Работая над очередным игровым (обучающим) проектом ПЛИС для платы Марсоход2 я столкнулся с тем, что мне явно не хватает места в кристалле. Кажется и проект не очень сложный, но моя реализация такова, что требует много логики. В принципе, это ерунда, дело-то житейское. Ну, если очень будет нужно, то можно выбрать ПЛИС с большей емкостью. Собственно мой проект — это игра «Жизнь», но реализованная в ПЛИС на языке Verilog HDL.
Про логику игры, рассказывать не буду, про нее и так написано уже достаточно.
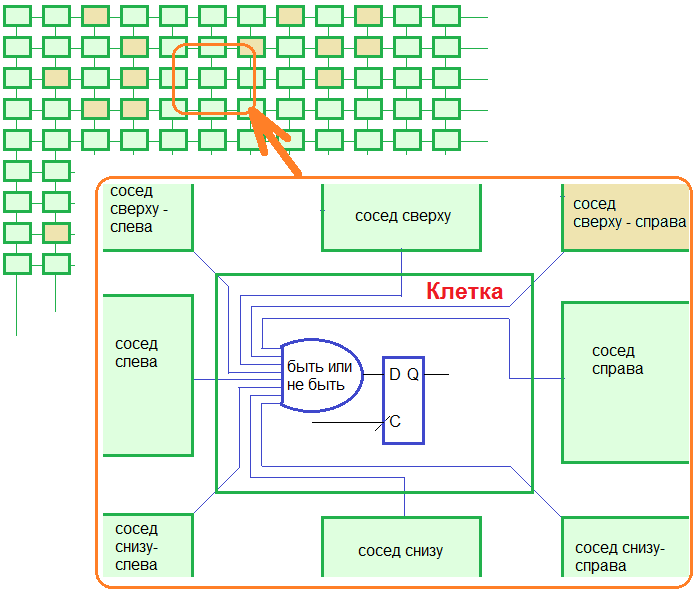
Идея проекта вот такая: каждая клетка в игровом поле представляет собой самостоятельный вычислитель. В каждом вычислителе есть своя логическая функция и свой регистр, который хранит текущее состояние клетки (живая/не живая). Все пространство для жизни клеток — это двумерный массив вычислителей, вычислители образуют целую сеть. Все вычислители работают синхронно, так как на все регистры подается единая тактовая частота. Рисунок вверху должен прояснить схему проекта.
Так вот. На моей плате стоит ПЛИС Cyclone III EP3C10E144C8 компании Альтера. 10тыс логических элементов. Сперва я думал, что смогу сделать двумерный массив клеток 128x64=8192 клетки. Не помещается. 64x64=4096 — то же не помещается в кристалл. Как же так. Я сумел вместить в ПЛИС только 32x16=512 клеток. Пичалька…
Размышления приводят меня к мысли, что возможно, в будущем, технология ПЛИС перерастет в нечто большее, чем программируемая логика. Вот об этом своем видении я хотел бы рассказать. Искушенному читателю сразу скажу, что многое далее написанное есть просто плод воображения и может быть даже бред.
Однако..
В настоящее время технология ПЛИС используется довольно узким кругом специалистов. В основном FPGA используются для прототипирования микросхем и для мелкосерийных изделий, когда изготовление микросхем ASIC экономически нецелесообразно. Специалистов по FPGA, я думаю, не очень много. Технология довольно сложная и требует многих специфических знаний. С другой стороны, для организации высокоскоростных и параллельных вычислений ПЛИС — это пожалуй самая подходящая технология.
Мы знаем, например, что компания Альтера предлагает и продвигает технологию OpenCL
Просто говоря — это такой C-подобный язык для описания параллельных вычислений в FPGA акселераторе. Кстати, Nvidia и ее видеокарты так же поддерживают параллельные вычисления c OpenCL.
Таким образом, видно, что Альтера явно задумываются о том, как донести «обычные» C-подобные параллельные вычисления FPGA в народ. Посмотрим, что там с ценами на платы для параллельных вычислений с FPGA? Плата Terasic DE5-Net.
25 пользователям нравится цена 8 тыс баксов (шучу).
Есть и другие попытки привезти FPGA в народ — Altera выпустила совместно с Intel микросхему серии E6x5C, где в едином корпусе соединен процессор Atom и ПЛИС Arria II. Хорошая попытка, но технология так кажется и не смогла найти массового потребителя.
Видимо существующие кристаллы ПЛИС плохо вписываются в современную парадигму программирования.
А какая у нас сейчас современная парадигма «нормального» программирования?
Мне кажется, что как-то так:
- на компьютере всегда одновременно исполняется несколько вычислительных процессов и потоков
- состояние процессов и потоков хранится в памяти, процесс может запросить у ОС столько памяти, сколько нужно; можно даже попросить больше, чем есть физической памяти — и процесс может реально получить эту виртуальную память.
- вычисления производятся процессором, иногда он имеет много ядер. Обычно процесс или поток не знают (или не хотят знать) в каком ядре процессора сейчас исполняется задача.
- более приоритетная задача может вытеснить менее приоритетную задачу. Вытеснить — это значит сохранить состояние страниц памяти вялого процесса на диск и переключиться на более приоритетный процесс. Выделить ему больший слайс времени.
Понятно, что чем больше памяти и чем больше ядер процессора, тем быстрее работают все процессы в системе.
Память и ядра процессора — это ресурсы компьютера, вычислителя, которые операционная система распределяет между процессами.
Теперь представим себе, что в будущем мы получим компьютеры, где на ряду с памятью и ядрами процессора будут иметься в наличии еще блоки логики «как-бы-плис». Этот ресурс «как-бы-плис» по своим свойствам находится где-то между процессором и памятью. С одной стороны «как-бы-плис» = это вычислитель, то есть ближе к процессору, но с другой стороны это и память, ибо в регистрах плис хранится довольно много информации. Состояние вычислителя «как-бы-плис» уже довольно трудно будет сохранить в структуре task_struct при переключении контекста задачи. Но, наверное, можно попытаться вытеснить состояние блоков логики в swap файл, как виртуальную память. И временно ОС может подгрузить другие блоки логики для активного потока…
Кстати, и Altera и Xilinx уже довольно давно имеют FPGA с возможностью частичной перезагрузки отдельных участков, блоков логики (Partial Reconfiguration) — то есть в принципе они как-то идут в эту сторону…
Программист может выделить для процесса столько «как-бы-плис», сколько нужно. Буквально функцией lalloc (logic alloc) по аналогии с malloc (memory alloc). Потом из файла считать туда «прошивку ПЛИС» и она будет жить и работать. Мы, программисты, по большому счету не должны думать есть эта память/логика «как-бы-плис» у системы или ее нет. А не наше это дело. Да, иногда может быть очень медленно при ограниченных ресурсах, но разве мы не знаем как «лагают» видеоигры на слабых видеокартах? Пользователи знают, что за сильное железо придется платить, но хорошо бы, чтоб даже минимальная система уже имела в базовом варианте логические блоки «как-бы-плис» для использования в программах.
На самом деле, конечно, я представляю себе, что такая технология вряд ли скоро появится, слишком все это сложно и не реализуемо. По крайней мере существующие микросхемы ПЛИС мало подходят для этих целей хотя бы потому, что для конфигурирования ПЛИС используются медленные последовательные интерфейсы типа JTAG. Но может быть, когда-то кто-то из нас сделает это?
ЗЫ: кстати, а вот и моя игра жизнь в ПЛИС, такая маленькая, 32x16… ну нет у меня виртуальной
ЗЫ2: все исходники и подробное описание проекта игры Жизнь можно взять здесь.
