Как только Google Analytics или Яндекс.Метрика публикуют новость о новом отчёте, метрике или обновлении интерфейса и всё сообщество ликует, я испытываю лёгкое головокружение. Но не от радости. Для меня это сигнал о том, что в ближайшее время вместо того, чтобы работать над качеством продукта, мы начнем изучать системы аналитики. Погоня за количеством данных вытеснила стремление к качеству анализа на задворки потребностей. Точность стала важнее тренда, а на сайтах теперь стоят по 3-5 счётчиков от разных систем аналитики.

Данных много не бывает? Ещё как бывает. Вспомните про парадокс данных, который отлично сформулировал Авинаш Кошик. Недостаток данных не позволяет принимать решения, но и изобилие не даёт представление о том, что происходит.
Так не пора ли приступить к поискам ответов? Я расскажу об универсальном методе, который помогает мне делать выводы, а еще приносит огромное удовольствие в работе с информацией. Чтобы далекие от интернет-маркетинга и веб-аналитики пользователи не заскучали, для примера я взяла тему из нашей с вами повседневной реальности.
Работа с данными состоит из нескольких этапов, но необходимости соблюдать строгую последовательность нет: приходится то и дело возвращаться к предыдущим этапам и забегать вперед.
1. Подготовка
– Формулировка вопросов.
– Выбор источника.
– Сбор данных.
– Изучение.
– Очистка данных и принятие допущений.
2. Анализ
– Поиск ответов на поставленные вопросы.
– Поиск закономерностей.
– Поиск зависимостей.
3. Демонстрация результата
– Визуализация данных.
– Демонстрация решений, ответов.
Поехали!
Данные – это ловушка для ума. Они заманивают в лес цифр и легко могут сбить с верного пути. Для того, чтобы не отклоняться от цели, задайте вопрос, на который хотите получить ответ. Сформулируйте его в свободной форме и запишите на бумаге. Пусть это будет простой вопрос «Хорошо или плохо продаёт мой сайт?» или «Куда исчезли покупатели с сайта?». Дальше разбейте общий вопрос на подвопросы и допишите их в список. Например, к вопросу о продажах на сайте будет уместен подвопрос: какие товары продаются хорошо, какие плохо. Не забудьте оставить на листе бумаги пустое место, вполне возможно, что на последующих этапах вам захочется дополнить список.
Мои вопросы:
Какова внешняя политика России в последние годы?
(Я предупреждала, что данные возьму из реальной жизни).
Подвопросы:
Меня интересуют внешнеполитические процессы после Мюнхенской конференции с февраля 2007 по сентябрь 2014. Вопросы сформулировала, теперь отправляемся на поиск источника.
Ключевое требование к источнику: составляющие его данные должны быть релевантными и однородными.
Релевантные означают то, что они содержат необходимый и достаточный минимум информации для ответа на поставленные вопросы, а также близки первоисточнику.
В исторической науке есть целая отрасль, которая называется источниковедением. Она занимается классификацией и анализом источников и оперирует понятиями первичного и вторичного источника. Для получения максимально достоверных результатов важно пользоваться первоисточниками – сообщениями «из первых рук», не обработанными кем-то извне. Так например данные из Википедии о событиях во внешней политике не являются первоисточником. Первоисточником могут быть протоколы встреч первых лиц с датами встреч и списком участников.
Второе требование к данным – это однородность. Наличие общих свойств, природа которых неизменна для всего множества объектов, – обязательное условие. Другими словами, данные должны быть качественно однородными по своему составу. Не корректно сравнивать и складывать метрики из Яндекс.Метрики и Google Analytics, так как способы их обработки могут быть разными. Хотя я довольно часто наблюдаю обратную картину.
Вернемся к внешней политике. За источник данных я взяла официальные сообщения о значимых внешнеполитических мероприятиях с участием России с сайта kremlin.ru. Несмотря на то, что официальные пресс-релизы не являются первичными источниками, мы можем их использовать в работе. Они максимально близки к первоисточнику. Публикации с одной стороны отражают качество работы контент-менеджера и PR-службы Кремля, с другой имеют прямое отношение к происходящим событиям.
1) Данные из архива в разделе Внешняя политика
2) Новости по тегу «внешняя политика» (с 08.05.2008 по 14.10.2014)
Забегу вперёд и скажу, что мне придётся отказаться от использования первого источника. C сентября 2009 года архив перестал пополняться новостями, к тому же в первом и во втором случаях использовались разные принципы описания новостей.
После того, как мы определились с источником, приступаем к самой сложной и важной части работ: сбору данных.
Я попросила программиста спарсить разделы сайта в таблицу CSV, чтобы в дальнейшем было удобно работать с записями в Excel. Вы же вольны выбирать любые удобные для вас средства анализа данных.
Важная деталь: необходимо использовать реляционную модель организации данных.
Проще говоря, каждая новая запись должна располагаться в новой строке, атрибуты помещаться в столбцах и принадлежать одному типу данных (дата, текст, число и др.). Мы ведь стремимся к созданию однородной и качественной базы данных.
В моём примере записью в строке является уникальная публикация на тему внешнеполитических мероприятий. В Excel она выглядит как запись в строке с атрибутами: дата события, тип события, участник/участники события.
Парсинг двух разделов дался нам нелегко: сайт отдавал ошибку 402 Payment Required, 6 объектов куда-то потерялись, около 3 500 записей оказались в нашем распоряжении. Если потерю в 0,18% данных можно допустить, то факт, что на руках две таблицы из разных источников и с разными атрибутами, игнорировать было нельзя. При их объединении принцип однородности данных был бы нарушен, поэтому мне пришлось дополнительно сравнивать пересекающиеся периоды из обоих источников, и в конце концов я решила убрать первый источник. В конце концов мы получили 3326 записей о событиях за период с 08.05.2008 по 14.10.2014.
Теперь полученные данные необходимо изучить. Excel располагает простыми и удобными инструментами: группировками, фильтрами, сортировками, сводными таблицами, которых вполне достаточно для большинства задач. Я с интересом просмотрела содержание ячеек и обратила внимание на повторяющиеся названия мероприятий в заголовках новостей. С завидным постоянством встречались публикации о встречах, телефонных переговорах, подписании документов, церемониях. К записям напросился новый атрибут «тип события», я создала ещё один столбец и заполнила его соответствующими значениями.

Важно отметить, что не все события трактовались однозначно. Например, сообщение о начале встречи и сообщение о переговорах на встрече я отнесла к одному типу мероприятия «Встреча», а значит об одном мероприятии в нашей базе могло быть несколько записей. Принятые допущения были зафиксированы и применены ко всем данным.
Исследуемый период с 08.05.2008 по 14.10.2014 захватывает президентства В.В. Путина и Д.А. Медведева. Напомню даты:
В.В. Путин – 07.05.2000 – 07.05.2008
Д.А. Медведев – 07.05.2008 – 07.05.2012
В.В. Путин – 07.05.2012 – н.в.
Этот этап работ оказался самым продолжительным и ответственным. Я не один раз прогоняла данные через фильтры, группировала записи, проверяла корректность значений, типов данных, в итоге добилась необходимой однородности и корректности.
Сразу после подготовки данных важно сделать перерыв и вернуться в начало – к вопросам, которые мы сформулировали. Часто происходит так, что к этому моменту мысль уходит далеко за пределы текущего исследования, поэтому возврат в начало становится наилучшим способом не упустить важное.
Теперь мы близки к тому, чтобы строить выводы. На этапе анализа важно избегать предвзятости. Приступать к исследованию с желанием доказать готовую гипотезу можно, но не стоит забывать о возможном существовании альтернатив. Пытаясь доказать, что показатель отказов вырос из-за плохого трафика, мы никогда не обнаружим падение скорости загрузки сайта после недавнего релиза.
Еще одно предостережение касается поиска зависимостей и закономерностей. Нам очень хочется узнать, как одно значение влияет на другое, потому что в нашем обыденном представлении причина и следствие ходят парой. Но социальные явления, а поведение пользователей на сайте тоже к ним относится, характеризуются множественностью причин и следствий. Даже когда мы видим на графике две похожие по форме кривые, которые отражают разные признаки одного явления, между ними может не быть никакой взаимосвязи. Любые выводы о наличии корреляционной зависимости между значениями всегда носят вероятностный характер.
А теперь приступим к нашим ответам на вопросы о внешней политике.
Какова активность России во внешней политике на протяжении последних лет.
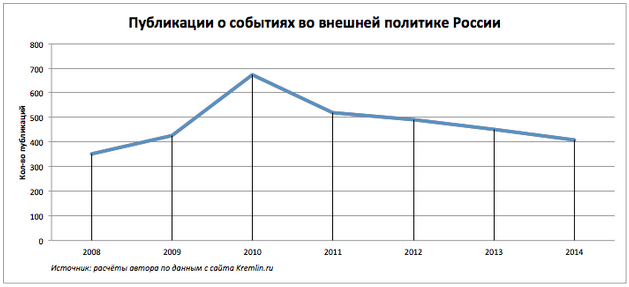
В 2010 году вышло максимальное количество новостей на внешнеполитическую тему.
Каков список стран, с которыми Россия взаимодействовала чаще всех. Я составила список топ-5 стран, о которых накоплено максимальное количество сообщений за исследуемый период. Будем держать прицел на ключевых участниках международных отношений. Если вдруг кто-то исчезнет из выборки на последующих этапах – это послужит сигналом проверить данные ещё раз или задать новый вопрос.

Какие самые популярные типы событий упоминались в новостях и есть ли какие-то особенности или изменения на протяжении всего периода.
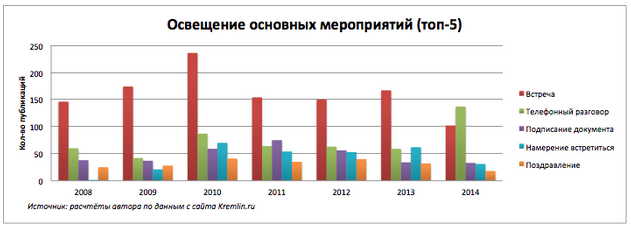
Количество пресс-релизов о встречах в 2010 году максимальное. В 2014 году заметно резкое увеличение количества сообщений о состоявшихся телефонных переговорах.
Российские политики стали больше разговаривать и меньше встречаться. Оперативные и срочные задачи требуют меньше церемоний.
Интересно, с какими странами и организациям выросло количество телефонных переговоров в 2014 году. Я выбрала участников с максимальным количеством сообщений о телефонных разговорах за 2014 год.
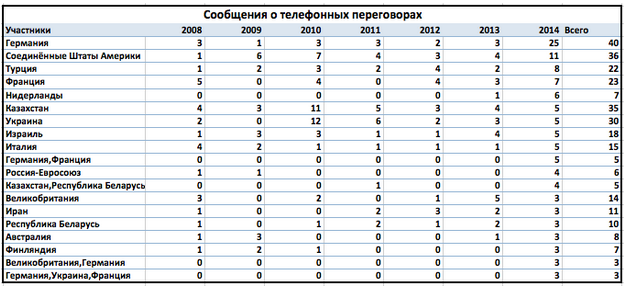
В 2014 году наблюдаем уникальные составы участников телефонных переговоров и рост прямых контактов с рядом стран. Из ключевых участников международных отношений в списке отсутствует Китай, позже выясним, с чем это может быть связано.
Построим график количества сообщений по странами с учётом многосторонних телефонных переговоров.
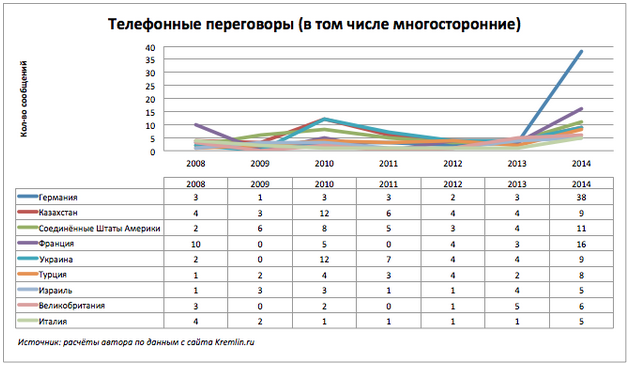
Заметно увеличение телефонных разговоров с Германией, Францией и США.
Что же со встречами? Возьмем лидирующие по встречам страны и посмотрим на общую картину.
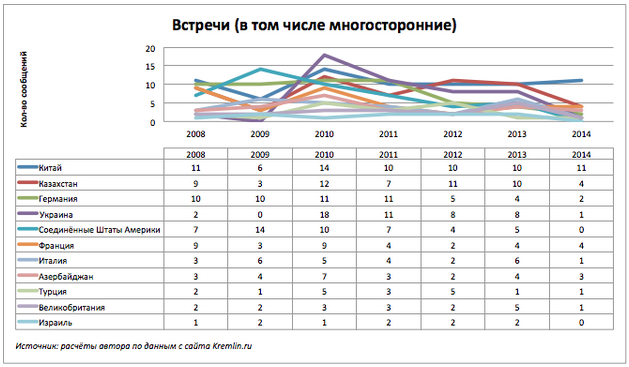
График не самый показательный, но из таблицы с данными видно, что на 14.10.2014 нет ни одного сообщения о встречах России с США и Израилем.
Интересен характер взаимодействий России с конкретными странами. Продолжим рассматривать два ключевых мероприятия встречи и телефонные разговоры по странам.
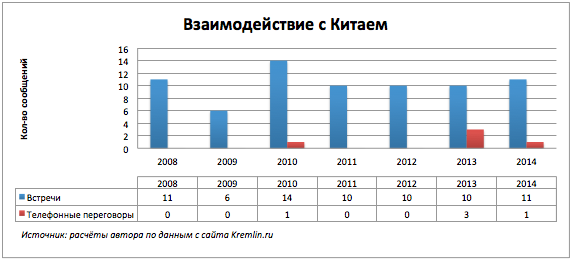
Наш восточный сосед не любит болтовню по телефону.
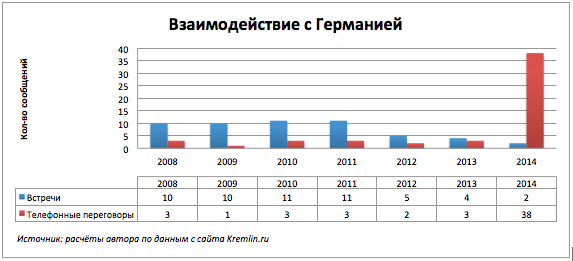
Телефонные звонки за текущий год побили все рекорды.
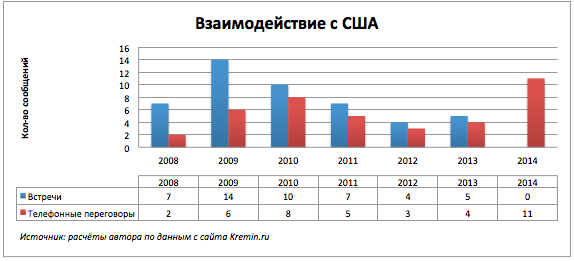
Уже конец года и никаких встреч.
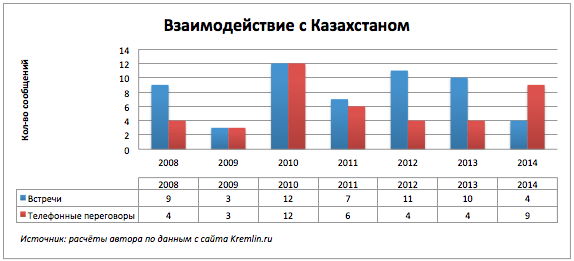
Скачкообразные изменения.
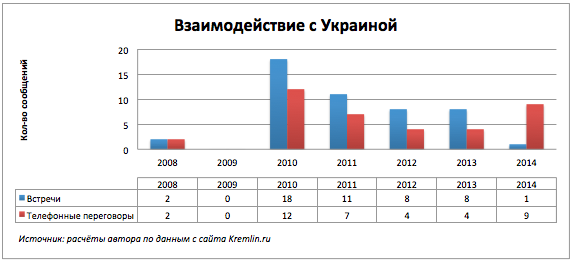
В 2009-ом году полный штиль. Отсутствие сообщений вероятно связано с газовым конфликтом между Россией и Украиной в 2008-2009.
Вы, возможно, обратили внимание на то, что в столбце «участники» у нас несколько типов значений: с указанием одной и нескольких стран через запятую или стран и организаций.
Встречи между политиками бывают двусторонними и многосторонними. Интересно взглянуть на то, с какими странами Россия встречается чаще на двусторонних переговорах, с какими на многосторонних.
Для этого я дополнила данные ещё одним атрибутом: коэффициентом, равным отношению общего количества встреч к количеству двусторонних. Те страны, которые окажутся ниже среднего, по большей части ведут переговоры на двусторонних встречах; те, что выше среднего, участвуют активно в многосторонних.
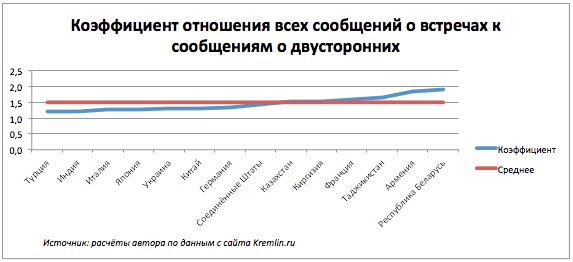
Нет ничего удивительного в том, что страны СНГ оказались ближе к точке пересечения и выше среднего – они принимают участие в совместных форумах и саммитах. Но вот что в их компании забыла Франция? Я сделала сводную таблицу по всем мероприятий с участием Франции за весь период, и оказалось, что Франция была третьей стороной в переговорах по разрешению Грузино-южноосетинского конфликта 2008 года.
***
Конечно, можно ещё массу интересных вещей вытащить из этих данных, но ответы на вопросы я получила, значит, цель достигнута. Даже больше: теперь у меня всегда под рукой информация для более глубокого понимания текущей ситуации во внешней политике. Как видите, если перестать коллекционировать цифры и начать задавать конкретные вопросы, данные отвечают на языке полезных и интересных выводов.
Напоследок расскажу мою любимую историю о первом месте работы Авинаша Кошика. Будущий мировой эксперт в области веб-аналитики пришёл в компанию, где были настроены 200 отчётов. Через месяц после своего прихода Авинаш Кошик отключил их все. Прошло две недели, а пропажи так никто и не заметил.
upd. Обещанные файлы
1. Исходник
2. Обработка
пароль на открытие: habr2014

Данных много не бывает? Ещё как бывает. Вспомните про парадокс данных, который отлично сформулировал Авинаш Кошик. Недостаток данных не позволяет принимать решения, но и изобилие не даёт представление о том, что происходит.
Так не пора ли приступить к поискам ответов? Я расскажу об универсальном методе, который помогает мне делать выводы, а еще приносит огромное удовольствие в работе с информацией. Чтобы далекие от интернет-маркетинга и веб-аналитики пользователи не заскучали, для примера я взяла тему из нашей с вами повседневной реальности.
Основные этапы работы с данными
Работа с данными состоит из нескольких этапов, но необходимости соблюдать строгую последовательность нет: приходится то и дело возвращаться к предыдущим этапам и забегать вперед.
1. Подготовка
– Формулировка вопросов.
– Выбор источника.
– Сбор данных.
– Изучение.
– Очистка данных и принятие допущений.
2. Анализ
– Поиск ответов на поставленные вопросы.
– Поиск закономерностей.
– Поиск зависимостей.
3. Демонстрация результата
– Визуализация данных.
– Демонстрация решений, ответов.
Поехали!
Подготовка
Формулировка вопросов
Данные – это ловушка для ума. Они заманивают в лес цифр и легко могут сбить с верного пути. Для того, чтобы не отклоняться от цели, задайте вопрос, на который хотите получить ответ. Сформулируйте его в свободной форме и запишите на бумаге. Пусть это будет простой вопрос «Хорошо или плохо продаёт мой сайт?» или «Куда исчезли покупатели с сайта?». Дальше разбейте общий вопрос на подвопросы и допишите их в список. Например, к вопросу о продажах на сайте будет уместен подвопрос: какие товары продаются хорошо, какие плохо. Не забудьте оставить на листе бумаги пустое место, вполне возможно, что на последующих этапах вам захочется дополнить список.
Мои вопросы:
Какова внешняя политика России в последние годы?
(Я предупреждала, что данные возьму из реальной жизни).
Подвопросы:
- Какова активность России во внешней политике на протяжении последних лет?
- С какими странами Россия наиболее активно взаимодействует?
- Как изменялись предпочтения во взаимодействиях с другими странами?
Меня интересуют внешнеполитические процессы после Мюнхенской конференции с февраля 2007 по сентябрь 2014. Вопросы сформулировала, теперь отправляемся на поиск источника.
Выбор источника данных
Ключевое требование к источнику: составляющие его данные должны быть релевантными и однородными.
Релевантные означают то, что они содержат необходимый и достаточный минимум информации для ответа на поставленные вопросы, а также близки первоисточнику.
В исторической науке есть целая отрасль, которая называется источниковедением. Она занимается классификацией и анализом источников и оперирует понятиями первичного и вторичного источника. Для получения максимально достоверных результатов важно пользоваться первоисточниками – сообщениями «из первых рук», не обработанными кем-то извне. Так например данные из Википедии о событиях во внешней политике не являются первоисточником. Первоисточником могут быть протоколы встреч первых лиц с датами встреч и списком участников.
Второе требование к данным – это однородность. Наличие общих свойств, природа которых неизменна для всего множества объектов, – обязательное условие. Другими словами, данные должны быть качественно однородными по своему составу. Не корректно сравнивать и складывать метрики из Яндекс.Метрики и Google Analytics, так как способы их обработки могут быть разными. Хотя я довольно часто наблюдаю обратную картину.
Вернемся к внешней политике. За источник данных я взяла официальные сообщения о значимых внешнеполитических мероприятиях с участием России с сайта kremlin.ru. Несмотря на то, что официальные пресс-релизы не являются первичными источниками, мы можем их использовать в работе. Они максимально близки к первоисточнику. Публикации с одной стороны отражают качество работы контент-менеджера и PR-службы Кремля, с другой имеют прямое отношение к происходящим событиям.
1) Данные из архива в разделе Внешняя политика
2) Новости по тегу «внешняя политика» (с 08.05.2008 по 14.10.2014)
Забегу вперёд и скажу, что мне придётся отказаться от использования первого источника. C сентября 2009 года архив перестал пополняться новостями, к тому же в первом и во втором случаях использовались разные принципы описания новостей.
После того, как мы определились с источником, приступаем к самой сложной и важной части работ: сбору данных.
Сбор, изучение, очистка, допущения
Я попросила программиста спарсить разделы сайта в таблицу CSV, чтобы в дальнейшем было удобно работать с записями в Excel. Вы же вольны выбирать любые удобные для вас средства анализа данных.
Важная деталь: необходимо использовать реляционную модель организации данных.
Проще говоря, каждая новая запись должна располагаться в новой строке, атрибуты помещаться в столбцах и принадлежать одному типу данных (дата, текст, число и др.). Мы ведь стремимся к созданию однородной и качественной базы данных.
В моём примере записью в строке является уникальная публикация на тему внешнеполитических мероприятий. В Excel она выглядит как запись в строке с атрибутами: дата события, тип события, участник/участники события.
Парсинг двух разделов дался нам нелегко: сайт отдавал ошибку 402 Payment Required, 6 объектов куда-то потерялись, около 3 500 записей оказались в нашем распоряжении. Если потерю в 0,18% данных можно допустить, то факт, что на руках две таблицы из разных источников и с разными атрибутами, игнорировать было нельзя. При их объединении принцип однородности данных был бы нарушен, поэтому мне пришлось дополнительно сравнивать пересекающиеся периоды из обоих источников, и в конце концов я решила убрать первый источник. В конце концов мы получили 3326 записей о событиях за период с 08.05.2008 по 14.10.2014.
Теперь полученные данные необходимо изучить. Excel располагает простыми и удобными инструментами: группировками, фильтрами, сортировками, сводными таблицами, которых вполне достаточно для большинства задач. Я с интересом просмотрела содержание ячеек и обратила внимание на повторяющиеся названия мероприятий в заголовках новостей. С завидным постоянством встречались публикации о встречах, телефонных переговорах, подписании документов, церемониях. К записям напросился новый атрибут «тип события», я создала ещё один столбец и заполнила его соответствующими значениями.

Важно отметить, что не все события трактовались однозначно. Например, сообщение о начале встречи и сообщение о переговорах на встрече я отнесла к одному типу мероприятия «Встреча», а значит об одном мероприятии в нашей базе могло быть несколько записей. Принятые допущения были зафиксированы и применены ко всем данным.
Исследуемый период с 08.05.2008 по 14.10.2014 захватывает президентства В.В. Путина и Д.А. Медведева. Напомню даты:
В.В. Путин – 07.05.2000 – 07.05.2008
Д.А. Медведев – 07.05.2008 – 07.05.2012
В.В. Путин – 07.05.2012 – н.в.
Этот этап работ оказался самым продолжительным и ответственным. Я не один раз прогоняла данные через фильтры, группировала записи, проверяла корректность значений, типов данных, в итоге добилась необходимой однородности и корректности.
Анализ данных
Сразу после подготовки данных важно сделать перерыв и вернуться в начало – к вопросам, которые мы сформулировали. Часто происходит так, что к этому моменту мысль уходит далеко за пределы текущего исследования, поэтому возврат в начало становится наилучшим способом не упустить важное.
Теперь мы близки к тому, чтобы строить выводы. На этапе анализа важно избегать предвзятости. Приступать к исследованию с желанием доказать готовую гипотезу можно, но не стоит забывать о возможном существовании альтернатив. Пытаясь доказать, что показатель отказов вырос из-за плохого трафика, мы никогда не обнаружим падение скорости загрузки сайта после недавнего релиза.
Еще одно предостережение касается поиска зависимостей и закономерностей. Нам очень хочется узнать, как одно значение влияет на другое, потому что в нашем обыденном представлении причина и следствие ходят парой. Но социальные явления, а поведение пользователей на сайте тоже к ним относится, характеризуются множественностью причин и следствий. Даже когда мы видим на графике две похожие по форме кривые, которые отражают разные признаки одного явления, между ними может не быть никакой взаимосвязи. Любые выводы о наличии корреляционной зависимости между значениями всегда носят вероятностный характер.
А теперь приступим к нашим ответам на вопросы о внешней политике.
Демонстрация результата
Какова активность России во внешней политике на протяжении последних лет.

В 2010 году вышло максимальное количество новостей на внешнеполитическую тему.
Каков список стран, с которыми Россия взаимодействовала чаще всех. Я составила список топ-5 стран, о которых накоплено максимальное количество сообщений за исследуемый период. Будем держать прицел на ключевых участниках международных отношений. Если вдруг кто-то исчезнет из выборки на последующих этапах – это послужит сигналом проверить данные ещё раз или задать новый вопрос.

Какие самые популярные типы событий упоминались в новостях и есть ли какие-то особенности или изменения на протяжении всего периода.
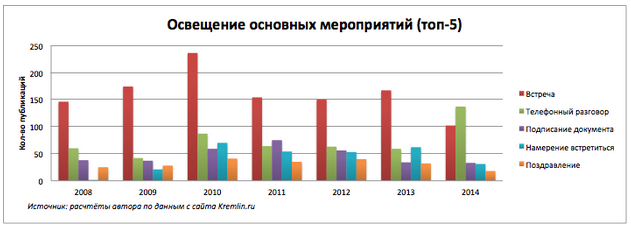
Количество пресс-релизов о встречах в 2010 году максимальное. В 2014 году заметно резкое увеличение количества сообщений о состоявшихся телефонных переговорах.
Российские политики стали больше разговаривать и меньше встречаться. Оперативные и срочные задачи требуют меньше церемоний.
Интересно, с какими странами и организациям выросло количество телефонных переговоров в 2014 году. Я выбрала участников с максимальным количеством сообщений о телефонных разговорах за 2014 год.
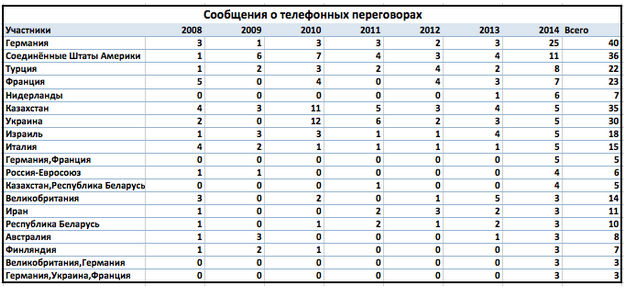
В 2014 году наблюдаем уникальные составы участников телефонных переговоров и рост прямых контактов с рядом стран. Из ключевых участников международных отношений в списке отсутствует Китай, позже выясним, с чем это может быть связано.
Построим график количества сообщений по странами с учётом многосторонних телефонных переговоров.
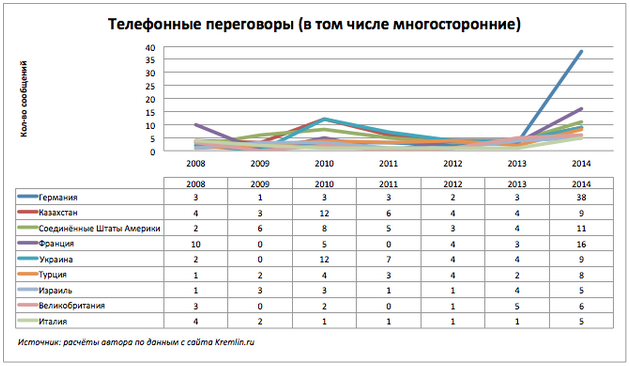
Заметно увеличение телефонных разговоров с Германией, Францией и США.
Что же со встречами? Возьмем лидирующие по встречам страны и посмотрим на общую картину.
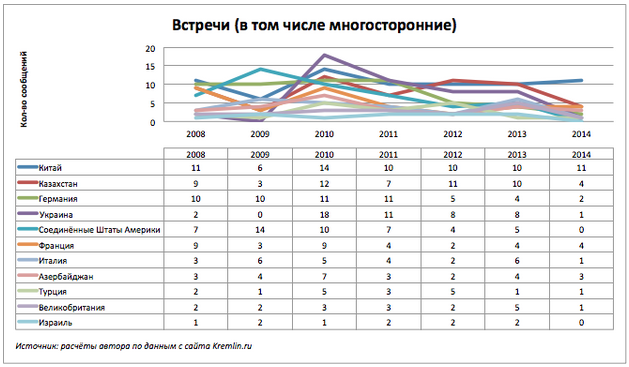
График не самый показательный, но из таблицы с данными видно, что на 14.10.2014 нет ни одного сообщения о встречах России с США и Израилем.
Интересен характер взаимодействий России с конкретными странами. Продолжим рассматривать два ключевых мероприятия встречи и телефонные разговоры по странам.
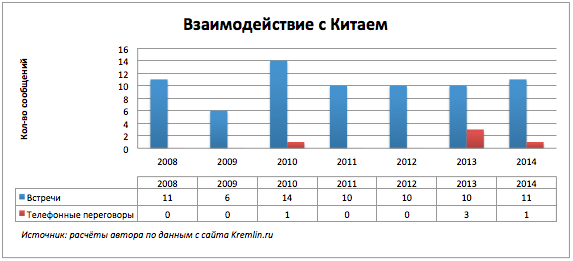
Наш восточный сосед не любит болтовню по телефону.

Телефонные звонки за текущий год побили все рекорды.
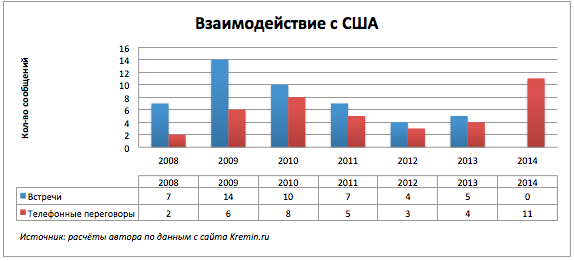
Уже конец года и никаких встреч.
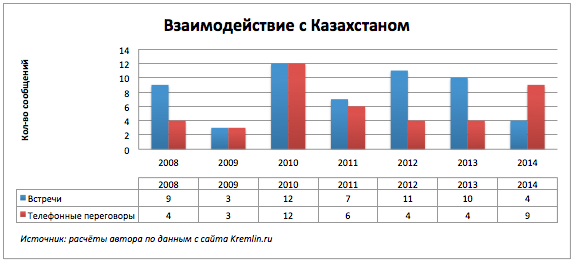
Скачкообразные изменения.
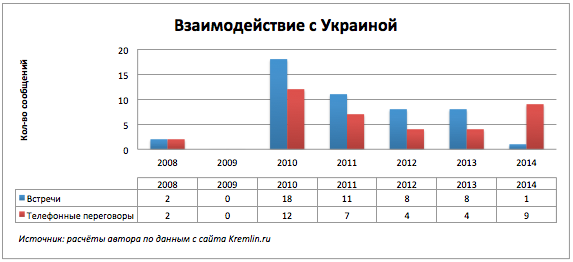
В 2009-ом году полный штиль. Отсутствие сообщений вероятно связано с газовым конфликтом между Россией и Украиной в 2008-2009.
Вы, возможно, обратили внимание на то, что в столбце «участники» у нас несколько типов значений: с указанием одной и нескольких стран через запятую или стран и организаций.
Встречи между политиками бывают двусторонними и многосторонними. Интересно взглянуть на то, с какими странами Россия встречается чаще на двусторонних переговорах, с какими на многосторонних.
Для этого я дополнила данные ещё одним атрибутом: коэффициентом, равным отношению общего количества встреч к количеству двусторонних. Те страны, которые окажутся ниже среднего, по большей части ведут переговоры на двусторонних встречах; те, что выше среднего, участвуют активно в многосторонних.
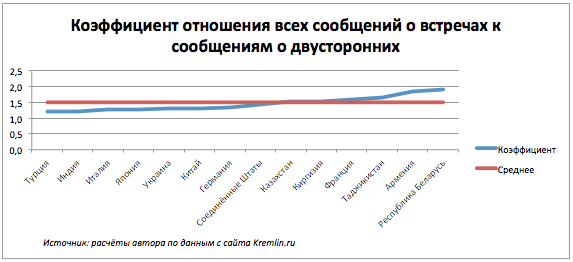
Нет ничего удивительного в том, что страны СНГ оказались ближе к точке пересечения и выше среднего – они принимают участие в совместных форумах и саммитах. Но вот что в их компании забыла Франция? Я сделала сводную таблицу по всем мероприятий с участием Франции за весь период, и оказалось, что Франция была третьей стороной в переговорах по разрешению Грузино-южноосетинского конфликта 2008 года.
***
Конечно, можно ещё массу интересных вещей вытащить из этих данных, но ответы на вопросы я получила, значит, цель достигнута. Даже больше: теперь у меня всегда под рукой информация для более глубокого понимания текущей ситуации во внешней политике. Как видите, если перестать коллекционировать цифры и начать задавать конкретные вопросы, данные отвечают на языке полезных и интересных выводов.
Напоследок расскажу мою любимую историю о первом месте работы Авинаша Кошика. Будущий мировой эксперт в области веб-аналитики пришёл в компанию, где были настроены 200 отчётов. Через месяц после своего прихода Авинаш Кошик отключил их все. Прошло две недели, а пропажи так никто и не заметил.
upd. Обещанные файлы
1. Исходник
2. Обработка
пароль на открытие: habr2014
