Всем привет!
Многим известно, что во всех современных процессорах есть вычислительный конвейер. Бытует заблуждение, что конвейер — это какая-то фишка процессоров, а в чипах для других приложений (к примеру, сетевых) этого нет. На самом деле конвейеризация (или pipelining) — это ключ к созданию высокопроизводительных приложений на базе ASIC/FPGA.
Очень часто для достижения высокой производительности выбирают такие алгоритмы, которые легко конвейеризируются в чипе. Если интересно узнать о низкоуровневых подробностях, добро пожаловать под кат!
Рассмотрим следующий пример: необходимо суммировать четыре беззнаковых восьмибитных числа. В рамках этой задачи я пренебрег тем, что результат суммирования 8-битных чисел может быть большим, чем 255.
Вполне очевидный код на языке SystemVerilog для этой задачи:
Взглянем на получившуюся схему из регистров и сумматоров. Используем для этого RTL Viewer в Quartus'e. (Tools -> Netlist Viewer -> RTL Viewer). В рамках этой статьи слова «регистр» и «триггер» являются полноценными синонимами.
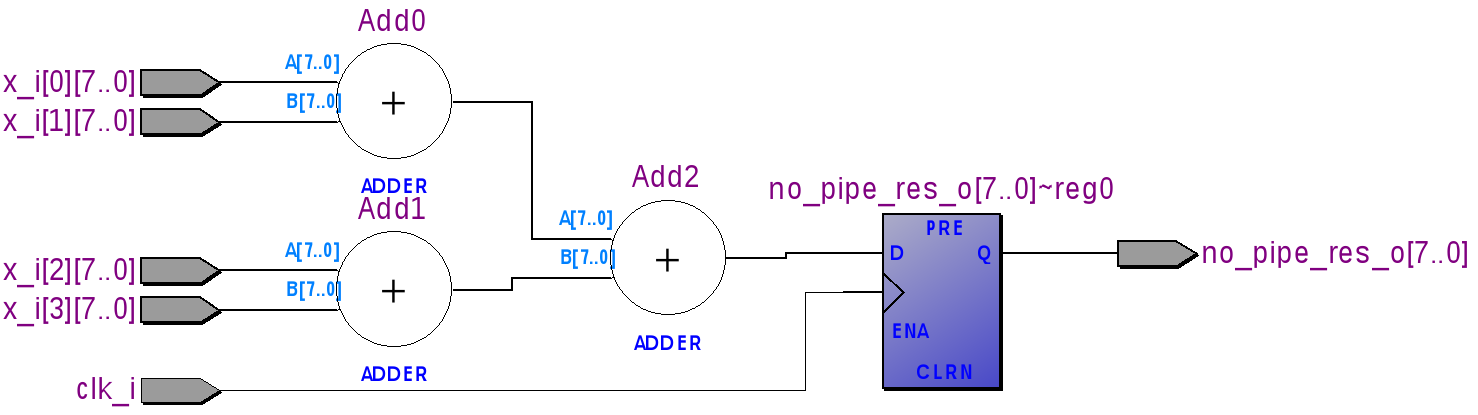
Что получилось?
Добавим регистры между сумматорами Add0/Add1 и Add2.
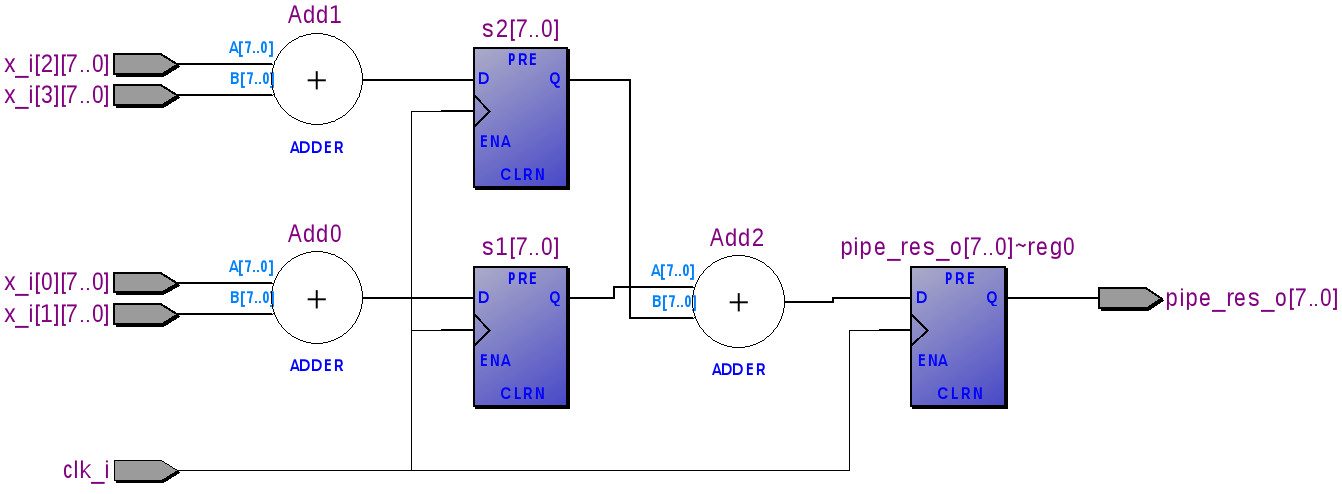
Для того чтобы увидеть разницу в поведении модулей no_pipe_example и pipe_example объединим их в один и просимулируем.

По положительному фронту (так называемый posedge) clk_i на вход модуля были поданы 4 числа: 4, 8, 15 и 23. На следующий положительный фронт в регистре no_pipe_res_o появился ответ 50, а в регистрах s1 и s2 значения полусумм 12 и 38. На следующий posedge в регистре pipe_res_o появился ответ 50, а в no_pipe_res_o появился 0, что не удивительно, т.к. четыре нуля были поданы в качестве входных значений и схема их честно сложила.
Сразу заметно, что результат в pipe_res_o запаздывает на один такт чем в no_pipe_res_o, т.к. были добавлены регистры s1 и s2.
Рассмотрим, что будет, если мы каждый такт будем подавать новый массив чисел для суммирования:

Несложно заметить, что обе ветки (с конвейером так и без) готовы к тому, что бы каждый такт принимать новую порцию данных.
Возникает справедливый вопрос: зачем использовать конвейер, если на вычисления тратятся больше времени (тактов) и это занимает больше триггеров (ресурсов)?
Производительность этой схемы определяется количеством 8-битных четверок, которых она сможет принять и обработать в секунду. Схема готова к новой порции данных каждый такт, следовательно, чем будет выше значение частоты clk_i, тем выше производительность схемы.
Существует формула, по которой рассчитывается максимальная допустимая частота между двумя триггерами. Её упрощенный вариант:
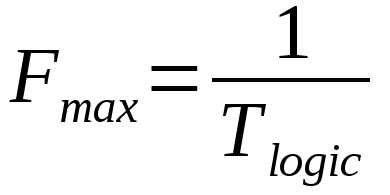
Легенда:
Под спойлером расположена полная формула, пояснения к которой можно найти в списке литературы, который приведен в конце статьи.
Для оценки максимальной частоты рассматриваются пути между всеми триггерами в пределах одного клокового домена: то есть только те триггеры, которые работают от интересующего нас клока. Затем определяется самый длинный путь, который и показывает максимальную частоту, на которой будет работать схема без ошибок.
Чем больше логических элементов будет на пути сигнала от одного триггера до другого, тем больше будет значение Tlogic. Если мы хотим увеличить частоту, то нам надо сокращать это значение! Как же это сделать?
Добавление регистров — это и есть конвейеризация! Конвейеризированные схемы в большинстве случаев могут работать на больших частотах, чем те, которые без конвейера.
Рассмотрим следующий пример:
Есть два триггера, A и B, сигнал между ними преодолевает два «облачка» логики, одно из которых занимает 4 ns, другое 7 ns. Если будет проще, представьте, что зеленое облако — это сумматор, а оранжевое — мультиплексор. Примеры и числа взяты из головы.
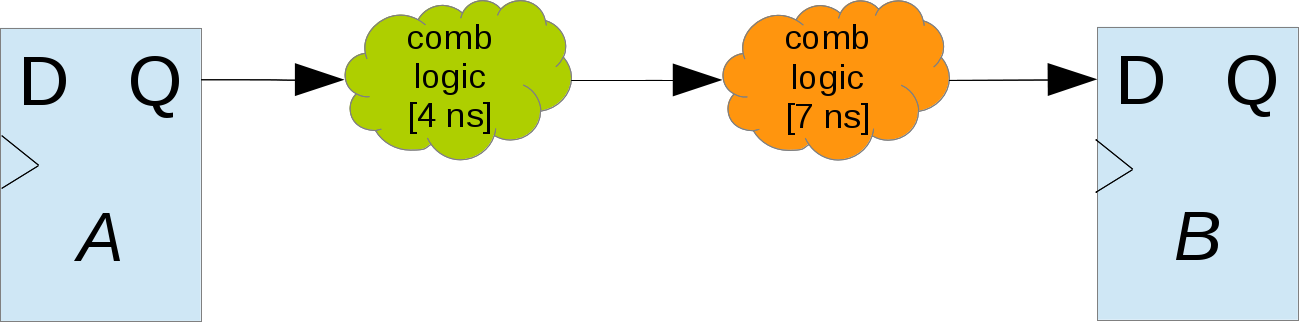
Чему будет равна Fmax? Сумма 4 и 7 ns будет отображать значение Tlogic: Fmax ~91 МГц.
Добавим регистр C между комбинационкой:
Fmax оценивается по худшему пути, время которого теперь составляет 7 ns, или ~142 МГц. Разуеется, не надо бросаться и добавлять регистры для повышения частоты где попало, т.к. можно легко напороться на самую частую ошибку (в моем опыте), что где-то на один такт поехала схема, т.к. где-то добавили регистр, а где-то нет. Бывает, схема к конвейризации не была готова, т.к. есть обратная связь, в связи с задержкой на такт(ы), начала неправильно работать.
Подведем небольшой итог:
Отмечу, что иногда цели добиться максимальной частоты нет, чаще всего наоборот: известна частота, к которой надо стремиться. К примеру, стандартная частота работы 10G MAC-ядра — 156.25 МГц. Может оказаться удобным, что бы вся схема работала от этой частоты. Бывают требования, которые напрямую не связаны с тактовой частотой: к примеру, есть задача, что бы какая-то система поиска делала 10 миллионов поисков в секунду. С одной стороны, можно сделать конвейер на частоте 10 МГц, и подготовить схему, чтобы принимать данные каждые такт. С другой, более выгодным вариантом может оказаться такой: повысить частоту до 100 МГц и сделать такой конвейер, который готов принимать данные каждый 10-й такт.
Конечно, этот пример очень детский, но он является ключом к созданию схем с очень большой производительностью.
В прошлой статье я обмолвился, что занимаюсь разработкой высокоскоростных Ethernet-приложений на базе FPGA. Главную основу таких приложений составляют конвейеры, которые перемалывают пакеты. Так получилось, что при подготовке этой статьи я прочитал небольшую лекцию о конвейеризации в FPGA студентам-стажерам, которые набираются опыта в этом ремесле. Подумал, что эти советы будут уместны здесь, и, возможно, вызовут какую-то дискуссию. Опытные разработчики, скорее всего, не найдут что-то новое или оригинальное)
Иногда начинающие FPGA-разработчики допускают следующую ошибку: определяют факт прихода новых данных по самим данным. К примеру, проверяют данные на ноль: если не ноль, то новые данные пришли, иначе ничего не делаем. Так же вместо нуля используют какую-то другую «запрещенную» комбинацию (все единицы).
Это не очень правильный подход, так как:
Вводя сигналы валидности, мы сообщаем модулю факт наличия валидных данных на входе, а он в свою очередь показывает, когда данные на выходе корректны. Эти сигналы может использовать следующий модуль, который стоит в конвейерной цепочке.
Добавим сигналы валидности x_val_i и pipe_res_val_o в пример выше:
Согласитесь, сразу же стало нагляднее, что здесь происходит: в какой такт данные на входе и выходе оказываются валидными?
Пару замечаний:
Чаще всего при разработке сразу ясно, что необходимо построить конвейер для достижения нужной частоты. Когда конвейер пишется с нуля, необходимо подумать об архитектуре, к примеру, решить когда можно отправлять данные на конвейер. В качестве иллюстрации приведу типичную архитектуру конвейера обработки Ethernet-пакета.
Легенда:
В этом примере fifo_0 является отправителем данных, а fifo_1 — получателем. Допустим, что по каким-то причинам из fifo_1 не всегда вычитываются данные или скорость чтения данных меньше, чем скорость записи, в итоге, это фифо может переполниться. Не надо писать в полную фифошку, т.к., как минимум, вы сломаете пакет (из пакета может пропасть какой-то набор данных) и некорректно его передадите.
Что fifo может сообщить?
Чтобы не ломались данные, нам надо когда-то не вычитывать данные пакета из fifo_0 и приостанавливать работу конвейера. Как это сделать?
Допустим, мы выделили fifo_1 под MTU, к примеру, 1500 байт. Перед началом чтения пакета из fifo_0 arb смотрит на количество свободных байт в fifo_1. Если оно больше, чем размер текущего пакета, то выставляем rd_req и не снимаем до конца пакета. Иначе ждем пока фифо не освободится.
Плюсы:
Минусы:
Примечание:
При расчете свободного места надо сделать запас на длину конвейера. К примеру, прямо сейчас в fifo_1 свободно 100 байт, к нам пришел пакет 95 байт. Смотрим, что 100 больше 95 и начинаем пересылать пакет. Это не совсем верно, т.к. мы не знаем текущего состояния конвейера — если мы обрабатываем предыдущий пакет, то в худшем случае в fifo_1 дополнительно запишутся еще слова в количестве длины конвейера (в тактах). Если конвейер работает 10 тактов, то еще 10 слов попадут в fifo_1, и фифо может переполниться, когда мы будем писать пакет из 95 байт.
Зарезервируем в fifo_1 количество слов равное длине конвеера. Используем сигнал almost_full.
Арбитр каждый такт смотрит на этот сигнал. Если он равен 0, то мы вычитываем одно слово пакета, иначе — нет.
Плюсы:
Минусы:
У предыдущих вариантов есть общая черта: если слово пакета попало в начало конвейера, то уже ничего не сделать: через константное количество тактов это слово (либо его модификация) попадет в fifo_1.
Альтернативный вариант заключается в том, что конвейер можно останавливать во время работы. У каждой стадии с номером M появляется вход ready, который показывает, готова ли стадия M+1 принимать данные или нет. На вход самой последней стадии заводится инверсия full или almost_full (если есть желание немного перестраховаться).

Плюсы:
Минусы:
Вышеописанные проблемы можно разрешить используя интерфейсы, в которых уже заложены вспомогательные сигналы. Альтера для потоков данных предлагает использовать интерфейс Avalon Streaming (Avalon-ST). Его подробное описание можно найти тут. Кстати, именно этот интерфейс используется в Альтеровских 10G/40G/100G Ethernet MAC-ядрах.
Сразу обращает на себя внимание наличие сигналов valid и ready, о которых мы говорили ранее. Сигнал empty показывает количество свободных (неиспользуемых) байт в последнем слове пакета. Сигналы startofpacket и endofpacket определяют начало и конец пакета: удобно использовать эти сигналы для сбросов различных счетчиков, которые отсчитывают оффсеты для выцепления нужных данных.
Xilinx предлагает использовать AXI4-Stream для этих целей.
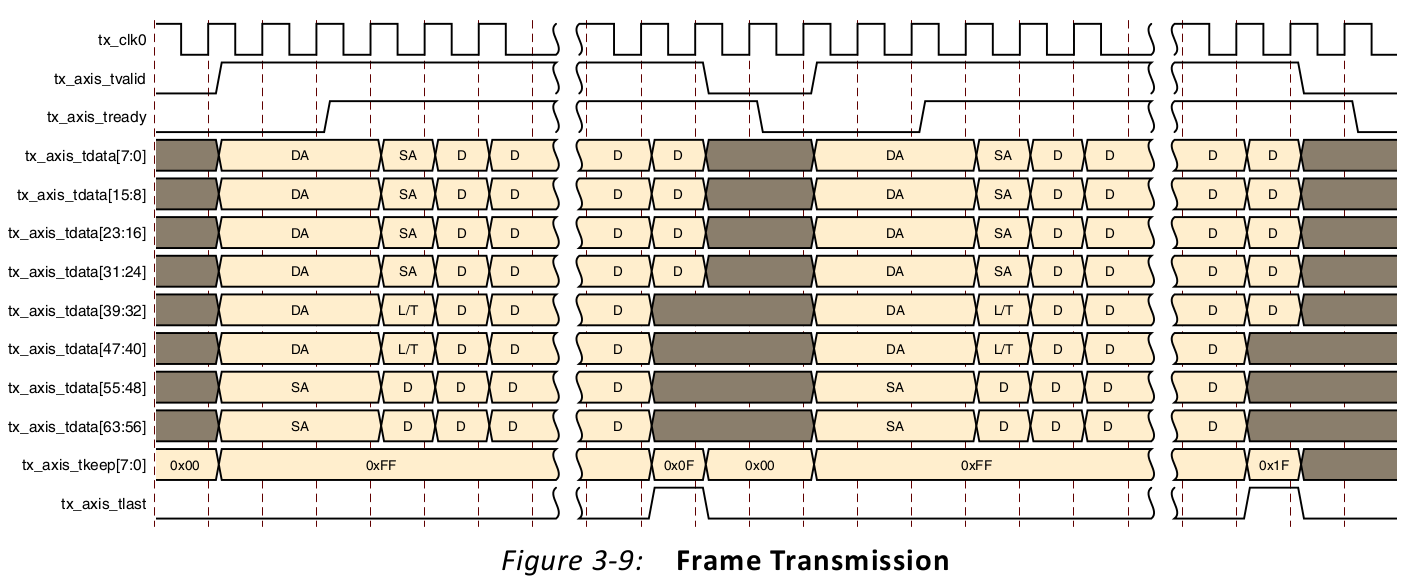
В целом, набор сигналов похож (на этой картинке не все сигналы, возможные доступные в этом стандарте). Если честно, AXI4-Stream я никогда не использовал. Если кто-то использовал оба интерфейса, буду признателен, если поделитесь сравнением и впечатлениями.
Думаю, плюсы использования стандартных интерфейсов упоминать не надо. Ну, и минусы очевидны: необходимо соблюдать стандарт, что выражается в большем количестве кода, ресурсов, тестов и пр. Конечно, можно делать свои велосипеды, но в перспективе на большом проекте (и топовых чипах) это может вылезти боком.
В качестве примера посложнее чем пара сумматоров предлагаю сделать модуль, который в Ethernet-пакете меняет местами MAC-адреса источника и получателя (mac_src и mac_dst). Это может полезным, если есть желание весь трафик, который приходит на девайс отправить обратно (так называемый заворот трафика/шлейф или loopback). Реализация, конечно же, должна быть сделана конвейером.
Используем интерфейс Avalon-ST с 64-битной шиной данных (для 10G) без сигналов ready и error. В качестве тестового пакета возьмем тот, который смотрели на xgmii в предыдущей статье. Тогда:
Код на SystemVerilog под спойлером:
Не всё так страшно, как могло показаться ранее: большая часть строчек ушла на описание входов/выходов модуля и линии задержки. По startofpacket определяем в каком слове мы находимся, и какие данные надо подставлять в комбинационку new_data_c, которая потом защелкивается в data_o. Сигналы startofpacket, endofpacket, empty, valid задерживаются на нужное количество тактов.
Симуляция модуля:
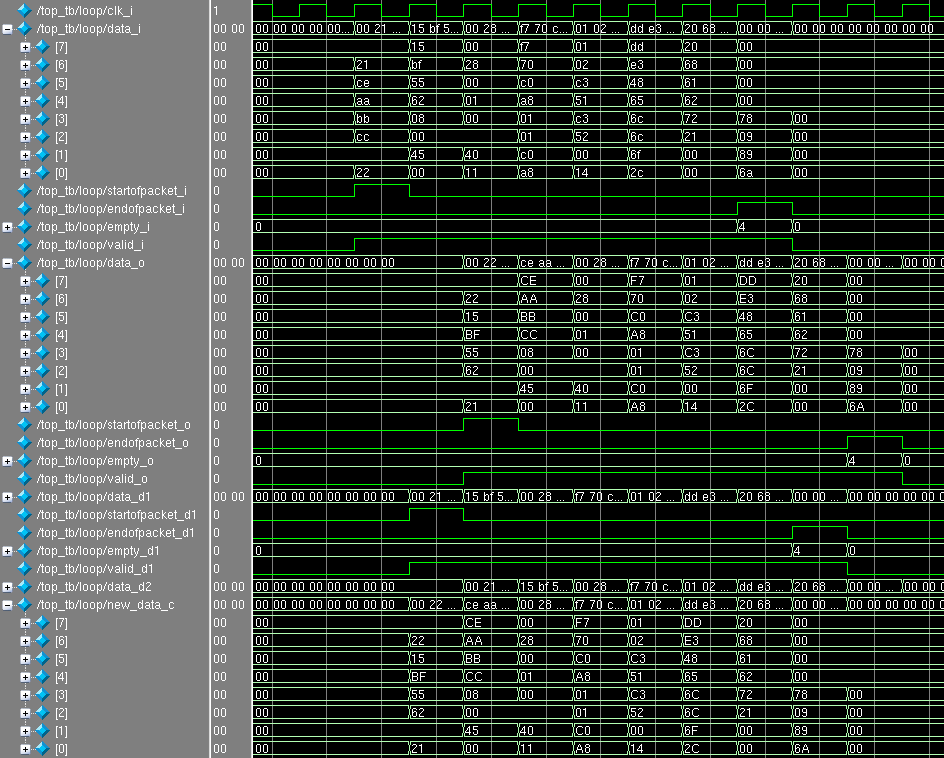
Как видим, MAC-адреса поменялись местами, а все остальные данные в пакете не изменились.
В следующей статье мы разберем квадродерево: более серьезный пример конвейеризации, где задействуем одну из архитектурных особенностей FPGA — блочную память.
Спасибо за уделенное время и внимание! Если появились вопросы, задавайте без сомнений.
P.S. Благодарю des333 за конструктивную критику и советы.
Многим известно, что во всех современных процессорах есть вычислительный конвейер. Бытует заблуждение, что конвейер — это какая-то фишка процессоров, а в чипах для других приложений (к примеру, сетевых) этого нет. На самом деле конвейеризация (или pipelining) — это ключ к созданию высокопроизводительных приложений на базе ASIC/FPGA.
Очень часто для достижения высокой производительности выбирают такие алгоритмы, которые легко конвейеризируются в чипе. Если интересно узнать о низкоуровневых подробностях, добро пожаловать под кат!
Простой пример
Рассмотрим следующий пример: необходимо суммировать четыре беззнаковых восьмибитных числа. В рамках этой задачи я пренебрег тем, что результат суммирования 8-битных чисел может быть большим, чем 255.
Вполне очевидный код на языке SystemVerilog для этой задачи:
module no_pipe_example(
input clk_i,
input [7:0] x_i [3:0],
output logic [7:0] no_pipe_res_o
);
// no pipeline
always_ff @( posedge clk_i )
begin
no_pipe_res_o <= ( x_i[0] + x_i[1] ) +
( x_i[2] + x_i[3] );
end
endmodule
Взглянем на получившуюся схему из регистров и сумматоров. Используем для этого RTL Viewer в Quartus'e. (Tools -> Netlist Viewer -> RTL Viewer). В рамках этой статьи слова «регистр» и «триггер» являются полноценными синонимами.

Что получилось?
- Входы x_i[0] и x_i[1] подаются на сумматор Add0, а x_i[2] и x_i[3] на Add1.
- Выходы c Add0 и Add1 подаются на сумматор Add2.
- Выход с сумматора Add2 защелкивается в триггер no_pipe_res_o.
Добавим регистры между сумматорами Add0/Add1 и Add2.
module pipe_example(
input clk_i,
input [7:0] x_i [3:0],
output logic [7:0] pipe_res_o
);
// pipeline
logic [7:0] s1 = '0;
logic [7:0] s2 = '0;
always_ff @( posedge clk_i )
begin
s1 <= x_i[0] + x_i[1];
s2 <= x_i[2] + x_i[3];
pipe_res_o <= s1 + s2;
end
endmodule

- Входы x_i[0] и x_i[1] подаются на сумматор Add0, а x_i[2] и x_i[3] на Add1.
- После суммирования результат кладется в регистры s1 и s2.
- Данные с регистров s1 и s2 подаются на Add2, результат суммирования защелкивается в pipe_res_o.
Для того чтобы увидеть разницу в поведении модулей no_pipe_example и pipe_example объединим их в один и просимулируем.
Скрытый текст
module pipe_and_no_pipe_example(
input clk_i,
input [7:0] x_i [3:0],
output logic [7:0] no_pipe_res_o,
output logic [7:0] pipe_res_o
);
// no pipeline
always_ff @( posedge clk_i )
begin
no_pipe_res_o <= ( x_i[0] + x_i[1] ) +
( x_i[2] + x_i[3] );
end
// pipeline
logic [7:0] s1 = '0;
logic [7:0] s2 = '0;
always_ff @( posedge clk_i )
begin
s1 <= x_i[0] + x_i[1];
s2 <= x_i[2] + x_i[3];
pipe_res_o <= s1 + s2;
end
endmodule

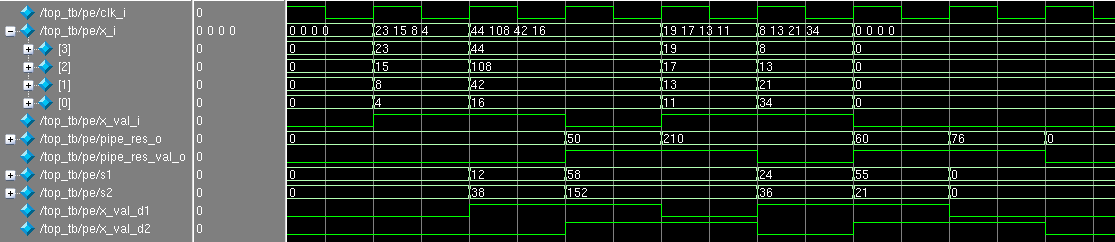
По положительному фронту (так называемый posedge) clk_i на вход модуля были поданы 4 числа: 4, 8, 15 и 23. На следующий положительный фронт в регистре no_pipe_res_o появился ответ 50, а в регистрах s1 и s2 значения полусумм 12 и 38. На следующий posedge в регистре pipe_res_o появился ответ 50, а в no_pipe_res_o появился 0, что не удивительно, т.к. четыре нуля были поданы в качестве входных значений и схема их честно сложила.
Сразу заметно, что результат в pipe_res_o запаздывает на один такт чем в no_pipe_res_o, т.к. были добавлены регистры s1 и s2.
Рассмотрим, что будет, если мы каждый такт будем подавать новый массив чисел для суммирования:

Несложно заметить, что обе ветки (с конвейером так и без) готовы к тому, что бы каждый такт принимать новую порцию данных.
Возникает справедливый вопрос: зачем использовать конвейер, если на вычисления тратятся больше времени (тактов) и это занимает больше триггеров (ресурсов)?
Производительность конвейера
Производительность этой схемы определяется количеством 8-битных четверок, которых она сможет принять и обработать в секунду. Схема готова к новой порции данных каждый такт, следовательно, чем будет выше значение частоты clk_i, тем выше производительность схемы.
Существует формула, по которой рассчитывается максимальная допустимая частота между двумя триггерами. Её упрощенный вариант:

Легенда:
- Fmax — максимальная тактовую частота.
- Tlogic — задержка при прохождении сигнала через логические элементы.
Под спойлером расположена полная формула, пояснения к которой можно найти в списке литературы, который приведен в конце статьи.
Скрытый текст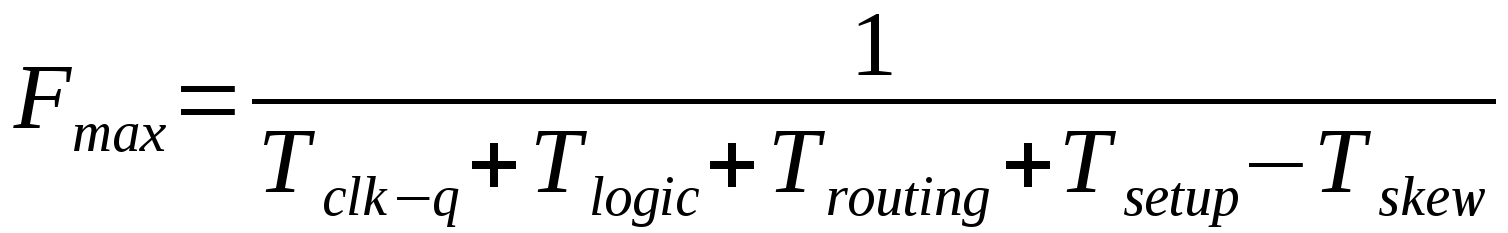

Для оценки максимальной частоты рассматриваются пути между всеми триггерами в пределах одного клокового домена: то есть только те триггеры, которые работают от интересующего нас клока. Затем определяется самый длинный путь, который и показывает максимальную частоту, на которой будет работать схема без ошибок.
Чем больше логических элементов будет на пути сигнала от одного триггера до другого, тем больше будет значение Tlogic. Если мы хотим увеличить частоту, то нам надо сокращать это значение! Как же это сделать?
- Оптимизировать код. Иногда новички (да и опытные разработчики, чего греха таить!) пишут такие конструкции, которые превращаются в очень длинные цепочки логики: этого надо избегать, различными трюками. Иногда необходимо оптимизировать схему под конкретную архитектуру FPGA.
- Добавить регистр(ы). Просто разрезаем логику на кусочки.
Добавление регистров — это и есть конвейеризация! Конвейеризированные схемы в большинстве случаев могут работать на больших частотах, чем те, которые без конвейера.
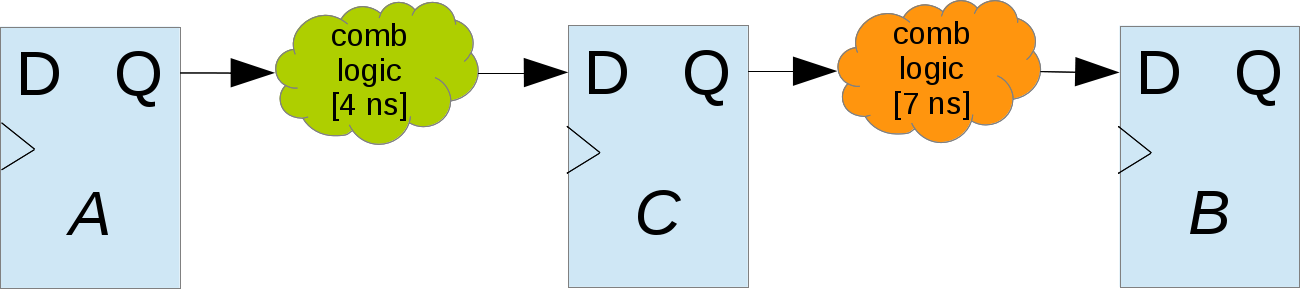
Рассмотрим следующий пример:
Есть два триггера, A и B, сигнал между ними преодолевает два «облачка» логики, одно из которых занимает 4 ns, другое 7 ns. Если будет проще, представьте, что зеленое облако — это сумматор, а оранжевое — мультиплексор. Примеры и числа взяты из головы.

Чему будет равна Fmax? Сумма 4 и 7 ns будет отображать значение Tlogic: Fmax ~91 МГц.
Добавим регистр C между комбинационкой:

Fmax оценивается по худшему пути, время которого теперь составляет 7 ns, или ~142 МГц. Разуеется, не надо бросаться и добавлять регистры для повышения частоты где попало, т.к. можно легко напороться на самую частую ошибку (в моем опыте), что где-то на один такт поехала схема, т.к. где-то добавили регистр, а где-то нет. Бывает, схема к конвейризации не была готова, т.к. есть обратная связь, в связи с задержкой на такт(ы), начала неправильно работать.
Подведем небольшой итог:
- Благодаря конвейеризации можно увеличить пропускную способность схемы, жертвуя временем обработки и ресурсами.
- Разбивать логику необходимо как можно равномерно, т.к. максимальная частота схемы зависит от худшего пути. Разбив 11 ns пополам, можно было бы получить 182 МГц.
- Разумеется, до бесконечности увеличивать частоту не получится, т.к. временными параметрами, на которые мы сейчас закрыли глаза, нельзя будет пренебрегать. В первую очередь Trouting.
Отмечу, что иногда цели добиться максимальной частоты нет, чаще всего наоборот: известна частота, к которой надо стремиться. К примеру, стандартная частота работы 10G MAC-ядра — 156.25 МГц. Может оказаться удобным, что бы вся схема работала от этой частоты. Бывают требования, которые напрямую не связаны с тактовой частотой: к примеру, есть задача, что бы какая-то система поиска делала 10 миллионов поисков в секунду. С одной стороны, можно сделать конвейер на частоте 10 МГц, и подготовить схему, чтобы принимать данные каждые такт. С другой, более выгодным вариантом может оказаться такой: повысить частоту до 100 МГц и сделать такой конвейер, который готов принимать данные каждый 10-й такт.
Конечно, этот пример очень детский, но он является ключом к созданию схем с очень большой производительностью.
Советы и личный опыт
В прошлой статье я обмолвился, что занимаюсь разработкой высокоскоростных Ethernet-приложений на базе FPGA. Главную основу таких приложений составляют конвейеры, которые перемалывают пакеты. Так получилось, что при подготовке этой статьи я прочитал небольшую лекцию о конвейеризации в FPGA студентам-стажерам, которые набираются опыта в этом ремесле. Подумал, что эти советы будут уместны здесь, и, возможно, вызовут какую-то дискуссию. Опытные разработчики, скорее всего, не найдут что-то новое или оригинальное)
Использовать сигналы валидности
Иногда начинающие FPGA-разработчики допускают следующую ошибку: определяют факт прихода новых данных по самим данным. К примеру, проверяют данные на ноль: если не ноль, то новые данные пришли, иначе ничего не делаем. Так же вместо нуля используют какую-то другую «запрещенную» комбинацию (все единицы).
Это не очень правильный подход, так как:
- На зануление и проверку тратятся ресурсы. На больших шинах данных это может быть очень дорогим.
- Может быть неочевидно для других разработчиков, что здесь происходит (WTF code).
- Какой-то запрещенной комбинации может и не быть. Как в примере с сумматором выше: все значения от 0 до 255 валидны и могут подаваться на сумматор.
Вводя сигналы валидности, мы сообщаем модулю факт наличия валидных данных на входе, а он в свою очередь показывает, когда данные на выходе корректны. Эти сигналы может использовать следующий модуль, который стоит в конвейерной цепочке.
Добавим сигналы валидности x_val_i и pipe_res_val_o в пример выше:
Скрытый текст
module pipe_with_val_example(
input clk_i,
input [7:0] x_i [3:0],
input x_val_i,
output logic [7:0] pipe_res_o,
output logic pipe_res_val_o
);
logic [7:0] s1 = '0;
logic [7:0] s2 = '0;
logic x_val_d1 = 1'b0;
logic x_val_d2 = 1'b0;
always_ff @( posedge clk_i )
begin
x_val_d1 <= x_val_i;
x_val_d2 <= x_val_d1;
end
always_ff @( posedge clk_i )
begin
s1 <= x_i[0] + x_i[1];
s2 <= x_i[2] + x_i[3];
pipe_res_o <= s1 + s2;
end
assign pipe_res_val_o = x_val_d2;
endmodule

Согласитесь, сразу же стало нагляднее, что здесь происходит: в какой такт данные на входе и выходе оказываются валидными?
Пару замечаний:
- В этот пример было бы неплохо добавить reset, что бы он сбрасывал x_val_d1/d2.
- Несмотря на то, что данные невалидны, сумматоры их всё равно складывают и кладут данные в регистры. С другой стороны, можно было бы разрешать сохранять в регистры только тогда, когда данные валидны. В этом примере сохранение невалидных данных ни к чему плохому не приводит: я разрешение работы и не добавлял. Однако, если есть необходимость оптимизировать по потребляемой мощности, то придется добавить такие сигналы и попросту ток не гонять :).
Подумать об отправителе и получателе данных
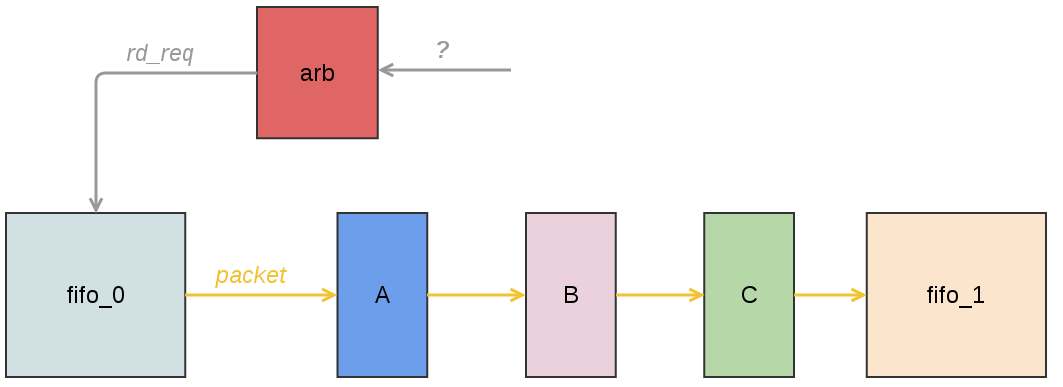
Чаще всего при разработке сразу ясно, что необходимо построить конвейер для достижения нужной частоты. Когда конвейер пишется с нуля, необходимо подумать об архитектуре, к примеру, решить когда можно отправлять данные на конвейер. В качестве иллюстрации приведу типичную архитектуру конвейера обработки Ethernet-пакета.

Легенда:
- fifo_0, fifo_1 — фифошки для размещения данных пакета. В этом примере подразумевается, что перед началом чтения из fifo_0 весь пакет уже там размещен, а логика за fifo_1 не требует целого пакета для начала обработки.
- arb — арбитр, который решает когда вычитывать данные из fifo_0 и подавать на вход модуля A. Вычитывание производится выставлением сигнала rd_req (read request).
- A, B, C — абстрактные модули, которые образуют конвейерную цепочку. Совершенно не обязательно, что каждый модуль обрабатывает данные один такт. Модули внутри тоже могут быть конвейеризированы. Они выполняют какую-то обработку пакета, к примеру, образуют систему парсеров или проводят модификацию пакета (например, подменяют MAC-адреса источника или получателя).
В этом примере fifo_0 является отправителем данных, а fifo_1 — получателем. Допустим, что по каким-то причинам из fifo_1 не всегда вычитываются данные или скорость чтения данных меньше, чем скорость записи, в итоге, это фифо может переполниться. Не надо писать в полную фифошку, т.к., как минимум, вы сломаете пакет (из пакета может пропасть какой-то набор данных) и некорректно его передадите.
Что fifo может сообщить?
- used_words — количество использованных слов. Зная размер фифошки, можно рассчитать количество свободных слов. В этом примере считаем, что одно слово равно одному байту.
- full и almost_full — сигналы о том, что фифо уже заполнилось, либо «почти» заполнилось. «Почти» определяется настраиваемой границей использованных слов.
Чтобы не ломались данные, нам надо когда-то не вычитывать данные пакета из fifo_0 и приостанавливать работу конвейера. Как это сделать?
Алгоритм в лоб
Допустим, мы выделили fifo_1 под MTU, к примеру, 1500 байт. Перед началом чтения пакета из fifo_0 arb смотрит на количество свободных байт в fifo_1. Если оно больше, чем размер текущего пакета, то выставляем rd_req и не снимаем до конца пакета. Иначе ждем пока фифо не освободится.
Плюсы:
- Арбитраж относительно простой и быстро делается.
- Меньше граничных условий для проверки.
Минусы:
- fifo_1 надо выделять под MTU. А если у вас MTU 64K, то пара таких фифо отожрет вам пол-FPGA) Иногда без фифо под пакет нельзя обойтись, но лучше ресурсы экономить.
- Если конвейер простаивает, т.к. места на целый пакет не хватает, то мы теряем в производительности. Если говорить более точно, то худший случай (переполнение fifo_0, в которую тоже кто-то кладет пакеты) наступает быстрее.
Примечание:
При расчете свободного места надо сделать запас на длину конвейера. К примеру, прямо сейчас в fifo_1 свободно 100 байт, к нам пришел пакет 95 байт. Смотрим, что 100 больше 95 и начинаем пересылать пакет. Это не совсем верно, т.к. мы не знаем текущего состояния конвейера — если мы обрабатываем предыдущий пакет, то в худшем случае в fifo_1 дополнительно запишутся еще слова в количестве длины конвейера (в тактах). Если конвейер работает 10 тактов, то еще 10 слов попадут в fifo_1, и фифо может переполниться, когда мы будем писать пакет из 95 байт.
Улучшение «алгоритма в лоб»
Зарезервируем в fifo_1 количество слов равное длине конвеера. Используем сигнал almost_full.
Арбитр каждый такт смотрит на этот сигнал. Если он равен 0, то мы вычитываем одно слово пакета, иначе — нет.
Плюсы:
- fifo_1 может быть не очень большой, к примеру, на пару десятков слов.
Минусы:
- Модули A, B, C должны быть готовы к тому, что пакет будет приходить не каждый такт, а по частям. Если более формально: сигнал валидности внутри пакета может прерываться.
- Необходимо проверить больше граничных условий.
- Если добавятся новые стадии конвейера (следовательно, увеличиться его длина), то можно забыть уменьшить верхнюю границу в fifo_1. Либо необходимо как-то параметром эту границу высчитывать, что может быть нетривиально.
Остановка конвейера во время работы
У предыдущих вариантов есть общая черта: если слово пакета попало в начало конвейера, то уже ничего не сделать: через константное количество тактов это слово (либо его модификация) попадет в fifo_1.
Альтернативный вариант заключается в том, что конвейер можно останавливать во время работы. У каждой стадии с номером M появляется вход ready, который показывает, готова ли стадия M+1 принимать данные или нет. На вход самой последней стадии заводится инверсия full или almost_full (если есть желание немного перестраховаться).

Плюсы:
- Можно безболезнено добавлять новые стадии конвейера.
- У каждой стадии теперь могут появится нюансы в работе, но нет нужды переделывать архитектуру. К примеру: мы захотели добавить в пакет какой-то VLAN-tag, перед тем как положить пакет в fifo_1. VLAN-tag — это 4 байта, в нашем случае — 4 слова. Если пакеты идут друг за другом, то в первых двух случаях arb должен был понять, что надо после конца пакета сделать паузу в 4 такта, т.к. пакет увеличится на 4 слова. В этом случае всё само отрегулируется и модуль, который вставляет VLAN в момент его вставки выставит ready, равным нулю, на стадию конвейера, которая стоит перед ним.
Минусы:
- Код становится более сложным.
- При верификации необходимо проверить еще больше граничных условий.
- Скорее всего занимает больше ресурсов, чем предыдущие варианты.
Использовать стандартизованные интерфейсы
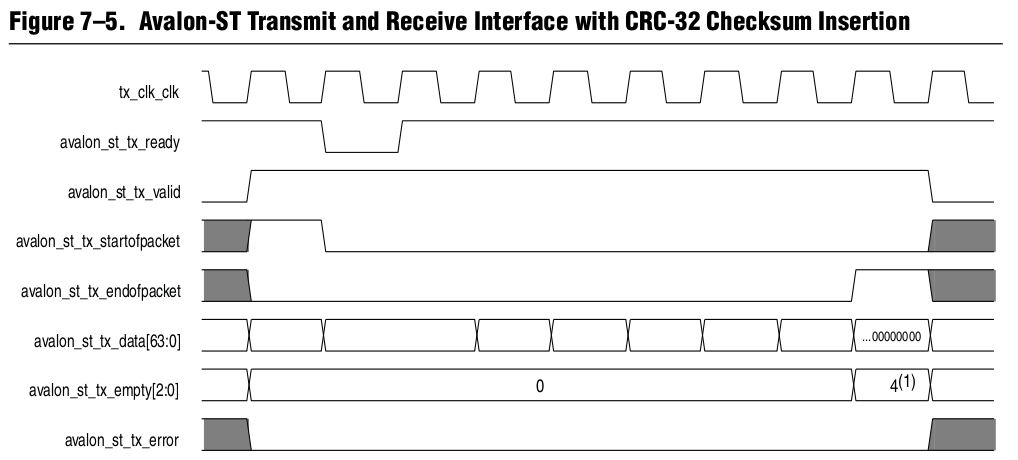
Вышеописанные проблемы можно разрешить используя интерфейсы, в которых уже заложены вспомогательные сигналы. Альтера для потоков данных предлагает использовать интерфейс Avalon Streaming (Avalon-ST). Его подробное описание можно найти тут. Кстати, именно этот интерфейс используется в Альтеровских 10G/40G/100G Ethernet MAC-ядрах.

Сразу обращает на себя внимание наличие сигналов valid и ready, о которых мы говорили ранее. Сигнал empty показывает количество свободных (неиспользуемых) байт в последнем слове пакета. Сигналы startofpacket и endofpacket определяют начало и конец пакета: удобно использовать эти сигналы для сбросов различных счетчиков, которые отсчитывают оффсеты для выцепления нужных данных.
Xilinx предлагает использовать AXI4-Stream для этих целей.

В целом, набор сигналов похож (на этой картинке не все сигналы, возможные доступные в этом стандарте). Если честно, AXI4-Stream я никогда не использовал. Если кто-то использовал оба интерфейса, буду признателен, если поделитесь сравнением и впечатлениями.
Думаю, плюсы использования стандартных интерфейсов упоминать не надо. Ну, и минусы очевидны: необходимо соблюдать стандарт, что выражается в большем количестве кода, ресурсов, тестов и пр. Конечно, можно делать свои велосипеды, но в перспективе на большом проекте (и топовых чипах) это может вылезти боком.
Бонус
В качестве примера посложнее чем пара сумматоров предлагаю сделать модуль, который в Ethernet-пакете меняет местами MAC-адреса источника и получателя (mac_src и mac_dst). Это может полезным, если есть желание весь трафик, который приходит на девайс отправить обратно (так называемый заворот трафика/шлейф или loopback). Реализация, конечно же, должна быть сделана конвейером.
Используем интерфейс Avalon-ST с 64-битной шиной данных (для 10G) без сигналов ready и error. В качестве тестового пакета возьмем тот, который смотрели на xgmii в предыдущей статье. Тогда:
- mac_dst — 00:21:CE:AA:BB:CC (байты с 0 по 5). Располагается в 0 слове в байтах 7:2.
- mac_src — 00:22:15:BF:55:62 (байты с 6 по 11). Располагается в 0 слове в байтах 1:0 и в 1 слове в байтах 7:4.
Код на SystemVerilog под спойлером:
Скрытый текст
module loop_l2(
input clk_i,
input rst_i,
input [7:0][7:0] data_i,
input startofpacket_i,
input endofpacket_i,
input [2:0] empty_i,
input valid_i,
output logic [7:0][7:0] data_o,
output logic startofpacket_o,
output logic endofpacket_o,
output logic [2:0] empty_o,
output logic valid_o
);
logic [7:0][7:0] data_d1;
logic startofpacket_d1;
logic endofpacket_d1;
logic [2:0] empty_d1;
logic valid_d1;
logic [7:0][7:0] data_d2;
logic [7:0][7:0] new_data_c;
always_ff @( posedge clk_i or posedge rst_i )
if( rst_i )
begin
data_d1 <= '0;
startofpacket_d1 <= '0;
endofpacket_d1 <= '0;
empty_d1 <= '0;
valid_d1 <= '0;
data_o <= '0;
startofpacket_o <= '0;
endofpacket_o <= '0;
empty_o <= '0;
valid_o <= '0;
data_d2 <= '0;
end
else
begin
data_d1 <= data_i;
startofpacket_d1 <= startofpacket_i;
endofpacket_d1 <= endofpacket_i;
empty_d1 <= empty_i;
valid_d1 <= valid_i;
data_o <= new_data_c;
startofpacket_o <= startofpacket_d1;
endofpacket_o <= endofpacket_d1;
empty_o <= empty_d1;
valid_o <= valid_d1;
data_d2 <= data_d1;
end
always_comb
begin
new_data_c = data_d1;
if( startofpacket_d1 )
begin
new_data_c = { data_d1[1:0], data_i[7:4], data_d1[7:6] };
end
else
if( startofpacket_o )
begin
new_data_c[7:4] = data_d2[5:2];
end
end
endmodule
Не всё так страшно, как могло показаться ранее: большая часть строчек ушла на описание входов/выходов модуля и линии задержки. По startofpacket определяем в каком слове мы находимся, и какие данные надо подставлять в комбинационку new_data_c, которая потом защелкивается в data_o. Сигналы startofpacket, endofpacket, empty, valid задерживаются на нужное количество тактов.
Симуляция модуля:

Как видим, MAC-адреса поменялись местами, а все остальные данные в пакете не изменились.
В следующей статье мы разберем квадродерево: более серьезный пример конвейеризации, где задействуем одну из архитектурных особенностей FPGA — блочную память.
Спасибо за уделенное время и внимание! Если появились вопросы, задавайте без сомнений.
Список литературы
- Advanced FPGA Design — одна из лучших книг по FPGA, что я видел. В главе 1 подробно разобрана конвейеризация. ИМХО, книга для тех, кто уже получил какой-то опыт в FPGA разработке и хочет систематизировать свои знания либо какие-то интуитивные догадки.
- TimeQuest Timing Analyzer — приложение для оценки значения таймингов (в том числе Fmax) для FPGA фирмы Altera.
P.S. Благодарю des333 за конструктивную критику и советы.
