Постановка задачи
Выявить узкие места при работе приложения с базами данных. Составить отчёт по производительности sql-запросов, проанализировать ошибки и взаимоблокировки, составить сравнительные отчёты, посчитать степень покрытия состава хранимых процедур тестами, построить диаграммы.
Тестирование проводится регулярно. Поэтому отчёты должны формировать автоматически, быть стандартизованы, легко сравниваться между собой.
Используемые технологии:
- Microsoft SQL Server;
- Microsoft Office Excel;
- Комплекс sql-запросов, организованный в проект SQLProfilerReportHelper;
- Инструмент нагрузочного тестирования с возможностью выполнить sql-запрос (JMeter, Visual Studio Ultimate, ...);
Уровень 300 (для профессионалов).
Если коротко, то порядок действий для формирования отчётов по готовому трейсу таков:
- запустить SQLProfilerReportHelper, кликнуть по кнопкам;
- выполнить выборку записей из таблиц-отчётов, скопировать результаты в буфер обмена;
- запустить Microsoft Office Excel, вставить записи из буфера в автоматически форматируемую таблицу и сохранить документ-отчёт.
Инструмент и шаблон отчёта доступны для скачивания SQLProfilerReportHelper.
Если вам интересно ознакомиться с описанием инструмента и отчётов и порядком их составления, читайте далее.
Расскажу про два основных отчёта:
- статистика выполнения хранимых процедур (Draft report);
- статистика выполнения всех запросов (Detail report).
1. Трассировка
Процесс нельзя понять посредством его прекращения. Понимание должно двигаться вместе с процессом, слиться с его потоком и течь вместе с ним.
— из романа «Дю́на» Фрэнка Герберта

Трассировка, результаты которой анализируются автоматически, предполагает наличие конкретных событий и колонок. Удобен программный запуск, при старте нагрузочного теста. Именно такой способ использую, возможны и другие варианты.
При профилировании нагруженной OLTP-системы лучше сохранять трейсы в файлы. Выполняя загрузку файлов трассировки в таблицу базу данных уже после тестирования. Так создаётся меньшая дополнительная нагрузка на SQL Server, чем при записи трассировки в базу данных (на сколько меньшая не измерял). И расходуется меньше места (файлы трассировки в 3,9-4 раза меньше аналогичной таблицы трассировки). Далее предполагается, что тестируется OLTP и тестирование нагрузочное.
При профилировании OLAP-системы, когда нагрузка невысока, записывать трейсы можно сразу в базу данных.
1.1. Автоматический запуск

Удобно запускать профилирование в событии начала нагрузочного теста. В контексте нагрузочного теста определить параметры, значения которых удобно менять без изменения кода нагрузочного теста:
- useSQLProfiling (true/false) — использовать трассировку при запуске теста (например, true)
- pathSQLPrifiling — путь к каталогу на сервере с Microsoft SQL Server для сохранения файлов трассировки (например, D:\Traces\Synerdocs\)
- названия баз данных (четыре параметра) — использую для фильтрации профилируемых событий (tempdb и три базы данных тестируемой системы)
Из контекста нагрузочного теста также извлекается название профиля нагрузки, которое отражается в имени файлов трейса. И профиля нагрузки извлекается длительность тестирования, для вычисления момента завершения трассировки.
Выполняется параметризированный запрос Script.01.Start trace.sql (см. в каталоге scripts\start trace\ в папке проекта или во врезке ниже).
Script.01.Start trace.sql
-- Script.01.Start trace.sql
-- Параметры:
-- @traceDuration, Int, "Длительность (в секундах)"
-- Значение берётся из профиля нагрузочного теста, при старте тестирования.
-- @fileName, nvarchar(256), "Сохранять трейс в файл"
-- Значение формируется на основе папки профайлинга, названия профиля нагрузки и текущего времени.
-- D:\Traces\Synerdocs\ServiceLoadTestBigFiles.2014.01.21 08.30.10
-- @db1, nvarchar(256), фильтр по имени базы данных
-- @db2, nvarchar(256), фильтр по имени базы данных
-- @db3, nvarchar(256), фильтр по имени базы данных
-- @db4, nvarchar(256), фильтр по имени базы данных
-- Create a Queue
declare @rc int
declare @TraceID int
declare @maxfilesize bigint
declare @stopTraceTime datetime
declare @traceFileName nvarchar(256)
declare @traceOptions int
-- Create 100 MBytes files
set @maxfilesize = 100
-- Duration of trace
set @stopTraceTime = DATEADD(second, @traceDuration, SYSDATETIME())
-- Trace filename
set @traceFileName = @fileName
-- TRACE_FILE_ROLLOVER
set @traceOptions = 2
exec @rc = sp_trace_create @TraceID output, @traceOptions, @traceFileName, @maxfilesize, @stopTraceTime
if (@rc != 0) goto error
-- Set the events
declare @on bit
set @on = 1
-- 162. User Error Message. Displays error messages that users see in the case of an error or exception.
exec sp_trace_setevent @TraceID, 162, 1, @on -- TextData. ntext.
exec sp_trace_setevent @TraceID, 162, 4, @on -- TransactionID. bigint.
exec sp_trace_setevent @TraceID, 162, 9, @on -- ClientProcessID. int.
exec sp_trace_setevent @TraceID, 162, 10, @on -- ApplicationName. nvarchar.
exec sp_trace_setevent @TraceID, 162, 11, @on -- LoginName. nvarchar.
exec sp_trace_setevent @TraceID, 162, 12, @on -- SPID. int.
exec sp_trace_setevent @TraceID, 162, 20, @on -- Severity.
exec sp_trace_setevent @TraceID, 162, 14, @on -- StartTime. datetime.
exec sp_trace_setevent @TraceID, 162, 31, @on -- Error. int.
exec sp_trace_setevent @TraceID, 162, 35, @on -- DatabaseName. nvarchar.
exec sp_trace_setevent @TraceID, 162, 49, @on -- RequestID. int.
exec sp_trace_setevent @TraceID, 162, 50, @on -- XactSequence. bigint.
-- 148. Deadlock Graph. Occurs when an attempt to acquire a lock is canceled because the attempt was part of a deadlock and was chosen as the deadlock victim. Provides an XML description of a deadlock.
exec sp_trace_setevent @TraceID, 148, 1, @on -- TextData. ntext.
exec sp_trace_setevent @TraceID, 148, 4, @on -- TransactionID. bigint. Not used.
exec sp_trace_setevent @TraceID, 148, 11, @on -- LoginName. nvarchar.
exec sp_trace_setevent @TraceID, 148, 12, @on -- SPID. int.
exec sp_trace_setevent @TraceID, 148, 14, @on -- StartTime. datetime.
-- 10. RPC:Completed. Occurs when a remote procedure call (RPC) has completed.
exec sp_trace_setevent @TraceID, 10, 1, @on -- TextData. ntext.
exec sp_trace_setevent @TraceID, 10, 4, @on -- TransactionID. bigint.
exec sp_trace_setevent @TraceID, 10, 9, @on -- ClientProcessID. int.
exec sp_trace_setevent @TraceID, 10, 10, @on -- ApplicationName. nvarchar.
exec sp_trace_setevent @TraceID, 10, 11, @on -- LoginName. nvarchar.
exec sp_trace_setevent @TraceID, 10, 12, @on -- SPID. int.
exec sp_trace_setevent @TraceID, 10, 13, @on -- Duration. bigint.
exec sp_trace_setevent @TraceID, 10, 14, @on -- StartTime. datetime.
exec sp_trace_setevent @TraceID, 10, 15, @on -- EndTime. datetime.
exec sp_trace_setevent @TraceID, 10, 16, @on -- Reads. bigint.
exec sp_trace_setevent @TraceID, 10, 17, @on -- Writes. bigint.
exec sp_trace_setevent @TraceID, 10, 18, @on -- CPU. int.
exec sp_trace_setevent @TraceID, 10, 31, @on -- Error. int.
exec sp_trace_setevent @TraceID, 10, 34, @on -- ObjectName. nvarchar.
exec sp_trace_setevent @TraceID, 10, 35, @on -- DatabaseName. nvarchar.
exec sp_trace_setevent @TraceID, 10, 48, @on -- RowCounts. bigint.
exec sp_trace_setevent @TraceID, 10, 49, @on -- RequestID. int.
exec sp_trace_setevent @TraceID, 10, 50, @on -- XactSequence. bigint.
-- 12. SQL:BatchCompleted. Occurs when a Transact-SQL batch has completed.
exec sp_trace_setevent @TraceID, 12, 1, @on -- TextData. ntext.
exec sp_trace_setevent @TraceID, 12, 4, @on -- TransactionID. bigint.
exec sp_trace_setevent @TraceID, 12, 9, @on -- ClientProcessID. int.
exec sp_trace_setevent @TraceID, 12, 11, @on -- LoginName. nvarchar.
exec sp_trace_setevent @TraceID, 12, 10, @on -- ApplicationName. nvarchar.
exec sp_trace_setevent @TraceID, 12, 12, @on -- SPID. int.
exec sp_trace_setevent @TraceID, 12, 13, @on -- Duration. bigint.
exec sp_trace_setevent @TraceID, 12, 14, @on -- StartTime. datetime.
exec sp_trace_setevent @TraceID, 12, 15, @on -- EndTime. datetime.
exec sp_trace_setevent @TraceID, 12, 16, @on -- Reads. bigint.
exec sp_trace_setevent @TraceID, 12, 17, @on -- Writes. bigint.
exec sp_trace_setevent @TraceID, 12, 18, @on -- CPU. int.
exec sp_trace_setevent @TraceID, 12, 31, @on -- Error. int.
exec sp_trace_setevent @TraceID, 12, 35, @on -- DatabaseName. nvarchar.
exec sp_trace_setevent @TraceID, 12, 48, @on -- RowCounts. bigint.
exec sp_trace_setevent @TraceID, 12, 49, @on -- RequestID. int.
exec sp_trace_setevent @TraceID, 12, 50, @on -- XactSequence. bigint.
-- Set the Filters
exec sp_trace_setfilter @TraceID, 35, 0, 6, @db1
exec sp_trace_setfilter @TraceID, 35, 1, 6, @db2
exec sp_trace_setfilter @TraceID, 35, 1, 6, @db3
exec sp_trace_setfilter @TraceID, 35, 1, 6, @db4
-- Set the trace status to start
exec sp_trace_setstatus @TraceID, 1
-- display trace id for future references
select TraceID=@TraceID
goto finish
error:
select ErrorCode=@rc
finish:
Возвращаемые значения:
- TraceID, int, идентификатор сеанса трассировки, пригодится для последуюшей остановки трассировки;
- ErrorCode, int, код ошибки, если трассировка не началась, см. Return Code Values для sp_trace_create.
Способ выполнения запроса в событии нагрузочного теста зависит от инструмента тестирования и языка разработки. И в Java и в C# это делается просто. Можно написать отдельное руководство. Некоторые особенности, в двух предложениях:
- События выполняются на нагрузочном агенте, когда нагрузочных агентов несколько, в параметрах нагрузочного теста задаётся имя агента, который будет выполнять старт и досрочное завершение профилирования, агент узнаёт о своём предназначении по имени.
- Если SQL Server находится за DMZ, то агент, работающий с SQL Server ставится на пограничный сервер, и для агента назначается нулевой профиль нагрузки, но проще не использовать DMZ на нагрузочном стенде.
Специалисты, хорошо знакомые с нагрузочным тестированием, поймут предыдущие два предложения. Если понять не удалось, то у вас нет агентов, DMZ, или вам проще запускать трассировку в полуавтоматическом и ручном режиме.
1.1.1. Остановка трассировки

Трассировка запускается на время. Момент завершения трассировки определяектся продолжительностью тестирования (параметр traceDuration) и вычисляется в скрипте Script.01.Start trace.sql. Предполагается, что нагрузочное тестирование также запускается на время, имеет продолжительность, которую можно получить программно.
1.1.2. Досрочное прекращение

При выполнении Script.01.Start trace.sql возвращается TraceId. Если тестирование прекращается досрочно, в событии прекращения тестирования значение TraceId передаётся в скрипт:
-- Stops the specified trace.
EXEC sp_trace_setstatus @traceid = @traceid , @status = 0
-- Closes the specified trace and deletes its definition from the server.
EXEC sp_trace_setstatus @traceid = @traceid , @status = 2
1.2. Полуавтоматический запуск

Если невозможно автоматически выполнять sql-запрос при старте тестирования, то запрос Script.01.Start trace.sql можно выполнить вручную из SQL Management Studio, предварительно определив параметры скрипта.
Если время остановки невозможно вычислить при старте трассировки, то параметр stopTraceTime не надо передавать в процедуру sp_trace_create (см. Script.01.Start trace.sql :29).
1.2.1. Остановка трассировки
Останавливать профилирование можно также скриптом, выбирая останавливаемый сеанс трассировки, например, по каталогу (D:\Traces\Synerdocs\):
-- Script.02.Stop trace.sql
DECLARE @traceid INT
SET @traceid = (SELECT TOP 1 [id] FROM sys.traces WHERE [path] LIKE 'D:\Traces\Synerdocs\%')
IF @traceid IS NOT NULL
BEGIN
-- Stops the specified trace.
EXEC sp_trace_setstatus @traceid = @traceid , @status = 0
-- Closes the specified trace and deletes its definition from the server.
EXEC sp_trace_setstatus @traceid = @traceid , @status = 2
END
SELECT * FROM sys.traces
1.3. Ручной запуск
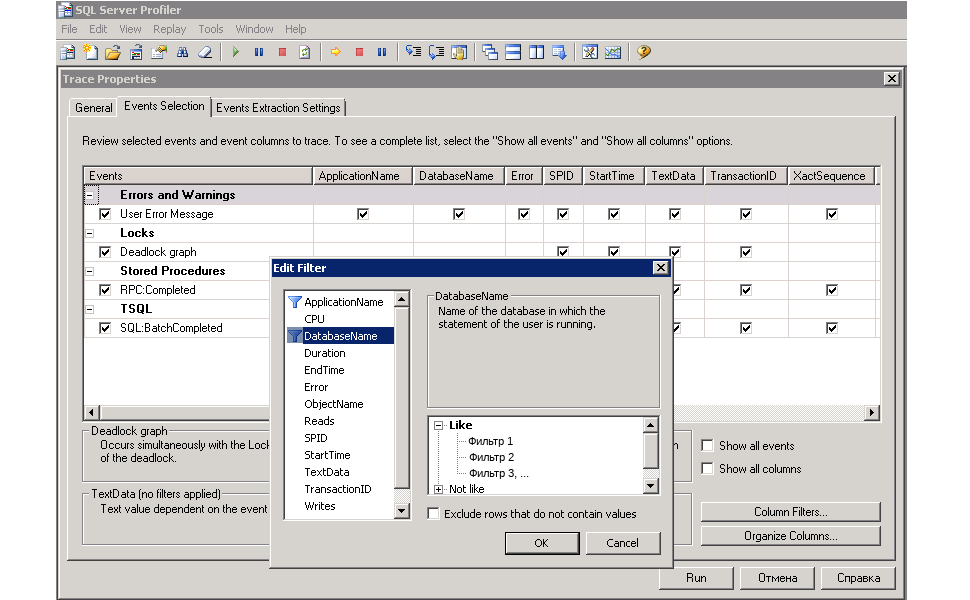
Microsoft SQL Server Profiler позволяет собрать большое количество событий.
См. sp_trace_setevent (http://msdn.microsoft.com/ru-ru/library/ms186265.aspx).
В качестве наиболее интересных событий выделю ошибки, блокировки, выполнение процедур и запросов:
Останавливать профилирование можно также скриптом, выбирая останавливаемый сеанс трассировки, например, по каталогу (D:\Traces\Synerdocs\):
-- Script.02.Stop trace.sql
DECLARE @traceid INT
SET @traceid = (SELECT TOP 1 [id] FROM sys.traces WHERE [path] LIKE 'D:\Traces\Synerdocs\%')
IF @traceid IS NOT NULL
BEGIN
-- Stops the specified trace.
EXEC sp_trace_setstatus @traceid = @traceid , @status = 0
-- Closes the specified trace and deletes its definition from the server.
EXEC sp_trace_setstatus @traceid = @traceid , @status = 2
END
SELECT * FROM sys.traces
1.3. Ручной запуск
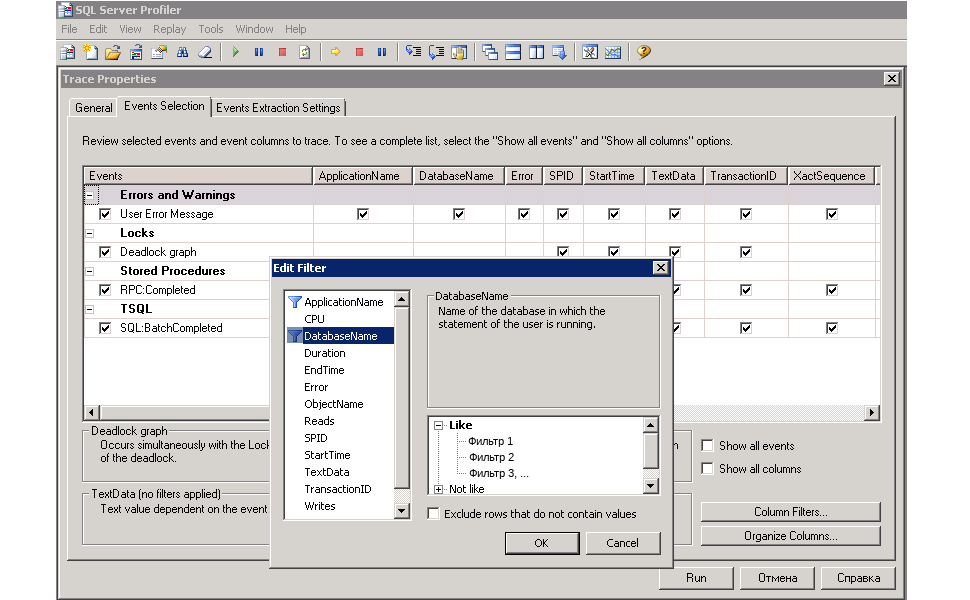
Microsoft SQL Server Profiler позволяет собрать большое количество событий.
См. sp_trace_setevent (http://msdn.microsoft.com/ru-ru/library/ms186265.aspx).
В качестве наиболее интересных событий выделю ошибки, блокировки, выполнение процедур и запросов:
| ИД (EventID) | Событие (Event Name) | Описание (Event description) |
|---|---|---|
| 162 | User Error Message | Displays error messages that users see in the case of an error or exception |
| 148 | Deadlock Graph | Occurs when an attempt to acquire a lock is canceled because the attempt was part of a deadlock and was chosen as the deadlock victim. |
| 10 | RPC:Completed | Occurs when a remote procedure call (RPC) has completed. |
| 12 | SQL:BatchCompleted | Occurs when a Transact-SQL batch has completed. |
У выбранных событий наиболее интересны колонки:
| ColumnID | ColumnName | Type | Ошибки | Блокировки | Процедуры | Запросы |
|---|---|---|---|---|---|---|
| 1 | TextData | ntext | + | + | + | + |
| 13 | Duration | bigint | + | + | ||
| 14 | StartTime | datetime | + | + | + | + |
| 16 | Reads | bigint | + | + | ||
| 17 | Writes | bigint | + | + | ||
| 18 | CPU | int | + | + | ||
| 31 | Error | int | + | + | + | |
| 34 | ObjectName | nvarchar | + | |||
| 35 | DatabaseName | nvarchar | + | + | + |
Включаю в трассировку дополнительные колонки, в отчётах они не используются, но пригождаются при ручном анализе:
| ColumnID | ColumnName | Type | Ошибки | Блокировки | Процедуры | Запросы |
|---|---|---|---|---|---|---|
| 4 | TransactionID | bigint | + | + | + | + |
| 9 | ClientProcessID | int | + | + | + | |
| 10 | ApplicationName | nvarchar | + | + | + | |
| 11 | LoginName | nvarchar | + | + | + | + |
| 12 | SPID | int | + | + | + | + |
| 15 | EndTime | datetime | + | + | ||
| 48 | RowCounts | bigint | + | + | ||
| 49 | RequestID | int | + | + | + | |
| 50 | XactSequence | bigint | + | + | + |
Трассировка с фильтрацией по DatabaseName (ColumnID 35), выполняется лишь для выбранных баз данных SQL Server (на тестовых серверах, часто, баз данных много, надо выбрать лишь нужные):
- tempdb;
- базы данных тестируемого приложения.
Фильтрацию и группировку также удобно выполнять по LoginName.
Если вам удобен ручной запуск трассировки, то Microsoft SQL Server Profiler позволит просматривать результаты профилирования сразу.
1.3.1. Преобразование настроенных параметров в скрипт для автоматизации
Если у вас есть другой набор событий, колонок и фильтров. И вы хотите автоматизировать запуск трассировки с таким набором параметров, то SQL Server Profiler поможет и тут.

Настройка автоматического запуска трассировки:
- Запустить Microsoft SQL Server Profiler.
- Выбрать профилируемые события, выбрать атрибуты профилируемых событий.
- Задать параметры фильтрации (по DatabaseName или по LoginName), параметры открываются по нажатию кнопки Column Filters….
- Сохранить параметры трассировки, заданные на вкладке Events Selection окна «Trace Properties», используя пункт меню «File/Export/Script Trace Definition/For SQL Server 2005 – 2008 R2…».
Получится заготовка скрипта. Похожая на текст скрипта:
Сгенерированный скрипт с настройками профилирования
/****************************************************/
/* Created by: SQL Server 2008 R2 Profiler */
/* Date: 21/01/2014 10:23:02 */
/****************************************************/
-- Create a Queue
declare @rc int
declare @TraceID int
declare @maxfilesize bigint
set @maxfilesize = 5
-- Please replace the text InsertFileNameHere, with an appropriate
-- filename prefixed by a path, e.g., c:\MyFolder\MyTrace. The .trc extension
-- will be appended to the filename automatically. If you are writing from
-- remote server to local drive, please use UNC path and make sure server has
-- write access to your network share
exec @rc = sp_trace_create @TraceID output, 0, N'InsertFileNameHere', @maxfilesize, NULL
if (@rc != 0) goto error
-- Client side File and Table cannot be scripted
-- Set the events
declare @on bit
set @on = 1
exec sp_trace_setevent @TraceID, 162, 31, @on
exec sp_trace_setevent @TraceID, 162, 1, @on
exec sp_trace_setevent @TraceID, 162, 9, @on
exec sp_trace_setevent @TraceID, 162, 49, @on
exec sp_trace_setevent @TraceID, 162, 10, @on
exec sp_trace_setevent @TraceID, 162, 14, @on
exec sp_trace_setevent @TraceID, 162, 50, @on
exec sp_trace_setevent @TraceID, 162, 11, @on
exec sp_trace_setevent @TraceID, 162, 35, @on
exec sp_trace_setevent @TraceID, 162, 4, @on
exec sp_trace_setevent @TraceID, 162, 12, @on
exec sp_trace_setevent @TraceID, 162, 20, @on
exec sp_trace_setevent @TraceID, 148, 11, @on
exec sp_trace_setevent @TraceID, 148, 4, @on
exec sp_trace_setevent @TraceID, 148, 12, @on
exec sp_trace_setevent @TraceID, 148, 14, @on
exec sp_trace_setevent @TraceID, 148, 1, @on
exec sp_trace_setevent @TraceID, 10, 15, @on
exec sp_trace_setevent @TraceID, 10, 31, @on
exec sp_trace_setevent @TraceID, 10, 16, @on
exec sp_trace_setevent @TraceID, 10, 48, @on
exec sp_trace_setevent @TraceID, 10, 1, @on
exec sp_trace_setevent @TraceID, 10, 9, @on
exec sp_trace_setevent @TraceID, 10, 17, @on
exec sp_trace_setevent @TraceID, 10, 49, @on
exec sp_trace_setevent @TraceID, 10, 10, @on
exec sp_trace_setevent @TraceID, 10, 18, @on
exec sp_trace_setevent @TraceID, 10, 34, @on
exec sp_trace_setevent @TraceID, 10, 50, @on
exec sp_trace_setevent @TraceID, 10, 11, @on
exec sp_trace_setevent @TraceID, 10, 35, @on
exec sp_trace_setevent @TraceID, 10, 4, @on
exec sp_trace_setevent @TraceID, 10, 12, @on
exec sp_trace_setevent @TraceID, 10, 13, @on
exec sp_trace_setevent @TraceID, 10, 14, @on
exec sp_trace_setevent @TraceID, 12, 15, @on
exec sp_trace_setevent @TraceID, 12, 31, @on
exec sp_trace_setevent @TraceID, 12, 16, @on
exec sp_trace_setevent @TraceID, 12, 48, @on
exec sp_trace_setevent @TraceID, 12, 1, @on
exec sp_trace_setevent @TraceID, 12, 9, @on
exec sp_trace_setevent @TraceID, 12, 17, @on
exec sp_trace_setevent @TraceID, 12, 49, @on
exec sp_trace_setevent @TraceID, 12, 10, @on
exec sp_trace_setevent @TraceID, 12, 14, @on
exec sp_trace_setevent @TraceID, 12, 18, @on
exec sp_trace_setevent @TraceID, 12, 50, @on
exec sp_trace_setevent @TraceID, 12, 11, @on
exec sp_trace_setevent @TraceID, 12, 35, @on
exec sp_trace_setevent @TraceID, 12, 4, @on
exec sp_trace_setevent @TraceID, 12, 12, @on
exec sp_trace_setevent @TraceID, 12, 13, @on
-- Set the Filters
declare @intfilter int
declare @bigintfilter bigint
exec sp_trace_setfilter @TraceID, 35, 0, 6, N'ServiceDB'
exec sp_trace_setfilter @TraceID, 35, 1, 6, N'ClientDB'
exec sp_trace_setfilter @TraceID, 35, 1, 6, N'LogsDB'
exec sp_trace_setfilter @TraceID, 35, 1, 6, N'Tempdb'
-- Set the trace status to start
exec sp_trace_setstatus @TraceID, 1
-- display trace id for future references
select TraceID=@TraceID
goto finish
error:
select ErrorCode=@rc
finish:
go
В заготовку скрипта трассировки не попадают параметры с вкладки General окна «Trace Properties». Там есть нужные параметры, которые добавляются в скрипт вручную:
- Save to file;
- Set maximum file size (MB);
- Enable file rollover;
- Enable trace stop time.
Имя файла и время остановки трассировки задаётся из кода нагрузочного теста, а максимальный размер файла и признак того, что нужно будет создавать новые файлы, удобно задать константой. Именно так и был создан Script.01.Start trace.sql, рассмотренный выше.
Описание параметров Set maximum file size (MB) и Enable file rollover: http://msdn.microsoft.com/en-us/library/ms191206.aspx.
Загрузка файлов трассировки в базу данных
Для формирования отчётов файлы трассировки загружаются в таблицу базы данных.
Предварительно создаётся база данных, в таблицы этой базы данных будут загружаться трейсы, в ней же будут создаваться таблицы с отчётами. Можно назвать базу данных ProfilerResults. В имени базы данных удобно отразить наименование проекта, отчёты по которому будут скапливаться в ней. Проект, над которым работаю, когда-то назвали «Midway», поэтому базу данных назвал MidwayProfilerResults. Для создания базы данных удобно использовать SQL Management Studio, где есть мастер для создания базы данных, пара кликов и готово.
Для загрузки используется системная функция fn_trace_gettable.
use "ProfilerResults"
SELECT
"EventClass"
, "TextData"
, "Duration"
, "StartTime"
, "Reads"
, "Writes"
, "CPU"
, "Error"
, "ObjectName"
, "DatabaseName"
, "TransactionID"
, "ClientProcessID"
, "ApplicationName"
, "LogiName"
, "SPID"
, "EndTime"
, "RowCounts"
, "RequestID"
, "XactSequence"
INTO "SOAP.v2.3.1.5577"
FROM ::fn_trace_gettable(N'D:\Traces\Synerdocs\LoadTest.SOAP.Trace.StartOn 2013.01.21 08.30.00.trc', default)
В параметрах fn_trace_gettable указывается путь к первому файлу трассировки, а второй параметр default означает, что в таблицу загрузятся все файлы из того же сеанса трассировки (не только указанный файл размером 100 МБайт).

Имя таблицы профайлинга задаётся так, чтобы отражать версию тестируемой системы и профиль нагрузки (в примере: «SOAP.v2.3.1.5577»). Создаваемые таблицы с отчётами будут содержать в имени название таблицы профайлинга, по которой сформированы. И чтобы в дальнейшем найти нужную таблицу с отчётом среди множества других, лучше задать значащее имя таблице.
Загрузка может выполняться долго, зависит от оборудования. На используемом сервере скорость загрузки такая: 160-190 МБайт/минуту или 1,5 — 2 файла трассировки в минуту (один файл — 100 МБайт). Замеры по двум недавним операциям загрузки файлов трассировки в базу данных (обычный профиль нагрузки и профиль нагрузки с большими файлами).
| Размер файлов трейса (МБайт) | Длительность загрузки (ч: мин: сек) | Средняя скорость загрузки (МБайт/мин) | Размер таблицы трассировки (МБайт) | Количество строк | Средний размер строки таблицы (КБайт) | Коэффициент увеличения размера после загрузки в таблицу |
|---|---|---|---|---|---|---|
| 7 598 | 00:45:17 | 168,8 | 29 478,3 | 766 370 | 39,4 | 3,9 |
| 67 062 | 05:46:32 | 193,8 | 268 875,7 | 2 861 599 | 96,2 | 4,0 |
2. Сводный отчёт по процедурам (RPC:Completed) — «Draft Report»
Излишне тщательный анализ искажает истину.
— древнее фрименское изречение, из романа «Мессия Дюны» Фрэнка Герберта
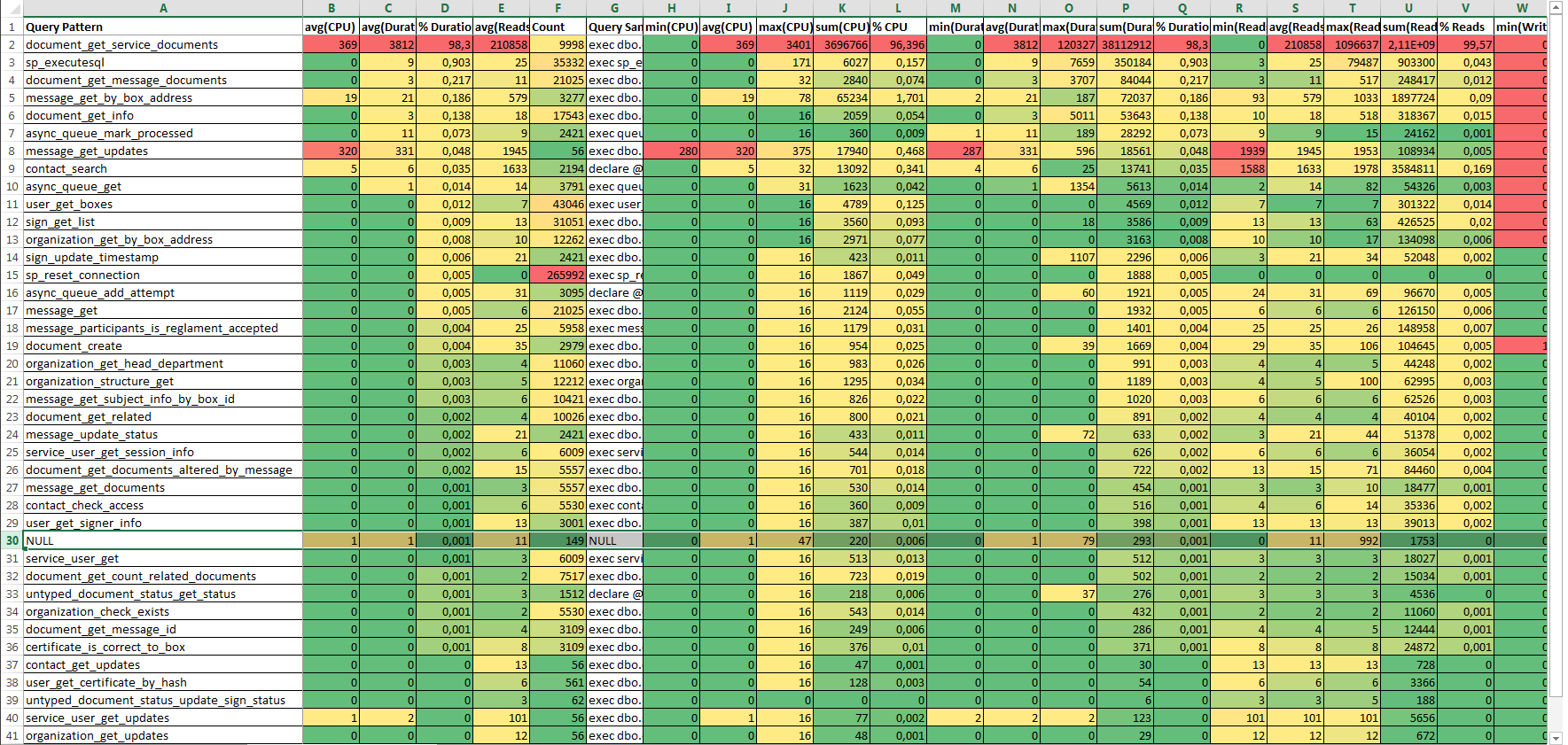
Если работа с базой данных осуществляется преимущественно через API базы данных (набор хранимых процедур и функций), то этот отчёт — первое, что стоит построить.
Отчёт представляет собой группировку событий RPC:Completed из таблицы трассировки по имени базы данных (DatabaseName) и имени хранимой процеруды или функции (ObjectName) с подсчётом статистики и текстами смых быстрых и самых медленных запросов. Статистика по SQL:BatchCompleted также есть в отчёте, но это лишь одна строка — строка NULL, без детализации. Поэтому этот отчёт назван «Draft Report».
Для автоматизации построения отчёта «Draft Report» используется вспомогательный инструмент Tools.SQLProfilerReportHelper.
2.1. Подготовка к формированию отчёта «Draft Report»
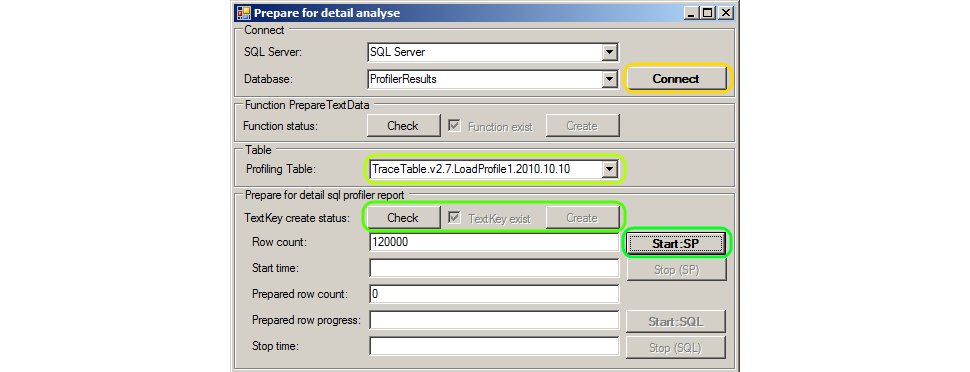
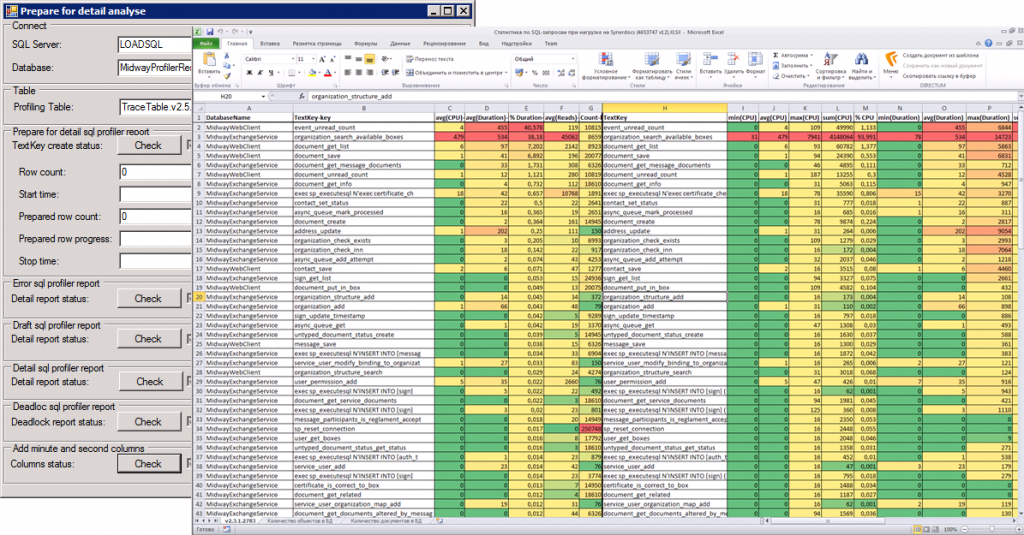
Подготовка сводится к нажатию кнопок на форме Tools.SQLProfilerReportHelper:
- Запустить Tools.SQLProfilerReportHelper.
- Указать имя SQL Server и базы данных профайлинга в полях SQL Server и Database. В примере это — «SQL Server» и «ProfilerResults». Нажать кнопку Connect. Используется Windows-аутентификация на SQL Server, пользователь должен быть администратором базы данных профайлинга.
- Выбрать из списка Profiling Table таблицу с результатами профайлинга. В примере это — «TraceTable.v2.7.LoadProfile1.2010.10.10».
- Создать новую колонку TextKey в таблице профайлинга — проверить наличие/отсутствие колонки в таблице, нажав кнопку Check, и если колонки не существует (кнопка Create станет доступной), нажать кнопку Create.
- Нажать кнопку Start: SP. По нажатию выполнится копирования значений из колонки ObjectName в колонку TextKey.
Во время копирования ObjectName в колонку TextKey отображается сколько записей осталось обработать. И вычисляется оставшаяся длительность операции. Процесс можно прервать нажатием кнопки Stop: SP.
2.2. Формирование отчёта «Draft Report»

После завершения копирования создать черновой отчёт (Draft report). Для этого нужно нажать кнопку Check (проверить наличие/отсутствие таблицы с отчётом), и если таблицы с отчётом нет, то нажать кнопку Create. В результате чего будет создана таблица с окончанием «DraftStat» в имени, в нашем примере — TraceTable.v2.7.LoadProfile1.2010.10.10.DraftStat. Размер таблицы относительно небольшой (10-30 МБайт). Таблица предназначена для долгосрочного хранения статистики выполнения хранимых процедур и функций.
Содержимое таблицы получить запросом:
USE "ProfilerResults"
SELECT * FROM "dbo"."TraceTable.v2.7.LoadProfile1.2010.10.10.DraftStat"

Запрос удобно выполнить в SQL Management Studio.
Скопировать в буфер обмена все колонки, кроме колонок с текстами запросов TextData-....
Состав колонок таблицы DtaftStat (отчёт Draft Report)
| Колонка | Тип | Описание |
|---|---|---|
| DatabaseName | nvarchar(256) | База данных (ключ группировки). |
| ObjectName-key | nvarchar(256) | Наименование хранимой процедуры или функции (ключ группировки). |
| avg(CPU)-key | int | Время ЦП (среднее) в миллисекундах, используемое событием. |
| avg(Duration)-key | bigint | Длительность выполнения события (средняя) в миллисекундах. |
| % Duration-key | float | Доля суммарной длительности события (ключ сортировки). |
| avg(Reads)-key | bigint | Количество логических чтений диска (среднее), выполненное сервером для события. |
| Count-key | int | Количество вызовов (штук). |
| ObjectName | nvarchar(256) | Наименование хранимой процедуры или функции (ключ группировки). |
| avg(CPU) | int | Среднее значение по колонке CPU (среднее время ЦП в миллисекундах, используемое событием). |
| max(CPU) | int | Максимальное время ЦП в миллисекундах, используемое событием. |
| sum(CPU) | int | Суммарное время ЦП в миллисекундах, используемое событием. |
| % CPU | float | Доля суммарного времени ЦП события. |
| min(Duration) | bigint | Длительность события (миниальная) в миллисекундах. |
| avg(Duration) | bigint | Длительность события (средняя) в миллисекундах. |
| max(Duration) | bigint | Длительность события (максимальная) в миллисекундах. |
| sum(Duration) | bigint | Длительность события (суммарная) в миллисекундах. |
| % Duration | float | Доля суммарной длительности события. |
| min(Reads) | bigint | Количество логических чтений диска (минимальное), выполненное сервером для события. |
| avg(Reads) | bigint | Количество логических чтений диска (среднее), выполненное сервером для события. |
| max(Reads) | bigint | Количество логических чтений диска (максимальное), выполненное сервером для события. |
| sum(Reads) | bigint | Количество логических чтений диска (суммарное), выполненное сервером для события. |
| % Reads | float | Доля количества логических чтений диска, выполненных сервером для события. |
| min(Writes) | bigint | Количество физических обращений к дискам на запись (минильное), выполненное сервером для события. |
| avg(Writes) | bigint | Количество физических обращений к дискам на запись (среднее), выполненное сервером для события. |
| max(Writes) | bigint | Количество физических обращений к дискам на запись (максимальное), выполненное сервером для события. |
| sum(Writes) | bigint | Количество физических обращений к дискам на запись (сумарное), выполненное сервером для события. |
| % Writes | float | Доля количества физических обращений к дискам за напись, выполненных сервером для события. |
| Count | int | Количество событий. |
| % Count | float | Доля количества событий. |
| TextData-min(Duration) | ntext | Текст запроса, для которого длительность выполнения минимальна. |
| TextData-max(Duration) | ntext | Текст запроса, для которого длительность выполнения максимальна. |
| TextData-min(Reads) | ntext | Текст запроса, для которого количество выполненных сервером логических чтений диска минимально. |
| TextData-max(Reads) | ntext | Текст запроса, для которого количество выполненных сервером логических чтений диска максимально. |
| TextData-min(CPU) | ntext | Текст запроса, для которого время ЦП минимально. |
| TextData-max(CPU) | ntext | Текст запроса, для которого время ЦП максимально. |
| TextData-min(Writes) | ntext | Текст запроса, для которого количество выполненных сервером физических обращений к дискам на запись минимально. |
| TextData-max(Writes) | ntext | Текст запроса, для которого количество выполненных сервером физических обращений к дискам на запись максимально. |
Открыть в Microsoft Office Excel шаблон отчёта (таблица с автоматическим форматированием ячеек — подсветка значений от плохих до хороших). Вставить содержимое буфера обмена в документ.
Документ будет выглядеть, как большая раскрашенная таблица, отсортированная по убыванию колонки % Duration.
Первые шесть колонок отделены от остальных (и дублируют их) являются основными. Эти шесть основных колонок удобно копировать из документа Excel в документ Word.
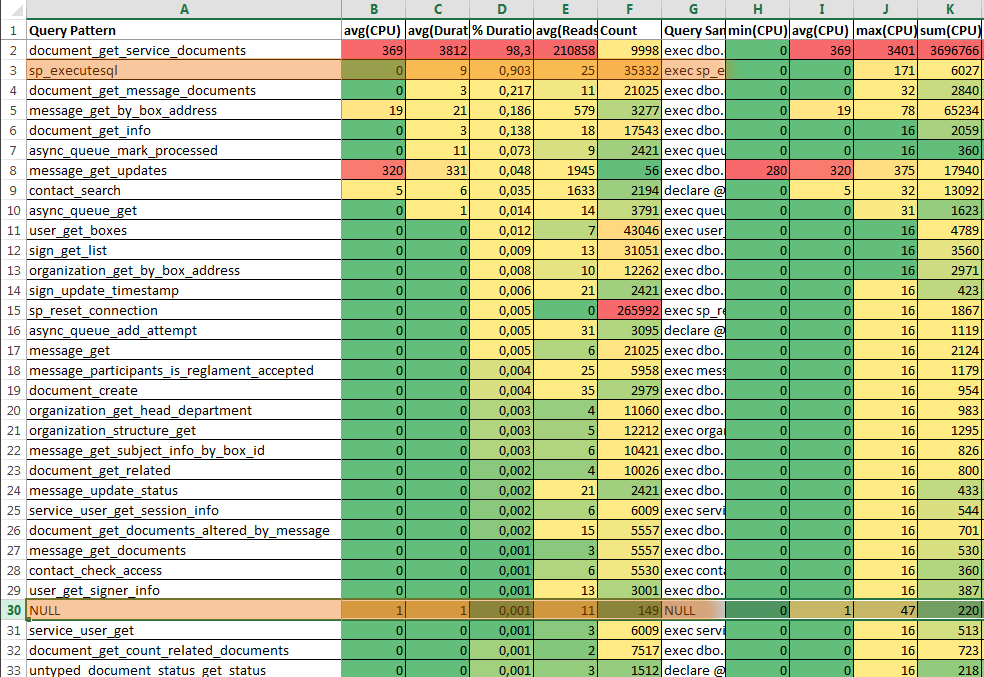
Строки с ключом «NULL» и ключом «sp_executesql» — это статистика по вызовам запросов (SQL:BatchCompleted) и запросов, выполненных посредством вызова хранимой процедуры sp_executesql. Если таких запросов мало (колонка Count) и доля длительности их выполнения невелика (колонка % Duration), то детальный отчёт можно и не строить, ограничившись анализом чернового отчёта.
2.3. Анализ отчёта «Draft Report»

Обратить внимание на хранимые процедуры с максимальным значением % Duration и avg(Reads).
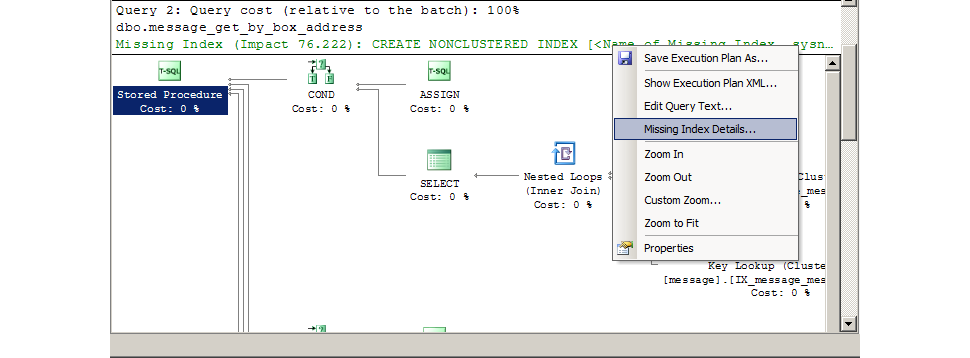
Часто такие вызовы можно ускорить, добавив недостающие индексы. SQL Management Studio подскажет, какие именно индексы лучше добавить. Правильность советов не абсолютная, но высокая.
Был случай, что запрос был оптимальным и индексы были на месте, но в тексте хранимой процедуры осуществлялась выборка всех записей большой таблицы (для отладки) — от этого, запрос лидировал в отчёте по % Duration. Выполнение запроса в SQL Management Studio выявляет такие случаи огромных выборок. По отчёту такие моменты не выявить, статистику по колонке RowCount в отчёт не включаю (надо бы включить).

Полагаю, иногда можно кешировать вызовы с большим значением % Duration и Count (отсортировать записи можно по убыванию произведения «% Duration» x «Count»).
Возможно, в вызовах с большим значением % Duration и avg(CPU) есть неоптимальная работа со строками, математикой, рекурсией.
Вызовы с большим значением % Duration и avg(Write), возможно, неоптимально используют временные таблицы. Или указывают на вставку в таблицы, где слишком много индексов и сложных триггеров.
Тексты запросов с минимальными и максимальными значениями длительности, количества логических чтений, времени ЦП извлекаются из колонок таблицы-отчёта (в документе-отчёте этих колонок нет):
- TextData-min(Duration);
- TextData-max(Duration);
- TextData-min(Reads);
- TextData-max(Reads);
- TextData-min(CPU);
- TextData-max(CPU);
- TextData-min(Writes);
- TextData-max(Writes).
Тексты анализируются в SQL Management Studio.
3. Сводный отчёт по запросам (RPC:Completed + SQL:BatchCompleted) — Detail Report
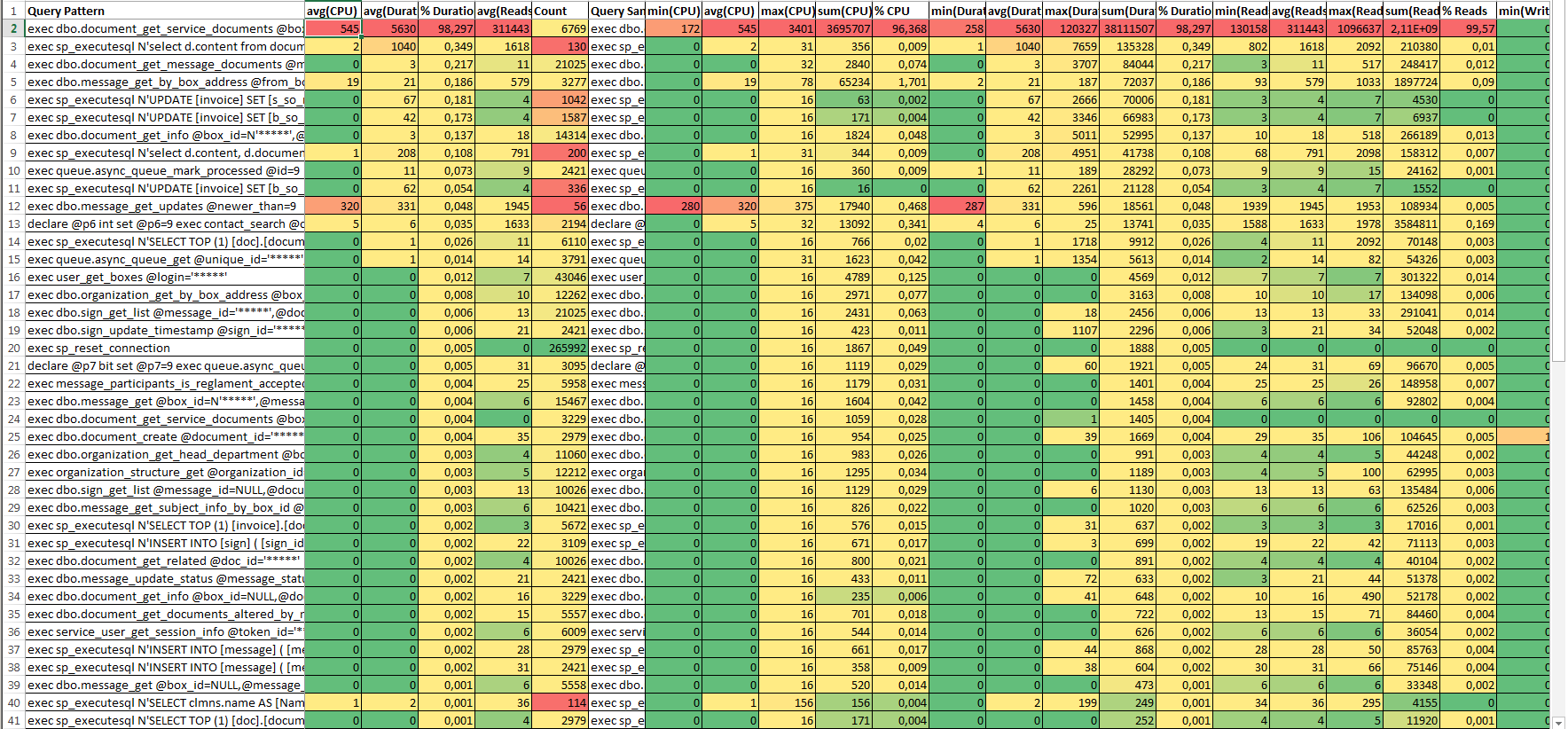
Если в Draft Report строки с ключами «NULL» и «sp_executesql» скрывали детализацию выполнения по многим запросам. То в Detail Report группировка будет выполнена максимально детально.
Формирование отчёта Detail Report предполагает, что отчёт Draft Report уже был сформирован и подготовительные действия выполнены.
3.1. Подготовка к формированию Detail Report
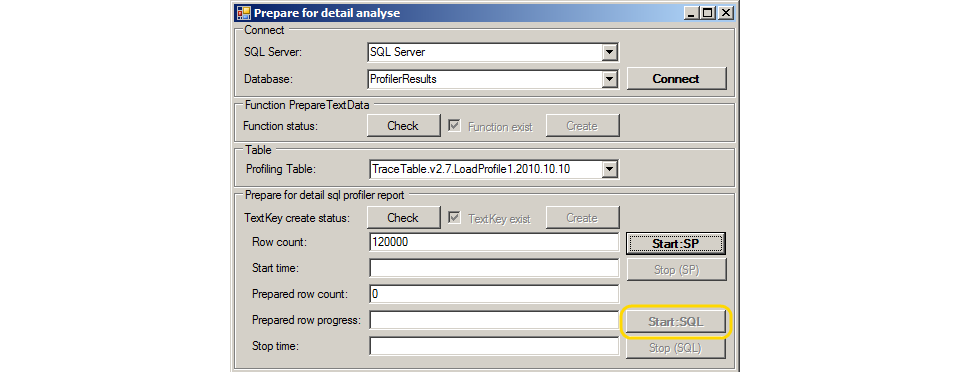
Если Draft Report сформирован, то достаточно:
- Убедиться, что функция PrepareTextData есть в базе данных, нажав кнопку Check в группе Function PrepareTextData (создать функцию при необходимости, нажав кнопку Create).
- Cформировать ключи группировки по текстам запросов (для группировки событий SQL:BatchCompleted по колонке TextData), нажав кнопку Start: SQL.
Иначе нужно выполнить всё с начала: подключиться к базе данных с таблицей профайлинга, выбрать таблицу профайлинга, создать колонку TextKey, нажать кнопку Start: SP для заполнения ключей группировки по хранимым процедурам. Действия осуществляются кликами по доступным кнопкам на форме инструмента. Кнопки, которые нажимать не нужно, становятся недоступными.
3.2. Формирование отчёта

- Проверить статус существования детального отчёта нажав кнопку Check в Detail report status.
- Создать отчёт, если его нет (если кнопка Create доступна для нажатия, то нажать её).
В результате будет создана новая таблица-отчёт, имя которой будет заканчиваться на «DetailStat».
Описание колонок совпадает с описанием колонок для Draft Report. Но в этой таблице строк больше (отчёт более детальный).
Данные таблицы DetailStat также копируются в буфер обмена и вставляются в шаблон отчёта как и для Draft Report.
3.3. Анализ отчёта
Анализ детального отчёта (Detail report) аналогичен анализу чернового отчёта (Draft Report). Но есть дополнительная возможность просмотра и выгрузки текстов запросов.
По нажатию на кнопку View открывается окно со содержимым детального отчёта.
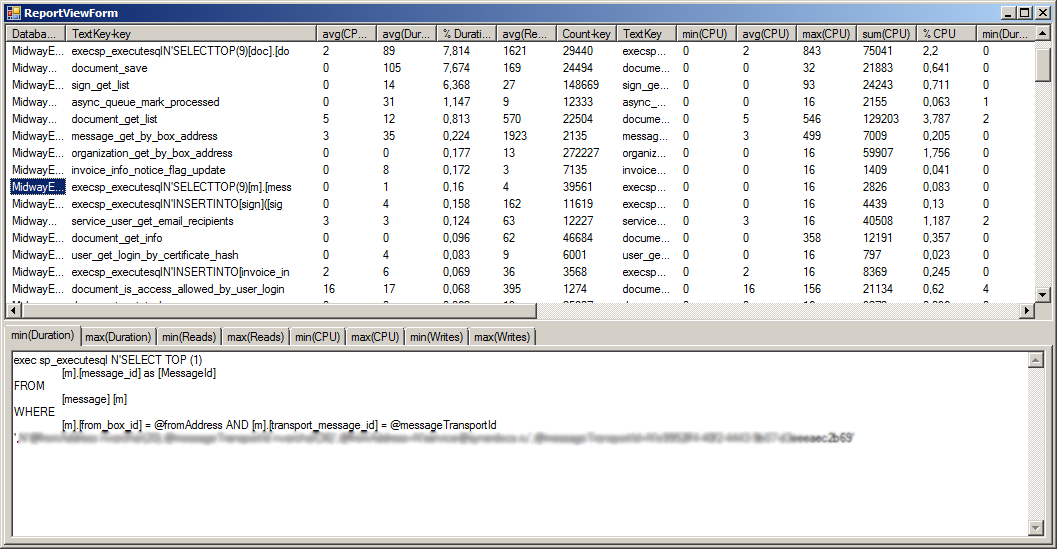 .
.В окне «ReportViewForm», можно посмотреть записи, отсортировать. Тексты запросов, по котором осуществляется клик, сохраняются в виде файлов в папку с программой. А на вкладках можно посмотреть тексты запросов, первые 10 000 символов текста запроса.
Такой способ выгрузки текстов запросов сделан для возможности анализа запросов большого размера. Так если в трес попали операции создания документов размером 100-700 МБайт, то тексты запросов для этих операций огромны. На столько огромны, что даже оперативной памяти может не хватить для запроса «select * from… DetailStat». При работе с таблицей-отчётом DetailStat через такой специальный просмотрщик записи извлекаются отдельными запросами, а не одним общим. Это позволяет выгрузить тексты больших запросов. Если больших запросов в отчёте нет, то работать из SQL Management Studio удобнее.
Последовательная выгрузка текстов запросов в файлы позволяет решить проблему нехватки памяти при работе с большими текстами запросов (выгружал тексты запросов размером 500 МБайт и более).
Промышленная эксплуатация
Описанный способ сбора и анализа трейсов Microsoft SQL Server опробован при тестировании двух продуктов. Оба продукта связаны с бухгалтерией.
OLTP-система (Synerdocs)
Частые выборки небольших порций данных, частые обновления отдельных записей (входящие/исходящие, документы, подписи). Много пользователей (1000-2000 тестовых пользователей). Много вызовов хранимых процедур и функций (API-базы данных). Мало вызовов sql-запросов, которые не являются вызовами хранимых процедур. Запросов за время нагрузочного тестирования набирается несколько сотен тысяч. Запросы собираются в сотню групп.
Сбор трейса запускается на длительность нагрузочного тестирования (пара-тройка часов). Потом десятки гигабайт трейса анализируются и превращаются в отчёты.
Тестирование проводится регулярно. В какой-то момент находить явные узкие места стало сложно. Понадобился инсрумент для детального анализа. И чтобы отчёты легко сравнивались между собой (ключи группировки должны быть короткими, чтобы влазить в колонку Excel). Так и появились отчёты, о которых рассказано выше.
OLAP-система (Prestima)
Выборка и группировка больших порцией данных, обновления отдельных записей (бюджетирование, счета, проводки). Относительно мало пользователей во время тестирования (нагрузку создают живые люди, которые запускают формирование отчётов). Много динамически формируемых запросов (длинный текст запроса, различия двух запросов могут быть только на 200-м символе в разделе с JOIN-ами или на 250-м в секции WHERE). Запросы аналитические, к множеству таблиц, с разными условиями. Отчётливое влияние критериев запроса на длительность. Самый долгий запрос от самого быстрого может отличаться не структурой запроса, а значениями параметров.
Сбор трейса запускается на длительность функционального и объёмного тестирования (возможно, пара-тройка дней). Периодически трейсы анализируются и превращаются в отчёты.
Чтобы статистика по сложным запросам не попадала в одну группу, ключи группировки должны быть точными. В процедуре PrepareTextData можно задать длину вычисляемого ключа. И при небольшом объёме трейсов использование длинных ключей группировки вполне нормально (скорость формирования отчётов останется высокой).
Авторство и ссылки
Аналитические отчёты, представленные в статье, являются потомками sql-запроса, написанного Извековым Михаилом (разработчик НПО Компьютер). Запрос прост и прекрасен:
-- Длинные строки с REPLACEами нужны чтобы заменить все цифры на символ X. Переменная @Len отвечает за то,
-- сколько первых символов запроса будут составлять его сигнатуру. Чем меньше значение этой переменной,
-- тем меньше групп запросов будет в результате, но больше шанс, что в одну группу попадут запросы разного типа.
-- Например при значении 26 все запросы получения IContents разных типов попадут в одну группу с сигнатурой "select distinct X as Ob",
-- если увеличить длину в два раза, то запросы разделятся на группы по типам объектов,
-- а если увеличить длину до 4000, то разделятся еще и по условиям фильтрации
-- (содержимое папки, документы связанные с записью справочника и т.п.).
declare @Hours float;
declare @CPUSumm int;
declare @Len int = 26;
select @CPUSumm = SUM(CPU) from Test -- Таблица, в которую сохранили трейс.
select @Hours = CAST(MAX(StartTime) - MIN(StartTime) as float) * 24 from Test -- Таблица, в которую сохранили трейс.
select
SUBSTRING(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(CAST(TextData as nvarchar(4000)),'0','X'),'1','X'),'2','X'),'3','X'),'4','X'),'5','X'),'6','X'),'7','X'),'8','X'),'9','X'),'XX','X'),'XX','X'),'XX','X'), 1, @Len) as [Query Pattern],
sum(CPU) / 1000 as CPU_sec_SUM,
avg(CPU) as CPU_msec_AVG,
max(CPU) as CPU_msec_MAX,
min(CPU) as CPU_msec_MIN,
avg(Duration) / 1000 as [AVG_Duration (msec)],
avg(Reads) as [Avg Reads],
avg(Writes) as [Avg Writes],
count(1) as TotalQnt,
round(count(1) / @Hours, 2) as Count_per_hour,
round(cast(SUM(CPU) as float) / @CPUSumm * 100, 3) as ImpactCPUPerf
from
Test -- Таблица, в которую сохранили трейс.
where
EventClass in (10, 12)
and ISNULL(ApplicationName, 'Unknown') in ('SBRSE', 'IS-Builder', 'Unknown')
group by
SUBSTRING(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(CAST(TextData as nvarchar(4000)),'0','X'),'1','X'),'2','X'),'3','X'),'4','X'),'5','X'),'6','X'),'7','X'),'8','X'),'9','X'),'XX','X'),'XX','X'),'XX','X'), 1, @Len)
Запрос Михаила, в оригинальном виде, не удалось использовать. Анализ трейса на 30-40 ГБайт выполняется долго. И тексты запросов в трейсе были такими, что никак не хотели группироваться. При коротком ключе (10 символов) все select и update запросы смешивались. А при длинном ключе (30 символов и более), вызовы хранимых процедур с GUID-параметрами создавали тысячи схожих ключей группировки:
exec [dbo].[getDoc] @id="128500FF-8B90-D060-B490-00CF4FC964FF" --exec [dbo].[getDoc] @id="XFF-X
exec [dbo].[getDoc] @id="AABBCCDD-0E0E-1234-B491-0D43C5F6C0F6" --exec [dbo].[getDoc] @id="AABBCНачал пробовать различные варианты расчёта ключа группировки. Результаты записывал в новую колонку таблицы профайлинга. А по этой колонке уже группировал результаты. Так всё и началось.
Совсем недавно, в пятницу, сидели с Мишей говорили о жизни непростой, да бороде густой. И забыл ему сказать, что статью буду писать.
От того, пока не знаю какая лицензия на скрипт Михаила. А лицензия на инструмент SQLProfilerReportHelper — BSD, свободная. Встраивайте скрипты трассировки в нагрузочные тесты, анализируйте трейсы, формируйте отчёты.
Инструмент доступен на Github: https://github.com/polarnik/SQLProfilerReportHelper.
Представленные в статье картинки отчётов старые, от того не особо секретные. Если заметили расхождение картинки отчёта и состава колонок в таблице-отчёте, формируемого инструментов, отнеситесь с пониманием.
Завершение
В руководстве описан процесс составления группирующих отчётов по данным профайлинга SQL Server. Это лишь десятая часть работ по выполнению тестирования производительности. Но яркая и важная.
В следующей части статьи расскажу про другие отчёты, которые формируются на основе трейсов.
