 Я бы хотел опубликовать цикл статей об измерениях характеристик систем связи и сетей передачи данных. Эта статья вводная и в ней будут затронуты лишь самые основы. В дальнейшем планирую более глубокое рассмотрение в стиле «как это сделано».
Я бы хотел опубликовать цикл статей об измерениях характеристик систем связи и сетей передачи данных. Эта статья вводная и в ней будут затронуты лишь самые основы. В дальнейшем планирую более глубокое рассмотрение в стиле «как это сделано».Покупая продукт или услугу мы часто оперируем таким понятием как качество. Что же такое качество? Если мы обратимся к словарю Ожегова, то там увидим следующее: «совокупность существенных признаков, свойств, особенностей, отличающих предмет или явление от других и придающих ему определенность». Перенося определение на область сетей связи, приходим к выводу, что нам требуется определить «существенные признаки, свойства и особенности», позволяющие однозначно определить отличие одной линии или сети связи от другой. Перечисление всех признаков и свойств обобщаются понятием «метрика». Когда кто-то говорит о метриках сетей связи, он имеет в виду те характеристики и свойства, которые позволят точно судить о системе связи в целом. Потребность в оценке качества лежит большей частью в экономической области, хотя и техническая её часть не менее интересна. Я же попробую балансировать между ними, чтобы раскрыть все самые интересные аспекты этой области знаний.
Всех заинтересовавшихся прошу под кат.
Мониторинг и диагностика систем связи
Как я писал выше, метрики качества определяют экономическую составляющую владения сетью или системой связи. Т.е. стоимость аренды или сдачи в аренду линии связи напрямую зависит от качества этой самой линии связи. Стоимость, в свою очередь, определяется спросом и предложением на рынке. Дальнейшие закономерности описаны у Адама Смита и развиты Милтоном Фридманом. Даже во времена СССР, когда была плановая экономика, а о «рынке» думали, как о преступлении против власти и народа, существовал институт госприемки, как для военных, так и гражданских целей, призванный обеспечить надлежащее качество. Но вернемся в наше время и попробуем определить эти метрики.
Рассмотрим сеть на основе Ethernet, как самой популярной технологии на данный момент. Не будем рассматривать метрики качества среды передачи данных, поскольку они мало интересуют конечного потребителя (разве что материал самой среды иногда бывает интересен: радио, медь или оптика). Самая первая метрика, которая приходит в голову — пропускная способность (bandwidth), т.е. сколько данных мы можем передать в единицу времени. Вторая, связанная с первой,- пакетная пропускная способность (PPS, Packets Per Second), отражающая сколько фреймов может быть передано в единицу времени. Поскольку сетевое оборудование оперирует фреймами, метрика позволяет оценить, справляется ли оборудование с нагрузкой и соответствует ли его производительность заявленной.
Третья метрика — это показатель потери фреймов (frame loss). Если невозможно восстановить фрейм, либо восстановленный фрейм не соответствует контрольной сумме, то принимающая, либо промежуточная система его отвергнет. Здесь имеется ввиду второй уровень системы OSI. Если рассматривать подробнее, то большинство протоколов не гарантируют доставку пакета получателю, их задача лишь переслать данные в нужном направлении, а те кто гарантирует (например, TCP) могут сильно терять в пропускной способности как раз из-за перепосылок фреймов (retransmit), но все они опираются на L2 фреймы, потерю которых учитывает эта метрика.
Четвертая — задержка (delay, latency),- т.е. через сколько пакет отправленный из точки A оказаться в точке B. Из этой характеристики можно выделить еще две: односторонняя задержка (one-trip) и круговая (round-trip). Фишка в том, что путь от A к B может быть один, а от B к A уже совсем другим. Просто поделить время не получится. А еще задержка время от времени может меняться, или “дрожать”,- такая метрика называется джиттером (jitter). Джиттер показывает вариацию задержки относительно соседних фреймов, т.е. девиацию задержки первого пакета относительно второго, или пятого относительно четвертого, с последующим усреднением в заданный период. Однако если требуется анализ общей картины или интересует изменение задержки в течении всего времени теста, а джиттер уже не отражает точно картину, то используется показатель вариации задержки (delay variation). Пятая метрика — минимальный MTU канала. Многие не придают важности этому параметру, что может оказаться критичным при эксплуатации “тяжелых” приложений, где целесообразно использовать jumbo-фреймы. Шестой, и малоочевидный для многих параметр — берстность — нормированная максимальная битовая скорость. По этой метрике можно судить о качестве оборудования, составляющего сеть или систему передачи данных, позволяет судить о размере буфера оборудования и вычислять условия надежности.
Об измерениях
Поскольку с метриками определились, стоит выбрать метод измерения и инструмент.
Задержка
Известный инструмент, поставляемый в большинстве операционных систем — утилита ping (ICMP Echo-Request). Многие ее используют по нескольку раз на дню для проверки доступности узлов, адресов, и т.п. Предназначена как раз для измерения RTT (Round Trip Time). Отправитель формирует запрос и посылает получателю, получатель формирует ответ и посылает отправителю, отправитель замеряя время между запросом и ответом вычисляет время задержки. Все понятно и просто, изобретать ничего не нужно. Есть некоторые вопросы точности и они рассмотрены в следующем разделе.
Но что, если нам надо измерить задержку только в одном направлении? Здесь все сложнее. Дело в том, что помимо просто оценки задержки пригодится синхронизировать время на узле отправителе и узле-получателе. Для этого придуман протокол PTP (Precision Time Protocol, IEEE 1588). Чем он лучше NTP описывать не буду, т.к. все уже расписано здесь, скажу лишь то, что он позволяет синхронизировать время с точностью до наносекунд. В итоге все сводится к ping-like тестированию: отправитель формирует пакет с временной меткой, пакет идет по сети, доходит до получателя, получатель вычисляет разницу между временем в пакете и своим собственным, если время синхронизировано, то вычисляется корректная задержка, если же нет, то измерение ошибочно.
Если накапливать информацию об измерениях, то на основании исторических данных о задержке можно без труда построить график и вычислить джиттер и вариацию задержки — показатель важный в сетях VoIP и IPTV. Важность его связана, прежде всего, с работой энкодера и декодера. При “плавающей” задержке и адаптивном буфере кодека повышается вероятность не успеть восстановить информацию, появляется “звон” в голосе (VoIP) или “перемешивание” кадра (IPTV).
Потери фреймов
Проводя измерения задержки, если ответный пакет не был получен, то предполагается, что пакет был потерян. Так поступает ping. Вроде тоже все просто, но это только на первый взгляд. Как написано выше, в случае с ping отправитель формирует один пакет и отправляет его, а получатель формирует свой собственный о отправляет его в ответ. Т.е. имеем два пакета. В случае потери какой из них потерялся? Это может быть не важно (хотя тоже сомнительно), если у нас прямой маршрут пакетов соответствует обратному, а если это не так? Если это не так, то очень важно понять в каком плече сети проблема. Например, если пакет дошел до получателя, то прямой путь нормально функционирует, если же нет, то стоит начать с диагностики этого участка, а вот если пакет дошел, но не вернулся, то точно не стоит тратить время на траблшутинг исправного прямого сегмента. Помочь в идентификации могла бы порядковая метка, встраиваемая в тестовый пакет. Если на обоих концах стоят однотипные измерители, то каждый из них в любой момент времени знает количество отправленных и полученных им пакетов. Какие именно из пакетов не дошли до получателя можно получить сравнением списка отправленных и полученных пакетов.
Минимальный MTU
Измерение этой характеристики не то чтобы сложно, скорее оно скучно и рутинно. Для определения минимального размера MTU (Maximum transmission unit) следует лишь запускать тест (тот же ping) с различными значениями размеров кадра и установленным битом DF (Don't Fragmentate), что приведет к непрохождению пакетов с размером кадра больше допустимого, ввиду запрета фрагментации.
Например, так не проходит:
$ ping -s 1500 -Mdo 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 1500(1528) bytes of data.
ping: local error: Message too long, mtu=1500
ping: local error: Message too long, mtu=1500
^C
--- 8.8.8.8 ping statistics ---
2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 1006ms
А так уже проходит:
$ ping -s 1400 -Mdo 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 1400(1428) bytes of data.
1408 bytes from 8.8.8.8: icmp_seq=1 ttl=48 time=77.3 ms
1408 bytes from 8.8.8.8: icmp_seq=2 ttl=48 time=76.8 ms
1408 bytes from 8.8.8.8: icmp_seq=3 ttl=48 time=77.1 ms
^C
--- 8.8.8.8 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 76.839/77.133/77.396/0.393 ms
Не часто используемая метрика с коммерческой точки зрения, но актуальная в некоторых случаях. Опять же, стоит отметить, что при асимметричном пути следования пакетов, возможен различный MTU в разных направлениях.
Пропускная способность
Наверняка многим известен факт, что количество переданной полезной информации в единицу времени зависит от размера фрейма. Связано это с тем, что фрейм содержит довольно много служебной информации — заголовков, размер которых не меняется при изменении размера фрейма, а изменяется поле “полезной” части (payload). Это значит, что несмотря на то, что даже если мы передаем данные на скорости линка, количество полезной информации переданной за тот же период времени может сильно варьироваться. Поэтому несмотря на то, что существуют утилиты для измерения пропускной способности канала (например iperf), часто невозможно получить достоверные данные о пропускной способности сети. Все дело в том, что iperf анализирует данные о трафике на основе подсчета той самой «полезной» части, окруженной заголовками протокола (как правило UDP, но возможен и TCP), следовательно нагрузка на сеть (L1,L2) не соответствует подсчитанной (L4). При использовании аппаратных измерителей скорость генерации трафика устанавливается в величинах L1, т.к. иначе было бы не очевидно для пользователя почему при измерении размера кадра меняется и нагрузка, это не так заметно, при задании ее в %% от пропускной способности, но очень бросается в глаза при указании в единицах скорости (Mbps, Gbps). В результатах теста, как правило, указывается скорость для каждого уровня (L1,L2,L3,L4). Например, так (можно переключать L2, L3 в выводе):
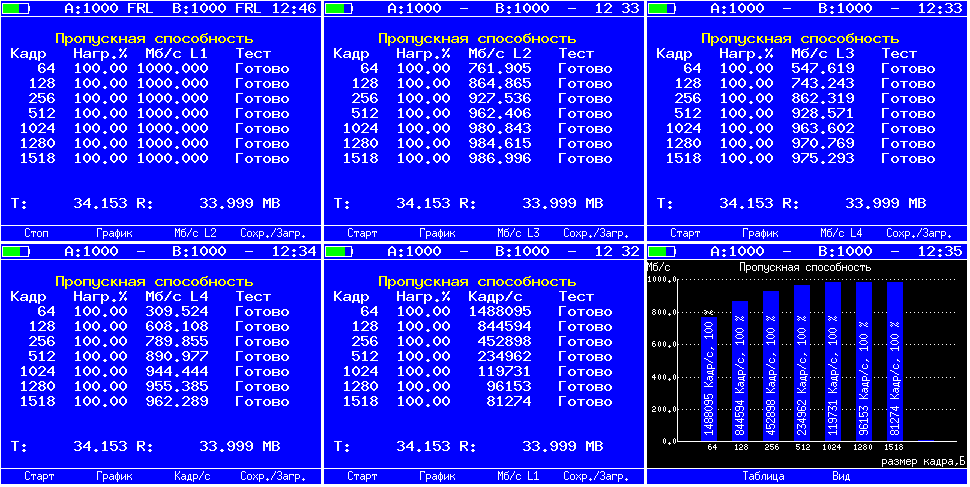
Пропускная способность в кадрах в секнду
Если говорить о сети или системе связи как о комплексе линий связи и активного оборудования, обеспечивающего нормальное функционирование, то эффективность работы такой системы зависит от каждого составляющего ее звена. Линии связи должны обеспечивать работу на заявленных скоростях (линейная скорость), а активное оборудование должно успевать обрабатывать всю поступающую информацию.
У всех производителей оборудования заявляется параметр PPS (packets per second), прямо указывающий сколько пакетов способно «переварить» оборудование. Ранее этот параметр был очень важен, поскольку подавляющее число техники просто не могло обработать огромное количество “мелких” пакетов, сейчас же все больше производители заявляют о wirespeed. Например, если передаются малые пакеты, то времени на обработку тратится, как правило, столько же, сколько и на большие. Поскольку содержимое пакета оборудованию не интересно, но важна информация из заголовков — от кого пришло и кому передать.
Сейчас все большее распространение в коммутирующем оборудовании получают ASIC (application-specific integrated circuit) — специально спроектированные для конкретных целей микросхемы, обладающие очень высокой производительностью, в то время как раньше довольно часто использовались FPGA (field-programmable gate array) — подробнее об их применении можно прочитать у моих коллег здесь и послушать здесь.
Бёрстность
Стоит отметить, что ряд производителей экономит на компонентах и использует малые буферы для пакетов. Например заявлена работа на скорости линка (wirespeed), а по факту происходят потери пакетов, связанные с тем, что буфер порта не может вместить в себя больше данных. Т.е. процессор еще не обработал скопившуюся очередь пакетов, а новые продолжают идти. Часто такое поведение может наблюдаться на различных фильтрах или конвертерах интерфейсов. Например предполагается, что фильтр принимает 1Gbps поток и направляет результаты обработки в 100Mbps интерфейс, если известно, что отфильтрованный трафик заведомо меньше 100Mbps. Но в реальной жизни случается так, что в какой-то момент времени может возникнуть «всплеск» трафика более 100Mbps и в этой ситуации пакеты выстраиваются в очередь. Если величина буфера достаточна, то все они уйдут в сеть без потерь, если же нет, то просто потеряются. Чем больше буфер, тем дольше может быть выдержана избыточная нагрузка.
Погрешности измерения
Но наука метрология не была бы наукой, если бы описывала только что и как измерять по своему усмотрению. Наукой область знаний становится тогда, когда определяются характеристики методов исследования, базирующиеся на подтвержденных знаниях. Одной из таких метрологических характеристик является то, что сам измерительный инструмент не должен вносить свою погрешность в процесс измерения, либо эта погрешность должна быть достоверно известна и определена. В случаях, когда мы имеем дело с инструментами на базе программного обеспечения и операционными системами общего назначения погрешность измерения, к сожалению, невозможно точно определить, а соответственно невозможно соответственно градуировать средство измерения. Все дело в том, что процессы, происходящие при обработке данных, получении пакетов из сети, формировании ответов носят вероятностный характер, связанный с архитектурой операционной системы. Попробую объяснить на примере ping’а:
- программа замеряет время, формирует пакет с данными, и отдает его ОС для «спуска» по OSI;
- OC ставит пакет в очередь, затем обрабатывает, при необходимости надевая недостающие инкапсуляции, дергает контекст, кладет пакет в буфер сетевой карты через драйвер, который тоже имеет, как правило кольцевой буфер;
- пакет путешествует по сети, пока не дойдет до получателя;
- сетевая карта получателя, приняв пакет и положив в буфер порождает прерывание;
- ОС получателя, остановив другие обработки, читает пакет и ставит в очередь на обработку, обрабатывает, отсылает назад (если говорим о ping), либо дергает контекст и отдает программе на обработку (если обработка не “ядерная”), т.е. повторяются пункты 1-2 только на стороне получателя;
- пакет снова путешествует по сети, только в обратном направлении (и не факт что точно соответствующему прямому);
- повторяются пункты 4-5 для отправителя;
- программа отправителя вычисляет время между началом 1 и завершением 7.
Таким образом, мы получили время от формирования программой пакета до времени получения ей же ответного пакета, вместо того, чтобы получить сумму по пунктам 3 и 6, т.е. в задержке учтены «паразитные» участки. Решением проблемы подобного рода будет вставка в пакет временной метки как можно ближе к выходу в сеть, т.е. хотя бы буфере сетевой карты. Это позволит отсечь “паразитное” влияние пунктов 1-2, но остается еще 4-5. На получателе следует возвращать пакет без обработки в операционной системе, например просто свопнув MAC получателя и отправителя. Получивший такой пакет начальный отправитель может сравнить начальную метку, установленную на выходе в сеть с текущей меткой на входе из сети и сделать намного более точный расчет задержки. Наглядный пример можно увидеть измеряя задержку в режиме эхо-запроса и в режиме сертифицированного теста на нашем «Беркут-ET» или «Беркут-ETX». В некоторых системах, в силу особенностей архитектуры, эхо-запрос может показать значения в районе 30-60 мс в прямом соединении (cross-connect), в то время как сертифицированный тест покажет 8-16 нс, т.е. разница на порядок. Два компьютера, скорее всего, покажут лучший результат, но внесенная ими погрешность в измерение задержки не может быть учтена. А эхо-запрос в нашем приборе присутствует не для измерения задержки как таковой, а в качестве стандартного инструмента проверки доступности какого-либо узла в сети.
Заключение
Следующие метрики являются основными и опорными для оценки качества сетей и систем связи:
- пропускная способность
- пакетная пропускная способность
- потери фреймов
- задержка
- one-trip
- round-trip
- jitter
- delay variation
- минимальный MTU
- бёрстность
Общим принципом измерений — генерация (или оценка) тестовых пакетов как можно ближе к выходу (или ко входу) измеряемого участка, в противном случае невозможно обеспечить точность из-за возрастания числа факторов, влияющих на измерения. На данный момент распространены и применяются такие методики тестирования как RFC2544 и Y.1564. О принципах работы наших приборов и специфике тестов можно написать очень много. Как раз в следующих публикациях планирую раскрыть некоторые секреты.
Всем спасибо за внимание.
