Привет, хабр.
Я думаю, многие из вас слышали о такой технологии — Microsoft Workflow. Она довольно неплохо раскручена, есть посты на хабре, есть книги на английском и на русском. Да и Microsoft публикует красивые картинки.
Суть технологии в том, что программисты создают API, а бизнес аналитик уже сам создает бизнес процесс. Без посредников.
Например, клиент запросил вот такой бизнес процесс:
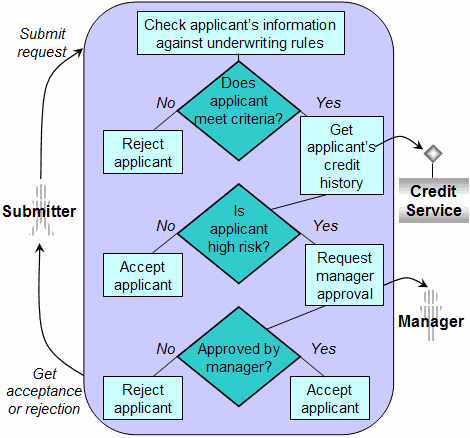
И далее бизнес-аналитик именно его и рисует. Программистам стоит лишь реализовать процедуры Accept, Reject и остальные похожие кубики. Круто, да?
Мне не особенно повезло в том, что я слышал об этой технологии только из книжек и из маркетинговых изданий. Ну и конечно из презентаций вида «Мы посмотрели на MS WF полгода назад, уже месяц немного используем — полет нормальный!». Я же работаю с продуктом, в котором Workflow внедрена уже 6 лет (сам я с ним работал всего пару лет), который имеет достаточно высокую нагрузку, а потому хотел бы показать основные подставы и засады этой библиотеки. Я надеюсь, пост поможет избежать тех же граблей, на которые наступали мы.
Идея крайне проста: программист создает кубики — Activity. Каждая Activity может иметь параметры. Например, можно создать RejectActivity cо свойством User. Чаще всего это будет означать, что Reject будет происходить для этого User'а. Каждая Activity, по сути, имеет внешнее представление (то есть то, как её увидит бизнес-аналитик) и реализацию. Кстати, здесь мы сразу получаем засаду #1: это один и тот же класс. Ну то есть наш красивый дизайнер должен линковаться на реализацию. Но это решается крайне просто с помощью IoC, потому назовем это лишь разминкой.
Когда бизнес-аналитик сделал дизайн (то есть нарисовал кучу activity, соединил их стрелочками), его можно сохранить в виде Xaml представления. Которое сможет загрузить Microsoft Workflow Runtime и начать выполнять.
На некоторых Activity можно сделать паузу (например, Delay Activity). В этом случае рабочее состояние сериализуется в базу. Ну и через определенное время (как мы сами указали) наш рабочий процесс опять проснется и пойдет дальше. Для сохранения нам потребуется база или свой написанный сохранятель. Всё круто, да?
Как Вы поняли из текста выше, иногда бизнес-процесс следует ставить на паузу. Типичный пример: мы ждем ответа от пользователя (то есть используем Event Activity). В этом случае происходит обыкновенная сериализация (xml сериализация для Workflow 4.0+, бинарная для более старых версий). Я думаю, читатели сразу поняли, что здесь очень легко сохранить лишнее или же немного ошибиться при сохранении в релизе А, а загрузке в релизе Б. Типичный пример из Workflow 3.0 — Вы подписались на Event с помощью лямбы/анонимного метода. Ну и, если вы знаете, тем самым Вы создали новое поле класса, которое сохраняется в базу. И у вас упадет загрузка, так как упадет десериализация. Отсюда, большой совет: Весь рабочий код должен быть строго вынесен за пределы ваших Activity. Все поля должны сохраняться где-нибудь подальше от Workflow. В Activity храним самый минимум и самые простые типы. Пусть лучше пострадает внутренний дизайн, чем стабильность.
На самом деле, подстава здесь не закончилась. Самое классное начинается тогда, когда надо поменять набор полей. Например, в нашу RejectActivity из примера понадобиться добавить Reason. И вот тут код должен быть готов к тому, что старая RejectActivity не содержит этого поля. Для Workflow 4.0+ можно еще поменять сериализованное представление в базе, а вот для Workflow 3.0 такой способ не всегда подойдет (так как хранится сжатое бинарное представление), потому быстро всё это не обновить.
На самом деле, у Microsoft Workflow целая серия недоработок. Причем, проблемы касаются как единичного выполнения (то есть ряд операций сделан не эффективно), так и распределения нагрузки. Однако, обо всем по порядку.
Представим, у нас идет бизнес процесс, в котором есть нулевые ожидания. Не важно, как они получились. Важно то, что они есть. Workflow трактует любое ожидание как отличный повод сохраниться, ну то есть сделать сериализацию, а потом загрузить опять нашу работу (правда, не совсем сразу, но не важно). Естественно, на время реакции это сказывается самым неблагоприятным образом. Отсюда совет: используйте Delay Activity как можно реже, а еще лучше — в связке с If Activity, которая проверит, что ждать, собственно, и не надо. Другой неприятный момент связан с тем, что если Вы сказали «ждать 5 суток», то простыми способами Вы не заставите Workflow всё-таки не ждать ничего, если наш instance уже в базе. Более того, если Workflow Runtime загрузит вашу работу в память, и увидит, что ждать следует еще кучу времени то она, как ни странно, просто оставит её в памяти. И будет ждать кучу времени. Отсюда, еще совет: из-за подобных проблем не используйте долгое ожидание. Лучше всего использовать много коротких или же просыпаться из-за внешнего Event'а, а уже Ваш внешний сервис разбудит процесс когда надо.
Если верить тем же статьям от Microsoft, Workflow прекрасно умеет распределять работу. Ну то есть Вы можете иметь несколько независимых серверов, каждый из которых будет брать немного заданий, выполнять их, брать следующие и так далее. В этом есть только один недостаток: это выдумка. Всё дело в том, что распределенная реализация Workflow — это крайне странное изделие. Оно работает по следующему алгоритму:
Да, числа 2 и 5 можно поменять. Важно другое: самый первый везунчик заберет вообще всю работу из базы. Кстати, через две минуты он опять вычистит базу, даже если ему есть, чем заняться. Если он не уложится за пять минут для какого-нибудь рабочего процесса, то тут произойдет странная штука: он таки выполнит рабочий процесс (вызовет все WCF соединения и т.д.), попытается сохранить в базу данных, но у него ничего не выйдет (блокировки-то нету!). В итоге в памяти этого Workflow Runtime теперь уже навсегда останется этот ломаный объект. И он не выйдет из неё добровольно до тех пор, пока Вы физически не остановите процесс. Workflow Runtime не будет сам останавливаться, сделать он уже ничего не сможет. Великолепная реализация. Более красивый сценарий случится, если Вы настроите блокировку не на пять минут, а на более продолжительное время. В этом случае после остановки процесса эти записи будут заблокированы. Ну то есть Вам уже нельзя будет просто так останавливать процесс, что может очень негативно сказаться на Production платформе. Эта проблема решается крайне легко: для правильной распределенной работы Вам следует самостоятельно написать процедуры работы с базой (то есть, реализовать все процедуры для параллельной и распределенной работы, сделать свою реализацию WorkflowPersistenceService). Здесь есть, кстати, одна особенность: Вам не обязательно работать с MS Sql базой данных, можете поэкспериментировать с другими способами. На деле, задача решается с помощью простой файловой шары, работает быстро и правильно, однако это не модно.
На самом деле, её нет. Конечно, Microsoft утверждает, что все стало прекрасно, но они забыли про один маленький график: зависимость количества Activity в памяти от общего времени работы (а раньше оно было таким). На деле оно не поменялось:

Это квадратичный график. Тут важны не абсолютные значения времени, а зависимость: насколько долго у Вас будет всё работать, если сложность бизнес-процесса будет расти. Более того, на деле именно такая зависимость времени Execute от общего количества Activity в памяти, и не важно — один это рабочий процесс или несколько. Например, если у Вас 10 параллельных рабочих процессов, то на обработку каждой маленькой Activity будет тратиться больше ресурсов, чем если бы был один рабочий процесс. Или по другому: 10 параллельных задач обрабатываются дольше, чем 10 последовательных задач. Причем, с нелинейной зависимостью.
В предыдущей части я написал, как работает Persistence Service: он забирает всё из базы. На деле такой фокус из 5000 параллельных сложных рабочих процессов губителен для системы: она начинает работать с крайне низкой скоростью: 1-10 Activity в минуту (!!!). И это при условии, что процессор будет загружен почти на 100%. Проблема ясна, но как её решать? Решение: сделать свой обработчик Activity, переиспользовать Activity, cделать эмуляцию Ваших рабочих процессов. По факту Вам придется быстренько реализовать базовый компонент Workflow, который занимается стартом и остановкой Activity. Это потребуется, чтобы во-первых не допускать большое количество запущенных Activity на рабочий процесс (ибо всё тормозит), а во-вторых чтобы ускорить время сериализации/десериализации (побыстрее выгонять лишних из памяти). Microsoft Workflow никогда не удаляет отработанную Activity. Вам же придется всё реализовать так, чтобы завершенные Activity не находились в памяти.
Я постарался описать часть проблем, которые Вас поджидают при работе с Microsoft Workflow. На деле здесь есть большое количество нюансов, но они более-менее решаемы, и я уверен, что Вы справитесь. По факту, если у Вас на работе встанет задача сделать свой настраиваемый бизнес процесс, то лучше все-таки начните использовать Microsoft Workflow. Для прототипа сойдет. Более того, при слабой нагрузке вся эта система может работать. Основные подставы известны — они выше, они вполне решаемы. К тому же, намного лучше работать с системой, от которой известно, что ожидать, чем с той, о которой есть только маркетинговая информация. Ну а если нагрузка начнет расти, Вы сможете модуль за модулем перенести на свою эффективную реализацию.
Я думаю, многие из вас слышали о такой технологии — Microsoft Workflow. Она довольно неплохо раскручена, есть посты на хабре, есть книги на английском и на русском. Да и Microsoft публикует красивые картинки.
Суть технологии в том, что программисты создают API, а бизнес аналитик уже сам создает бизнес процесс. Без посредников.
Например, клиент запросил вот такой бизнес процесс:
И далее бизнес-аналитик именно его и рисует. Программистам стоит лишь реализовать процедуры Accept, Reject и остальные похожие кубики. Круто, да?
Мне не особенно повезло в том, что я слышал об этой технологии только из книжек и из маркетинговых изданий. Ну и конечно из презентаций вида «Мы посмотрели на MS WF полгода назад, уже месяц немного используем — полет нормальный!». Я же работаю с продуктом, в котором Workflow внедрена уже 6 лет (сам я с ним работал всего пару лет), который имеет достаточно высокую нагрузку, а потому хотел бы показать основные подставы и засады этой библиотеки. Я надеюсь, пост поможет избежать тех же граблей, на которые наступали мы.
Как оно работает?
Идея крайне проста: программист создает кубики — Activity. Каждая Activity может иметь параметры. Например, можно создать RejectActivity cо свойством User. Чаще всего это будет означать, что Reject будет происходить для этого User'а. Каждая Activity, по сути, имеет внешнее представление (то есть то, как её увидит бизнес-аналитик) и реализацию. Кстати, здесь мы сразу получаем засаду #1: это один и тот же класс. Ну то есть наш красивый дизайнер должен линковаться на реализацию. Но это решается крайне просто с помощью IoC, потому назовем это лишь разминкой.
Когда бизнес-аналитик сделал дизайн (то есть нарисовал кучу activity, соединил их стрелочками), его можно сохранить в виде Xaml представления. Которое сможет загрузить Microsoft Workflow Runtime и начать выполнять.
На некоторых Activity можно сделать паузу (например, Delay Activity). В этом случае рабочее состояние сериализуется в базу. Ну и через определенное время (как мы сами указали) наш рабочий процесс опять проснется и пойдет дальше. Для сохранения нам потребуется база или свой написанный сохранятель. Всё круто, да?
Подстава с сериализацией
Как Вы поняли из текста выше, иногда бизнес-процесс следует ставить на паузу. Типичный пример: мы ждем ответа от пользователя (то есть используем Event Activity). В этом случае происходит обыкновенная сериализация (xml сериализация для Workflow 4.0+, бинарная для более старых версий). Я думаю, читатели сразу поняли, что здесь очень легко сохранить лишнее или же немного ошибиться при сохранении в релизе А, а загрузке в релизе Б. Типичный пример из Workflow 3.0 — Вы подписались на Event с помощью лямбы/анонимного метода. Ну и, если вы знаете, тем самым Вы создали новое поле класса, которое сохраняется в базу. И у вас упадет загрузка, так как упадет десериализация. Отсюда, большой совет: Весь рабочий код должен быть строго вынесен за пределы ваших Activity. Все поля должны сохраняться где-нибудь подальше от Workflow. В Activity храним самый минимум и самые простые типы. Пусть лучше пострадает внутренний дизайн, чем стабильность.
На самом деле, подстава здесь не закончилась. Самое классное начинается тогда, когда надо поменять набор полей. Например, в нашу RejectActivity из примера понадобиться добавить Reason. И вот тут код должен быть готов к тому, что старая RejectActivity не содержит этого поля. Для Workflow 4.0+ можно еще поменять сериализованное представление в базе, а вот для Workflow 3.0 такой способ не всегда подойдет (так как хранится сжатое бинарное представление), потому быстро всё это не обновить.
Засада с производительностью
На самом деле, у Microsoft Workflow целая серия недоработок. Причем, проблемы касаются как единичного выполнения (то есть ряд операций сделан не эффективно), так и распределения нагрузки. Однако, обо всем по порядку.
Когда следует сохраняться?
Представим, у нас идет бизнес процесс, в котором есть нулевые ожидания. Не важно, как они получились. Важно то, что они есть. Workflow трактует любое ожидание как отличный повод сохраниться, ну то есть сделать сериализацию, а потом загрузить опять нашу работу (правда, не совсем сразу, но не важно). Естественно, на время реакции это сказывается самым неблагоприятным образом. Отсюда совет: используйте Delay Activity как можно реже, а еще лучше — в связке с If Activity, которая проверит, что ждать, собственно, и не надо. Другой неприятный момент связан с тем, что если Вы сказали «ждать 5 суток», то простыми способами Вы не заставите Workflow всё-таки не ждать ничего, если наш instance уже в базе. Более того, если Workflow Runtime загрузит вашу работу в память, и увидит, что ждать следует еще кучу времени то она, как ни странно, просто оставит её в памяти. И будет ждать кучу времени. Отсюда, еще совет: из-за подобных проблем не используйте долгое ожидание. Лучше всего использовать много коротких или же просыпаться из-за внешнего Event'а, а уже Ваш внешний сервис разбудит процесс когда надо.
Распределенное выполнение
Если верить тем же статьям от Microsoft, Workflow прекрасно умеет распределять работу. Ну то есть Вы можете иметь несколько независимых серверов, каждый из которых будет брать немного заданий, выполнять их, брать следующие и так далее. В этом есть только один недостаток: это выдумка. Всё дело в том, что распределенная реализация Workflow — это крайне странное изделие. Оно работает по следующему алгоритму:
- Взять из базы ВСЕ не заблокированные рабочие процессы, которые сейчас могут выполниться И поставить им блокировку на пять минут
- Через две минуты: повторить пункт 1
Да, числа 2 и 5 можно поменять. Важно другое: самый первый везунчик заберет вообще всю работу из базы. Кстати, через две минуты он опять вычистит базу, даже если ему есть, чем заняться. Если он не уложится за пять минут для какого-нибудь рабочего процесса, то тут произойдет странная штука: он таки выполнит рабочий процесс (вызовет все WCF соединения и т.д.), попытается сохранить в базу данных, но у него ничего не выйдет (блокировки-то нету!). В итоге в памяти этого Workflow Runtime теперь уже навсегда останется этот ломаный объект. И он не выйдет из неё добровольно до тех пор, пока Вы физически не остановите процесс. Workflow Runtime не будет сам останавливаться, сделать он уже ничего не сможет. Великолепная реализация. Более красивый сценарий случится, если Вы настроите блокировку не на пять минут, а на более продолжительное время. В этом случае после остановки процесса эти записи будут заблокированы. Ну то есть Вам уже нельзя будет просто так останавливать процесс, что может очень негативно сказаться на Production платформе. Эта проблема решается крайне легко: для правильной распределенной работы Вам следует самостоятельно написать процедуры работы с базой (то есть, реализовать все процедуры для параллельной и распределенной работы, сделать свою реализацию WorkflowPersistenceService). Здесь есть, кстати, одна особенность: Вам не обязательно работать с MS Sql базой данных, можете поэкспериментировать с другими способами. На деле, задача решается с помощью простой файловой шары, работает быстро и правильно, однако это не модно.
Успешная работа под нагрузкой
На самом деле, её нет. Конечно, Microsoft утверждает, что все стало прекрасно, но они забыли про один маленький график: зависимость количества Activity в памяти от общего времени работы (а раньше оно было таким). На деле оно не поменялось:
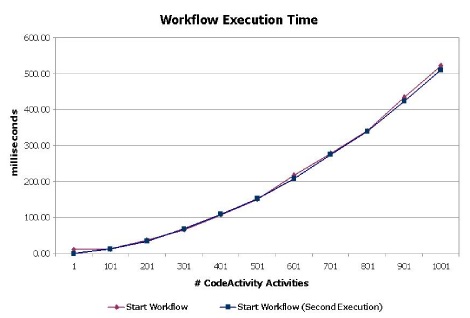
Это квадратичный график. Тут важны не абсолютные значения времени, а зависимость: насколько долго у Вас будет всё работать, если сложность бизнес-процесса будет расти. Более того, на деле именно такая зависимость времени Execute от общего количества Activity в памяти, и не важно — один это рабочий процесс или несколько. Например, если у Вас 10 параллельных рабочих процессов, то на обработку каждой маленькой Activity будет тратиться больше ресурсов, чем если бы был один рабочий процесс. Или по другому: 10 параллельных задач обрабатываются дольше, чем 10 последовательных задач. Причем, с нелинейной зависимостью.
В предыдущей части я написал, как работает Persistence Service: он забирает всё из базы. На деле такой фокус из 5000 параллельных сложных рабочих процессов губителен для системы: она начинает работать с крайне низкой скоростью: 1-10 Activity в минуту (!!!). И это при условии, что процессор будет загружен почти на 100%. Проблема ясна, но как её решать? Решение: сделать свой обработчик Activity, переиспользовать Activity, cделать эмуляцию Ваших рабочих процессов. По факту Вам придется быстренько реализовать базовый компонент Workflow, который занимается стартом и остановкой Activity. Это потребуется, чтобы во-первых не допускать большое количество запущенных Activity на рабочий процесс (ибо всё тормозит), а во-вторых чтобы ускорить время сериализации/десериализации (побыстрее выгонять лишних из памяти). Microsoft Workflow никогда не удаляет отработанную Activity. Вам же придется всё реализовать так, чтобы завершенные Activity не находились в памяти.
Резюме
Я постарался описать часть проблем, которые Вас поджидают при работе с Microsoft Workflow. На деле здесь есть большое количество нюансов, но они более-менее решаемы, и я уверен, что Вы справитесь. По факту, если у Вас на работе встанет задача сделать свой настраиваемый бизнес процесс, то лучше все-таки начните использовать Microsoft Workflow. Для прототипа сойдет. Более того, при слабой нагрузке вся эта система может работать. Основные подставы известны — они выше, они вполне решаемы. К тому же, намного лучше работать с системой, от которой известно, что ожидать, чем с той, о которой есть только маркетинговая информация. Ну а если нагрузка начнет расти, Вы сможете модуль за модулем перенести на свою эффективную реализацию.
