def maps():
print "maps maps maps"
def spam():
print "Erasing everything..."
print "done."
Вы знаете, что если очень долго смотреть на следующую строку, то там останутся только три слова «spam»?
s = "spam" ,spam ,"spam"
s[1]()
Действительно, первая строка очень необычная. В целом, в результате этого кода будет выполнена зловредная функция spam.
Посмотреть на ideone. (Для тех кто не знает: там внизу есть вывод выполнившейся программы)
RLO
В основе нашей проблемы с двунаправленным письмом лежит идея о том, что в памяти текст всегда хранится в порядке записи его человеком. В том числе при письме справа-налево, при котором текст будет отрисовываться в обратном привычному направлении.
Направление отрисовки определяется автоматически по принадлежности символов конкретному алфавиту (ивриту, например) или, если это знак пунктуации или цифра, то по более хитрым правилам, в зависимости от контекста.
RLO — символ форматирования, расшифровывается как right-to-left override. Меняет направление письма на правостороннее для символов с дефолтно-левосторонним письмом. (В стандарте написано, что это может использоваться для записи таких вот идентификаторов, когда те состоят из смешанного иврита и английского и, видимо, английские включения естественно читаются справа-налево).
Ну так вот. Благодаря ему мы можем получить нашу прелесть:
s = "spam<RLO>" ,spam ,"<PDF>spam"
s = "spam" ,spam ,"spam"
PDF расшифровывается как pop directional formatting, сбрасывает эффект последнего RLO или его друзей.
Нетрудно догадаться, что интерпретатор окажется равнодушен к непонятным символам в строковых литералах. А вот некоторые редакторы, вроде emacs*, Xcode, Kate, развернут промежуточный текст именно так, как это делает браузер.
* в случае emacs, возможно, поведение зависит от терминала. Но в vim и nano проблемы в том же терминале нет: оба показывают только код символа RLO в соответствующей позиции.
О других вариантах использования в коде
Символ RLO не является вайтспейсовым, кроме того, python ругается на него в составе идентификаторов, что немного ограничивает возможности применения.
Его приходится класть в строковые литералы, либо в комментарии. При этом к концу каждой строки файла, как параграфа, действие RLO заканчивается.
Картинки
vim
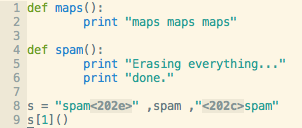
sublime text
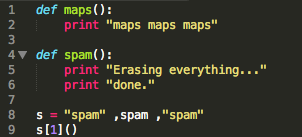
xcode

emacs

… и еще раз ссылка на ideone.
upd: есть еще вот такой вариант с Embedding и Mark
Бонус
«rm -rf echo», которая на самом деле только печатает «rm -rf»
echo -e '\xe2\x80\x8f\xe2\x80\xaaecho \xe2\x80\xac\xe2\x80\x8f\xe2\x80\xaarm -rf \xe2\x80\xac\xe2\x80\x8f'bash почему-то игнорирует символы форматирования в начале команды, чем открывает большой простор для злодействия.
