Network monitoring with intuition
Уже давно являюсь читателем Хабра, но написать статью заставило желание ответить на вопросы и, вероятно, диалог из первых уст. Прошу простить за возможную спутанность статьи — «чукча не писатель».
На Хабре уже есть несколько статей, посвященных данной системе («Мониторинг сетевого оборудования Cisco в системе Observium», «Observium — установка системы мониторинга») и мне хотелось бы их дополнить. В статье нет инструкций по установке или настройке, все это есть в официальной документации и по ссылкам, указанным выше.
В статье много картинок, некоторые спрятаны под спойлерами.
Observium, как гласит слоган на основном сайте, является системой мониторинга и наблюдения за сетевыми устройствами и серверами. При этом список поддерживаемых устройств огромен и не ограничивается только сетевыми устройствами, главное условие — чтобы устройство поддерживало работу SNMP. Но и кроме SNMP собираемая информация может быть дополнена другими способами и протоколами, например, syslog, rancid, unix-agent.
Немного истории. Изначально система создана «подданным его величества» Адамом Армстронгом примерно в 2005-2006 году (к сожалению, точную дату он и сам уже не помнит). В последствии к проекту присоединились еще разработчики, в том числе и ваш покорный слуга. Сначала система называлась Kikker (2005-2006), потом Project Observer (2006–2008), ObserverNMS (2008–2010) и, наконец, в 2010 году обрела текущее название Observium. Основным логотипом является хомяк индустриального вида.

Основной целью создания являлось создание системы с максимально простым управлением и наблюдением за устройствами, каковая остается и по сей день.
Модель распространения системы поделена на Community (выпускается раз в 6 месяцев) и Subscription (доступна подписчикам через непрерывные обновления stable/rolling).
Многим знакомы такие системы, как cacti, prtg, mrtg, но ни одна из них не сравнится по удобству добавления устройств и количеству поддерживаемых датчиков (по умолчанию).
Как выглядит процесс добавления нового устройства в систему:
1. Добавляем имя устройства (в командной строке или веб-интерфейсе).
2. Ждем 5-10 минут пока завершаться процессы discovery и первый poller, на этом всё.
Практически для добавления нового устройства достаточно настроек по умолчанию, необходимо только указать параметры авторизации, но и их можно добавить в общую конфигурацию и система будет автоматически проверять все заданные параметры авторизации.
Добавление устройства см. под спойлером
Добавление нового устройства:
Устройство добавлено, ждем завершения discovery/poller:

Устройство добавлено, ждем завершения discovery/poller:
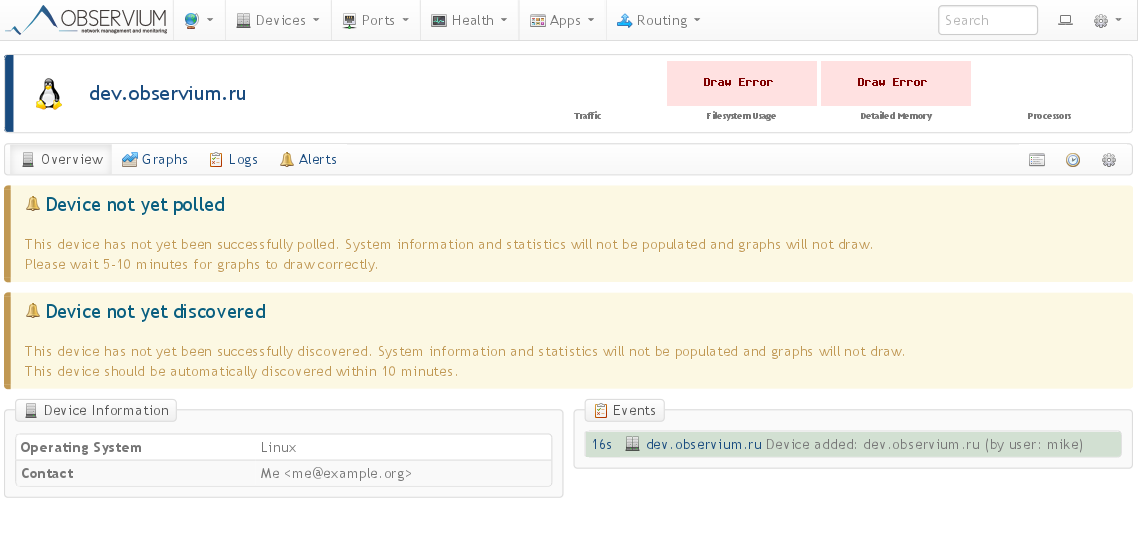
Обзор устройства:
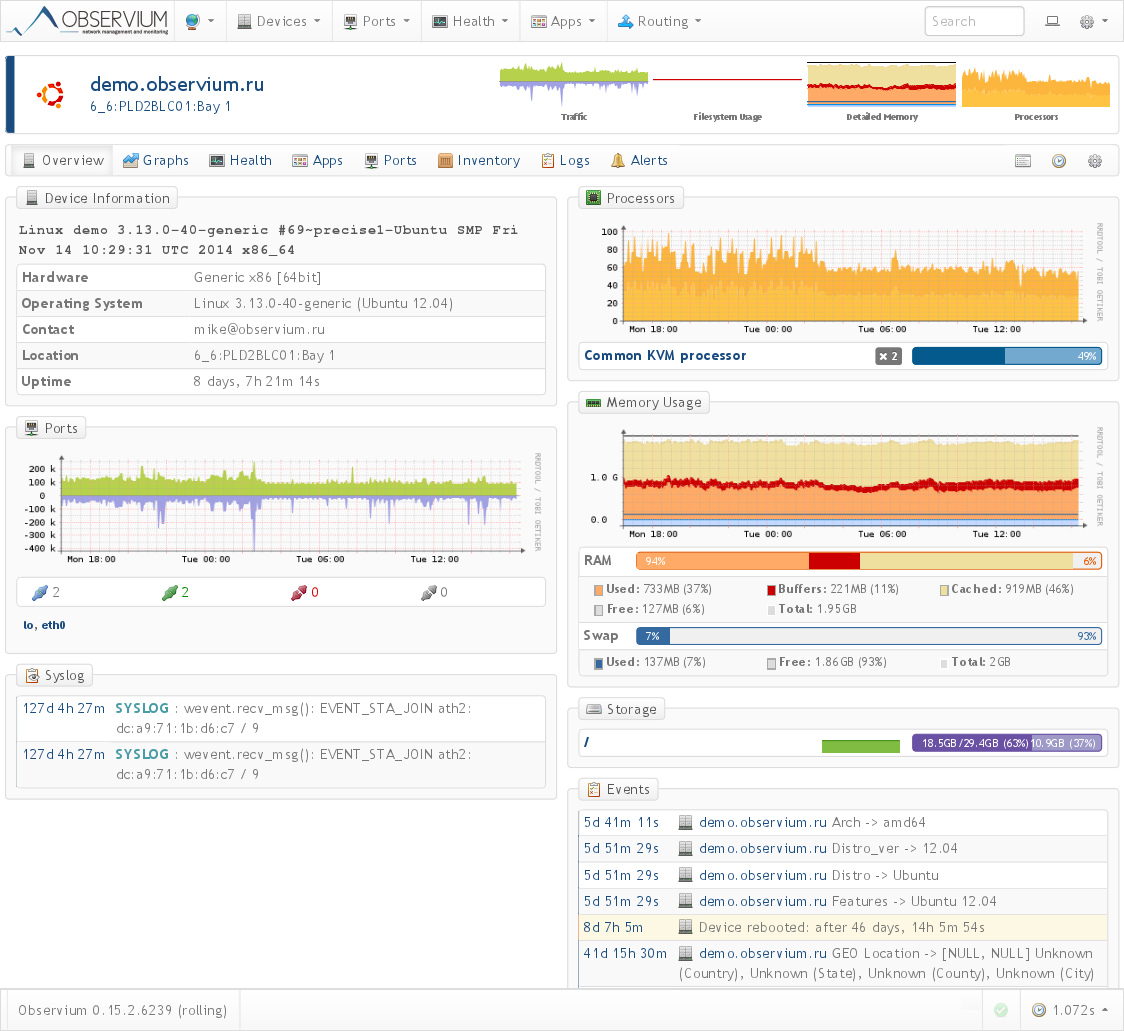
Кроме того, добавление новых устройств возможно в автоматизированном режиме из файла со списком устройств и/или через обнаружение устройств по протоколам CDP/LLDP и BGP/OSPF.
После того, как устройство было добавлено в систему, весь его «жизненный» цикл будет отслеживаться в автоматическом режиме. Например, если будет увеличена память или добавится новый датчик или добавтся/удалится порт — это все будет обнаружено без ручного вмешательства.
Весь сбор статистики поделен на 2 основных процесса:
- discovery, где выполняется основное обнаружение поддерживаемых на данном устройстве датчиков или счетчики;
- poller, где обнаруженные датчики опрашиваются каждые 5-ть минут;
Есть еще также 2 дополнительных процесса, работающих совместно с poller процессом, но они идут только в версии для подписчиков:
- bill, подсчет биллинговой информации на отдельных портах для пользователей;
- alert, это относительно недавно появившийся процесс для генерации уведомлений по практически любому собираемому системой параметру.
Процессы, в свою очередь, поделены на модули, соответствующие собираемой информации. Модулей много, основные — это os, system, ports, mempools, processors, sensors и другие. На снимке страницы выше можно заметить, что собираются такие параметры, как ОС, версия, начинка устройства.
И, наконец, модули поделены на MIBы, список который берется из файла определений для различных ОС.
Информация разнится в зависимости от производителя устройства, типа и доступных датчиков для конкретного устройства. Под спойлером несколько примеров:
Различные устройства
Cisco 7606

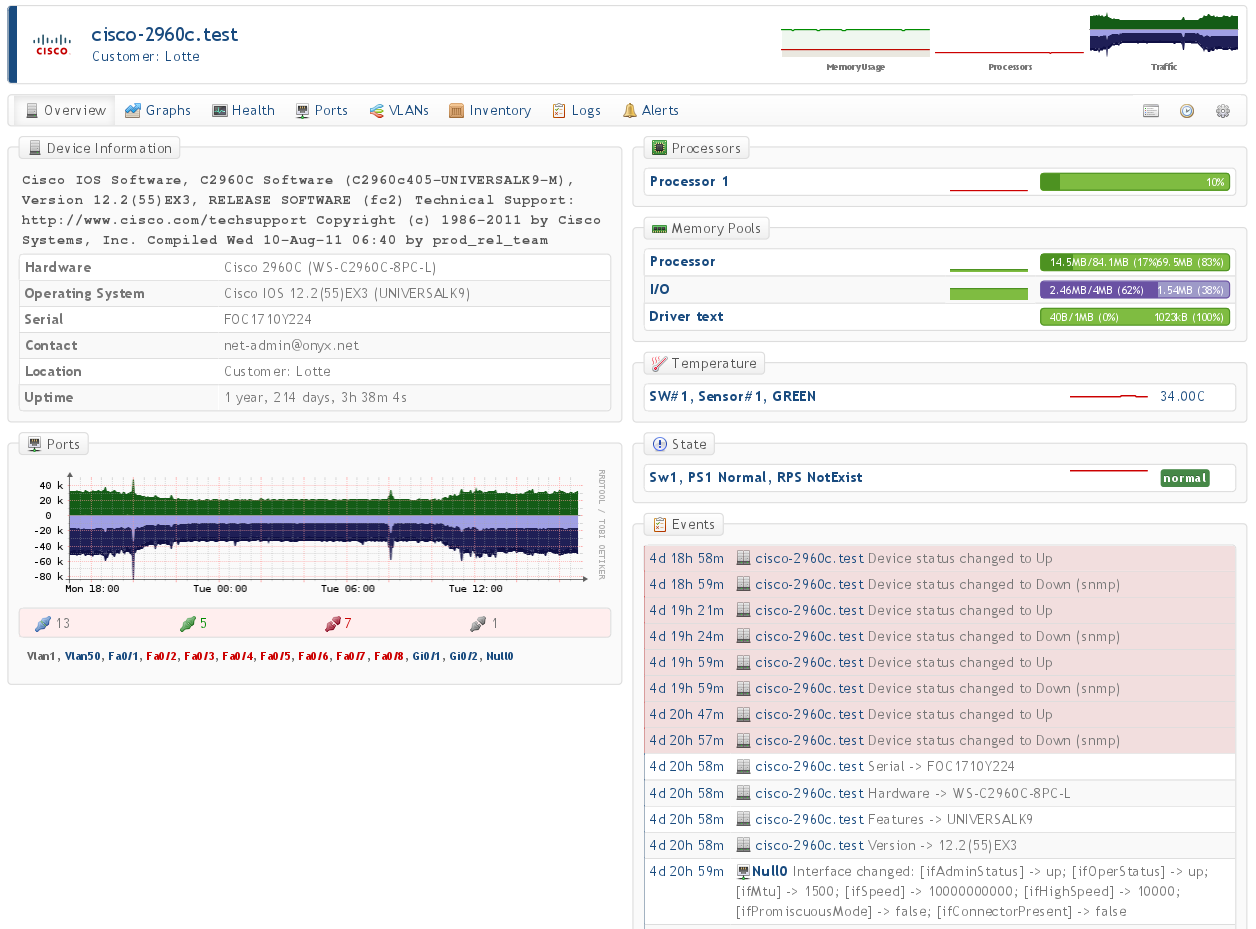
Cisco 2960C
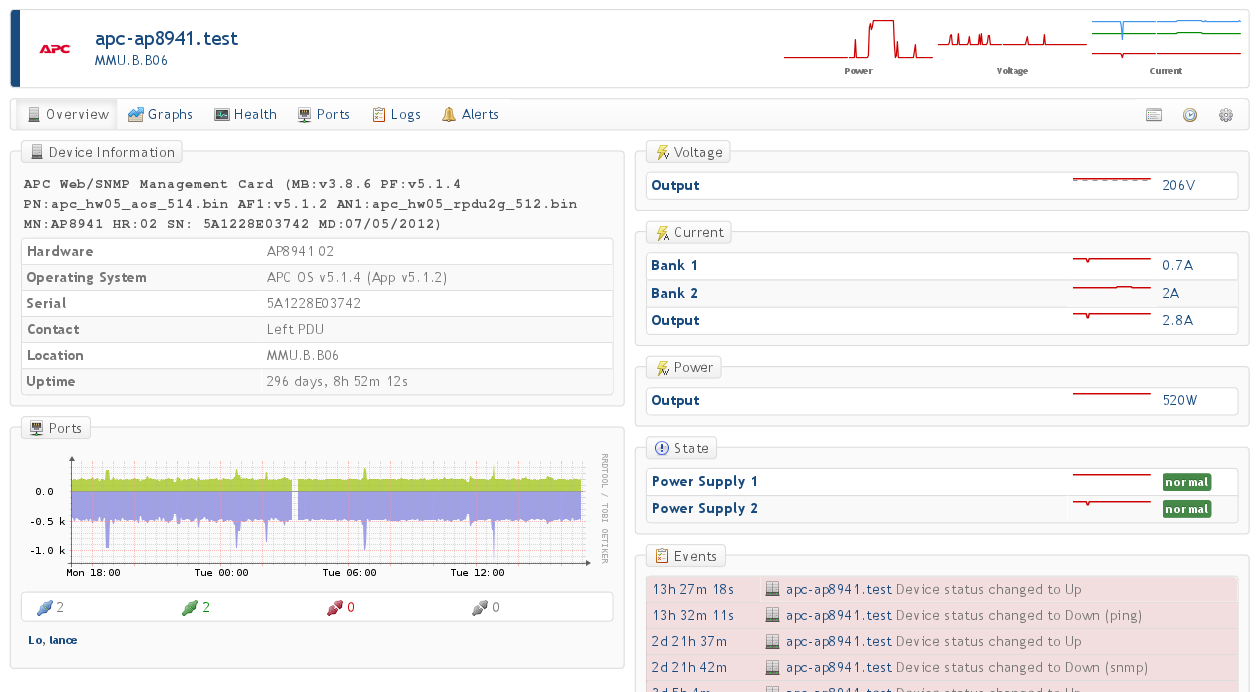
APC PDU
Olivetti printer


Cisco 2960C

APC PDU

Olivetti printer

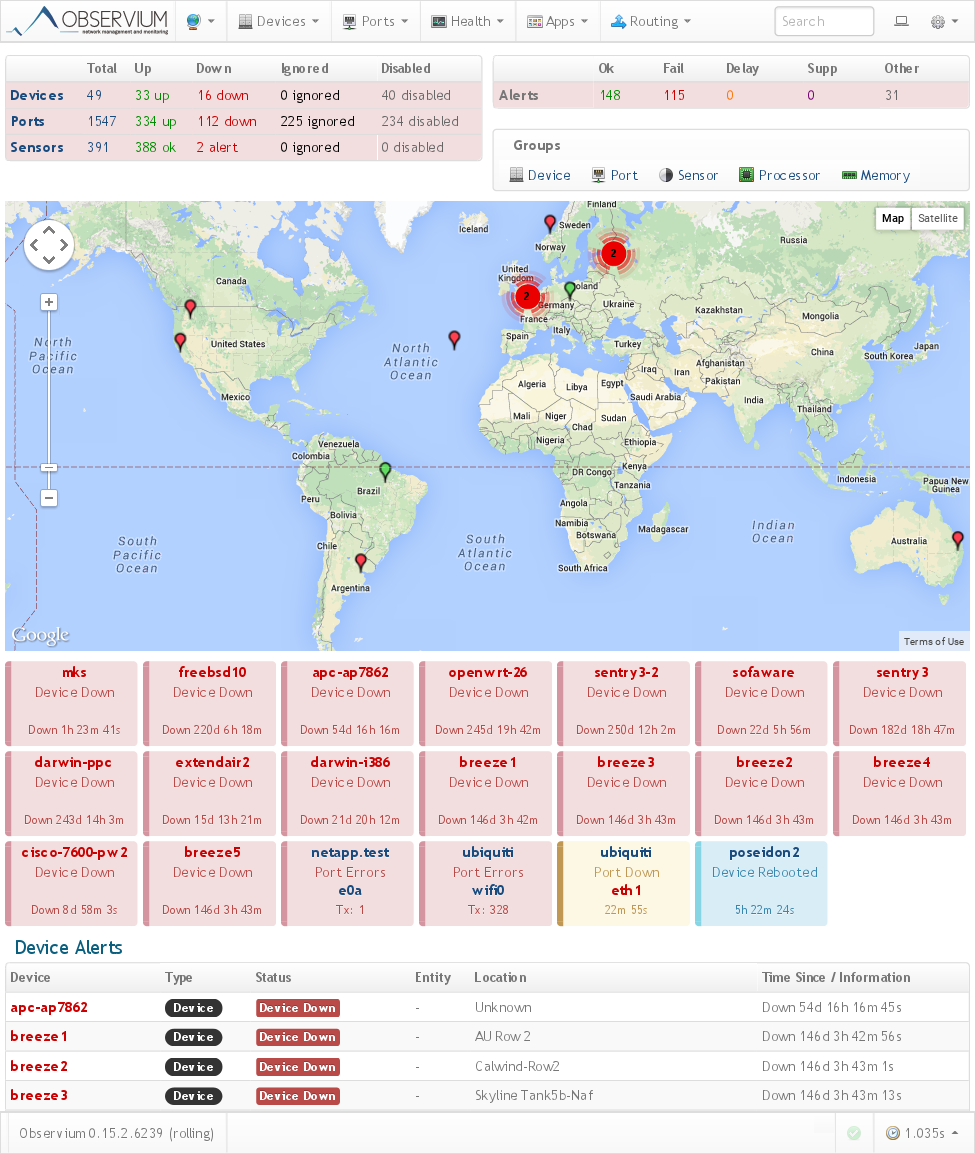
Обзорная страница:
Еще несколько спойлеров
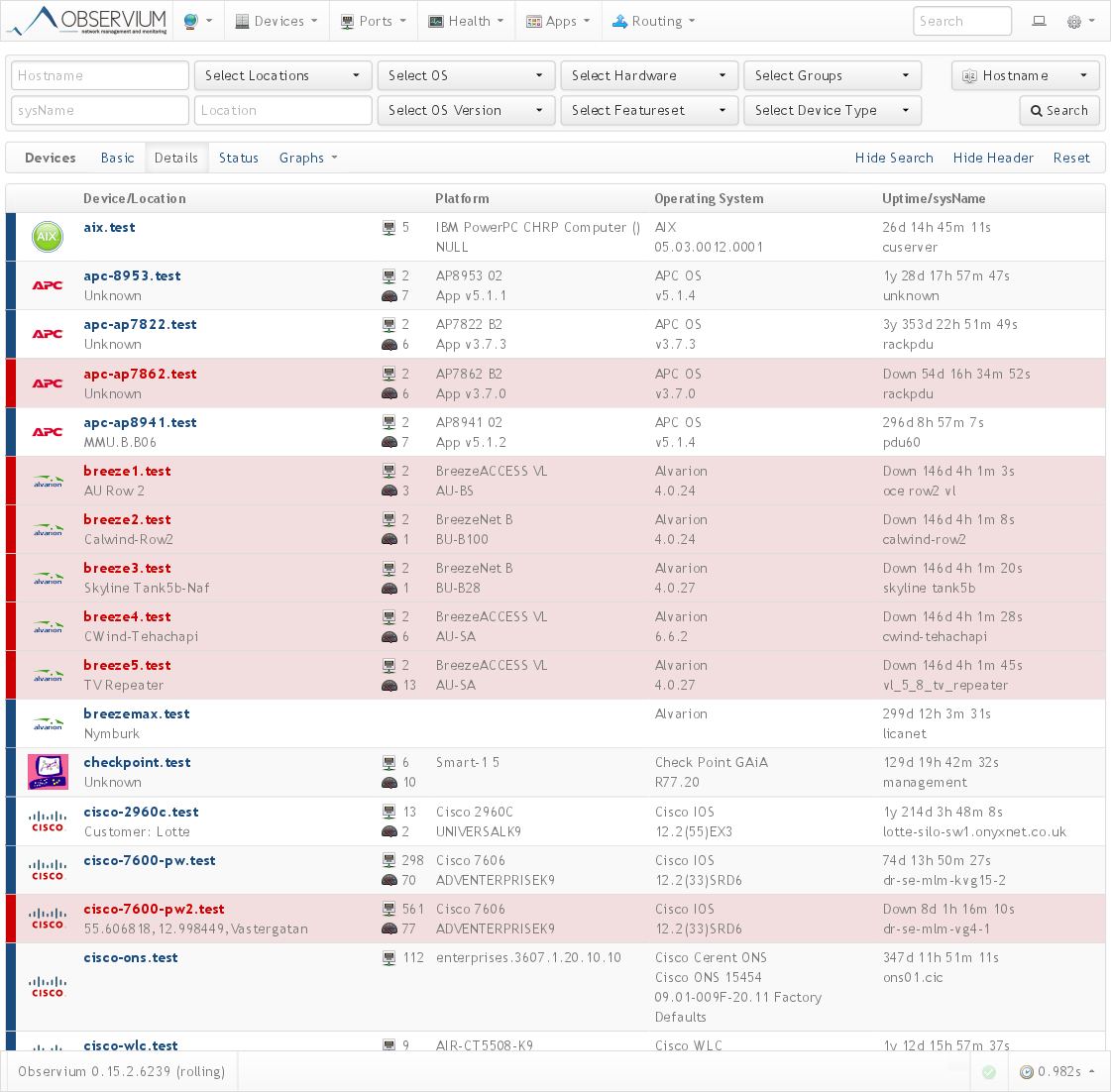
Обзор всех устройств:
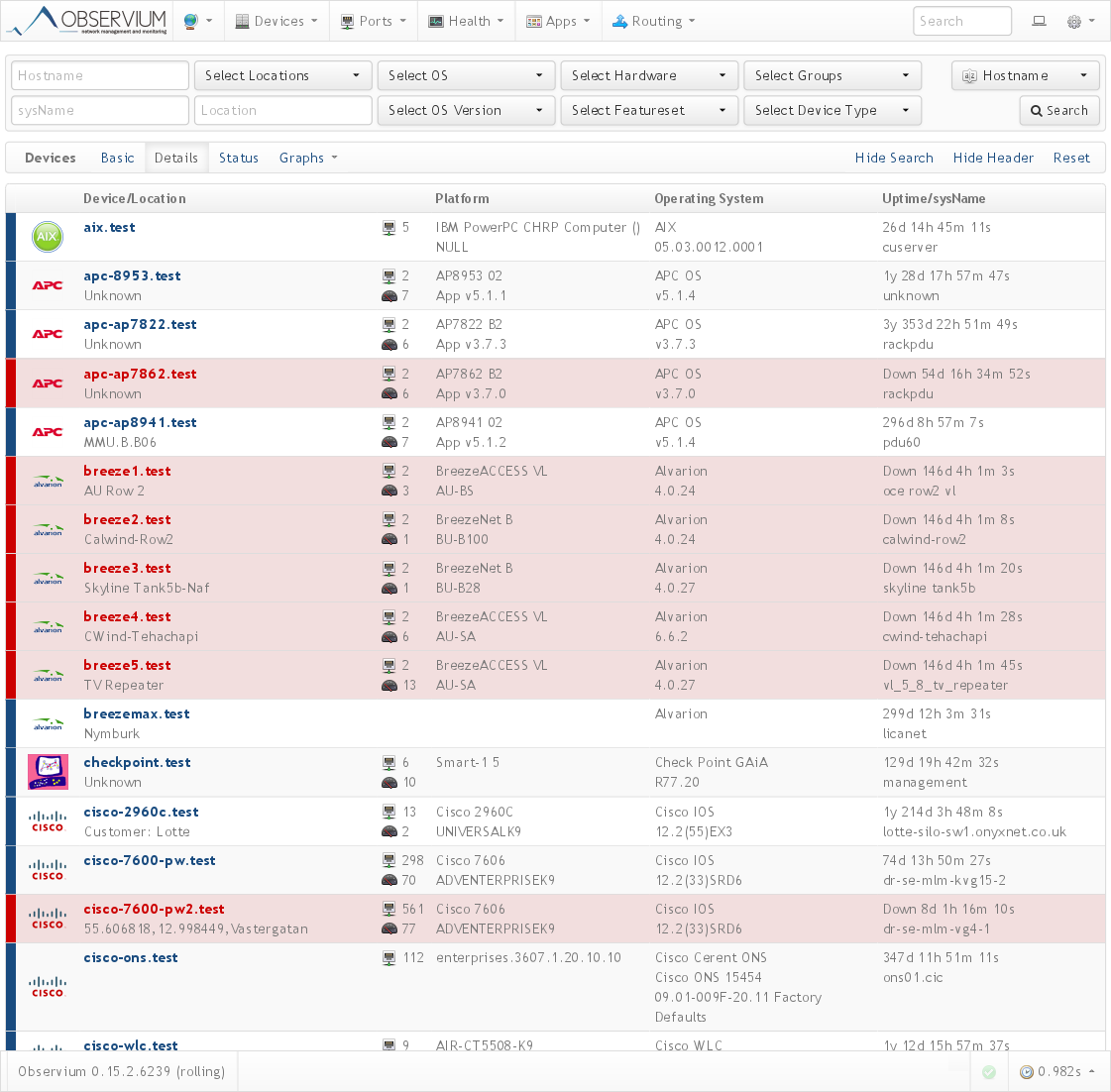
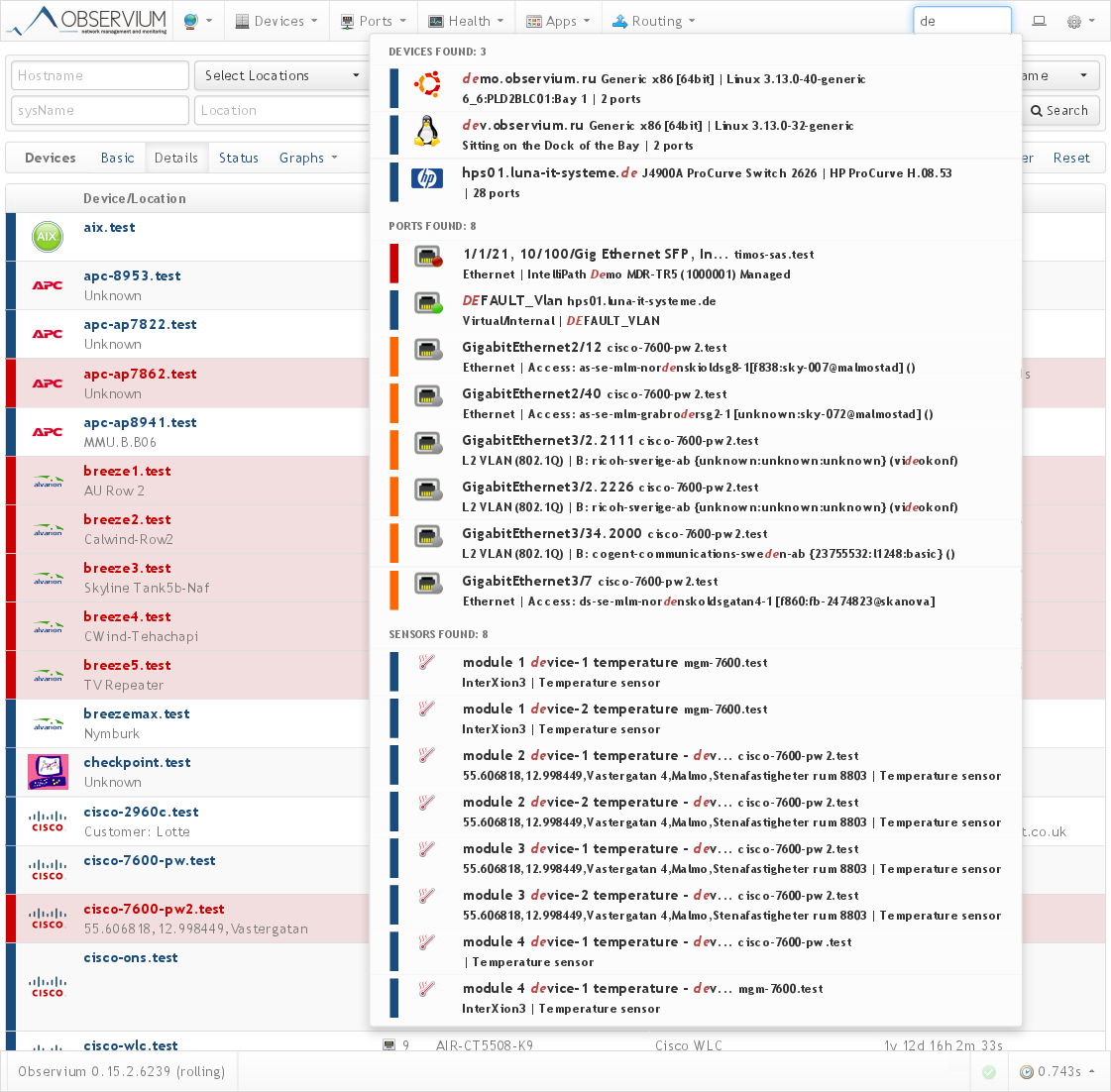
Быстрый поиск:
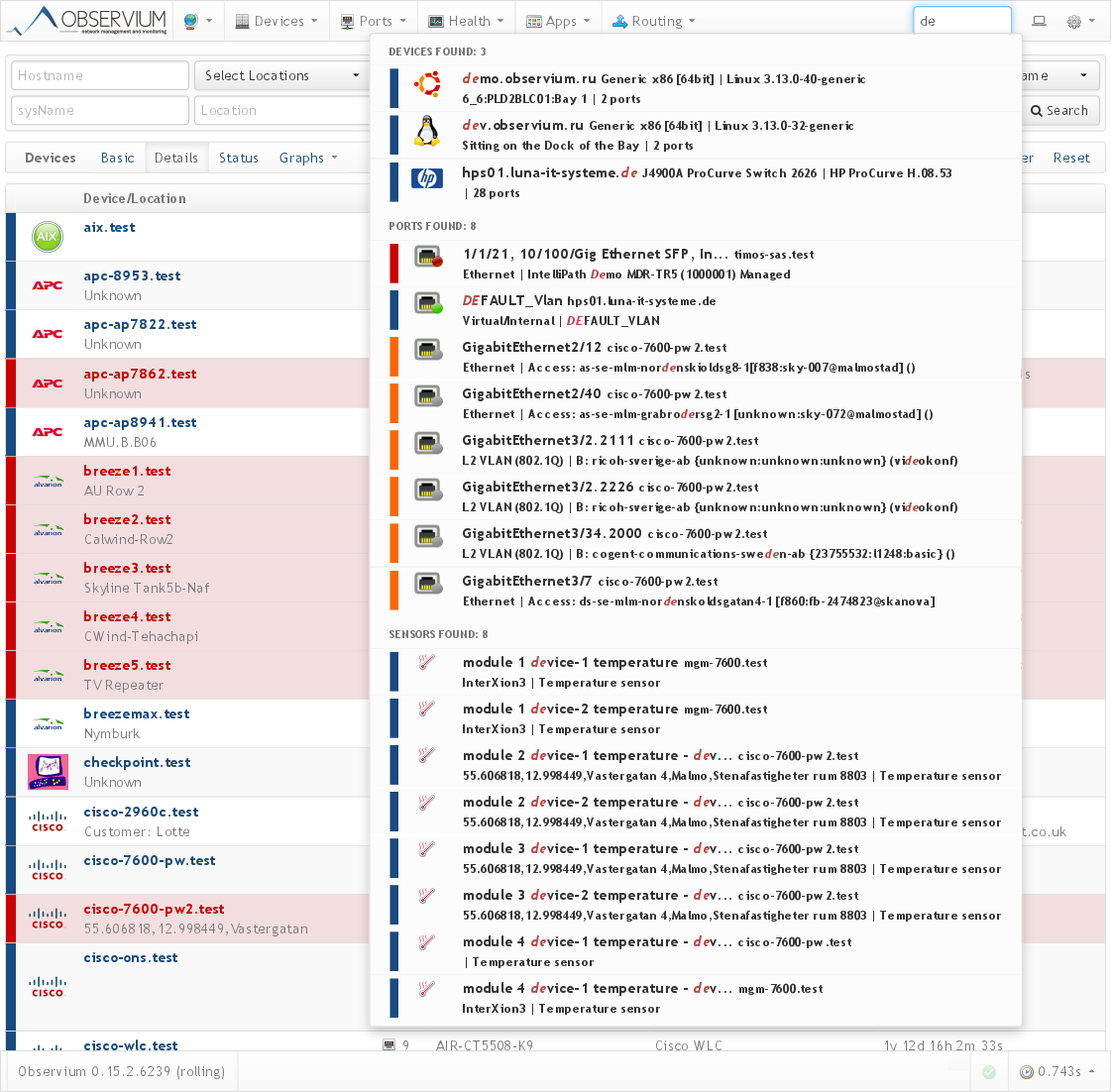
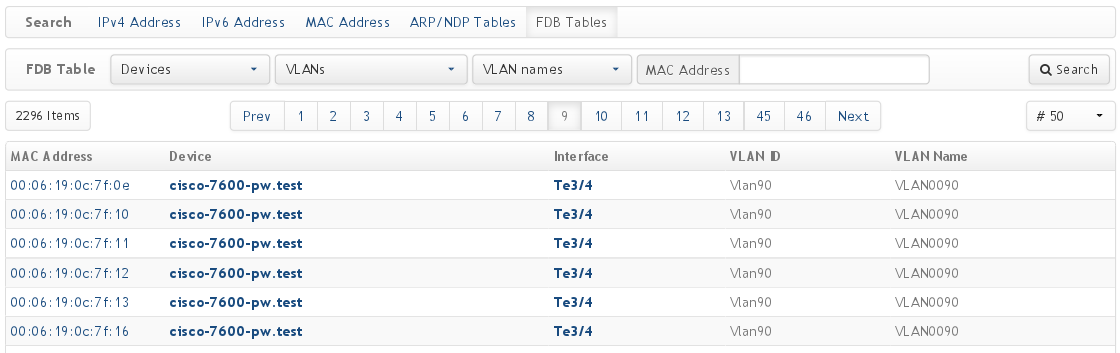
Поиск по IP/MAC/ARP/FDB:
BGP:

RANCID и история изменений конфигурации:


Быстрый поиск:
Поиск по IP/MAC/ARP/FDB:
BGP:
RANCID и история изменений конфигурации:


Система интегрируется с различными внешними утилитами, такие как syslog, rancid (в том числе показ последних изменений), collectd, smokeping, nfsen.
Поддерживается мониторинг датчиков по протоколу IPMI.
Есть мониторинг сервисов таких как Apache, Nginx, Mysql, Bind и других, через unix-agent.
Поддерживается мониторинг некоторых систем виртуализации.
Как упомянул выше, в платной версии имеется процесс для активных уведомлений. Он не заменит такие системы, как nagios/icinga или zabbix, так как на данный момент ограничен 5-ти минутными интервалами опроса устройств, но 60% потребностей по уведомлениям он способен обеспечить. А для систем с небольшим (<50) количеством устройств он полностью готов заменить любую другую систему. Под спойлером еще несколько картинок для него.
Активные уведомления
Правила проверки:
Текущие уведомления:

Лог уведомлений:


Текущие уведомления:

Лог уведомлений:
С картинками, наверно, хватит, всего не показать. Большинство возможностей можно увидеть на демо-странице (ох, только просьба не создавать хабраэффект) тут.
В остальном прошу задавать вопросы и пожелания, если надо чем-то дополнить статью.
