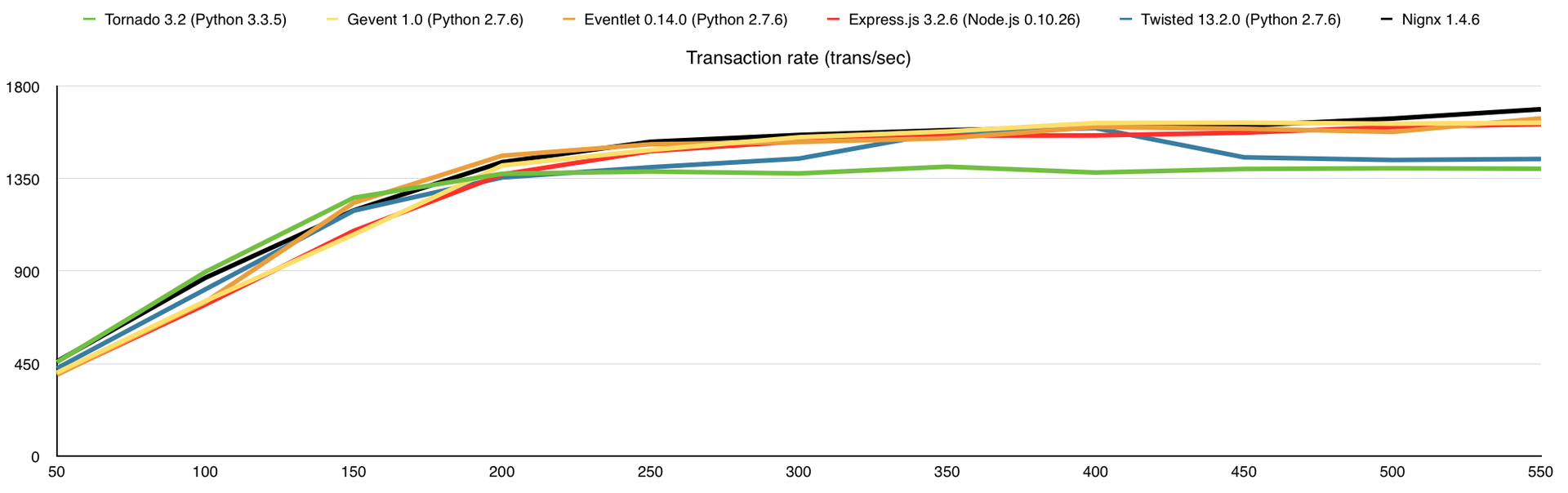
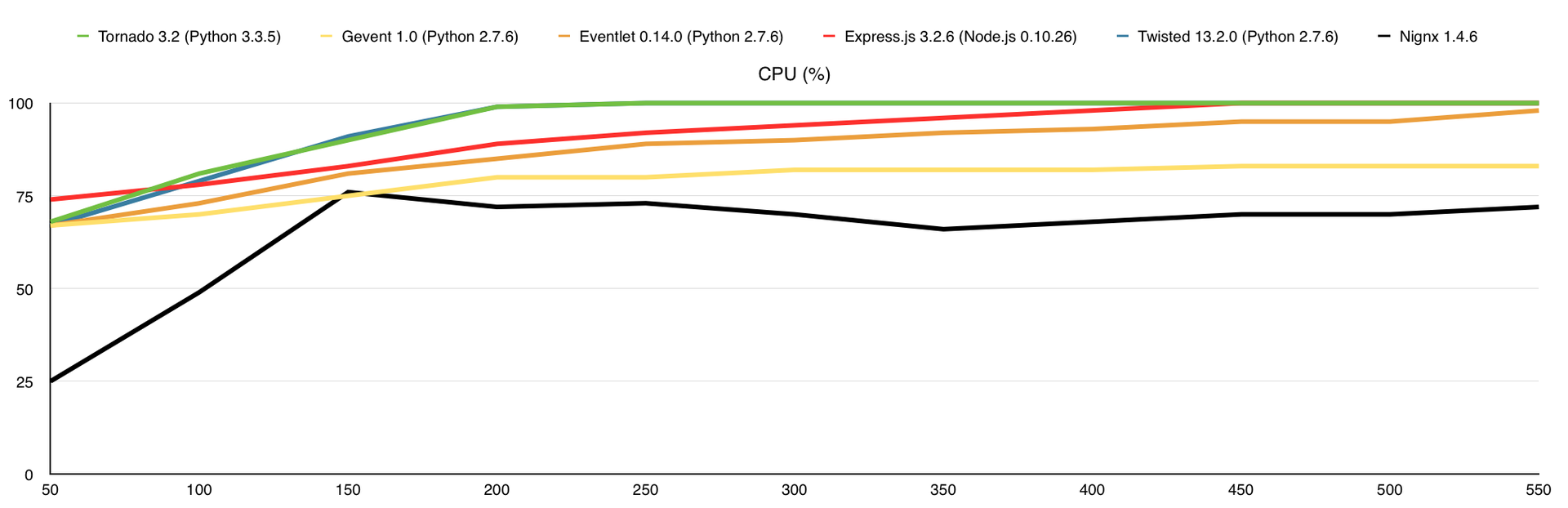
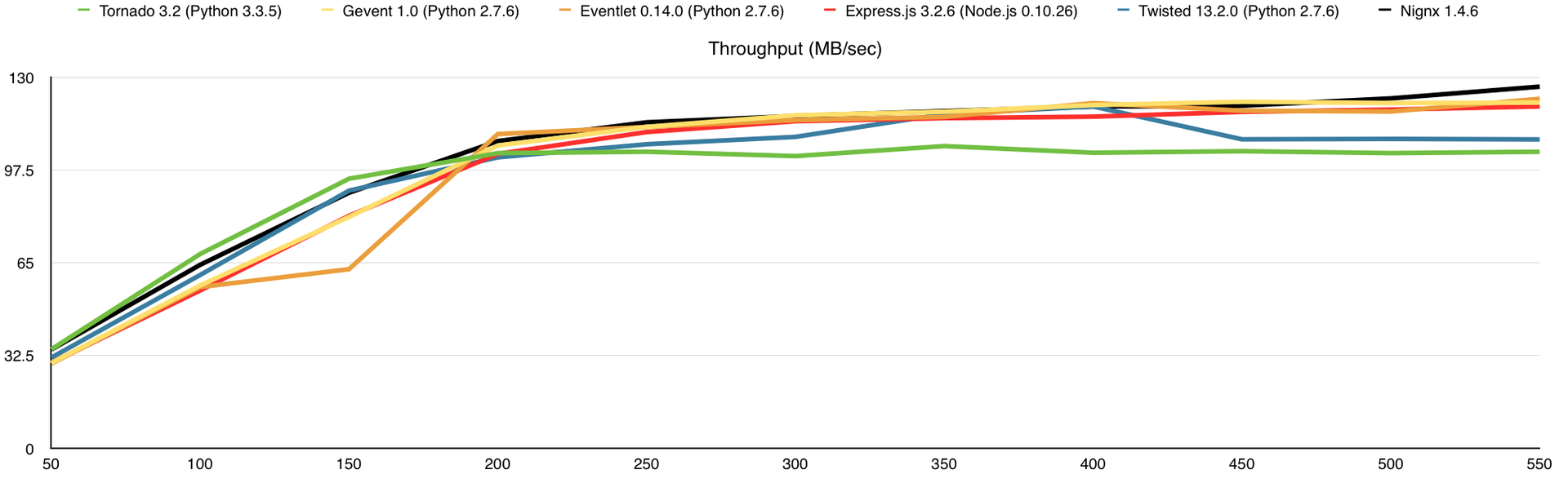
Вот что получаем (по оси Х – количество одновременных соединений):
Количество выполненных запросов
Количество обработанных запросов в секунду
Нагрузка на процессор (в %)
Потребление оперативной памяти (в % от 32Gb)

Нагрузка на канал связи (мегабайт в секунду)
Среднее время ответа на запрос (в секундах)
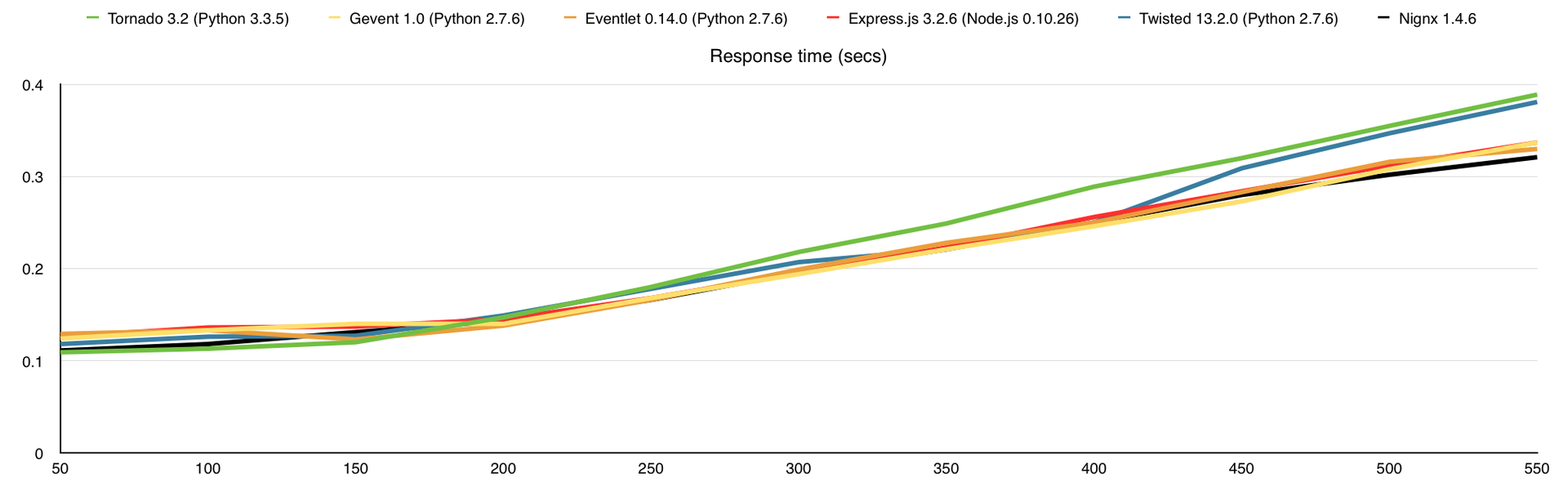
В этом тесте я добавил потребление оперативной памяти, а также веб-сервер nginx для сравнения. Здесь узким местом является канал связи, причём 1-го ядра достаточно для того, что бы весь этот канал в 1Gbps загрузить.
Результаты (в скобках количество обработанных запросов без ошибок):
- Nignx (100175)
- Eventlet (97925)
- Gevent (96918)
- Express.js (96162)
- Twisted (85733)
- Tornado (83241)
4. GridFS / Siege / Intel Core i7-4770 Quad-Core Haswell, 32 GB DDR3 RAM
На этом можно было завершать статью, но я хотел использовать MongoDB GridFS в своём проекте, поэтому решил посмотреть, как изменится производительность с её использованием. Данный тест аналогичен 3-му, за исключением того, что все изображения в количестве 10 000 штук я залил в MongoDB и переписал веб-серверы так, что бы они раздавали файлы из базы. Итак, что мы получаем:
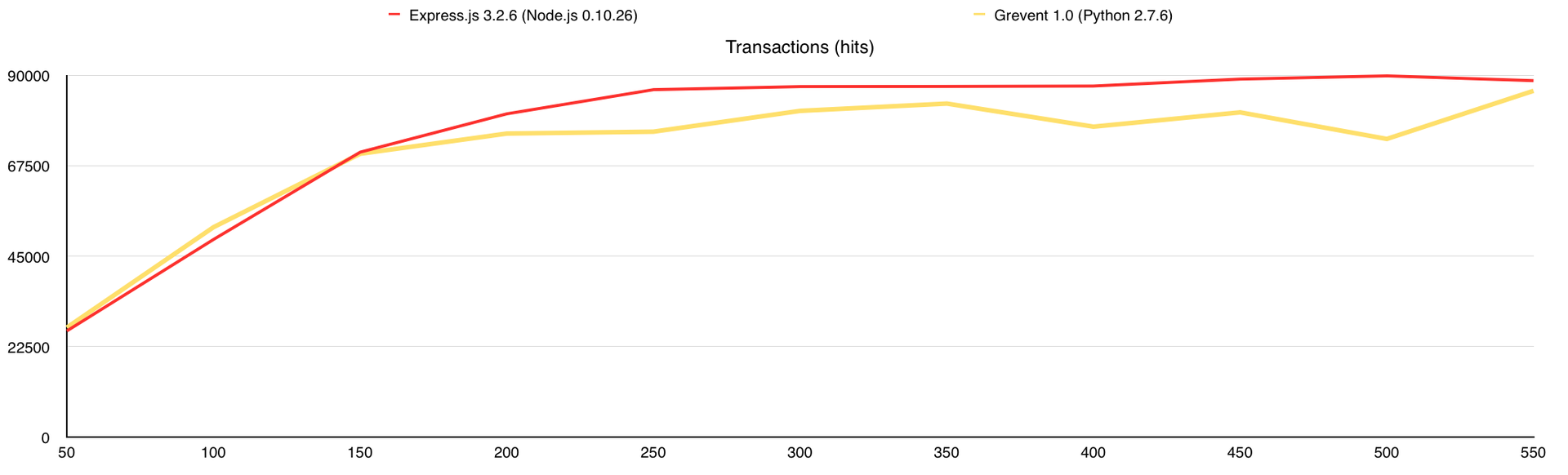
Количество выполненных запросов
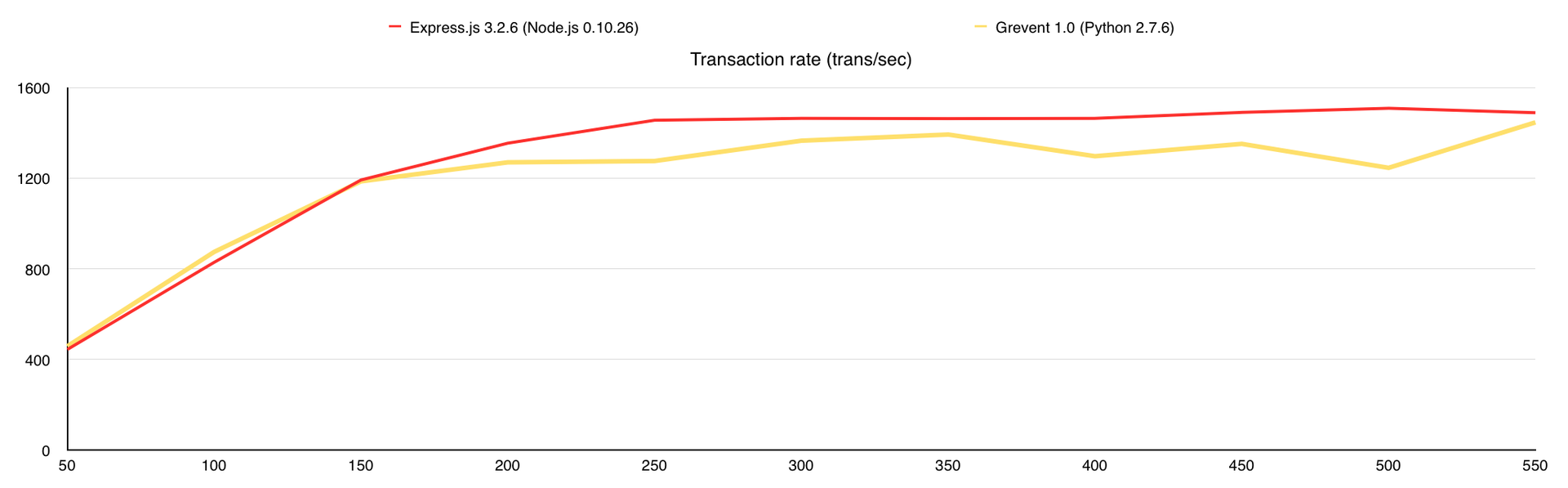
Количество обработанных запросов в секунду
Нагрузка на процессор (в %)

Потребление оперативной памяти (в % от 32Gb)

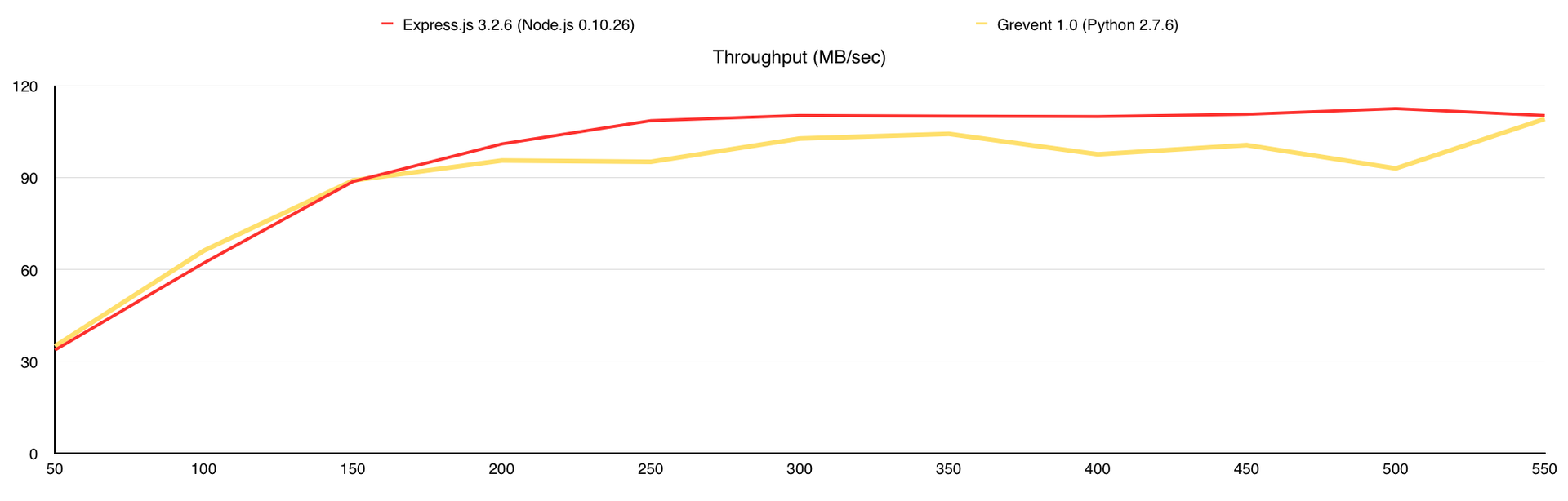
Нагрузка на канал связи (мегабайт в секунду)
Среднее время ответа на запрос (в секундах)
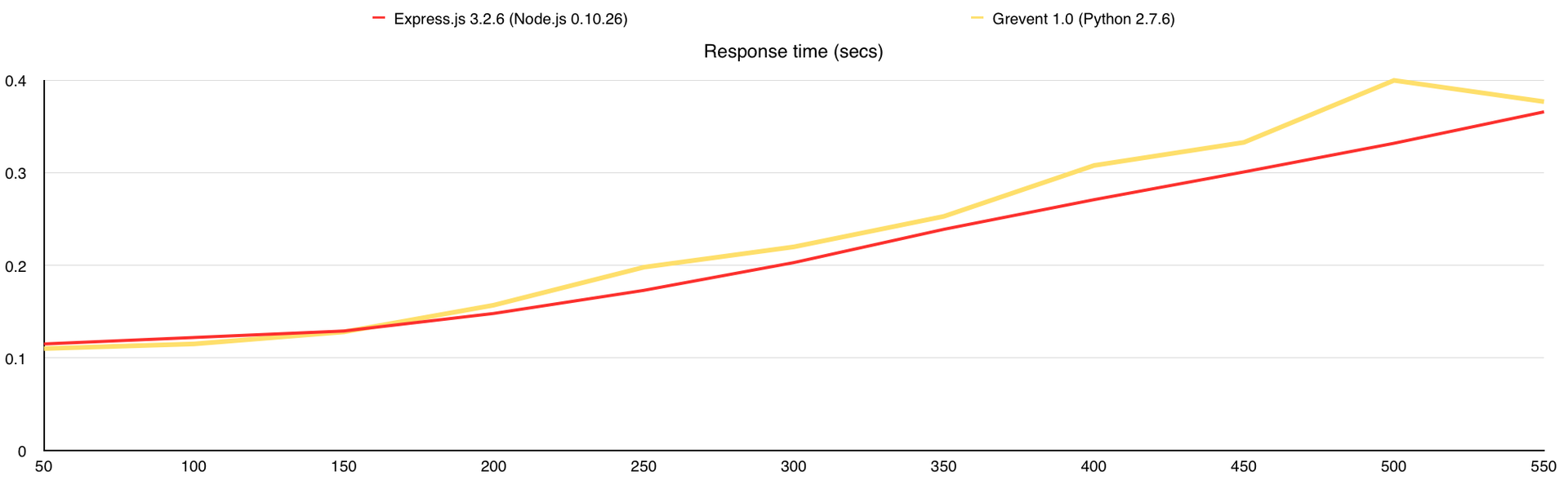
Количество ошибок
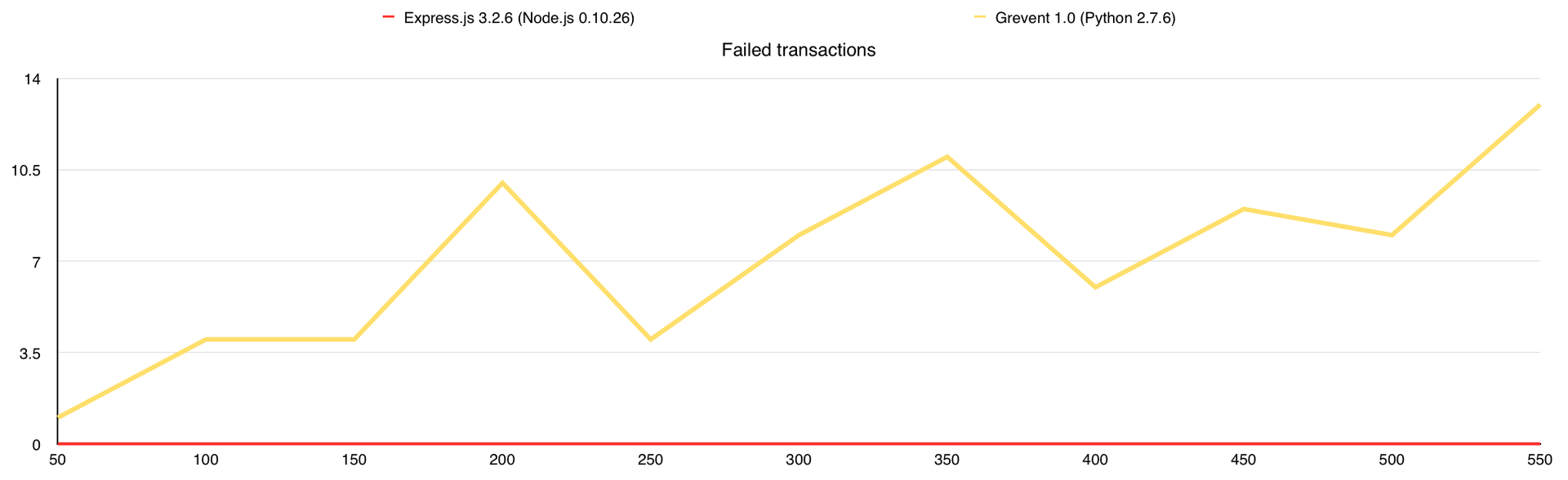
Во время теста у Gevent были ответы с ошибками, поэтому я добавил график «Количество ошибок». В целом GridFS вполне можно использовать, но стоит учитывать, что сама база создаёт немалую нагрузку на CPU, а у меня было 7 свободных ядер в её распоряжении, когда с файловой системой все гораздо проще.
Результаты (в скобках количество обработанных запросов без ошибок):
- Express.js (88714)
- Gevent (86182)
Выводы
- MacBook Pro Retina действительно отрабатывает 9 часов на одном заряде.
- Node.js не единственный инструмент, как считают некоторые, для разработки сетевых приложений.
- Gevent выдаёт очень хорошую производительность.
- Оформление статьи занимает больше времени, чем её написание.
- Тестирование производительности сложный процесс, который занимает много времени.
Если серьёзно, все зависит от условий, при которых будет работать ваш проект. Можно провести огромное число тестов, но когда сервис будет написан, все скорее всего будет совсем по другому. Например, при увеличении числа картинок с 10 000 до 1 000 000 узким местом уже становится производительность жёсткого диска, а не канал связи.
Материалы
Если вы решите провести собственное тестирование или более подробно изучить моё, то этот список вам должен помочь.
Отчёты
Полные отчёты с индивидуальными графиками и цифрами можно скачать по этим ссылкам:
- Text / Httperf / VPS 1 CPU, 512Mb RAM
- Text / Httperf / Intel Core i7-4770 Quad-Core Haswell, 32 GB DDR3 RAM
- Files / Siege / Intel Core i7-4770 Quad-Core Haswell, 32 GB DDR3 RAM
- GridFS / Siege / Intel Core i7-4770 Quad-Core Haswell, 32 GB DDR3 RAM
Иструменты
В своих тестах я использовал:
Фреймворки
В тестах принимали участие:
- Gevent (код текстового, файлового, GridFS сервера)
- Express.js (код текстового, файлового, GridFS сервера)
- Eventlet (код текстового, файлового сервера)
- Tornado (код текстового, файлового сервера)
- Eventmachine (код текстового сервера)
- Twisted (код текстового, файлового сервера)
Всем спасибо за внимание.
Подписывайтесь на меня в Twitter, я рассказываю о работе в стартапе, своих ошибках и правильных решениях, о python и всём, что касается веб-разработки.
P.S. Я ищу разработчиков в компанию, подробности у меня в профиле.
