Содержание:
1. Поиск и анализ цветового пространства оптимального для построения выделяющихся объектов на заданном классе изображений
2. Определение доминирующих признаков классификации и разработка математической модели изображений мимики"
3. Синтез оптимального алгоритма распознавания мимики
4. Реализация и апробация алгоритма распознавания мимики
5. Создание тестовой базы данных изображений губ пользователей в различных состояниях для увеличения точности работы системы
6. Поиск оптимальной аудио-системы распознавания речи на базе открытого исходного кода
7. Поиск оптимальной системы аудио распознавания речи с закрытым исходным кодом, но имеющими открытые API, для возможности интеграции
8. Эксперимент интеграции видео расширения в систему аудио-распознавания речи с протоколом испытаний
Цели
Определить наиболее оптимальный алгоритм для последующей его реализации и апробации в решении распознавания мимики.
Задачи
Провести анализ существующих алгоритмов видео распознавания человеческого лица и его характеристик, учитывая определенные нами доминирующие признаки классификации и математической модели. На основе полученных данных выбрать оптимальный вариант алгоритма визуального распознавания для последующего его внедрения под наши задачи реализации технологии распознавания мимики для мобильных устройств или компьютеров.
Тема
Так как перед нами стоит задача реализовать производительную систему распознавания мимики для мобильных устройств, то при выборе оптимального алгоритма под решение данной проблемы мы должны исходить из следующего:
• Низкое разрешение и высокий уровень шумов (характерно для большинства фронтальных VGA камер смартфонов и ПК);
• Невысокие производительные требования мобильных устройств и компьютеров для обсчитывания данных с частотой 25 кадров в секунду;
• Высокая скорость работы (для обработки видео в режиме онлайн).
На основе вышеперечисленных условий при выборе оптимального алгоритма под задачи распознавания мимики нам необходимо сфокусироваться на надежном алгоритме, который имеет минимальные системные требования и отличается высокой эффективностью работы. Также при осуществлении синтеза оптимального алгоритма распознавания мимики для решения поставленной задачи мы должны учитывать наш накопленный опыт, который мы приобрели в предыдущих этапах исследования.
Представим схему работы обработки и последующего анализа изображения в виде таблицы (рис.1). При этом на данном этапе исследования нам следует определить столбец, который мы для простоты перекрасили в синий цвет – то есть выбрать оптимальный алгоритм распознавания матрицы:
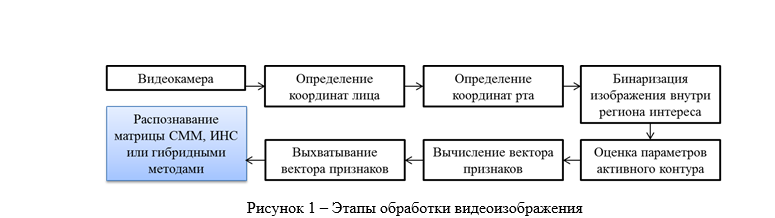
Но прежде чем приступить к выбору оптимального алгоритма под наши задачи распознавания мимики, следует объяснить механизм выхватывания вектора признаков.
Выхватывание вектора признаков
После того, как на предыдущих этапах была произведена бинаризация изображения и осуществлено выделение контура губ, происходит так называемая процедура наложения n точек, пронумерованных от p1 до pn по часовой стрелке. Используемые координаты точек нормализуются: средняя точка эллипса считается началом координат, ось x направлена по направлению большего радиуса эллипса, большой радиус эллипса считается единицей. Кроме координат точек, в процессе выделения контуров губ находятся параметры эллипса, описывающего область губ на исходном изображении. Параметры эллипса позволяют сделать выводы о таких общих параметрах области рта, как открыт рот или закрыт. Нумерация контура начинается с места пересечения контура губ левым большим радиусом эллипса.
Затем выполняем поиск углов (рис. 2). Среди полученных точек необходимо определить правый и левый угол. Несмотря на нумерацию точек, это не всегда точки p1 и pn/2. Правым углом считается точка, находящаяся в правой половине контура (между pn/4 и p3n/4), у которой угол α является наименьшим. Угол α — это угол между средними qnext и qprev. Здесь qnext= (pi+1+…+ pi+k)/k, qprev=(pi-1+…+ pi-k)/k, k=n/5. Аналогичное правило используется для левого угла [1].
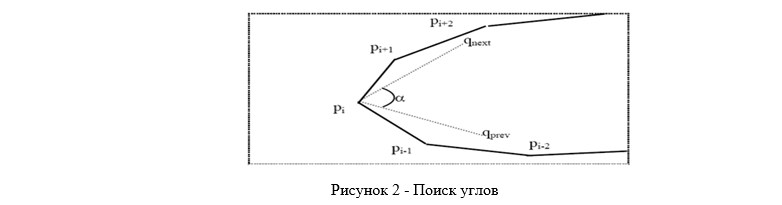
Следующим шагом после нахождения углов является преобразование набора исходных данных в набор векторов признаков. В качестве нескольких первых элементов в векторе признаков используются признаки, полученные отдельно от координат — отношение высоты эллипса области губ к его ширине. Дальнейшие элементы вектора признаков — это координаты левого и правого угла контура, координаты верхней и нижней точек контура, координаты остальных точек контура. Рассмотрим варианты анализа полученных данных методом главных компонент. Выделение базиса методом главных компонент позволяет найти основные направления, по которым изменяются вектора признаков. Это дает возможность значительно понизить размерность векторов признаков. Метод главных компонент применяется к набору векторов признаков, полученных из набора данных, отражающих большинство возможных состояний губ.
Теперь рассмотрим наиболее распространенные алгоритмы распознавания человеческого лица и его характеристик:
Алгоритмы основанные на методе скрытых Марковских моделей (Hidden Markov Models)
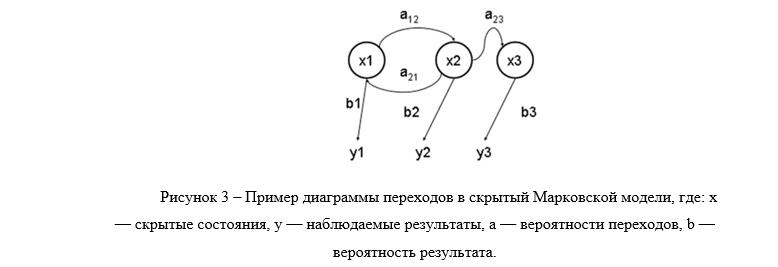
Скрытая Марковская модель (СММ) — статистическая модель, имитирующая работу процесса, похожего на Марковский процесс с неизвестными параметрами, и задачей ставится разгадывание неизвестных параметров на основе наблюдаемых.
Каждому вектору признаков необходимо поставить в соответствие символ скрытой Марковской модели (рис. 3). Для этого используем метод векторной квантизации. С помощью этого метода пространство векторов признаков разбивается на кластеры, по принципу близости к центрам кластеров — кодовым словам. Набор кодовых слов называется кодовой книгой. Основная сложность метода состоит в построении кодовой книги векторов. Размер кодовой книги определяется количеством состояний губ в исходных данных. Кодовая книга известного размера k строится алгоритмом K средних [2].
На первом шаге алгоритма случайным образом выбираются k векторов, считающихся кодовыми словами (центрами кластеров). На следующем шаге каждый входной вектор приписывается к тому кластеру, чье кодовое слово находится на наименьшем расстоянии от него. На третьем шаге кодовые слова каждого кластера пересчитываются. Каждое кодовое слово делается равным среднему арифметическому среди всех векторов кластера. Второй и третий шаги повторяются до тех пор, пока изменения кодовых слов не станут достаточно малы.
Этот алгоритм медленный, но применение анализа главных компонент перед квантованием позволяет понизить размерность и, тем самым, значительно ускорить процесс построения кодовой книги [3]. Новые исходные данные перед использованием в процессе распознавания квантуются: каждому вектору ставится в соответствие ближайший вектор из кодовой книги, и в дальнейшем вместо вектора в качестве символа скрытой Марковской модели используется его индекс в кодовой книге.
Распознавание по изображению не может работать на уровне визем, так как виземы для различных фонем достаточно близки. При этом распознавание на основе последовательностей визем — дифонов, трифонов — гораздо более надежно [4]. Для распознавания используется система эргодических скрытых Марковских моделей [5]. Каждому дифону соответствует своя СММ. СММ инициализируются равными вероятностями для символов и переходов между состояниями. Однако такая модель из-за высокой степени свободы плохо настраивается на обучающие данные, что негативно сказывается на качестве распознавания [6].
Обучение системы СММ производится с помощью последовательности квантованных векторов признаков. Исходные данные вручную разбиваются по обучаемым дифонам, после чего соответствующая СММ обновляется по алгоритму Баума-Велша [7]. Результирующая СММ выдает максимальные значения вероятности на последовательностях, близких к набору для обучения своего дифона.
В результате работы строится эффективный алгоритм построения векторов признаков губ для задачи распознавания речи. Алгоритм позволяет преобразовать данные контуров губ в наборы признаков, пригодных для распознавания. Алгоритм обладает свойствами надежности и устойчивости и легко интегрируется с системой распознавания речи на основе скрытых Марковских моделей. Однако, следует отметить и слабые стороны данного алгоритма, в частности он отличается слабой различающей способностью и плохо обучаем.
Алгоритмы основанные на методе Нейронных сетей (Artificial neural networks)
Нейросетевые методы — это методы, базирующиеся на применении различных типов нейронных сетей (НС). НС состоит из элементов, называемых формальными нейронами, которые сами по себе очень просты и связаны с другими нейронами. Каждый нейрон преобразует набор сигналов, поступающих к нему на вход в выходной сигнал. Именно связи между нейронами, кодируемые весами, играют ключевую роль. Одно из преимуществ НС (а так же недостаток при реализации их на последовательной архитектуре) это то, что все элементы могут функционировать параллельно (рис. М.4), тем самым существенно повышая эффективность решения задачи, особенно в обработке изображений. Кроме того, что НС позволяют эффективно решать многие задачи, они предоставляют мощные гибкие и универсальные механизмы обучения, что является их главным преимуществом перед другими методами. Также среди других достоинств нейросети следует признать возможность получения классификатора, хорошо моделирующего сложную функцию распределения изображений лиц. Недостатком же является необходимость в тщательной и кропотливой настройке нейросети для получения удовлетворительного результата классификации [8].
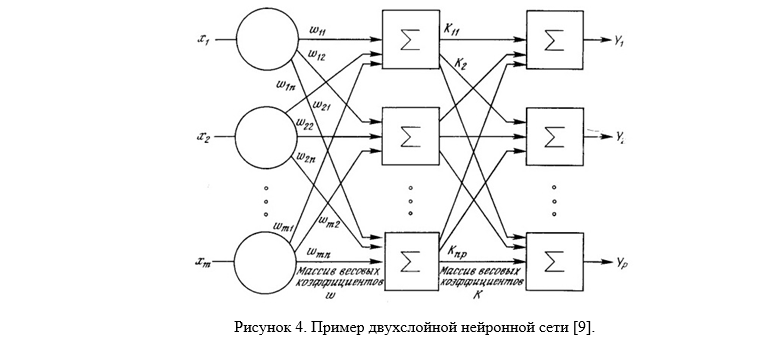
Алгоритмы основанные на комбинированных методах
Учитывая преимущества и недостатки алгоритмов основанных на скрытых Марковских моделей и нейронных сетях, в последнее время в научном мире распознавания на заданном классе изображений приобрели популярность гибридные алгоритмы. Согласно исследовательским данным гибридные ИНС/СММ распознаватели повышают точность традиционных СММ за счет моделирования корреляций между одновременными параметрами сигнала и между текущими и следующими параметрами [10]. То есть СММ обеспечивает возможность моделирования долговременных зависимостей, а ИНС обеспечивает непараметрическую универсальную аппроксимацию, оценку вероятности, алгоритмы дискриминантного обучения, уменьшение числа параметров для оценки, которые обычно требуются для стандартных СММ [11]. Однако, при выборе комбинированного алгоритма необходимо иметь в виду, что слишком большая и сложная архитектура работы гибридных алгоритмов увеличивает время обработки данных процессором системы.
Заключение
Для определения оптимального алгоритма для задачи распознавания мимики, нами был сначала подробно рассмотрен самый простой и надежный механизм выхватывания вектора признаков для последующего его анализа матричными алгоритмами. На следующем этапе мы рассмотрели и проанализировали достоинства и недостатки самых известных моделей построения алгоритма: скрытые Марковские модели, искусственные нейронные сети, гибридные алгоритмы. Изучив существующие подходы и решения в области обработки вектора признаков, мы остановились на комбинированных методах обработки данных, которые по нашему мнению являются наиболее эффективными для нашего решения: реализации надежной и быстрой системы распознавания мимики для мобильных устройств и компьютеров.
Список использованных источников
1. Soldatov S. Lip reading: preparing feature vectors. Graphics & Media Laboratory MSU, 2003
2. A. Linde, R. Grey. An algorithm for vector quantization design.// IEEE Transactions on Communicatinos COM-28, 1980
3. Soldatov S. Lip reading: preparing feature vectors. Graphics & Media Laboratory MSU, 2003
4. Там же.
5. Гультяева Т.А., Попов А.А. Модификации одномерных скрытых марковских моделей для задачи распознавания лиц// 16-Международная конференция по компьютерной графике и компьютерному зрению – GRAPHICON, 2006
6. K. Sobottka and I. Pitas, A novel method for automatic face segmentation, facial feature extraction and tracking, Signal processing: Image communication, Vol. 12, №3, pp. 263-281, June, 1998
7. Гультяева Т.А., Попов А.А. Модификации одномерных скрытых марковских моделей для задачи распознавания лиц// 16-Международная конференция по компьютерной графике и компьютерному зрению – GRAPHICON, 2006
8. Макаренко А.А. Классификация образов сверхточной нейронной сетью. Научн. сессия – ТУСУР-2006. Матер. Всерос. научн.-тех. конф. студентов, аспирантов и молодых спец-тов. Ч.1. Томск, 2005.
9. Ф. Уоссермен. Нейрокомпьютерная техника: теория и практика (Пер. на рус. яз. Зуев Ю.А., Точенов В.А.), 1992.
10. Осетров В.П. Аудиовизуальный распознаватель речи.// Кадровое обеспечение развития инновационной деятельности в России. Ершово, М., 2010.
11. Маковкин К.А. Гибридные модели: скрытые марковские модели и нейронные сети, их применение в системах распознавания речи.// Модели, методы, алгоритмы и архитектуры систем распознавания речи. Вычислит. центр им. А.А. Дородницына, М., 2006.
Продолжение следует.
