Так уж случилось, что последнее время приходилось заниматься оптимизацией и масштабированием различных систем. Одной из задач было масштабирование PostgreSQL. Как обычно происходит оптимизация БД? Наверное, в первую очередь смотрят на то, как правильно выбрать оптимальные настройки для работы и какие индексы можно создать. Если обойтись малой кровью не вышло, переходят к наращиванию мощностей сервера, выносу файлов журнала на отдельный диск, балансировке нагрузки, разбиению таблиц на партиции и к всякого рода рефакторингу и перепроектированию модели. И вот уже все идеально настроено, но наступает момент, когда всех этих телодвижения оказывается недостаточно. Что делать дальше? Горизонтальное масштабирование и шардинг данных.

Хочу поделиться опытом развертывания горизонтально масштабируемого кластера на СУБД Postgres-XL.
Postgres-XL — прекрасный инструмент, который позволяет объединить несколько кластеров PostgreSQL таким образом, чтоб они работали как один инстанс БД. Для клиента, который подключается в базе, нет никакой разницы, работает он с единственным инстансом PostgreSQL или с кластером Postgres-XL. Postgres-XL предлагает 2 режима распределения таблиц по кластеру: репликация и шардинг. При репликации все узлы содержат одинаковую копию таблицы, а при шардинге данные равномерно распределяются среди членов кластера. Текущая реализация основана на PostgreSQL-9.2. Так что вам будут доступны почти все фичи версии 9.2.
Postgres-XL состоит из трех типов компонентов: глобальный монитор транзакций (GTM), координатор (coordinator) и узел данных (datanode).
GTM — отвечает за обеспечение требований ACID. Ответственен за выдачу идентификаторов. Так как является единой точкой отказа, то рекомендуется подпирать с помощью GTM Standby. Выделение отдельного сервера для GTM является хорошей идеей. Для объединений множественных запросов и ответов от координаторов и узлов данных запущенных на одном сервере имеет смысл настроить GTM-Proxy. Таким образом снижается нагрузка на GTM так как уменьшается общее количество взаимодействий с ним.
Координатор — центральная часть кластера. Именно с ним взаимодействует клиентское приложение. Управляет пользовательскими сессиями и взаимодействует с GTM и узлами данных. Парсит запросы, строит план выполнения запросов и отсылает его на каждый из компонентов участвующий в запросе, собирает результаты и отсылает их обратно клиенту Координатор не хранит никаких пользовательских данных. Он хранит только служебные данные, чтобы определить как обрабатывать запросы, где находятся узлы данных. При выходе из строя одного из координаторов можно просто переключиться на другой.
Узел данных — место где хранятся пользовательские данные и индексы. Связь с узлами данных осуществляется только через координаторы. Для обеспечения высокой доступности можно подпереть каждый из узлов stanby сервером.
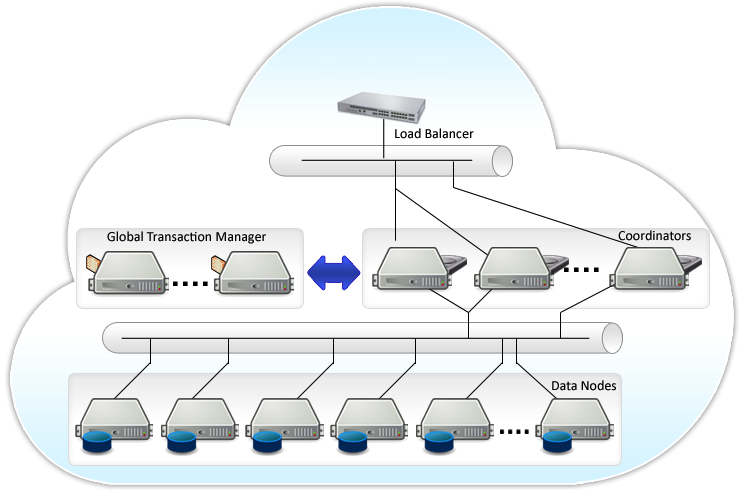
В качестве балансировщика нагрузки можно использовать pgpool-II. О его настройке уже много рассказывалось на хабре, например, тут и тут Хорошей практикой является установка координатора и узла данных на одной машине, так как нам не нужно заботиться о балансировке нагрузке между ними и данные из реплицируемых таблиц можно получить на месте без отправки дополнительного запроса по сети.
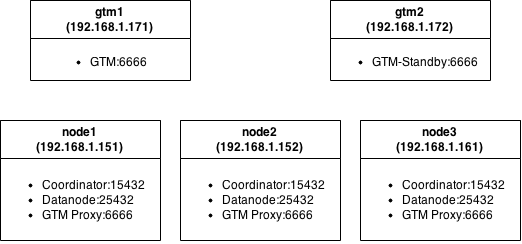
Каждый узел это виртуальная машина со скромным аппаратным обеспечением: MemTotal: 501284 kB, cpu MHz: 2604.
Тут все стандартно: качаем исходники с офсайта, доставляем зависимости, компилируем. Собирал на Ubuntu server 14.10.
После того как пакет собран заливаем его на узлы кластера и переходим к настройке компонентов.
Для обеспечения отказоустойчивости рассмотрим пример с настройкой двух GTM серверов. На обоих серверах создаем рабочий каталог для GTM и инициализируем его.
После чего переходим к настройке конфигов:
gtm1
gtm2
Сохраняем, стартуем:
В логах наблюдаем записи:
LOG: Started to run as GTM-Active.
LOG: Started to run as GTM-Standby.
После правки конфига можно запускать:
Для остальных узлов настройка отличается только указанием другого имени.
Теперь правим pg_hba.conf:
Все готово и можно запускать.
Заходим на координатор:
Выполняем запрос:
Запрос показывает как текущей сервер видит наш кластер.
Пример вывода:
Эти настройки неверны и их можно смело удалять.
Создаем новое отображение нашего кластера:
На остальных узлах нужно выполнить тоже самое.
Узел данных не позволит полностью очистить информацию, но ее можно перезаписать:
Теперь все настроено и работает. Создадим несколько тестовых таблиц.
Было создано 4 таблицы с одинаковой структурой, но разной логикой распределения по кластеру.
Данные таблицы test1 будут храниться только на 2х узлах данных — datanode1 и datanode2, а распределятся они будут по алгоритму roundrobin. Остальные таблицы задействуют все узлы. Таблица test2 работает в режиме репликации. Для определения на каком сервере будут храниться данные таблицы test3 используется хеш-функция по полю id, а для определения логики распределения test4 берется модуль по полю status. Попробуем теперь заполнить их:
Запросим теперь эти данные и посмотрим, как работает планировщик
Планировщик сообщает нам о том сколько узлов будет участвовать в запросе. Так как table2 реплицируется на все узлы, то просканирован будет только 1 узел. Кстати неясно по какой логике он выбирается. Логично было бы, чтоб он запрашивал данные с того же узла на котором и координатор.
Подключившись к узлу данных (на порт 25432) можно увидеть как были распределены данные.
Теперь давайте попробуем заполнить таблицы большим объемом данных и сравнить производительность запросов со standalone PostgreSQL.
Запрос в кластере Postgres-XL:
Этот же запрос на сервере с PostgreSQL:
Наблюдаем двукратное увеличение скорости. Не так уж и плохо, если у вас в распоряжении есть достаточное количество машин, то такое масштабирование выглядит довольно перспективно.
Как было замечено в комментариях интересно было бы посмотреть на join таблиц распределенных по нескольким узлам. Давайте попробуем:
Запрос на тех же объемах данных, но на standalone сервере:
Тут выигрыш всего лишь в 1,5 раза.
P.S. Надеюсь, данный пост поможет кому-нибудь. Комментарии и дополнения приветствуются! Благодарю за внимание.

Хочу поделиться опытом развертывания горизонтально масштабируемого кластера на СУБД Postgres-XL.
Postgres-XL — прекрасный инструмент, который позволяет объединить несколько кластеров PostgreSQL таким образом, чтоб они работали как один инстанс БД. Для клиента, который подключается в базе, нет никакой разницы, работает он с единственным инстансом PostgreSQL или с кластером Postgres-XL. Postgres-XL предлагает 2 режима распределения таблиц по кластеру: репликация и шардинг. При репликации все узлы содержат одинаковую копию таблицы, а при шардинге данные равномерно распределяются среди членов кластера. Текущая реализация основана на PostgreSQL-9.2. Так что вам будут доступны почти все фичи версии 9.2.
Терминология
Postgres-XL состоит из трех типов компонентов: глобальный монитор транзакций (GTM), координатор (coordinator) и узел данных (datanode).
GTM — отвечает за обеспечение требований ACID. Ответственен за выдачу идентификаторов. Так как является единой точкой отказа, то рекомендуется подпирать с помощью GTM Standby. Выделение отдельного сервера для GTM является хорошей идеей. Для объединений множественных запросов и ответов от координаторов и узлов данных запущенных на одном сервере имеет смысл настроить GTM-Proxy. Таким образом снижается нагрузка на GTM так как уменьшается общее количество взаимодействий с ним.
Координатор — центральная часть кластера. Именно с ним взаимодействует клиентское приложение. Управляет пользовательскими сессиями и взаимодействует с GTM и узлами данных. Парсит запросы, строит план выполнения запросов и отсылает его на каждый из компонентов участвующий в запросе, собирает результаты и отсылает их обратно клиенту Координатор не хранит никаких пользовательских данных. Он хранит только служебные данные, чтобы определить как обрабатывать запросы, где находятся узлы данных. При выходе из строя одного из координаторов можно просто переключиться на другой.
Узел данных — место где хранятся пользовательские данные и индексы. Связь с узлами данных осуществляется только через координаторы. Для обеспечения высокой доступности можно подпереть каждый из узлов stanby сервером.

В качестве балансировщика нагрузки можно использовать pgpool-II. О его настройке уже много рассказывалось на хабре, например, тут и тут Хорошей практикой является установка координатора и узла данных на одной машине, так как нам не нужно заботиться о балансировке нагрузке между ними и данные из реплицируемых таблиц можно получить на месте без отправки дополнительного запроса по сети.
Схема тестового кластера
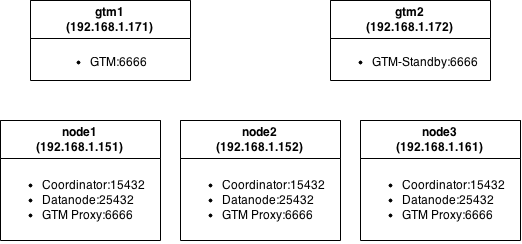
Каждый узел это виртуальная машина со скромным аппаратным обеспечением: MemTotal: 501284 kB, cpu MHz: 2604.
Установка
Тут все стандартно: качаем исходники с офсайта, доставляем зависимости, компилируем. Собирал на Ubuntu server 14.10.
$ sudo apt-get install flex bison docbook-dsssl jade iso8879 docbook libreadline-dev zlib1g-dev
$ ./configure --prefix=/home/${USER}/Develop/utils/postgres-xl --disable-rpath
$ make world
После того как пакет собран заливаем его на узлы кластера и переходим к настройке компонентов.
Настройка GTM
Для обеспечения отказоустойчивости рассмотрим пример с настройкой двух GTM серверов. На обоих серверах создаем рабочий каталог для GTM и инициализируем его.
$ mkdir ~/gtm
$ initgtm -Z gtm -D ~/gtm/
После чего переходим к настройке конфигов:
gtm1
gtm.conf
…
nodename = 'gtm_master'
listen_addresses = '*'
port = 6666
startup = ACT
log_file = 'gtm.log'
…
nodename = 'gtm_master'
listen_addresses = '*'
port = 6666
startup = ACT
log_file = 'gtm.log'
…
gtm2
gtm.conf
…
nodename = 'gtm_slave'
listen_addresses = '*'
port = 6666
startup = STANDBY
active_host = 'gtm1'
active_port = 6666
log_file = 'gtm.log'
…
nodename = 'gtm_slave'
listen_addresses = '*'
port = 6666
startup = STANDBY
active_host = 'gtm1'
active_port = 6666
log_file = 'gtm.log'
…
Сохраняем, стартуем:
$ gtm_ctl start -Z gtm -D ~/gtm/
В логах наблюдаем записи:
LOG: Started to run as GTM-Active.
LOG: Started to run as GTM-Standby.
Настройка GTM-Proxy
$ mkdir gtm_proxy
$ initgtm -Z gtm_proxy -D ~/gtm_proxy/
$ nano gtm_proxy/gtm_proxy.conf
gtm_proxy.conf
…
nodename = 'gtmproxy1' # имя должно быть уникально
listen_addresses = '*'
port = 6666
gtm_host = 'gtm1' #указываем ip или имя хоста на котором развернут GTM мастер
gtm_port = 6666
log_file = 'gtm_proxy.log'
…
nodename = 'gtmproxy1' # имя должно быть уникально
listen_addresses = '*'
port = 6666
gtm_host = 'gtm1' #указываем ip или имя хоста на котором развернут GTM мастер
gtm_port = 6666
log_file = 'gtm_proxy.log'
…
После правки конфига можно запускать:
$ gtm_ctl start -Z gtm_proxy -D ~/gtm_proxy/
Настройка координаторов
$ mkdir coordinator
$ initdb -D ~/coordinator/ -E UTF8 --locale=C -U postgres -W --nodename coordinator1
$ nano ~/coordinator/postgresql.conf
coordinator/postgresql.conf
…
listen_addresses = '*'
port = 15432
pooler_port = 16667
gtm_host = '127.0.0.1'
pgxc_node_name = 'coordinator1'
…
listen_addresses = '*'
port = 15432
pooler_port = 16667
gtm_host = '127.0.0.1'
pgxc_node_name = 'coordinator1'
…
Настройка узла данных
$ mkdir ~/datanode
$ initdb -D ~/datanode/ -E UTF8 --locale=C -U postgres -W --nodename datanode1
$ nano ~/datanode/postgresql.conf
datanode/postgresql.conf
…
listen_addresses = '*'
port = 25432
pooler_port = 26667
gtm_host = '127.0.0.1'
pgxc_node_name = 'datanode1'
…
listen_addresses = '*'
port = 25432
pooler_port = 26667
gtm_host = '127.0.0.1'
pgxc_node_name = 'datanode1'
…
Для остальных узлов настройка отличается только указанием другого имени.
Теперь правим pg_hba.conf:
echo "host all all 192.168.1.0/24 trust" >> ~/datanode/pg_hba.conf
echo "host all all 192.168.1.0/24 trust" >> ~/coordinator/pg_hba.conf
Запуск и донастройка
Все готово и можно запускать.
$ pg_ctl start -Z datanode -D ~/datanode/ -l ~/datanode/datanode.log
$ pg_ctl start -Z coordinator -D ~/coordinator/ -l ~/coordinator/coordinator.log
Заходим на координатор:
psql -p15432
Выполняем запрос:
select * from pgxc_node;
Запрос показывает как текущей сервер видит наш кластер.
Пример вывода:
node_name | node_type | node_port | node_host | nodeis_primary | nodeis_preferred | node_id
-------------+-----------+-----------+-----------+----------------+------------------+------------
coordinator1 | C | 5432 | localhost | f | f | 1938253334
Эти настройки неверны и их можно смело удалять.
delete from pgxc_node;
Создаем новое отображение нашего кластера:
create node coordinator1 with (type=coordinator, host='192.168.1.151', port=15432);
create node coordinator2 with (type=coordinator, host='192.168.1.152', port=15432);
create node coordinator3 with (type=coordinator, host='192.168.1.161', port=15432);
create node datanode1 with (type=datanode, host='192.168.1.151', primary=true, port=25432);
create node datanode2 with (type=datanode, host='192.168.1.152', primary=false, port=25432);
create node datanode3 with (type=datanode, host='192.168.1.161', primary=false, port=25432);
SELECT pgxc_pool_reload();
select * from pgxc_node;
node_name | node_type | node_port | node_host | nodeis_primary | nodeis_preferred | node_id
--------------+-----------+-----------+---------------+----------------+------------------+-------------
datanode1 | D | 25432 | 192.168.1.151 | t | f | 888802358
coordinator1 | C | 15432 | 192.168.1.151 | f | f | 1938253334
coordinator2 | C | 15432 | 192.168.1.152 | f | f | -2089598990
coordinator3 | C | 15432 | 192.168.1.161 | f | f | -1483147149
datanode2 | D | 25432 | 192.168.1.152 | f | f | -905831925
datanode3 | D | 25432 | 192.168.1.161 | f | f | -1894792127
На остальных узлах нужно выполнить тоже самое.
Узел данных не позволит полностью очистить информацию, но ее можно перезаписать:
psql -p 25432 -c "alter node datanode1 WITH ( TYPE=datanode, HOST ='192.168.1.151', PORT=25432, PRIMARY=true);"
Тестирование кластера
Теперь все настроено и работает. Создадим несколько тестовых таблиц.
CREATE TABLE test1
( id bigint NOT NULL, profile bigint NOT NULL,
status integer NOT NULL, switch_date timestamp without time zone NOT NULL,
CONSTRAINT test1_id_pkey PRIMARY KEY (id)
) to node (datanode1, datanode2);
CREATE TABLE test2
( id bigint NOT NULL, profile bigint NOT NULL,
status integer NOT NULL, switch_date timestamp without time zone NOT NULL,
CONSTRAINT test2_id_pkey PRIMARY KEY (id)
) distribute by REPLICATION;
CREATE TABLE test3
( id bigint NOT NULL, profile bigint NOT NULL,
status integer NOT NULL, switch_date timestamp without time zone NOT NULL,
CONSTRAINT test3_id_pkey PRIMARY KEY (id)
) distribute by HASH(id);
CREATE TABLE test4
( id bigint NOT NULL, profile bigint NOT NULL,
status integer NOT NULL, switch_date timestamp without time zone NOT NULL
) distribute by MODULO(status);
Было создано 4 таблицы с одинаковой структурой, но разной логикой распределения по кластеру.
Данные таблицы test1 будут храниться только на 2х узлах данных — datanode1 и datanode2, а распределятся они будут по алгоритму roundrobin. Остальные таблицы задействуют все узлы. Таблица test2 работает в режиме репликации. Для определения на каком сервере будут храниться данные таблицы test3 используется хеш-функция по полю id, а для определения логики распределения test4 берется модуль по полю status. Попробуем теперь заполнить их:
insert into test1 (id, profile, status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,10) a;
insert into test2 (id , profile,status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,10) a;
insert into test3 (id , profile,status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,10) a;
insert into test4 (id , profile,status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,10) a;
Запросим теперь эти данные и посмотрим, как работает планировщик
explain analyze select count(*) from test1;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=27.50..27.51 rows=1 width=0) (actual time=0.649..0.649 rows=1 loops=1)
-> Remote Subquery Scan on all (datanode1,datanode2) (cost=0.00..24.00 rows=1400 width=0) (actual time=0.248..0.635 rows=2 loops=1)
Total runtime: 3.177 ms
explain analyze select count(*) from test2;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Remote Subquery Scan on all (datanode2) (cost=27.50..27.51 rows=1 width=0) (actual time=0.711..0.711 rows=1 loops=1)
Total runtime: 2.833 ms
explain analyze select count(*) from test3;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=27.50..27.51 rows=1 width=0) (actual time=1.453..1.453 rows=1 loops=1)
-> Remote Subquery Scan on all (datanode1,datanode2,datanode3) (cost=0.00..24.00 rows=1400 width=0) (actual time=0.465..1.430 rows=3 loops=1)
Total runtime: 3.014 ms
Планировщик сообщает нам о том сколько узлов будет участвовать в запросе. Так как table2 реплицируется на все узлы, то просканирован будет только 1 узел. Кстати неясно по какой логике он выбирается. Логично было бы, чтоб он запрашивал данные с того же узла на котором и координатор.
Подключившись к узлу данных (на порт 25432) можно увидеть как были распределены данные.
Теперь давайте попробуем заполнить таблицы большим объемом данных и сравнить производительность запросов со standalone PostgreSQL.
insert into test3 (id , profile,status, switch_date) select a, round(random()*10000), round(random()*4), now() - '1 year'::interval * round(random() * 40) from generate_series(1,1000000) a;
Запрос в кластере Postgres-XL:
explain analyze select profile, count(status) from test3
where status<>2
and switch_date between '1970-01-01' and '2015-01-01' group by profile;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=34.53..34.54 rows=1 width=12) (actual time=266.319..268.246 rows=10001 loops=1)
-> Remote Subquery Scan on all (datanode1,datanode2,datanode3) (cost=0.00..34.50 rows=7 width=12) (actual time=172.894..217.644 rows=30003 loops=1)
Total runtime: 276.690 ms
Этот же запрос на сервере с PostgreSQL:
explain analyze select profile, count(status) from test
where status<>2
and switch_date between '1970-01-01' and '2015-01-01' group by profile;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
HashAggregate (cost=28556.44..28630.53 rows=7409 width=12) (actual time=598.448..600.495 rows=10001 loops=1)
-> Seq Scan on test (cost=0.00..24853.00 rows=740688 width=12) (actual time=0.418..329.145 rows=740579 loops=1)
Filter: ((status <> 2) AND (switch_date >= '1970-01-01 00:00:00'::timestamp without time zone) AND (switch_date <= '2015-01-01 00:00:00'::timestamp without time zone))
Rows Removed by Filter: 259421
Total runtime: 601.572 ms
Наблюдаем двукратное увеличение скорости. Не так уж и плохо, если у вас в распоряжении есть достаточное количество машин, то такое масштабирование выглядит довольно перспективно.
Как было замечено в комментариях интересно было бы посмотреть на join таблиц распределенных по нескольким узлам. Давайте попробуем:
create table test3_1 (id bigint NOT NULL, name text, CONSTRAINT test3_1_id_pkey PRIMARY KEY (id)) distribute by HASH(id);
insert into test3_1 (id , name) select a, md5(random()::text) from generate_series(1,10000) a;
explain analyze select test3.*,test3_1.name from test3 join test3_1 on test3.profile=test3_1.id;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Remote Subquery Scan on all (datanode1,datanode2,datanode3) (cost=35.88..79.12 rows=1400 width=61) (actual time=26.500..17491.685 rows=999948 loops=1)
Total runtime: 17830.984 ms
Запрос на тех же объемах данных, но на standalone сервере:
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=319.00..42670.00 rows=999800 width=69) (actual time=99.697..19806.038 rows=999940 loops=1)
Hash Cond: (test.profile = test_1.id)
-> Seq Scan on test (cost=0.00..17353.00 rows=1000000 width=28) (actual time=0.031..6417.221 rows=1000000 loops=1)
-> Hash (cost=194.00..194.00 rows=10000 width=41) (actual time=99.631..99.631 rows=10000 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 713kB
-> Seq Scan on test_1 (cost=0.00..194.00 rows=10000 width=41) (actual time=0.011..46.190 rows=10000 loops=1)
Total runtime: 25834.613 ms
Тут выигрыш всего лишь в 1,5 раза.
P.S. Надеюсь, данный пост поможет кому-нибудь. Комментарии и дополнения приветствуются! Благодарю за внимание.
