Много информации в сети по Zabbix, много и шаблонов самописных, хочу представить на суд аудитории свои модификации.
Zabbix — очень удобный и гибкий инструмент мониторинга. Хочешь — сотню мониторь, хочешь — тысячу станций, а не хочешь — следи за одним сервером, снимай сливки во всех разрезах. Буду не против отдать на github, если кто коллекционирует схожие.
Так случилось, что решили мы выложить на хостинг базу данных с оберткой из php-fpm+nginx. В качестве БД — postgres. Мысли собирать данные о работе машины были еще до покупки хостинга — это нужно, это полезно! Волшебным пенделем к внедрению системы послужили тормоза жесткого диска на нашей VDS станции — в начале скриптом каждую минуту кладем время и замерянную скорость в файл, а потом в экселе строим графики, сравниваем как было/стало, снимаем количественную статистику. И это всего один параметр! А вдруг виноват не VDS, а наши приложения, которые на нем работают. Вобщем, мониторить надо много, мониторить надо удобно!
Не буду останавливаться на том, как установить сервер, много вариантов и документации по этому поводу полно. Я пользовался официальной:
https://www.zabbix.com/documentation/ru/2.2/manual/installation/install_from_packages
В качестве операционной системы — CentOS 6.5
Файлы, которые вам понадобятся — в архиве habr-zabbix-mons.zip
На станцию агента помимо самого zabbix-agent обязательно ставим zabbix-sender:
Вместо «Ваш_агент_addr» поставить имя/ip машины, как добавили агента на сервере, поле «Host name».
Я пользуюсь программой hdparm. Вы можете использовать другую, если имеете предпочтения:
Выбираем раздел, который будем мониторить:
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
Разрешаем запуск sudo без консоли (отключаем requiretty) и добавляем команду, которую мы запускаем от имени пользователя zabbix:
Увеличиваем время на запрос параметра в конфиге агента, т.к. hdparm затрачивает 3-10 и более секунд на замер, в зависимости от скачков по скорости, видимо.
Также и на сервере надо исправить время ожидания ответа агента
Заходим в Веб-Админку Zabbix и добавляем в конфигурации хосту (Configuration->Hosts->Ваш_сервер_агент->Items) или к какому-нибудь шаблону, например OS Linux (Configuration->Templates->Template OS Linux->Items) новый параметр — жмем “Create Item”:
Готово! У нас есть параметр, и есть граф по нему. Если вы добавляли в шаблон, прикрепите шаблон к хосту. Любуемся!
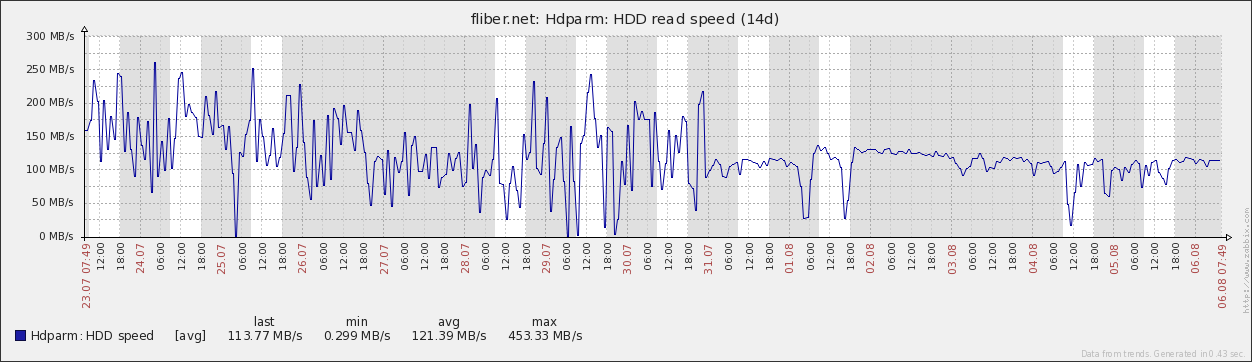
В нашем случае то, что было до 31.07 — это плохо, хоть и средняя скорость была высокой, но очень часто она спускалась ниже 1МБ/с. Сейчас (после перевода нас на очередную другую ноду) она стабильная и редко опускается, пока был минимум 5-6МБ/с. Думаю, что на прежней ноде она падала совсем не из-за диска, а из-за занятости каких-то других более важных ресурсов, но главное, что мы видим провалы!
Хороший параметр, но не снимайте его слишком часто, ведь в эти 3-10 секунд замера диск будет очень занят, рекомендую раз в 10-60 минут, или вообще отключить, если статистика вам понравилась и не будете мучить хостера.
Казалось бы, зачем мониторить логи? Подключил метрику, да аналитику, и наблюдай все там. Но эти ребята не покажут нам ботов, которые не запускают js на странице, также как и человеков, если у них отключен js. Предлагаемое решение покажет частоту обхода роботами ваших страниц, и поможет предупредить высокую нагрузку на ваш сервер от поисковых ботов. Ну и любую статистику, если поковыряете loghttp.sh
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
Кладем loghttp.sh в /etc/zabbix/scripts, в той же папке выполняем
Проверьте путь к access.log
Импортируем loghttp.xml в шаблоны zabbix: Configuration -> Templates, в строке заголовка “CONFIGURATION OF TEMPLATES” ищем справа кнопку “Import”, выбираем файл, импортируем.
Подключаем шаблон к хосту: Configuration->Hosts->Ваш_сервер_агент, вкладка “Templates”, в поле “Link new templates” начинаем писать “Logs”, появится выпадающий список — выбираем наш шаблон. “Add”, “Save”.
В шаблоне сказано мониторить лог раз в 10 минут, поэтому не торопитесь смотреть графики, а вот логи проверить можно. На стороне клиента “/var/log/zabbix/zabbix_agentd.log” и на стороне сервера “/tmp/zabbix_server.log” или “/var/log/zabbix/zabbix_server.log”.
Если все хорошо, то вскоре вы сможете наблюдать подобную картинку:

Google молодец — сканит с одной скоростью, Иногда приходит Mail, редко Bing, а Yahoo и не видать. Yandex с переменным успехом индексирует, но много — еще бы в выдаче показал, было бы замечательно :)
На графике Гугл и Яндекс на левой шкале, остальные — на правой. Значение на шкале — количество посещений от замера до замера, тоесть за 10 минут. Можно поставить 1 час, но тогда рискуем пропустить много посещений в момент ротации лога.
Зачем мониторить nginx — пока не знаю, ни разу проблем с ним не было. Но пусть будет, для статистики. Пробовал использовать набор шаблонов ZTC, но очень уж не нравятся мне мигающие процессы питона в памяти, по 10МБ каждый. Хочу нативно, хочу bash! И главное — за один запрос собрать все параметры. Именно этого я хотел добиться, когда мониторил все службы — минимум нагрузки на сервер и максимум параметров.
Подобных скриптов можно найти много, но раз уж я подошел комплексно к мониторингу Веб-сервера, выкладываю свою версию.
Научим nginx отдавать статусную страницу, добавим конфигурацию для localhost
Не забудьте применить изменения:
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
Кладем nginx.sh в /etc/zabbix/scripts, в той же папке выполняем
Если не ставили curl на предыдущем шаге, надо установить:
Проверьте, на всякий случай, что в nginx.sh в переменных SENDER и CURL верные пути.
Импортируем loghttp.xml в шаблоны zabbix, подключаем шаблон к хосту.
Ну и, наслаждаемся картинками!
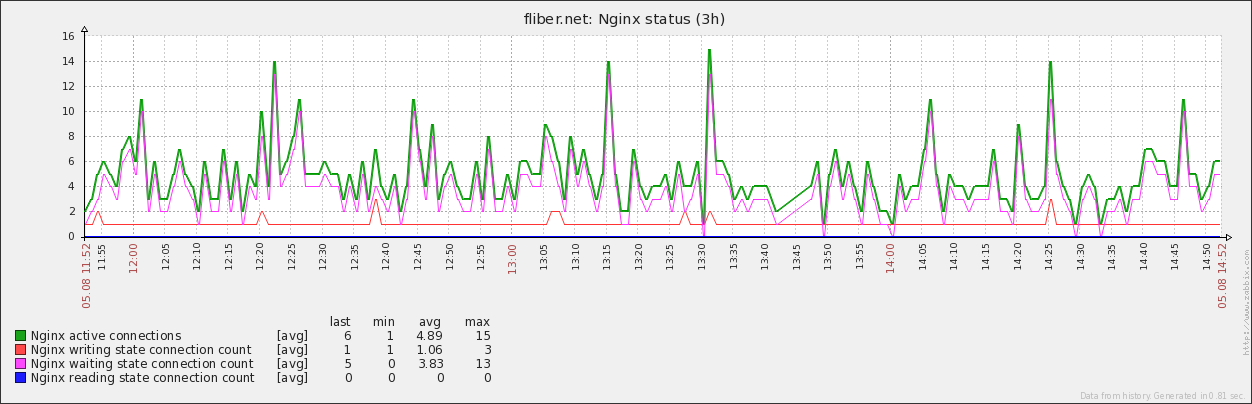
Данный монитор умеет информировать о том, что nginx не работает, либо что он начал отвечать слишком медленно. По-умолчанию порог такой: если за последние 10 замеров скорость реакции nginx не опускалась ниже 10мс, создаем Warning. Монитор сообщит, если сервер вернет некорректный статус(nginx в памяти, а отвечает белибердой).
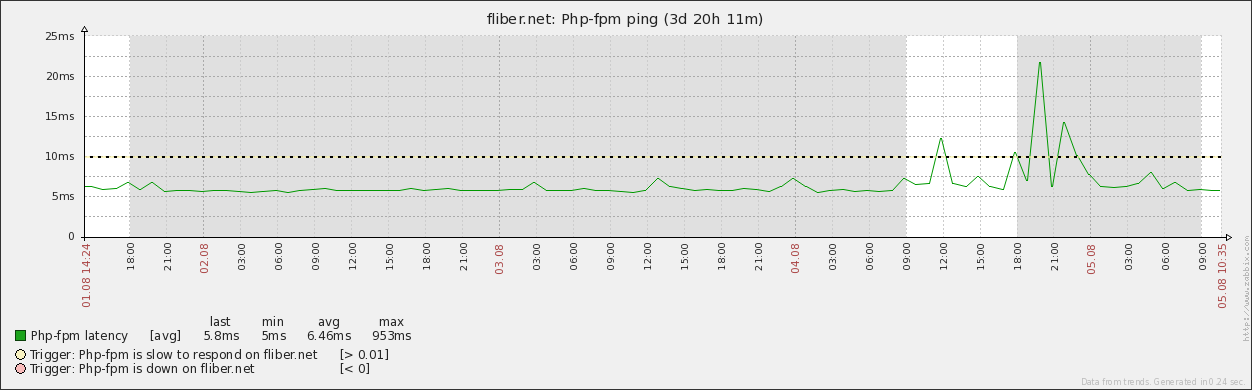
Полезно осуществлять, если у вас используется динамический набор процессов (pm = dynamic в /etc/php-fpm.d/www.conf) по умолчанию или осознанно. Монитор умеет предупреждать о недоступности службы, или ее замедлении.
Я пытался сделать опрос службы без nginx, но у меня не получилось найти такую установленную программу, которая бы помогла во взаимодействии с php-fpm. Подскажите варианты, если кто знает.
Возможно, php-fpm не отдает статус, проверим
Если что-то поменяли, применяем:
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
Кладем php-fpm.sh в /etc/zabbix/scripts, в той же папке выполняем
Пропишите в php-fpm.sh путь до FastCGI сервера (параметр listen в /etc/php-fpm.d/www.conf)
Если не установлен cgi-fcgi, надо установить:
Импортируем php-fpm.xml в шаблоны zabbix, подключаем шаблон к хосту.
Это основное блюдо! Его повар готовил дольше всех :)
В качестве прототипа был выбран pg_monz — open_source, поддерживается, много параметров, работает с последней версией postgres. Недостаток глобальный — я собираю все параметры по службе, т.к. не знаю, какой из них и когда “выпрыгнет”.
Когда разобрался с pg_monz и включил сбор всех параметров — по базам и таблицам, всего около 700 штук, нагрузка на сервер увеличилась в 10 раз! (скорее-всего с pgbouncer будет не так заметно) Хотя параметры собирались раз в 300 секунд. Оно и понятно — для каждого параметра запускается psql и выполняет запрос, часто к одним и тем же таблицам, просто к разным полям. В общем — от pg_monz остались только названия полей и таблиц. Ну, пробуем!
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
Кладем psql*.sh в /etc/zabbix/scripts, в той же папке выполняем
Проверьте, на всякий случай, что в nginx.sh и psql_db_stats.sh в переменной PSQLC верный путь до psql.
Импортируем psql.xml в шаблоны zabbix. Если не планируете собирать данные по базам и таблицам, то сразу отключите на вкладке “Discovery” шаблона “PSQL DB list” и “PSQL table list”. А если планируете, то для начала задайте макрос на вкладке “Macros” агента {$PGTBL_REGEXP} — имя таблицы, которую будете мониторить подробно. Хотя, скорее всего, в начале вы захотите посмотреть все таблицы :)
Подключаем шаблон к хосту, смотрим как собираются данные…
Все параметры шаблона (унаследованы от pg_monz) и значения их по умолчанию можно посмотреть на вкладке “Macros” шаблона. Попробую сделать описание этих параметров:
* в качестве параметра используется регулярное выражение, например
org — все таблицы и схемы, в которых содержится подстрока org
\.(organization|resource|okved)$ — таблицы с именами organization, resource, okved в любой схеме
^msn\. — все таблицы в схеме msn
Получается, что параметры {$PGDB_REGEXP} и {$PGTBL_REGEXP} — это не просто названия, это подстрока, которая будет искаться в названиях всех баз данных и схем.таблиц.
Только вот регулярки будут работать не все, а только те, в которых не содержатся символы \, ', ", `, *, ?, [, ], {, }, ~, $, !, &, ;, (, ), <, >, |, #, @, 0x0a. Если вы хотите снять это ограничение, отредактируйте /etc/zabbix/zabbix_agentd.conf
www.postgresql.org/docs/9.3/static/functions-matching.html#FUNCTIONS-POSIX-REGEXP
Если у вас не появляется параметр “PSQL error log”, то скорее всего не верно задан путь {$PGLOGDIR} — поищите на агенте файлик “postgresql-Sun.log” — где он лежит, эту папку и записывайте в макрос.
Как принято в лучших домах — десерт!
В данной статье просматривается вся цепочка — от запроса пользователя до данных, кроме одного узла — самого php. Чтобы чуть чуть приоткрыть этот ящик, попробуем собрать статистику встроенного в php5 ускорителя opcache функцией opcache_get_status.
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
Кладем php-opc.* в /etc/zabbix/scripts, в той же папке выполняем
Пропишите в php-opc.sh путь до FastCGI сервера (параметр listen в /etc/php-fpm.d/www.conf)
Если не ставили fcgi для мониторинга php-fpm, надо установить:
Импортируем php-opc.xml в шаблоны zabbix, подключаем шаблон к хосту.
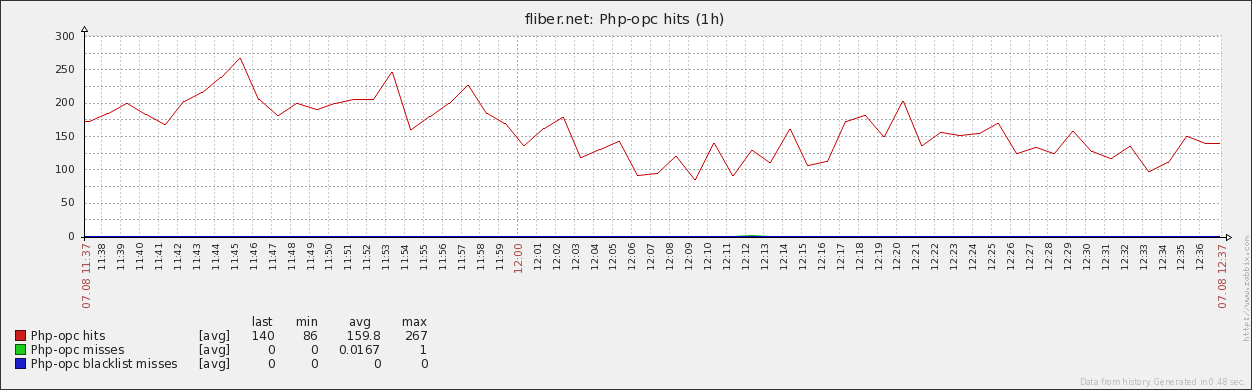
Пока создавал триггеры, уменьшил размеры памяти на кэш для своего opcache в 2 раза. Так-что полезно видеть и эту статистику. Если бы проект на этом сервере не пополнялся новыми модулями, то уменьшил бы в 4 раза легко.
Пока не знаю, какие еще параметры можно промониторить. Это основные сервисы, которые работают на нашей VDS-машине. Как наберется — поделюсь, конечно. Было бы неплохо добавить шаблон-скррипт mysql, но задачи пока нет. Если очень надо — сделаю :)
Подход можно обсуждать — у меня же получились отдельные примочки для каждой службы, и это тоже неплохо — взял скрипт, дополнил конфиг, залил шаблон — готово.
Если собирать эти мониторы в один пакет, то, конечно, надо делать дополнительно discovery на каждую службу — может быть несколько nginx, php-fpm, postgres. Они могут слушать как порты, так и сокеты.
ZabbixServer 2.2.4
ZabbixAgent 2.2.4
hdparm 9.43
nginx 1.6.1
php-fpm 5.3.3
PostgreSQL 9.3.4
php-opcache 5.5.15
Шаблоны и скрипты тут: http://www.uralati.ru/frontend/for_articles/2014-08-habr-zabbix-mons.zip
Для мониторинга php-fpm и pfp-opcache в архиве имеется версия скриптов для работы с curl(с теми же шаблонами). Описание настроек закомментировано в соответствующих скриптах php-*_curl.sh, см.upd2
Zabbix — очень удобный и гибкий инструмент мониторинга. Хочешь — сотню мониторь, хочешь — тысячу станций, а не хочешь — следи за одним сервером, снимай сливки во всех разрезах. Буду не против отдать на github, если кто коллекционирует схожие.
Так случилось, что решили мы выложить на хостинг базу данных с оберткой из php-fpm+nginx. В качестве БД — postgres. Мысли собирать данные о работе машины были еще до покупки хостинга — это нужно, это полезно! Волшебным пенделем к внедрению системы послужили тормоза жесткого диска на нашей VDS станции — в начале скриптом каждую минуту кладем время и замерянную скорость в файл, а потом в экселе строим графики, сравниваем как было/стало, снимаем количественную статистику. И это всего один параметр! А вдруг виноват не VDS, а наши приложения, которые на нем работают. Вобщем, мониторить надо много, мониторить надо удобно!
Не буду останавливаться на том, как установить сервер, много вариантов и документации по этому поводу полно. Я пользовался официальной:
https://www.zabbix.com/documentation/ru/2.2/manual/installation/install_from_packages
В качестве операционной системы — CentOS 6.5
Файлы, которые вам понадобятся — в архиве habr-zabbix-mons.zip
На станцию агента помимо самого zabbix-agent обязательно ставим zabbix-sender:
yum install -y http://repo.zabbix.com/zabbix/2.2/rhel/6/x86_64/zabbix-2.2.4-1.el6.x86_64.rpm yum install -y http://repo.zabbix.com/zabbix/2.2/rhel/6/x86_64/zabbix-agent-2.2.4-1.el6.x86_64.rpm yum install -y http://repo.zabbix.com/zabbix/2.2/rhel/6/x86_64/zabbix-sender-2.2.4-1.el6.x86_64.rpm
[root@fliber ~]# vi /etc/zabbix/zabbix_agentd.conf
LogFileSize=1
Hostname=Ваш_агент_addr
Server=123.45.67.89
ServerActive=123.45.67.89
Вместо «Ваш_агент_addr» поставить имя/ip машины, как добавили агента на сервере, поле «Host name».
chkconfig zabbix-agent --level 345 on service zabbix-agent start
Мониторим скорость жесткого диска
Я пользуюсь программой hdparm. Вы можете использовать другую, если имеете предпочтения:
yum install hdparm
Выбираем раздел, который будем мониторить:
[root@fliber ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/vda1 219608668 114505872 104106808 78% /
tmpfs 11489640 0 11489640 0% /dev/shm
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
UserParameter=hdparm.rspeed,sudo /sbin/hdparm -t /dev/vda1 | awk 'BEGIN{s=0} /MB\/sec/ {s=$11} /kB\/sec/ {s=$11/1024} END{print s}'
Разрешаем запуск sudo без консоли (отключаем requiretty) и добавляем команду, которую мы запускаем от имени пользователя zabbix:
[root@fliber ~]# visudo
#Defaults requiretty
zabbix ALL=(ALL) NOPASSWD: /sbin/hdparm -t /dev/vda1
Увеличиваем время на запрос параметра в конфиге агента, т.к. hdparm затрачивает 3-10 и более секунд на замер, в зависимости от скачков по скорости, видимо.
[root@fliber ~]# vi /etc/zabbix/zabbix_agentd.conf
Timeout=30
service zabbix-agent restart
Также и на сервере надо исправить время ожидания ответа агента
[root@pentagon ~]# vi /usr/local/etc/zabbix_server.conf
Timeout=30
Заходим в Веб-Админку Zabbix и добавляем в конфигурации хосту (Configuration->Hosts->Ваш_сервер_агент->Items) или к какому-нибудь шаблону, например OS Linux (Configuration->Templates->Template OS Linux->Items) новый параметр — жмем “Create Item”:
Name: Hdparm: HDD speed
Key: hdparm.rspeed
Type of information: Numeric (float)
Units: MB/s
Update interval (in sec): 601
Applications: Filesystems
Name: Hdparm: HDD read speed
Y axis MIN value: Fixed 0.0000
Items: Add: “Hdparm: HDD speed”
Готово! У нас есть параметр, и есть граф по нему. Если вы добавляли в шаблон, прикрепите шаблон к хосту. Любуемся!

В нашем случае то, что было до 31.07 — это плохо, хоть и средняя скорость была высокой, но очень часто она спускалась ниже 1МБ/с. Сейчас (после перевода нас на очередную другую ноду) она стабильная и редко опускается, пока был минимум 5-6МБ/с. Думаю, что на прежней ноде она падала совсем не из-за диска, а из-за занятости каких-то других более важных ресурсов, но главное, что мы видим провалы!
Хороший параметр, но не снимайте его слишком часто, ведь в эти 3-10 секунд замера диск будет очень занят, рекомендую раз в 10-60 минут, или вообще отключить, если статистика вам понравилась и не будете мучить хостера.
Мониторим логи nginx
Казалось бы, зачем мониторить логи? Подключил метрику, да аналитику, и наблюдай все там. Но эти ребята не покажут нам ботов, которые не запускают js на странице, также как и человеков, если у них отключен js. Предлагаемое решение покажет частоту обхода роботами ваших страниц, и поможет предупредить высокую нагрузку на ваш сервер от поисковых ботов. Ну и любую статистику, если поковыряете loghttp.sh
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
UserParameter=log.http.all,/etc/zabbix/scripts/loghttp.sh
Кладем loghttp.sh в /etc/zabbix/scripts, в той же папке выполняем
chmod o+x loghttp.sh yum install curl chown zabbix:zabbix /etc/zabbix/scripts service zabbix-agent restart
Проверьте путь к access.log
[root@fliber ~]# vi loghttp.sh
LOG=Путь_к_логу_nginx
Импортируем loghttp.xml в шаблоны zabbix: Configuration -> Templates, в строке заголовка “CONFIGURATION OF TEMPLATES” ищем справа кнопку “Import”, выбираем файл, импортируем.
Подключаем шаблон к хосту: Configuration->Hosts->Ваш_сервер_агент, вкладка “Templates”, в поле “Link new templates” начинаем писать “Logs”, появится выпадающий список — выбираем наш шаблон. “Add”, “Save”.
В шаблоне сказано мониторить лог раз в 10 минут, поэтому не торопитесь смотреть графики, а вот логи проверить можно. На стороне клиента “/var/log/zabbix/zabbix_agentd.log” и на стороне сервера “/tmp/zabbix_server.log” или “/var/log/zabbix/zabbix_server.log”.
Если все хорошо, то вскоре вы сможете наблюдать подобную картинку:

Google молодец — сканит с одной скоростью, Иногда приходит Mail, редко Bing, а Yahoo и не видать. Yandex с переменным успехом индексирует, но много — еще бы в выдаче показал, было бы замечательно :)
На графике Гугл и Яндекс на левой шкале, остальные — на правой. Значение на шкале — количество посещений от замера до замера, тоесть за 10 минут. Можно поставить 1 час, но тогда рискуем пропустить много посещений в момент ротации лога.
Мониторим nginx
Зачем мониторить nginx — пока не знаю, ни разу проблем с ним не было. Но пусть будет, для статистики. Пробовал использовать набор шаблонов ZTC, но очень уж не нравятся мне мигающие процессы питона в памяти, по 10МБ каждый. Хочу нативно, хочу bash! И главное — за один запрос собрать все параметры. Именно этого я хотел добиться, когда мониторил все службы — минимум нагрузки на сервер и максимум параметров.
Подобных скриптов можно найти много, но раз уж я подошел комплексно к мониторингу Веб-сервера, выкладываю свою версию.
Научим nginx отдавать статусную страницу, добавим конфигурацию для localhost
server {
listen localhost;
server_name status.localhost;
keepalive_timeout 0;
allow 127.0.0.1;
deny all;
location /server-status {
stub_status on;
}
access_log off;
}
Не забудьте применить изменения:
service nginx reload
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
UserParameter=nginx.ping,/etc/zabbix/scripts/nginx.sh
Кладем nginx.sh в /etc/zabbix/scripts, в той же папке выполняем
chmod o+x nginx.sh service zabbix-agent restart
Если не ставили curl на предыдущем шаге, надо установить:
yum install curl
Проверьте, на всякий случай, что в nginx.sh в переменных SENDER и CURL верные пути.
Импортируем loghttp.xml в шаблоны zabbix, подключаем шаблон к хосту.
Ну и, наслаждаемся картинками!

Данный монитор умеет информировать о том, что nginx не работает, либо что он начал отвечать слишком медленно. По-умолчанию порог такой: если за последние 10 замеров скорость реакции nginx не опускалась ниже 10мс, создаем Warning. Монитор сообщит, если сервер вернет некорректный статус(nginx в памяти, а отвечает белибердой).
Мониторим php-fpm
Полезно осуществлять, если у вас используется динамический набор процессов (pm = dynamic в /etc/php-fpm.d/www.conf) по умолчанию или осознанно. Монитор умеет предупреждать о недоступности службы, или ее замедлении.
Я пытался сделать опрос службы без nginx, но у меня не получилось найти такую установленную программу, которая бы помогла во взаимодействии с php-fpm. Подскажите варианты, если кто знает.
Возможно, php-fpm не отдает статус, проверим
[root@fliber ~]# vi /etc/php-fpm.d/www.conf
pm.status_path = /status
Если что-то поменяли, применяем:
service php-fpm reload
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
UserParameter=php.fpm.ping,/etc/zabbix/scripts/php-fpm.sh
Кладем php-fpm.sh в /etc/zabbix/scripts, в той же папке выполняем
chmod o+x php-fpm.sh service zabbix-agent restart
Пропишите в php-fpm.sh путь до FastCGI сервера (параметр listen в /etc/php-fpm.d/www.conf)
[root@fliber ~]# vi /etc/zabbix/scripts/php-fpm.sh
LISTEN='127.0.0.1:9000'
Если не установлен cgi-fcgi, надо установить:
yum install fcgi
Импортируем php-fpm.xml в шаблоны zabbix, подключаем шаблон к хосту.

Мониторим PostgreSQL
Это основное блюдо! Его повар готовил дольше всех :)
В качестве прототипа был выбран pg_monz — open_source, поддерживается, много параметров, работает с последней версией postgres. Недостаток глобальный — я собираю все параметры по службе, т.к. не знаю, какой из них и когда “выпрыгнет”.
Когда разобрался с pg_monz и включил сбор всех параметров — по базам и таблицам, всего около 700 штук, нагрузка на сервер увеличилась в 10 раз! (скорее-всего с pgbouncer будет не так заметно) Хотя параметры собирались раз в 300 секунд. Оно и понятно — для каждого параметра запускается psql и выполняет запрос, часто к одним и тем же таблицам, просто к разным полям. В общем — от pg_monz остались только названия полей и таблиц. Ну, пробуем!
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
UserParameter=psql.ping[*],/etc/zabbix/scripts/psql.sh $1 $2 $3 $4 $5
UserParameter=psql.db.ping[*],/etc/zabbix/scripts/psql_db_stats.sh $1 $2 $3 $4 "$5"
UserParameter=psql.db.discovery[*],psql -h $1 -p $2 -U $3 -d $4 -t -c "select '{\"data\":['||string_agg('{\"{#DBNAME}\":\"'||datname||'\"}',',')||' ]}' from pg_database where not datistemplate and datname~'$5'"
UserParameter=psql.t.discovery[*],/etc/zabbix/scripts/psql_table_list.sh $1 $2 $3 $4 "$5" "$6"
Кладем psql*.sh в /etc/zabbix/scripts, в той же папке выполняем
chmod o+x psql*.sh service zabbix-agent restart
Проверьте, на всякий случай, что в nginx.sh и psql_db_stats.sh в переменной PSQLC верный путь до psql.
Импортируем psql.xml в шаблоны zabbix. Если не планируете собирать данные по базам и таблицам, то сразу отключите на вкладке “Discovery” шаблона “PSQL DB list” и “PSQL table list”. А если планируете, то для начала задайте макрос на вкладке “Macros” агента {$PGTBL_REGEXP} — имя таблицы, которую будете мониторить подробно. Хотя, скорее всего, в начале вы захотите посмотреть все таблицы :)
Подключаем шаблон к хосту, смотрим как собираются данные…

Все параметры шаблона (унаследованы от pg_monz) и значения их по умолчанию можно посмотреть на вкладке “Macros” шаблона. Попробую сделать описание этих параметров:
| Macro | По умолчанию | Описание |
|---|---|---|
| {$PGDATABASE} | postgres | Имя базы данных для подключения |
| {$PGHOST} | 127.0.0.1 | Хост PostgreSQL (относительно Zabbix агента, если там же: 127.0.0.1) |
| {$PGLOGDIR} | /var/lib/pgsql/9.3/data/pg_log | Каталог с логами PostgreSQL |
| {$PGPORT} | 5432 | Номер порта PostgreSQL |
| {$PGROLE} | postgres | Имя пользователя для подключения к PostgreSQL |
| {$PGDB_REGEXP} | . (все базы) |
Название базы для сбора подробных сведений* |
| {$PGTBL_REGEXP} | . (все таблицы) |
Название таблицы для сбора подробных сведений* |
| {$PGCHECKPOINTS_THRESHOLD} | 10 | Если количество checkpoint’ов превысит данный порог, сработает триггер |
| {$PGCONNECTIONS_THRESHOLD} | 2 | Если среднее количество сессий за последние 10 минут превысит установленный порог, сработает триггер |
| {$PGDBSIZE_THRESHOLD} | 1073741824 | Если размер базы превысит оговоренный лимит в байтах, сработает триггер |
| {$PGTEMPBYTES_THRESHOLD} | 1048576 | Если скорость записи во временные файлы за последние 10 минут превысит PGTEMPBYTES_THRESHOLD в байтах, сработает триггер |
| {$PGCACHEHIT_THRESHOLD} | 90 | Если за последние 10 минут среднее попадание в кэш будет ниже порога, сработает триггер на базу |
| {$PGDEADLOCK_THRESHOLD} | 0 | Как только количество мертвых блокировок превысит установленный предел, сработает триггер |
| {$PGSLOWQUERY_SEC} | 1 | Если запрос выполняется дольше PGSLOWQUERY_SEC секунд, то считать его медленным |
| {$PGSLOWQUERY_THRESHOLD} | 1 | Если среднее количество медленных запросов за последние 10 минут превысит порог, то сработает триггер |
org — все таблицы и схемы, в которых содержится подстрока org
\.(organization|resource|okved)$ — таблицы с именами organization, resource, okved в любой схеме
^msn\. — все таблицы в схеме msn
Получается, что параметры {$PGDB_REGEXP} и {$PGTBL_REGEXP} — это не просто названия, это подстрока, которая будет искаться в названиях всех баз данных и схем.таблиц.
Только вот регулярки будут работать не все, а только те, в которых не содержатся символы \, ', ", `, *, ?, [, ], {, }, ~, $, !, &, ;, (, ), <, >, |, #, @, 0x0a. Если вы хотите снять это ограничение, отредактируйте /etc/zabbix/zabbix_agentd.conf
UnsafeUserParameters=1
www.postgresql.org/docs/9.3/static/functions-matching.html#FUNCTIONS-POSIX-REGEXP
Если у вас не появляется параметр “PSQL error log”, то скорее всего не верно задан путь {$PGLOGDIR} — поищите на агенте файлик “postgresql-Sun.log” — где он лежит, эту папку и записывайте в макрос.
Мониторим php-opcache
Как принято в лучших домах — десерт!
В данной статье просматривается вся цепочка — от запроса пользователя до данных, кроме одного узла — самого php. Чтобы чуть чуть приоткрыть этот ящик, попробуем собрать статистику встроенного в php5 ускорителя opcache функцией opcache_get_status.
Добавляем в /etc/zabbix/zabbix_agentd.d/user.conf
UserParameter=php.opc.ping,/etc/zabbix/scripts/php-opc.sh
UserParameter=php.opc.discovery,/etc/zabbix/scripts/php-opc.sh discover
Кладем php-opc.* в /etc/zabbix/scripts, в той же папке выполняем
chmod o+r php-opc.php chmod o+x php-opc.sh service zabbix-agent restart
Пропишите в php-opc.sh путь до FastCGI сервера (параметр listen в /etc/php-fpm.d/www.conf)
[root@fliber ~]# vi /etc/zabbix/scripts/php-opc.sh
LISTEN='127.0.0.1:9000'
Если не ставили fcgi для мониторинга php-fpm, надо установить:
yum install fcgi
Импортируем php-opc.xml в шаблоны zabbix, подключаем шаблон к хосту.

Пока создавал триггеры, уменьшил размеры памяти на кэш для своего opcache в 2 раза. Так-что полезно видеть и эту статистику. Если бы проект на этом сервере не пополнялся новыми модулями, то уменьшил бы в 4 раза легко.
Заключение
Пока не знаю, какие еще параметры можно промониторить. Это основные сервисы, которые работают на нашей VDS-машине. Как наберется — поделюсь, конечно. Было бы неплохо добавить шаблон-скррипт mysql, но задачи пока нет. Если очень надо — сделаю :)
Подход можно обсуждать — у меня же получились отдельные примочки для каждой службы, и это тоже неплохо — взял скрипт, дополнил конфиг, залил шаблон — готово.
Если собирать эти мониторы в один пакет, то, конечно, надо делать дополнительно discovery на каждую службу — может быть несколько nginx, php-fpm, postgres. Они могут слушать как порты, так и сокеты.
Версии
CentOS release 6.5 (Final)ZabbixServer 2.2.4
ZabbixAgent 2.2.4
hdparm 9.43
nginx 1.6.1
php-fpm 5.3.3
PostgreSQL 9.3.4
php-opcache 5.5.15
Шаблоны и скрипты тут: http://www.uralati.ru/frontend/for_articles/2014-08-habr-zabbix-mons.zip
Для мониторинга php-fpm и pfp-opcache в архиве имеется версия скриптов для работы с curl(с теми же шаблонами). Описание настроек закомментировано в соответствующих скриптах php-*_curl.sh, см.upd2
upd1
Теперь «HOST=Ваш_агент_addr», «SERVER=Ваш_сервер_addr» задавать не нужно.
Но нужно обязательно задать «Hostname=Ваш_агент_addr» в zabbix_agentd.conf. Значение «system.hostname» не годится.
Устаревшие шаблоны и скрипты тут: скачать
Спасибо за подсказку xenozauros.
Но нужно обязательно задать «Hostname=Ваш_агент_addr» в zabbix_agentd.conf. Значение «system.hostname» не годится.
Устаревшие шаблоны и скрипты тут: скачать
Спасибо за подсказку xenozauros.
upd2
Теперь для мониторинга php-fpm не нужно прописывать конфиг nginx
Теперь для мониторинга php-opcache не нужно прописывать конфиг nginx
Но требуется прописывание LISTEN до php-fpm в скриптах и установка cgi-fcgi:
Это переключение с curl на fcgi позволило сократить время выполнения запросов на мониторинг в 2 раза
Также добавлен копирайт и проверки на правильность путей до программ. Теперь при запуске скрипта из консоли он умеет ругаться, если не из консоли, то ошибка попадет в логи сервера, как не верный ответ.
Устаревшие шаблоны и скрипты тут: скачать
server {...
location ~ ^/(status|ping)$ {
include /etc/nginx/fastcgi_params;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME status;
}
...}
service nginx reload
Теперь для мониторинга php-opcache не нужно прописывать конфиг nginx
server {...
location /opc-status {
include /etc/nginx/fastcgi_params;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME /etc/zabbix/scripts/php-opc.php;
}
...}
service nginx reload
Но требуется прописывание LISTEN до php-fpm в скриптах и установка cgi-fcgi:
yum install fcgi
Это переключение с curl на fcgi позволило сократить время выполнения запросов на мониторинг в 2 раза
Также добавлен копирайт и проверки на правильность путей до программ. Теперь при запуске скрипта из консоли он умеет ругаться, если не из консоли, то ошибка попадет в логи сервера, как не верный ответ.
Устаревшие шаблоны и скрипты тут: скачать
