Всем привет!
Многие специалисты знают, что топовое сетевое оборудование использует специальные чипы для обработки трафика. Я принимаю участие в разработке таких молотилок и хочу поделиться своим опытом в создании таких высокопроизводительных девайсов (со интерфейсами 10/40/100G Ethernet).
Для создания нового канала сетевики чаще всего берут оптику, пару SFP+ модулей, втыкают их в девайсы: лампочки радостно загораются, пакеты начинают приходить: чип начинает их передавать получателям. Но как чип получает пакеты из среды передачи? Если интересно, то добро пожаловать под кат.
Ethernet — это стандарт, принятый ассоциацией IEEE. Стандарты 802.3 охватывают все возможные разновидности Ethernet (от 10M до 100G). Сконцентрируемся на конкретной реализации физического уровня: 10GBASE-R («обычный» 10G, без излишеств).
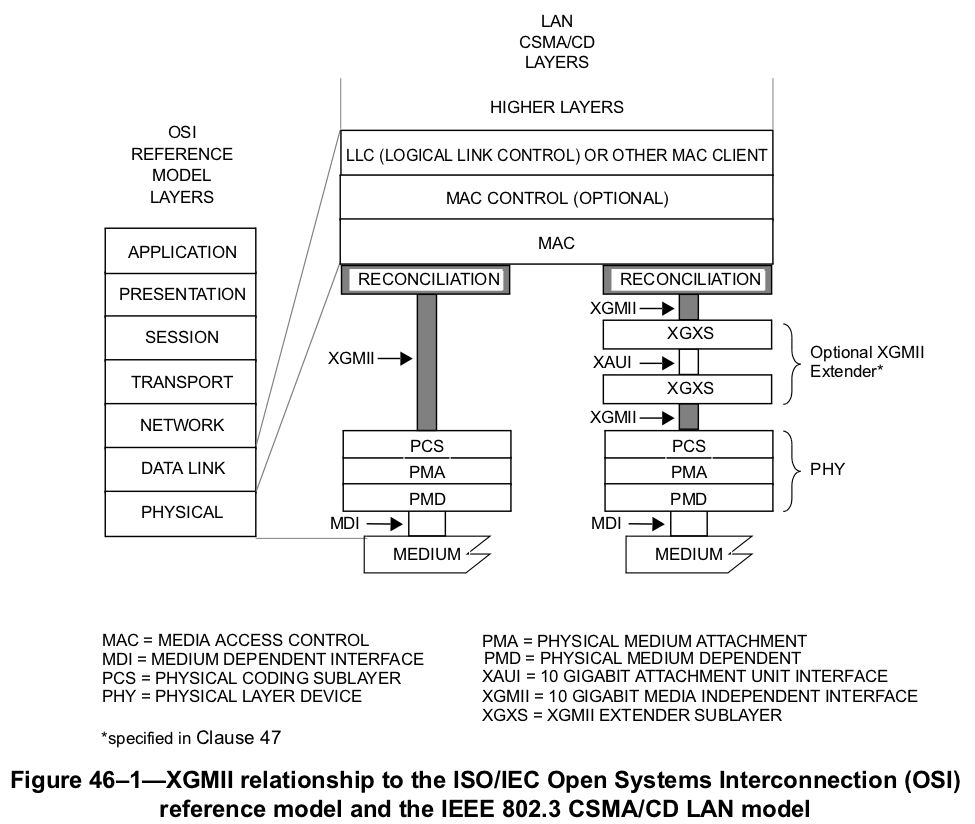
На этом рисунке показаны уровни модели OSI и то, как они отображаются на подуровни протокола Ethernet.
Подуровни:
PHY разделяется на следующие части:
Термины:
Для каждого типа физического уровня может быть своя реализация отдельных PHY-подуровней: применяется различное кодирование, различные частоты передачи (длины волн), но четкое разделение на уровни везде прослеживается. Наличие независимого от среды интерфейса (XGMII) упрощает разработку прикладной логики чипов, т.к. при любом подключении разработчик где-то получит XGMII. О том, что собой представляет XGMII мы поговорим позже.
Самым близким к среде расположен подуровень PMD: его задачи решают специальные модули, которые хорошо известны сетевым специалистам:
В этой таблице уже есть знакомая аббревиатура: XAUI. Оставим рассмотрение XENPAK/X2 на середину статьи, и обратимся к наиболее популярным модулям: XFP и SFP+.
XFI и SFI фактически представляют собой один и тот же интерфейс: дифпара, работающая на скоростях от 9.95 до 11.10 гигабод. Набор скоростей обуславливается тем, что несколько стандартов могут использовать этот интерфейс: от 10GBASE-W WAN до 10GBASE-R over G.709. Нас интересует 10GBASE-R LAN с скоростью в 10.3125 гигабод. Одна дифпара используется для приема, другая — для передачи.

Задачи подуровней PMA и PCS можно решить на чипе, где мы будем выполнять дальнейшую обработку Ethernet пакетов (после того, как выделим их из XGMII). Напомню, что в подуровне PMA необходимо на приеме выделить тактовую частоту и десериализовать входной сигнал. Такую работу могут выполнить специальные аппаратные блоки, которые для других задач нельзя использовать. Эти блоки называются трансиверами. На их подробное описание может уйти целая статья: кому интересно, могут посмотреть посмотреть блок-схему трансиверов в FPGA компании Altera.
После десериализации, данные попадают в подуровень PCS, где производится дескремблирование и декодирование (64b/66b) и отдаются данные в виде XGMII в сторону MAC'a. На передаче выполняются обратные действия.
PCS может быть реализован как с использованием специальных аппаратных блоков (Hard PCS), так и с помощью логики, доступной пользователю (Soft PCS). Разумеется, это утверждение справедливо только для FPGA: в ASIC'ах всё сделанно аппаратно. Производители FPGA закладывают аппаратные PCS блоки для стандартных протоколов, экономя разработчику время и ресурсы FPGA. Наличие таких блоков очень подкупает, т.к. многие стандартные протоколы по опыту работают из коробки, и для большинства из них код предоставляется бесплатно производителем FPGA.

Трансиверы в FPGA — вещь дорогая, дополнительный десяток трансиверов может значительно поднять цену на чип. Есть более дешевые чипы, с трансиверами, работающими на меньших скоростях (могут сериализовать/десериализовать данные на меньших частотах). Другим высокочастотным интерфейсом, который определен в секции 4 стандарта 802.3, является XAUI: 4 дифференциальные пары с скоростью передачи в 3.125 гигабод (для одной линии передачи).
При использовании XAUI возникает опциональный уровень XGXS, который позволяет отдалить PHY и MAC друг от друга на расстояние. Например, выполнять в разных чипах.
Задачу PMA и PCS в таком подключении могут выполнить специальные 10G трансиверы (Допускаю, что может возникнуть путаница, т.к. чуть ранее «трансиверы» вспыли в FPGA, и теперь тут возникает этот термин. Между прочим, модули XFP/SFP+ тоже называются трансиверами.)
Примеры 10G трансиверов:
Этот трансивер является отдельным чипом, ставится между XFP/SFP+ модулем и «нашим» чипом, который будет обрабатывать Ethernet пакеты. По факту, такой трансивер используя блоки PMA и PCS производит преобразование XFI/SFI в XGMI, а затем XGMII преобразуется в XAUI.
XAUI подается на ASIC/FPGA, где используются трансиверы, аналогичные тем, что были рассмотрены ранее, но на скорости 3.125G. Работа трансивера отличается от того варианта, как это происходит в режиме 10G:
XAUI PCS на выходе выдает интерфейс XGMII.
Некоторые PHY-трансиверы могут сразу выдавать на пины интерфейс XGMII и тогда трансиверы в ASIC/FPGA не надо использовать:

У такого метода подключения есть весомые недостатки:
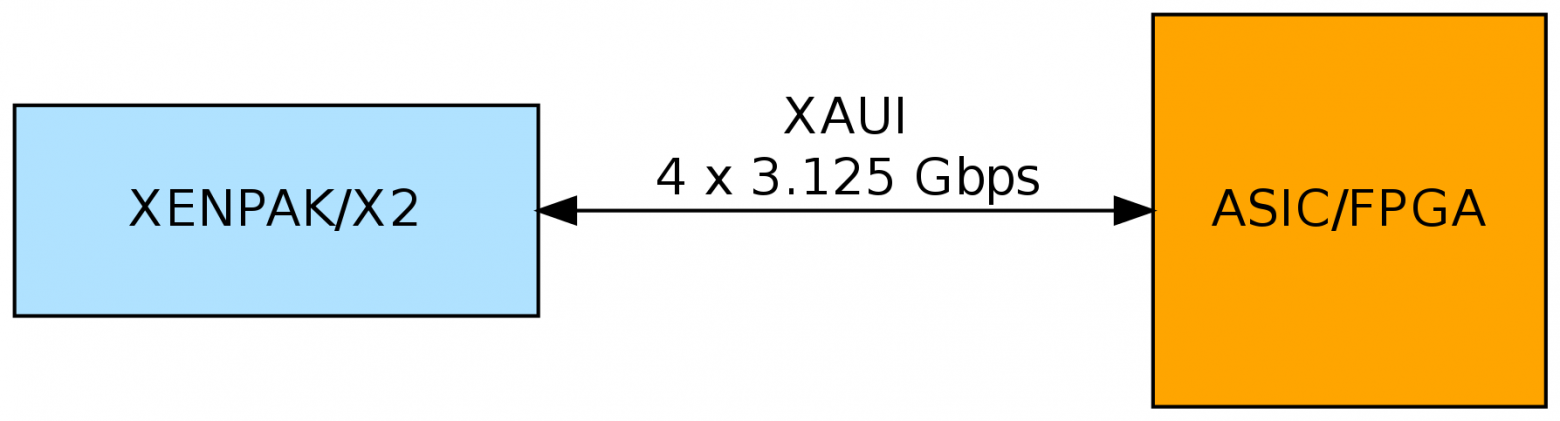
Как я и обещал, мы добрались до этих типов модулей. Несложно увидеть, что их подключение сводится ко второму варианту, только без использования внешнего чипа-трансивера. Модуль возьмет на себя задачи подуровней PMD, PMA и PCS.
XGMII определяется в clause 46 стандарта 802.3. Этот интерфейс состоит из независимого приема и передачи. Каждое из направлений имеет 32-битную шину данных (RXD/TXD [31:0]), четыре контрольных сигнала (RXC/TXC [3:0]) и клок, по которому работает направление (RX_CLK/TX_CLK). В стандарте определено, что шины данных и контрольных сигналов анализируются на каждый фронт клока (DDR). По шине данных идёт сам пакет, контрольные сигналы определяют начало помогают «выделять» начало и конец пакета, а так же сообщают об авариях.
Значение RX_CLK/TX_CLK равно 156.25 МГц. Перемножение 156.25 * 10^6 * 32 * 2 дает ровно 10 Gbit/s. Чаще всего от защелкивания по обоим фронтам клока уходят, повышая частоту или ширину данных:
Чем меньше частота, тем проще обработать эти данные и тем более бюджетные чипы можно использовать. Работу на частотах в ~300 МГц могут себе позволить только топовые (читай, дорогие) FPGA.
Для того, что бы «выцепить» из XGMII пакет применяется специальное MAC-ядро:
Разумеется, у этого ядра есть передающая часть, которая пакет «преобразует» в интерфейс XGMII.
Чаще всего такое ядро реализуется на логике, которая доступна для пользовательских задач. Однако, есть производитель FPGA, который MAC-ядра реализовал аппаратно, экономя ресуры пользователю.
MAC-ядро, выделив пакет из XGMII и разместив пакет во внутренней памяти чипа, «передает» контроль над пакетом прикладной логике чипа: парсерам, фильтрам, системам коммутации и пр. К примеру, если чип стоит на сетевой карте и будет принято решение о том, что надо пакет переслать на хост, то он может быть отправлен с помощью PCIe в оперативную память, подключенную к CPU.
С L1 в большей степени приходится сталкиваться инженерам-схемотехникам, которые разводят платы для приборов. FPGA-программисты с этим работают только в начале подъема железа: когда заработал XGMII и все трансиверы прошли тесты, то мы концентрируемся на том, как сделать обработку трафика. В одном приборе сделано подключение по первому варианту: SFI напрямую заходит в FPGA. В двух других по второму варианту (с использованием трансивера и XAUI). Так же есть девайс у которого есть подключение как напрямую SFI, так и через XAUI, но без трансивера (FPGA подключается к другому чипу).
Для использования внешних трансиверов (да и вообще, большинства специализированных чипов) необходимо подписать NDA. С этим особых проблем чаще всего не возникает. Вместе с NDA выдаются различные доки, например, настройки регистров чипа. Из опыта работы с трансиверами от двух разных производителей замечу, что при подъеме железа в первой партии стабильно возникают какие-то проблемы с настройкой трансивера, которые относительно быстро решались: трансиверы многофункциональные и иногда для настройки на необходимый режим работы надо пошаманить. Иногда бывает, что документация на чипы бывает очень плохая, и приходиться перебирать разные варианты, а техподдержка не отвечает или открыто заявляет, что поддержку по этим чипам она не осуществляет.
Один из плюсов использования чипа-трансивера является то, что вместе с документацией может распространяться набор прошивок-настроек, которые необходимо загружать в трансивер при установке определенного типа модуля. На сколько я понимаю, эти прошивки производят хитрую настройку эквалайзеров, без которой определенный тип модулей будет работать с битовыми ошибками. Один из таких SFP+ модулей (с лимитирующим усилителем) лечился именно таким образом. Если подключаться без трансивера, то такие настройки надо готовить самим для ASIC/FPGA, что может быть нетривиальной задачей.
Наличие интерфейса, который независим от среды передачи, очень упрощает жизнь, т.к. код (application logic: парсеры, генераторы, анализаторы, фильтры, и пр.) очень легко портировать из старых проектов в новые, т.к. не важно, какой тип подключения использовался.
Подключение (и обработка) 40G/100G к ASIC/FPGA похожа на 10G, однако, там есть свои нюансы. Если будет интересно, этому можно будет посвятить отдельную статью, правда, большой она не будет.
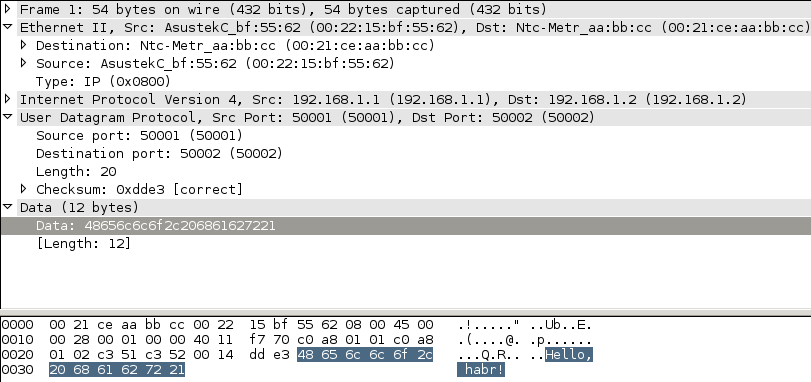
Возьмем обычный UDP-пакет с строчкой «Hello, habr!» и отправим на прибор, что бы посмотреть, как он будет выглядеть на XGMII.
У меня на столе лежит разобранный девайс, на котором чаще всего происходит тестирование новых фич: используем его для наглядного примера. Для этого подготовим специальную прошивку и подключим отладчик, чтобы увидеть сигналы внутри чипа. Подключение 10G сделано по второму варианту: с помощью внешнего трансивера, который отдает данные по XAUI в сторону FPGA. Этот трансивер двухканальный: может работать с двумя SFP+.

Как выглядит XGMII (и наш пакет) внутри FPGA:

В этом приборе внутри FPGA используется 72 битная шина XGMII, работающая на по положительному фронту частоты 156.25 МГц.
Легенда:
Можно заметить, что для получения Ethernet пакета осталось немного: найти его начало и конец (по контрольным символам) и вырезать лишнее: IDLE, PREAMBLE и TERM.
Спасибо за уделенное время и внимание! Если появились вопросы, задавайте без сомнений.
P.S.
Благодарю моих коллег по цеху des333 и paulig за конструктивную критику и советы.
Многие специалисты знают, что топовое сетевое оборудование использует специальные чипы для обработки трафика. Я принимаю участие в разработке таких молотилок и хочу поделиться своим опытом в создании таких высокопроизводительных девайсов (со интерфейсами 10/40/100G Ethernet).
Для создания нового канала сетевики чаще всего берут оптику, пару SFP+ модулей, втыкают их в девайсы: лампочки радостно загораются, пакеты начинают приходить: чип начинает их передавать получателям. Но как чип получает пакеты из среды передачи? Если интересно, то добро пожаловать под кат.
IEEE 802.3
Ethernet — это стандарт, принятый ассоциацией IEEE. Стандарты 802.3 охватывают все возможные разновидности Ethernet (от 10M до 100G). Сконцентрируемся на конкретной реализации физического уровня: 10GBASE-R («обычный» 10G, без излишеств).

На этом рисунке показаны уровни модели OSI и то, как они отображаются на подуровни протокола Ethernet.
Подуровни:
- PHY — физический подуровень.
- MAC — подуровень управления доступом к среде.
PHY разделяется на следующие части:
- PMD — обеспечивает передачи и приема отдельных бит на физическом интерфейсе.
- PMA — обеспечивает сериализацию/десериализацию данных, а так же выделение клока из последовательных данных (на приеме)
- PCS — обеспечивает скремблирование/дескремблирование, а так же кодирование/декодирование (64b/66b) блоков данных
- XGXS — XGMII расширитель: используется если PHY и MAC находится на расстоянии друг от друга (опционален).
- RECONCILIATION — подуровень, транслирующий XGMII в сигналы MAC.
Термины:
- Medium — среда передачи.
- MDI — интерфейс, зависимый от среды передачи данных.
- XGMII — 10G интерфейс, независимый от среды передачи данных. Задача XGMII — обеспечить простое и дешевое соединение между PHY и MAC.
- XAUI — 10G интерфейс подключения к трансиверу.
Для каждого типа физического уровня может быть своя реализация отдельных PHY-подуровней: применяется различное кодирование, различные частоты передачи (длины волн), но четкое разделение на уровни везде прослеживается. Наличие независимого от среды интерфейса (XGMII) упрощает разработку прикладной логики чипов, т.к. при любом подключении разработчик где-то получит XGMII. О том, что собой представляет XGMII мы поговорим позже.
PMD
Самым близким к среде расположен подуровень PMD: его задачи решают специальные модули, которые хорошо известны сетевым специалистам:
| Тип модуля | Интерфейс |
|---|---|
| XENPAK | XAUI |
| X2 | XAUI |
| XFP | XFI |
| SFP+ | SFI |
В этой таблице уже есть знакомая аббревиатура: XAUI. Оставим рассмотрение XENPAK/X2 на середину статьи, и обратимся к наиболее популярным модулям: XFP и SFP+.
XFI/SFI
XFI и SFI фактически представляют собой один и тот же интерфейс: дифпара, работающая на скоростях от 9.95 до 11.10 гигабод. Набор скоростей обуславливается тем, что несколько стандартов могут использовать этот интерфейс: от 10GBASE-W WAN до 10GBASE-R over G.709. Нас интересует 10GBASE-R LAN с скоростью в 10.3125 гигабод. Одна дифпара используется для приема, другая — для передачи.
XFI/SFI подключается напрямую к ASIC/FPGA
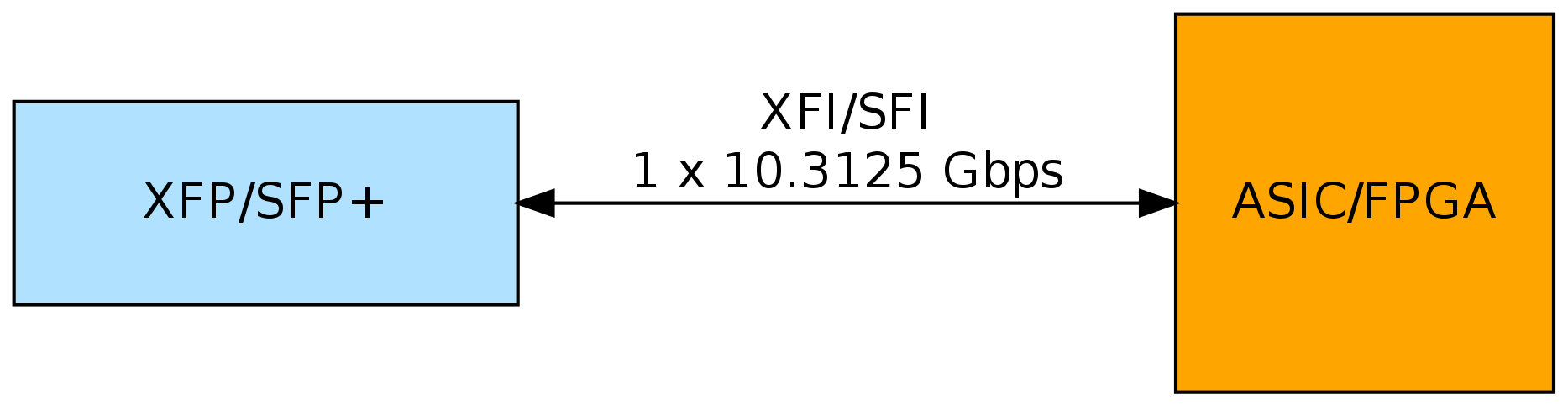
Задачи подуровней PMA и PCS можно решить на чипе, где мы будем выполнять дальнейшую обработку Ethernet пакетов (после того, как выделим их из XGMII). Напомню, что в подуровне PMA необходимо на приеме выделить тактовую частоту и десериализовать входной сигнал. Такую работу могут выполнить специальные аппаратные блоки, которые для других задач нельзя использовать. Эти блоки называются трансиверами. На их подробное описание может уйти целая статья: кому интересно, могут посмотреть посмотреть блок-схему трансиверов в FPGA компании Altera.
После десериализации, данные попадают в подуровень PCS, где производится дескремблирование и декодирование (64b/66b) и отдаются данные в виде XGMII в сторону MAC'a. На передаче выполняются обратные действия.
PCS может быть реализован как с использованием специальных аппаратных блоков (Hard PCS), так и с помощью логики, доступной пользователю (Soft PCS). Разумеется, это утверждение справедливо только для FPGA: в ASIC'ах всё сделанно аппаратно. Производители FPGA закладывают аппаратные PCS блоки для стандартных протоколов, экономя разработчику время и ресурсы FPGA. Наличие таких блоков очень подкупает, т.к. многие стандартные протоколы по опыту работают из коробки, и для большинства из них код предоставляется бесплатно производителем FPGA.
Подключение через внешний чип-трансивер

Трансиверы в FPGA — вещь дорогая, дополнительный десяток трансиверов может значительно поднять цену на чип. Есть более дешевые чипы, с трансиверами, работающими на меньших скоростях (могут сериализовать/десериализовать данные на меньших частотах). Другим высокочастотным интерфейсом, который определен в секции 4 стандарта 802.3, является XAUI: 4 дифференциальные пары с скоростью передачи в 3.125 гигабод (для одной линии передачи).
При использовании XAUI возникает опциональный уровень XGXS, который позволяет отдалить PHY и MAC друг от друга на расстояние. Например, выполнять в разных чипах.
Задачу PMA и PCS в таком подключении могут выполнить специальные 10G трансиверы (Допускаю, что может возникнуть путаница, т.к. чуть ранее «трансиверы» вспыли в FPGA, и теперь тут возникает этот термин. Между прочим, модули XFP/SFP+ тоже называются трансиверами.)
Примеры 10G трансиверов:
- www.vitesse.com/products/productLine/10GE-PHYs
- www.marvell.com/transceivers/alaska-x-gbe
- www.broadcom.com/products/Physical-Layer/10-Gigabit-Ethernet-PHYs
Этот трансивер является отдельным чипом, ставится между XFP/SFP+ модулем и «нашим» чипом, который будет обрабатывать Ethernet пакеты. По факту, такой трансивер используя блоки PMA и PCS производит преобразование XFI/SFI в XGMI, а затем XGMII преобразуется в XAUI.
XAUI подается на ASIC/FPGA, где используются трансиверы, аналогичные тем, что были рассмотрены ранее, но на скорости 3.125G. Работа трансивера отличается от того варианта, как это происходит в режиме 10G:
- Необходимо четыре трансивера (четыре аппаратных блока), т.к. используется 4 дифпары для этого интерфейса.
- XAUI PCS использует кодирование 8b/10b. В 10G PCS применяется 64b/66b.
XAUI PCS на выходе выдает интерфейс XGMII.
Некоторые PHY-трансиверы могут сразу выдавать на пины интерфейс XGMII и тогда трансиверы в ASIC/FPGA не надо использовать:

У такого метода подключения есть весомые недостатки:
- Большой расход пинов: в варианте XGMII у одного чипа используется минимум 78 ножек, против 16 в варианте с XAUI.
- Параллельные интерфейсы могут требовать выравнивания дорожек по плате, что иногда бывает нетривиальным.
Подключение XENPAK/X2
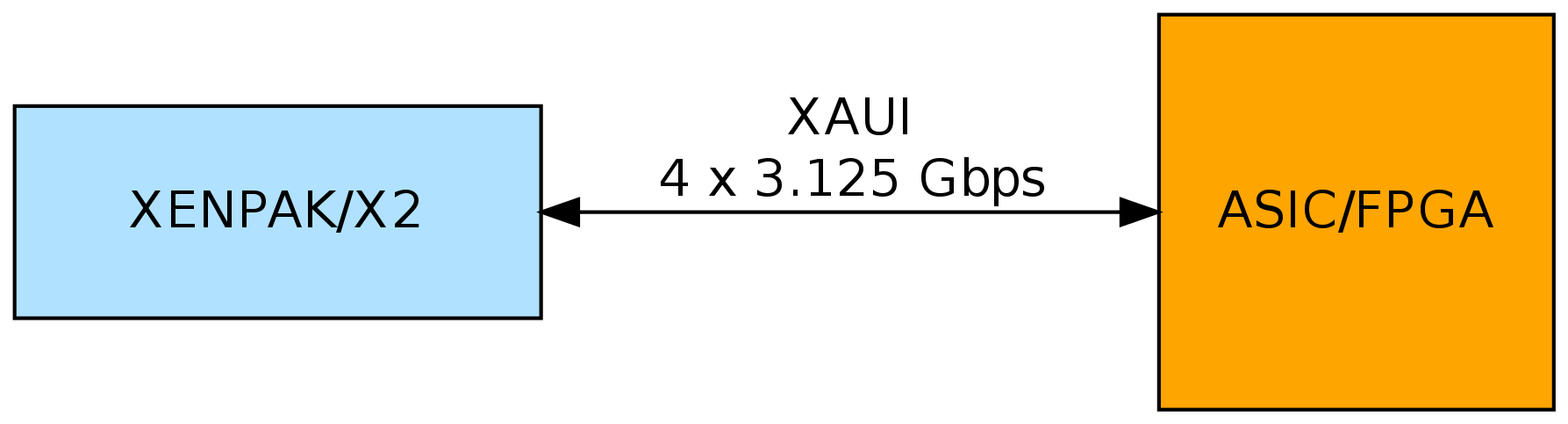
Как я и обещал, мы добрались до этих типов модулей. Несложно увидеть, что их подключение сводится ко второму варианту, только без использования внешнего чипа-трансивера. Модуль возьмет на себя задачи подуровней PMD, PMA и PCS.
XGMII
XGMII определяется в clause 46 стандарта 802.3. Этот интерфейс состоит из независимого приема и передачи. Каждое из направлений имеет 32-битную шину данных (RXD/TXD [31:0]), четыре контрольных сигнала (RXC/TXC [3:0]) и клок, по которому работает направление (RX_CLK/TX_CLK). В стандарте определено, что шины данных и контрольных сигналов анализируются на каждый фронт клока (DDR). По шине данных идёт сам пакет, контрольные сигналы определяют начало помогают «выделять» начало и конец пакета, а так же сообщают об авариях.
Значение RX_CLK/TX_CLK равно 156.25 МГц. Перемножение 156.25 * 10^6 * 32 * 2 дает ровно 10 Gbit/s. Чаще всего от защелкивания по обоим фронтам клока уходят, повышая частоту или ширину данных:
- Шина 36 бит (32 + 4) на частоте 312.5 МГц.
- Шина 72 бит (32 * 2 + 4 * 2) на частоте 156.25 МГц.
Чем меньше частота, тем проще обработать эти данные и тем более бюджетные чипы можно использовать. Работу на частотах в ~300 МГц могут себе позволить только топовые (читай, дорогие) FPGA.
Для того, что бы «выцепить» из XGMII пакет применяется специальное MAC-ядро:
- Пропреитарное. После покупки лицензии на такое IP-ядро, вы (чаще всего) получаете зашифрованные исходники (без возможности модификации) и нет особого ограничения на количество чипов, в которых можно использовать это ядро. Пример.
- С открытым кодом. Такие ядра очень полезны для новичков, т.к. код открыт, и можно разобраться как работает. Лицензия на использование определяется отдельно. Пример.
- Самописное.
Разумеется, у этого ядра есть передающая часть, которая пакет «преобразует» в интерфейс XGMII.
Чаще всего такое ядро реализуется на логике, которая доступна для пользовательских задач. Однако, есть производитель FPGA, который MAC-ядра реализовал аппаратно, экономя ресуры пользователю.
MAC-ядро, выделив пакет из XGMII и разместив пакет во внутренней памяти чипа, «передает» контроль над пакетом прикладной логике чипа: парсерам, фильтрам, системам коммутации и пр. К примеру, если чип стоит на сетевой карте и будет принято решение о том, что надо пакет переслать на хост, то он может быть отправлен с помощью PCIe в оперативную память, подключенную к CPU.
Личный опыт
С L1 в большей степени приходится сталкиваться инженерам-схемотехникам, которые разводят платы для приборов. FPGA-программисты с этим работают только в начале подъема железа: когда заработал XGMII и все трансиверы прошли тесты, то мы концентрируемся на том, как сделать обработку трафика. В одном приборе сделано подключение по первому варианту: SFI напрямую заходит в FPGA. В двух других по второму варианту (с использованием трансивера и XAUI). Так же есть девайс у которого есть подключение как напрямую SFI, так и через XAUI, но без трансивера (FPGA подключается к другому чипу).
Для использования внешних трансиверов (да и вообще, большинства специализированных чипов) необходимо подписать NDA. С этим особых проблем чаще всего не возникает. Вместе с NDA выдаются различные доки, например, настройки регистров чипа. Из опыта работы с трансиверами от двух разных производителей замечу, что при подъеме железа в первой партии стабильно возникают какие-то проблемы с настройкой трансивера, которые относительно быстро решались: трансиверы многофункциональные и иногда для настройки на необходимый режим работы надо пошаманить. Иногда бывает, что документация на чипы бывает очень плохая, и приходиться перебирать разные варианты, а техподдержка не отвечает или открыто заявляет, что поддержку по этим чипам она не осуществляет.
Один из плюсов использования чипа-трансивера является то, что вместе с документацией может распространяться набор прошивок-настроек, которые необходимо загружать в трансивер при установке определенного типа модуля. На сколько я понимаю, эти прошивки производят хитрую настройку эквалайзеров, без которой определенный тип модулей будет работать с битовыми ошибками. Один из таких SFP+ модулей (с лимитирующим усилителем) лечился именно таким образом. Если подключаться без трансивера, то такие настройки надо готовить самим для ASIC/FPGA, что может быть нетривиальной задачей.
Наличие интерфейса, который независим от среды передачи, очень упрощает жизнь, т.к. код (application logic: парсеры, генераторы, анализаторы, фильтры, и пр.) очень легко портировать из старых проектов в новые, т.к. не важно, какой тип подключения использовался.
Подключение (и обработка) 40G/100G к ASIC/FPGA похожа на 10G, однако, там есть свои нюансы. Если будет интересно, этому можно будет посвятить отдельную статью, правда, большой она не будет.
Hello, habr!
Возьмем обычный UDP-пакет с строчкой «Hello, habr!» и отправим на прибор, что бы посмотреть, как он будет выглядеть на XGMII.

У меня на столе лежит разобранный девайс, на котором чаще всего происходит тестирование новых фич: используем его для наглядного примера. Для этого подготовим специальную прошивку и подключим отладчик, чтобы увидеть сигналы внутри чипа. Подключение 10G сделано по второму варианту: с помощью внешнего трансивера, который отдает данные по XAUI в сторону FPGA. Этот трансивер двухканальный: может работать с двумя SFP+.

Как выглядит XGMII (и наш пакет) внутри FPGA:

В этом приборе внутри FPGA используется 72 битная шина XGMII, работающая на по положительному фронту частоты 156.25 МГц.
Легенда:
- xgmii_rxc — набор контрольных сигналов.
- xgmii_rxd — набор сигналов данных (разбито на байты для удобства).
- IDLE — сигналы отсутствия передачи пакета.
- PREAMBLE — преамбула, обозначает начало передачи пакета.
- L2_HDR — заголовок 2 уровня: Ethernet.
- L3_HDR — заголовок 3 уровня: IP.
- L4_HDR — заголовок 4 уровня: UDP.
- MSG — наше сообщение («Hello, habr!»).
- PAD — заполнение. Присуствует в пакете, если изначальная длина полезной нагрузки была меньше 60 байт.
- FCS — проверочная сумма пакета. По ней можно определить, побился пакет во время пересылки, или нет.
- TERM — сигнал окончания передачи пакета.
Можно заметить, что для получения Ethernet пакета осталось немного: найти его начало и конец (по контрольным символам) и вырезать лишнее: IDLE, PREAMBLE и TERM.
Спасибо за уделенное время и внимание! Если появились вопросы, задавайте без сомнений.
P.S.
Благодарю моих коллег по цеху des333 и paulig за конструктивную критику и советы.
